

基于colab的yolov3-tensorflow训练自己的数据集(全小白教程)
- 1.站在巨人的肩上
- 2.colab的使用
* - 1. 创建谷歌账号;
- 2. 创建云盘;
- 3.挂载云盘文件夹
- 3.YOLOV3-Tensorflow
* - 1.下载源码
- 2.下载Labelimg标注工具
- 3.创建VOC文件夹
- 4.标注图像
- 5.分割训练集与测试集
- 6.放入yolov3.weights文件
- 7.上传文件夹
- 4.在colab服务器上进行训练
* - 1.服务器基本设置
- 2.挂载colab文件夹
- 3.生成tfrecord文件
- 4.迁移训练
- 5.测试模型
- 总结
本文原创:转载请说明来源
1.站在巨人的肩上
github源码:https://github.com/zzh8829/yolov3-tf2
参考B站视频:https://www.bilibili.com/video/BV1YK4y1E7zd(colab使用)
https://www.bilibili.com/video/BV1r5411t7Db?t=1536&p=2(训练)
2.colab的使用
colab是谷歌推出的免费GPU使用的云服务器平台(说实话,用完之后感觉谷歌还是一个良心企业),想深入了解的可以去谷歌官网了解。
1. 创建谷歌账号;
**前情提示**:使用谷歌的时候,最好要有能“科学”上网的工具,不然中间某一步可能就进行不下去了。
大家下载装好谷歌浏览器,然后注册一个谷歌账号就行,这个比较简单,需要自己的手机号,就不多说了。
2. 创建云盘;

登录号账号,可以在谷歌浏览器的右上方你头像的左边按钮里面找到 云端硬盘,点击进去。

在左上方点击 新建然后点击 关联更多应用

在搜索里面找到colabratory,安装好后,返回云端硬盘新建,可以直接看到该应用了。
; 3.挂载云盘文件夹
由于colab设计的初衷是供大家短期使用,所以每次使用colab服务器,里面的文件都会被清除。建议大家把工程文件放到云盘,然后进行挂载,不然colab服务器不会保存你的文件。挂载操作我会放到下面一起讲解。
3.YOLOV3-Tensorflow
1.下载源码
本教程使用的源码地址是:https://github.com/zzh8829/yolov3-tf2,大家下载后解压放在一个全英文路径就行了。
2.下载Labelimg标注工具
不会使用的同学,可以参考https://www.jianshu.com/p/ff99d430150f,保证能打开软件界面后,看下面内容。
3.创建VOC文件夹

各位一定要严格按照这样的格式进行创建,不要做修改,直接照着搬就行了。(这里有两个py文件是我写的脚本,后续会说)
- yolov3-tf2-master
- VOCdevkit
- VOC2012
- Annotation
- ImageSets
- Main
- JPEGImages
现在文件夹里面的内容都是空的,接下来,把所有需要标注的文件放进JPEGImages里面,注意要是jpg格式的图片。
下面的代码是用于格式化图片名称的,这样方便后续查看。
import os
class ImageRename():
def __init__(self):
self.path = 'E:\yolov3-tf2-master\VOCdevkit\VOC2012\JPEGImages'
def rename(self):
filelist = os.listdir(self.path)
total_num = len(filelist)
i = 0
for item in filelist:
if item.endswith('.jpg'):
src = os.path.join(os.path.abspath(self.path), item)
dst = os.path.join(os.path.abspath(self.path), '0000' + format(str(i), '0>3s') + '.jpg')
os.rename(src, dst)
i = i + 1
if __name__ == '__main__':
newname = ImageRename()
newname.rename()
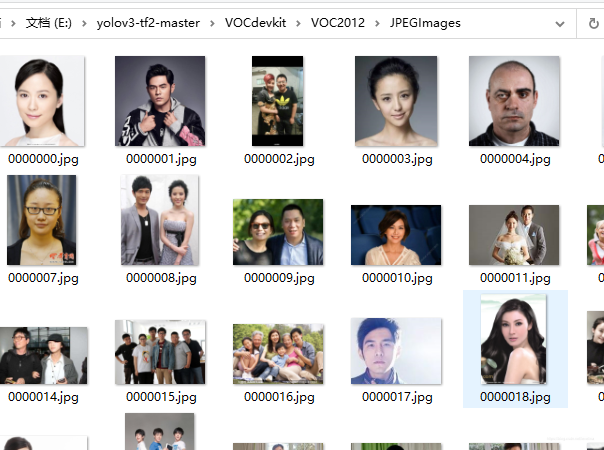
效果就像这样。
4.标注图像

打开labelimg,我们需要注意把第三个圈住的地方改成pascalVOC模式,然后点击open Dir找到刚刚我们的JPEGImages文件夹,然后点Change Save Dir把标注好的xml文件存到Annotation里,然后就是进行标注工作。操作都是图形化的,很简单,能看懂,如果实在不懂的,可以看看这方面的教程,主要是要把路径设置正确。
特别注意:在标注的时候,你的数据集有多少类别,就相应的在data文件夹里,复制voc2012.names文件,然后改成你想要的(我这里改成了face_voc2012.names),文件里面存放的是你的类,一类一行,本教程用的是一类就是face。( 在所有操作中,需要注意你的文件名和地址,方面与我的教程有所不同时,自己修改)
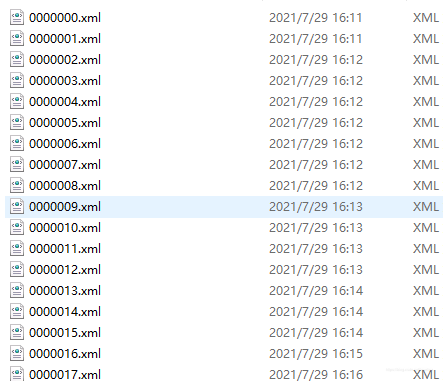
标注完成后,会生成这样的xml文件,那就代表完成标注工作了。
; 5.分割训练集与测试集
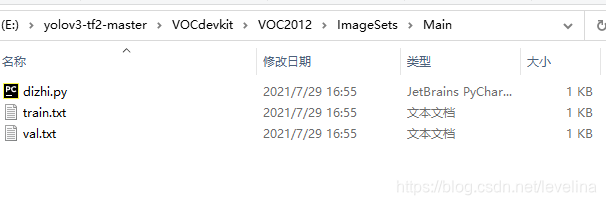
在ImageSets里的Main里创建py文件,源码我放下面,作用就是分割好训练集与测试集
import os,glob
path = r'E:\yolov3-tf2-master\VOCdevkit\VOC2012\JPEGImages'
path_list = os.listdir(path)
path_list.sort()
print(len(path_list))
with open('train.txt', "w", encoding='utf-8') as f:
for i in path_list[0:int(len(path_list)*0.8)]:
sentences = i[:-4]+'\n'
f.write(sentences)
with open('val.txt', "w", encoding='utf-8') as f:
for i in path_list[int(len(path_list)*0.8):-1]:
sentences = i[:-4]+'\n'
f.write(sentences)
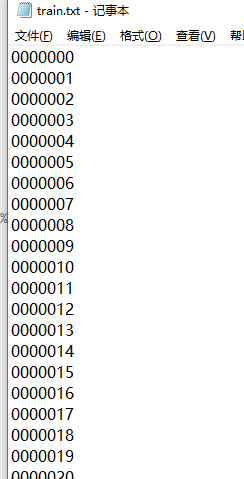
其实这里面存放的就是图片的地址。
6.放入yolov3.weights文件
在https://pjreddie.com/media/files/yolov3.weights下载yolov3.weights放在data文件夹下。
7.上传文件夹
做完上面的步骤,我们把文件夹上传到我的云端硬盘。
; 4.在colab服务器上进行训练
1.服务器基本设置
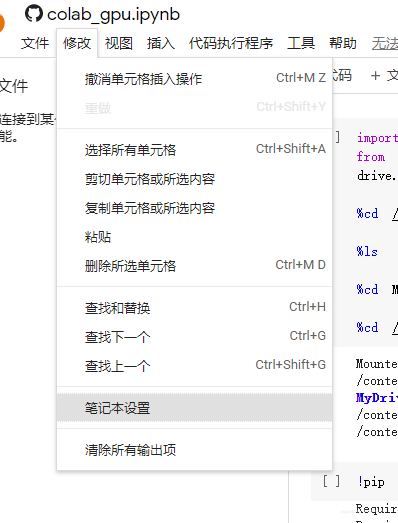
在云端硬盘 新建中选择colab进入服务器,点击左上方 修改,点击 笔记本设置,选择GPU。
然后点击右上方 连接到托管的运行时,即可连接使用colab服务器了。
; 2.挂载colab文件夹
需要说明的是:colab服务器使用的是Linux系统,IDE是jupyter notebook,小白的话需要懂一些基础操作。(比如运行代码需要在前面加感叹号)
在界面上方点击+代码,添加代码块,尽量多添加几条。
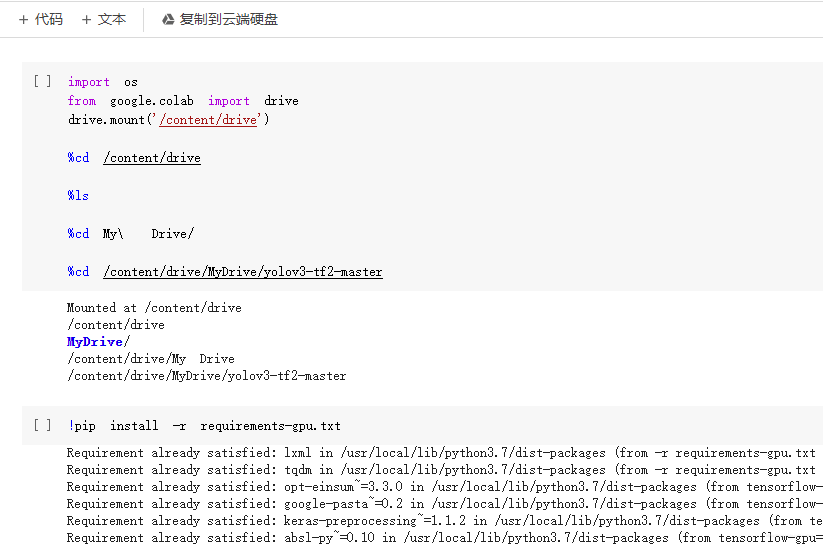
然后在代码块中键入一下代码,尽量一行一个代码块,方面查看。
import os
from google.colab import drive
drive.mount('/content/drive')
%cd /content/drive
%ls
%cd My\ Drive/
%cd /content/drive/MyDrive/yolov3-tf2-master
!pip install -r requirements-gpu.txt
!python convert.py
3.生成tfrecord文件
这个操作是这个tensorflow版本特有的操作,目的应该是将所有训练集和测试集的地址全部存入一个地址,方便读取。
python tools/voc2012.py --data_dir ./VOCdevkit/VOC2012 --split train --output_file ./data/voc_train.tfrecord --classes ./data/face_voc2012.names
python tools/voc2012.py --data_dir ./VOCdevkit/VOC2012 --split val --output_file ./data/voc_val.tfrecord --classes ./data/face_voc2012.names
执行完后,会在data文件夹下生成voc_train.tfrecord和voc_val.tfrecord,那就代表生成tfrecord文件成功了。
4.迁移训练
下面的代码用于训练,参数较多,不过都应该都可以看懂,一一对应就好。
python train.py --dataset ./data/voc_train.tfrecord --val_dataset ./data/voc_val.tfrecord --classes ./data/face_voc2012.names --num_classes 1 --mode fit --transfer darknet --batch_size 32 --epochs 20 --weights ./checkpoints/yolov3.tf --weights_num_classes 80
如果你训练的类目与我有所不同,请修改 num_classes,其他的可以保持不动。
还有一点需要注意的就是:在训练过程中,可以会出现loss还未降到20,就过早停止训练的情况 WARNING:tensorflow:Unresolved object in checkpoint: (root).layer-8 W0428 16:43:05.946897 140396833212224 util.py:150] Unresolved object in checkpoint: (root).layer-8 WARNING:tensorflow:Unresolved object in checkpoint: (root).layer-9 W0428 16:43:05.947242 140396833212224 util.py:150] Unresolved object in checkpoint: (root).layer-9 Epoch 00003: early stopping
这时候我们需要打开train.py进行修改
callbacks = [
ReduceLROnPlateau(verbose=1),
EarlyStopping(patience=3, verbose=1),
ModelCheckpoint('checkpoints/yolov3_train_{epoch}.tf',
verbose=1, save_weights_only=True),
TensorBoard(log_dir='logs')
]

本教程标注了45张人脸作为训练,训练步数epoch设置为了20。用时219秒,loss就降到了73。不得不说这比在darknet上训练快多了,我快感动哭了。。。。
不过大家自己做的时候,要尽量保证loss降到20以下,这样模型才准确。
完成训练后,模型会保存到./checkpoints/,在下面一步会用到
5.测试模型
测试模型用下面的代码,注意有与我不同的地方,请自己修改,比如权重文件地址,和图片地址, 特别注意:这里把threshold设置为 0.3,因为源码的最高分为0.5,所以不设置的话,可能会导致显示不出来。
python detect.py --classes ./data/face_voc2012.names --num_classes 1 --weights ./checkpoints/yolov3_train_20.tf --image ./VOCdevkit/VOC2012/JPEGImages/0000016.jpg
--yolo_score_threshold 0.3
本教程测试的效果如下

总结
总的来说,整个流程会有点复杂,但是绝对不难,相信各位仔细操作,就可以跑出结果,对于更高阶的检测,比如连接摄像头和其他,可以看源码的说明文档,由于我目前没有设备所以就没有演示。
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/521303/
转载文章受原作者版权保护。转载请注明原作者出处!