

问题一:数据集太小
如果数据集太小,模型将没有足够样例概括来区分特征。这将使数据过拟合,从而出现训练误差低但测试误差高的情况。
解决方案1
尝试找到更多和原始数据集来源相同的数据。
- 注:如果图像很相似或者你追求的就是泛化,也可用其他来源的数据。
- 小贴士:这并非易事,需要你投入时间和经费。在开始之前,你要先分析确定需要多少额外数据。将不同大小的数据集得出的结果做比较,然后思考一下这个问题。
解决方案2
通过为同一张图像创建多个细微变化的副本来扩充数据,可以让你以非常低的成本创造很多额外的图像。你可以试着裁剪、旋转或缩放图片,也可以添加噪音、模糊、改变图片颜色或遮挡部分内容。


- 注:不管怎么操作,只需保证这些数据仍代表相同类就好了。虽然这种操作很厉害,但收集更多原始数据效果好。
- 小贴士:这种”扩充术”不适合所有问题,比如如果你想分类黄柠檬和绿柠檬,就不需要调颜色。
; 问题二:分类质量差
这是个简单但耗时的问题,需要你浏览一遍数据集确认每个样例的标签贴得对不对。
除此以外,一定要为你的分类选择合适的粒度(granularity)。基于要解决的问题,来增加或减少你的分类。
比如,要识别猫,你可以用全局分类器先确定它是动物,之后再用动物分类器确定它是一只小猫。一个大型的模型能同时做到这两点,但分起类来也更加困难。
问题三:数据集质量差
数据质量差会导致结果的质量差。
当你的数据集中有一些样例离达标很远,比如下面这几张图像。

这些图像会干扰模型的正确分类,需要将这些图像在数据集中剔除。
虽然是个漫长枯燥的过程,但对结果的提升效果很明显。
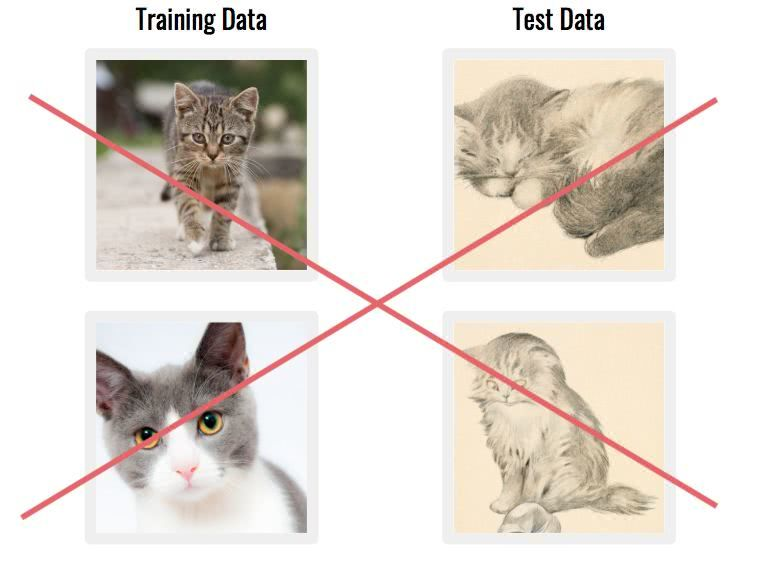
另一个常见问题是,数据集可能是由与实际应用程序不匹配的数据组成的。如果图像来自完全不同来源,这个问题可能尤为严重。
解决方案:
尝试用相同的工具查找/构建一个数据集。
; 问题四:分类不平衡
如果每个分类的样例数量与其他类别数量差距太大,则模型可能倾向于数量占主导地位的类,因为它会让错误率变低。
解决方案1:
你可以收集更多非代表性的分类。然而这通常需要花费时较多间和金钱,也可能根本不可行。
解决方案2:
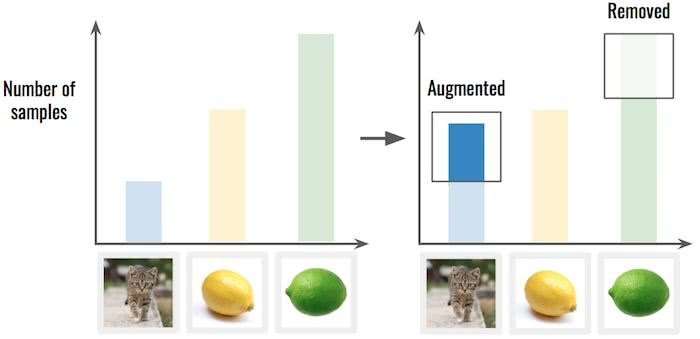
对数据进行过采样/降采样处理。这意味着你可能需要从那些比例过多的分类中移除一些样例,也可以在比例较少的类别中进行上面提到过的样例扩充处理。先扩充样例不足的分类(猫咪)这将使类别的分布更平滑
问题五:数据不平衡
如果数据没有专门的格式,或者它的值没有在特定的范围,模型处理起来可能很困难。如果图像有特定的纵横比或像素值,得到的结果会更好。
解决方案1:
裁剪或拉伸数据,使其与其他样例的格式相同,如下图所示。

解决方案2:
将数据规范化,使每个样例在相同的值范围内。

; 问题六:没有验证或测试
数据集被清理、扩充并打上标签后,就需要把它们分组了。
许多数据研究人员会将这些数据分成两组:80%用于训练,20%用于测试,这将会使发现过拟合变容易。
然而,如果在同一个测试集上尝试多个模型,情况则有所不同。选择测试精度的最佳模型,实际上是对测试集进行过拟合处理。
解决方案:
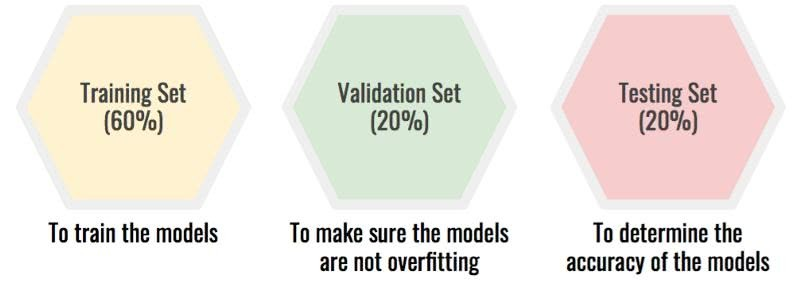
将数据集分为训练、验证和测试三组,这可以保护测试集,防止它因为所选的模型而过拟合。那这个过程就变成了:
在训练集上训练模型
在验证集上测试它们,确保它们没有过拟合
选择最佳模型,并用测试集测试,看看你的模型准确性有多高。
- 注:用整个数据集去训练模型,数据越多,效果越好。
Original: https://blog.csdn.net/jinchenpeng/article/details/116303017
Author: 云游四海 Jin
Title: 深度学习关于数据集的六大问题
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/521292/
转载文章受原作者版权保护。转载请注明原作者出处!