

目录
概述
本文基于Tensorflow r1.15源码 链接 通过Sample示例,重点分析计算图创建与执行的内部原理。
Sample示例
import tensorflow as tf
x1 = tf.placeholder(tf.float32, shape=(2, 2))
y1 = tf.placeholder(tf.float32, shape=(2, 2))
b1 = tf.placeholder(tf.float32, shape=(2, 2))
x2 = tf.matmul(x1, y1)
y2 = tf.add(x2, b1)
with tf.Session() as sess:
vals = sess.run(y2, feed_dict={x1:[[0.7, 0.5], [0.7, 0.5]] ,
y1:[[0.7, 0.5], [0.7, 0.5]],
b1:[[0.7, 0.5], [0.7, 0.5]]} )
sess.close()
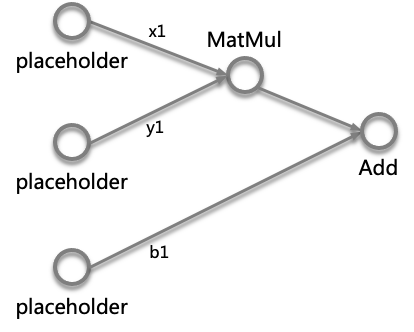

Sample代码对应的计算图
非常直观简单的一个Sample示例,3个Placeholder作为输入,做MatMul和Add两个计算
GPU设备创建
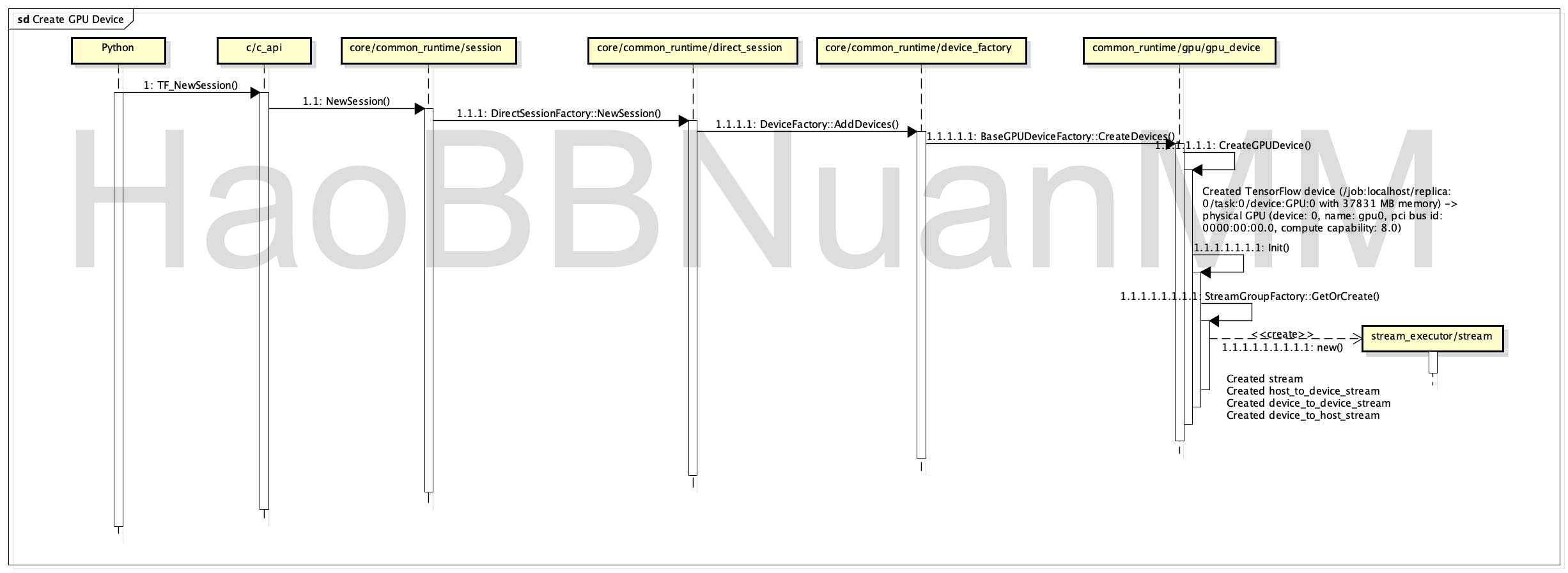
GPU Device创建时序
Sample程序运行时python部分会创建新的Session,在Native部分会如上图所示创建GPUDevice,特别是创建stream_executor模块中的stream对象,它是真正提供CUDA API计算能力的模块,如下图所示: StreamExecutorInterface 提供操作GPU的抽象API接口,GpuExecutor提供API的实现并通过GpuDrivre真正调用了CUDA Runtime/Driver API操作GPU设备
//tensorflow/stream_executor/stream_executor_internal.h
// CUDA-platform implementation of the platform-agnostic
// StreamExecutorInferface.
class GpuExecutor : public internal::StreamExecutorInterface {
...
//tensorflow/stream_executor/gpu/gpu_executor.h
// CUDA-platform implementation of the platform-agnostic
// StreamExecutorInferface.
class GpuExecutor : public internal::StreamExecutorInterface {
...
//tensorflow/stream_executor/cuda/cuda_gpu_executor.cc
port::Status GpuExecutor::Init(int device_ordinal,
DeviceOptions device_options) {
device_ordinal_ = device_ordinal;
auto status = GpuDriver::Init();
if (!status.ok()) {
return status;
}
status = GpuDriver::GetDevice(device_ordinal_, &device_);
if (!status.ok()) {
return status;
}
status = GpuDriver::CreateContext(device_ordinal_, device_, device_options,
&context_);
if (!status.ok()) {
return status;
}
//tensorflow/stream_executor/cuda/cuda_driver.cc
// Actually performs the work of CUDA initialization. Wrapped up in one-time
// execution guard.
static port::Status InternalInit() {
...
res = cuInit(0 /* = flags */);
...
/* static */ port::Status GpuDriver::GetDevice(int device_ordinal,
CUdevice* device) {
RETURN_IF_CUDA_RES_ERROR(cuDeviceGet(device, device_ordinal),
"Failed call to cuDeviceGet");
...
/* static */ port::Status GpuDriver::CreateContext(
int device_ordinal, CUdevice device, const DeviceOptions& device_options,
GpuContext** context) {
...
CHECK_EQ(CUDA_SUCCESS,
cuDevicePrimaryCtxGetState(device, &former_primary_context_flags,
&former_primary_context_is_active));
计算图创建与执行

计算图创建与执行时序图
该部分的时序图比较复杂,按如下的层次结构来理解和看图
计算图运行DirectSession::Run 主要工作包括下面几部分
- 创建所有子图的执行器DirectSession::GetOrCreateExecutors 主要工作包括
- 为Sample程序创建完整的计算图DirectSession::BuildGraph,为计算图通过grappler模块做优化,包括各种Optimizer和优化Pass,其中会通过VirtualPlacer模块将计算图中各个节点放到合适的计算设备上,通过PruneGraph做剪枝优化,对于Sample程序生成下图的计算图
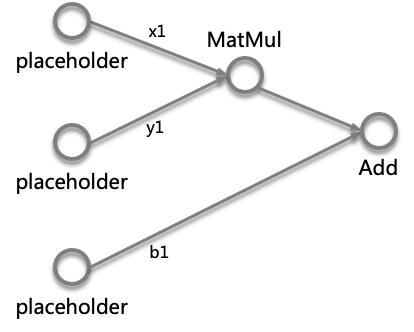
Sample程序计算图
- 将计算图分割到不同计算设备分割成子图DirectSession::Partition,这一步会根据不同节点在计算设备之间(CPU
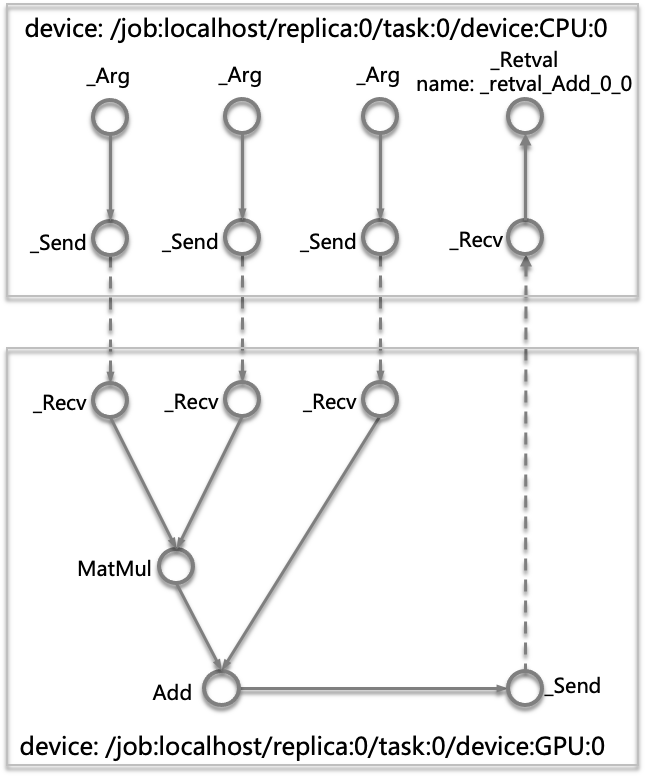
Sample程序计算图经过Partition分割成CPU和GPU上两个子图
- 为每个子图创建它的执行器NewLocalExecutor,该步骤中会为每个子图上的阶段创建对应的Op Kernel实例,以便在后续执行真正的计算
- 运行各个子图DirectSessoin::RunInternal,每个子图的执行器异步运行子图,子图中的每个节点通过线程池来调度执行 Process -> PrepareInputs -> Compute/ComputeAsync(执行OP Kernel完成GPU的计算) -> ProcessOutputs -> PropagateOutputs -> ActivateNodes -> NodeDone 这个pipeline,直到所有计算图中的节点执行完毕 (该过程更详细的代码介绍,可以参考我的前一篇Tensorflow Internals源码分析文章链接
Original: https://blog.csdn.net/HaoBBNuanMM/article/details/123458507
Author: HaoBBNuanMM
Title: 【架构分析】Tensorflow Internals源码分析2 – 计算图创建与执行
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/521048/
转载文章受原作者版权保护。转载请注明原作者出处!