

深度学习之卷积神经网络(14)CIFAR10与ResNet18实战
本节我们将实现18层的深度残差网络ResNet18,并在CIFAR10图片数据集上训练与测试。并将与13层的普通神经网络VGG13进行简单的性能比较。
网络结构
标准的ResNet18接受输入为224 × 224 224×224 2 2 4 ×2 2 4大小的图片数据,我们将ResNet18进行适量调整,使得它输入大小为32 × 32 32×32 3 2 ×3 2,输出维度为10。调整后的ResNet18网络结构如下图所示:


调整后的ResNet18网络结构
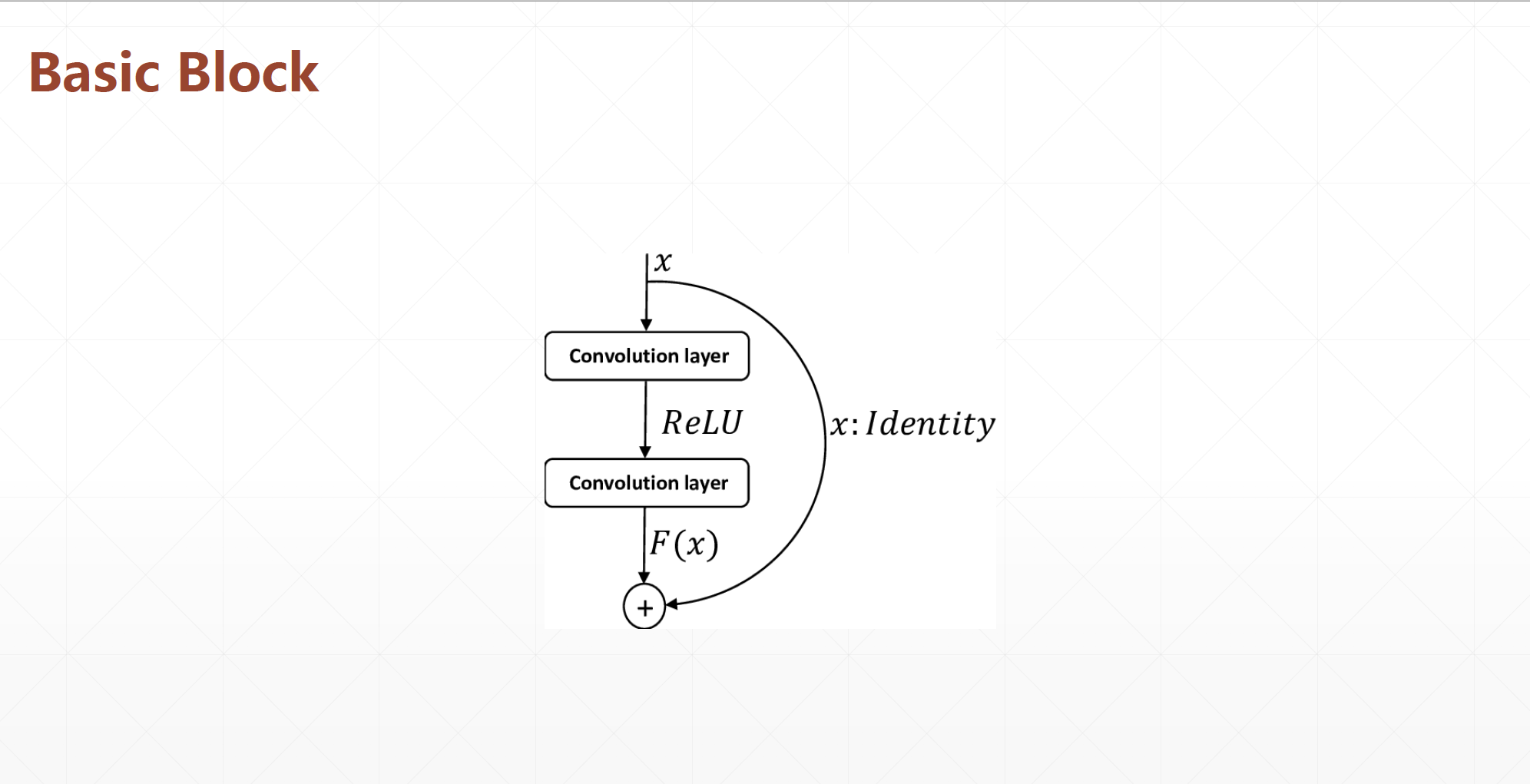
; Basic Block
首先实现中间两个卷积层,Skip Connection 1 × 1 1×1 1 ×1 卷积层的残差模块。代码如下:
class BasicBlock(layers.Layer):
# 残差模块
def __init__(self, filter_num, stride=1):
super(BasicBlock, self).__init__()
# 第一个卷积单元
self.conv1 = layers.Conv2D(filter_num, (3, 3), strides=stride, padding='same')
self.bn1 = layers.BatchNormalization()
self.relu = layers.Activation('relu')
# 第二个卷积单元
self.conv2 = layers.Conv2D(filter_num, (3, 3), strides=1, padding='same')
self.bn2 = layers.BatchNormalization()
if stride != 1:# 通过1x1卷积完成shape匹配
self.downsample = Sequential()
self.downsample.add(layers.Conv2D(filter_num, (1, 1), strides=stride))
else:# shape匹配,直接短接
self.downsample = lambda x:x
def call(self, inputs, training=None):
# [b, h, w, c],通过第一个卷积单元
out = self.conv1(inputs)
out = self.bn1(out)
out = self.relu(out)
# 通过第二个卷积单元
out = self.conv2(out)
out = self.bn2(out)
# 通过identity模块
identity = self.downsample(inputs)
# 2条路径输出直接相加
output = layers.add([out, identity])
output = tf.nn.relu(output) # 激活函数
return output
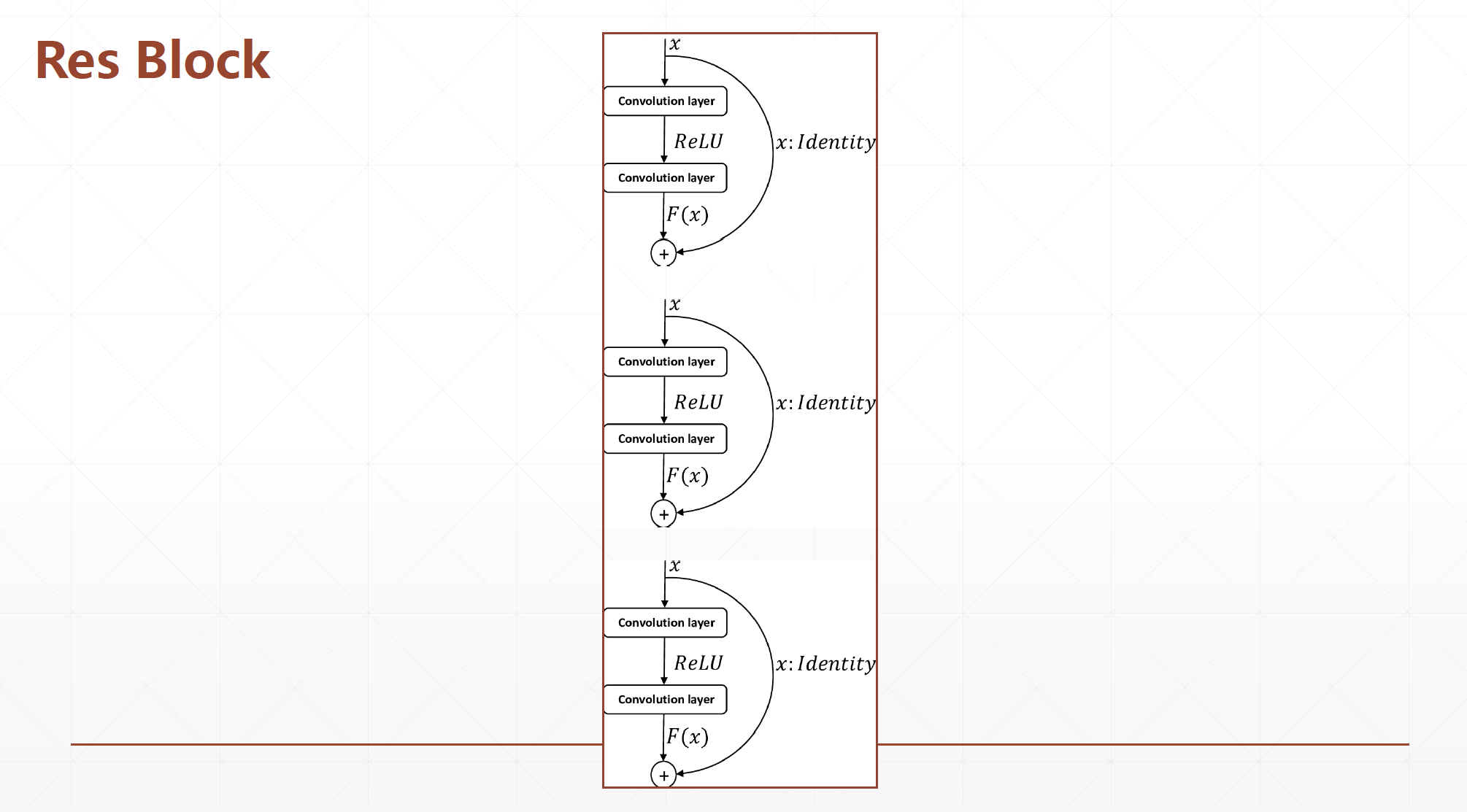
在设计深度卷积神经网络时,一般按照特征图高宽h / w h/w h /w逐渐减少,通道数c c c逐渐增大的经验法则。可以通过堆叠通道数逐渐增大的Res Block来实现高层特征提取,通过build_resblock可以一次完成多个残差模块的新建。代码如下:
def build_resblock(self, filter_num, blocks, stride=1):
# 辅助函数,堆叠filter_num个BasicBlock
res_blocks = Sequential()
# 只有第一个BasicBlock的步长可能不为1,实现下采样
res_blocks.add(BasicBlock(filter_num, stride))
for _ in range(1, blocks):#其他BasicBlock步长都为1
res_blocks.add(BasicBlock(filter_num, stride=1))
return res_blocks
Res Block
下面我们来实现通用的ResNet网络模型。代码如下:
class ResNet(keras.Model):
# 通用的ResNet实现类
def __init__(self, layer_dims, num_classes=10): # [2, 2, 2, 2]
super(ResNet, self).__init__()
# 根网络,预处理
self.stem = Sequential([layers.Conv2D(64, (3, 3), strides=(1, 1)),
layers.BatchNormalization(),
layers.Activation('relu'),
layers.MaxPool2D(pool_size=(2, 2), strides=(1, 1), padding='same')
])
# 堆叠4个Block,每个block包含了多个BasicBlock,设置步长不一样
self.layer1 = self.build_resblock(64, layer_dims[0])
self.layer2 = self.build_resblock(128, layer_dims[1], stride=2)
self.layer3 = self.build_resblock(256, layer_dims[2], stride=2)
self.layer4 = self.build_resblock(512, layer_dims[3], stride=2)
# 通过Pooling层将高宽降低为1x1
self.avgpool = layers.GlobalAveragePooling2D()
# 最后连接一个全连接层分类
self.fc = layers.Dense(num_classes)
def call(self, inputs, training=None):
# 通过根网络
x = self.stem(inputs)
# 一次通过4个模块
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
# 通过池化层
x = self.avgpool(x)
# 通过全连接层
x = self.fc(x)
return x
ResNet18
通过调整每个Res Block的堆叠数量和通道数可以产生不同的ResNet,如通过64-64-128-128-256-256-512-512通道数配置,共8个Res Block,可得到ResNet18的网络模型。每个ResBlock包含了2个主要的卷积层,因此卷积层数量是8 ⋅ 2 = 16 8\cdot2=16 8 ⋅2 =1 6,加上网络末尾的全连接层,共18层。创建ResNet18和ResNet34可以简单实现如下:

def resnet18():
# 通过调整模块内部BasicBlock的数量和配置实现不同的ResNet
return ResNet([2, 2, 2, 2])
def resnet34():
# 通过调整模块内部BasicBlock的数量和配置实现不同的ResNet
return ResNet([3, 4, 6, 3])
下面完成CIFAR10数据集的加载工作,代码如下:
(x, y), (x_test, y_test) = load_data('/Users/xuruihang/.keras/datasets/cifar-10-batches-py')
(x,y), (x_test, y_test) = datasets.cifar10.load_data() # 加载数据集
y = tf.squeeze(y, axis=1) # 删除不必要的维度
y_test = tf.squeeze(y_test, axis=1) # 删除不必要的维度
print(x.shape, y.shape, x_test.shape, y_test.shape)
train_db = tf.data.Dataset.from_tensor_slices((x, y)) # 构建训练集
随机打散,预处理,批量化
train_db = train_db.shuffle(1000).map(preprocess).batch(512)
test_db = tf.data.Dataset.from_tensor_slices((x_test, y_test)) # 构建测试集
随机打散,预处理,批量化
test_db = test_db.map(preprocess).batch(512)
采样一个样本
sample = next(iter(train_db))
print('sample:', sample[0].shape, sample[1].shape,
tf.reduce_min(sample[0]), tf.reduce_max(sample[0]))
数据预处理,直接将数据范围映射到[ − 1 , 1 ] [-1,1][−1 ,1 ]区间。这里也可以基于ImageNet数据图片的均值和标准差做标准化处理。代码如下:
def preprocess(x, y):
# 将数据映射到-1~1
x = 2*tf.cast(x, dtype=tf.float32) / 255. - 1
y = tf.cast(y, dtype=tf.int32) # 类型转换
return x,y
网络训练逻辑和普通的分类网络训练部分一样,固定训练50个Epoch。代码如下:
for epoch in range(100): # 训练epoch
for step, (x, y) in enumerate(train_db):
with tf.GradientTape() as tape:
# [b, 32, 32, 3] => [b, 10],前向传播
logits = model(x)
# [b] => [b, 10],one-hot编码
y_onehot = tf.one_hot(y, depth=10)
# 计算交叉熵
loss = tf.losses.categorical_crossentropy(y_onehot, logits, from_logits=True)
loss = tf.reduce_mean(loss)
# 计算梯度信息
grads = tape.gradient(loss, model.trainable_variables)
# 更新网络参数
optimizer.apply_gradients(zip(grads, model.trainable_variables))
计算准确率并打印:
total_num = 0
total_correct = 0
for x, y in test_db:
logits = model(x)
prob = tf.nn.softmax(logits, axis=1)
pred = tf.argmax(prob, axis=1)
pred = tf.cast(pred, dtype=tf.int32)
correct = tf.cast(tf.equal(pred, y), dtype=tf.int32)
correct = tf.reduce_sum(correct)
total_num += x.shape[0]
total_correct += int(correct)
acc = total_correct / total_num
print(epoch, 'acc:', acc)
ResNet18的网络参数量共1100万个,经过50个Epoch后,网络的正确率达到了 79.3%。这里的实战代码比较精简,在精调超参数、数据增强等手段加持下,准确率可以达到更高。
完整代码
CIFAR10
import numpy as np
import os
from tensorflow.python.keras import backend as k
def load_batch(file):
import pickle
with open(file, 'rb') as fo:
d = pickle.load(fo, encoding='bytes')
d_decoded = {}
for k, v in d.items():
d_decoded[k.decode('utf8')] = v
d = d_decoded
data = d['data']
labels = d['labels']
data = data.reshape(data.shape[0], 3, 32, 32)
return data, labels
def load_data(path ='data/cifar-10-batches-py'):
"""Loads CIFAR10 dataset.
# Returns
Tuple of Numpy arrays: (x_train, y_train), (x_test, y_test).
"""
from tensorflow.python.keras import backend as K
num_train_samples = 50000
x_train = np.empty((num_train_samples, 3, 32, 32), dtype='uint8')
y_train = np.empty((num_train_samples,), dtype='uint8')
for i in range(1, 6):
fpath = os.path.join(path, 'data_batch_' + str(i))
(x_train[(i - 1) * 10000: i * 10000, :, :, :],
y_train[(i - 1) * 10000: i * 10000]) = load_batch(fpath)
fpath = os.path.join(path, 'test_batch')
x_test, y_test = load_batch(fpath)
y_train = np.reshape(y_train, (len(y_train), 1))
y_test = np.reshape(y_test, (len(y_test), 1))
if K.image_data_format() == 'channels_last':
x_train = x_train.transpose(0, 2, 3, 1)
x_test = x_test.transpose(0, 2, 3, 1)
return (x_train, y_train), (x_test, y_test)
ResNet
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers, Sequential
class BasicBlock(layers.Layer):
# 残差模块
def __init__(self, filter_num, stride=1):
super(BasicBlock, self).__init__()
# 第一个卷积单元
self.conv1 = layers.Conv2D(filter_num, (3, 3), strides=stride, padding='same')
self.bn1 = layers.BatchNormalization()
self.relu = layers.Activation('relu')
# 第二个卷积单元
self.conv2 = layers.Conv2D(filter_num, (3, 3), strides=1, padding='same')
self.bn2 = layers.BatchNormalization()
if stride != 1:# 通过1x1卷积完成shape匹配
self.downsample = Sequential()
self.downsample.add(layers.Conv2D(filter_num, (1, 1), strides=stride))
else:# shape匹配,直接短接
self.downsample = lambda x:x
def call(self, inputs, training=None):
# [b, h, w, c],通过第一个卷积单元
out = self.conv1(inputs)
out = self.bn1(out)
out = self.relu(out)
# 通过第二个卷积单元
out = self.conv2(out)
out = self.bn2(out)
# 通过identity模块
identity = self.downsample(inputs)
# 2条路径输出直接相加
output = layers.add([out, identity])
output = tf.nn.relu(output) # 激活函数
return output
class ResNet(keras.Model):
# 通用的ResNet实现类
def __init__(self, layer_dims, num_classes=10): # [2, 2, 2, 2]
super(ResNet, self).__init__()
# 根网络,预处理
self.stem = Sequential([layers.Conv2D(64, (3, 3), strides=(1, 1)),
layers.BatchNormalization(),
layers.Activation('relu'),
layers.MaxPool2D(pool_size=(2, 2), strides=(1, 1), padding='same')
])
# 堆叠4个Block,每个block包含了多个BasicBlock,设置步长不一样
self.layer1 = self.build_resblock(64, layer_dims[0])
self.layer2 = self.build_resblock(128, layer_dims[1], stride=2)
self.layer3 = self.build_resblock(256, layer_dims[2], stride=2)
self.layer4 = self.build_resblock(512, layer_dims[3], stride=2)
# 通过Pooling层将高宽降低为1x1
self.avgpool = layers.GlobalAveragePooling2D()
# 最后连接一个全连接层分类
self.fc = layers.Dense(num_classes)
def call(self, inputs, training=None):
# 通过根网络
x = self.stem(inputs)
# 一次通过4个模块
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
# 通过池化层
x = self.avgpool(x)
# 通过全连接层
x = self.fc(x)
return x
def build_resblock(self, filter_num, blocks, stride=1):
# 辅助函数,堆叠filter_num个BasicBlock
res_blocks = Sequential()
# 只有第一个BasicBlock的步长可能不为1,实现下采样
res_blocks.add(BasicBlock(filter_num, stride))
for _ in range(1, blocks):#其他BasicBlock步长都为1
res_blocks.add(BasicBlock(filter_num, stride=1))
return res_blocks
def resnet18():
# 通过调整模块内部BasicBlock的数量和配置实现不同的ResNet
return ResNet([2, 2, 2, 2])
def resnet34():
# 通过调整模块内部BasicBlock的数量和配置实现不同的ResNet
return ResNet([3, 4, 6, 3])
ResNet_CIFAR10_train
import tensorflow as tf
from tensorflow.keras import layers, optimizers, datasets, Sequential
import os
from Chapter10.ResNet import resnet18
from Chapter10.CIFAR10 import load_data
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
tf.random.set_seed(2345)
def preprocess(x, y):
# 将数据映射到-1~1
x = 2*tf.cast(x, dtype=tf.float32) / 255. - 1
y = tf.cast(y, dtype=tf.int32) # 类型转换
return x,y
(x, y), (x_test, y_test) = load_data('/Users/xuruihang/.keras/datasets/cifar-10-batches-py')
(x,y), (x_test, y_test) = datasets.cifar10.load_data() # 加载数据集
y = tf.squeeze(y, axis=1) # 删除不必要的维度
y_test = tf.squeeze(y_test, axis=1) # 删除不必要的维度
print(x.shape, y.shape, x_test.shape, y_test.shape)
train_db = tf.data.Dataset.from_tensor_slices((x, y)) # 构建训练集
随机打散,预处理,批量化
train_db = train_db.shuffle(1000).map(preprocess).batch(512)
test_db = tf.data.Dataset.from_tensor_slices((x_test, y_test)) # 构建测试集
随机打散,预处理,批量化
test_db = test_db.map(preprocess).batch(512)
采样一个样本
sample = next(iter(train_db))
print('sample:', sample[0].shape, sample[1].shape,
tf.reduce_min(sample[0]), tf.reduce_max(sample[0]))
def main():
# [b, 32, 32, 3] => [b, 1, 1, 512]
model = resnet18() # ResNet18网络
model.build(input_shape=(None, 32, 32, 3))
model.summary() # 统计网络参数
optimizer = optimizers.Adam(lr=1e-4) # 构建优化器
for epoch in range(100): # 训练epoch
for step, (x, y) in enumerate(train_db):
with tf.GradientTape() as tape:
# [b, 32, 32, 3] => [b, 10],前向传播
logits = model(x)
# [b] => [b, 10],one-hot编码
y_onehot = tf.one_hot(y, depth=10)
# 计算交叉熵
loss = tf.losses.categorical_crossentropy(y_onehot, logits, from_logits=True)
loss = tf.reduce_mean(loss)
# 计算梯度信息
grads = tape.gradient(loss, model.trainable_variables)
# 更新网络参数
optimizer.apply_gradients(zip(grads, model.trainable_variables))
if step % 50 == 0:
print(epoch, step, 'loss:', float(loss))
total_num = 0
total_correct = 0
for x, y in test_db:
logits = model(x)
prob = tf.nn.softmax(logits, axis=1)
pred = tf.argmax(prob, axis=1)
pred = tf.cast(pred, dtype=tf.int32)
correct = tf.cast(tf.equal(pred, y), dtype=tf.int32)
correct = tf.reduce_sum(correct)
total_num += x.shape[0]
total_correct += int(correct)
acc = total_correct / total_num
print(epoch, 'acc:', acc)
if __name__ == '__main__':
main()
运行结果
训练50轮的运行结果如下图所示:
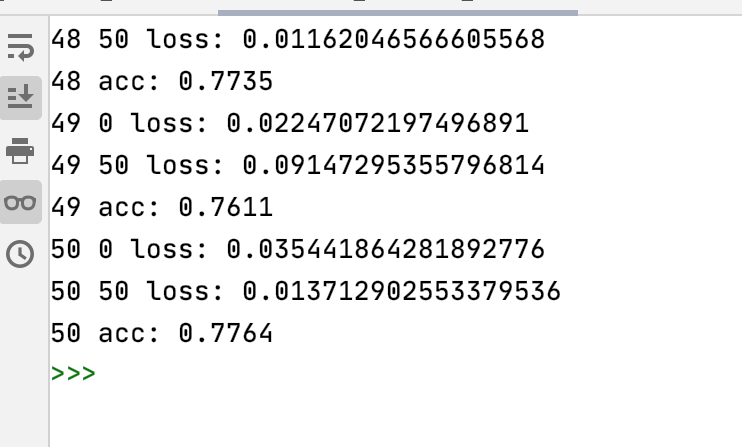
训练50轮的运行结果如下图所示:
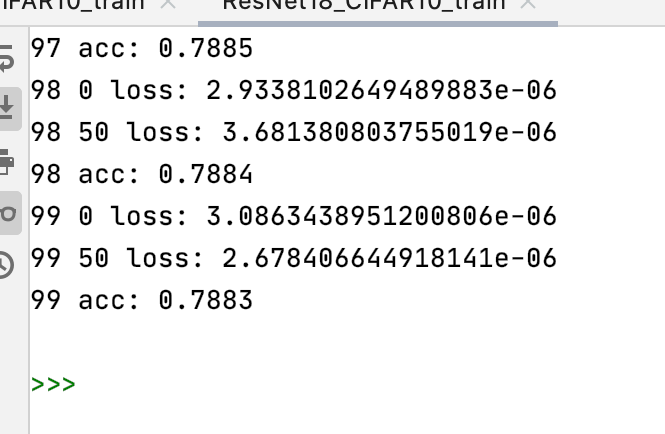
可以发现,从50轮以后提升很小,甚至在某些轮的训练后准确率反而比上一轮训练准确率小,这说明模型已经收敛。
; 完整的运行结果
sequential (Sequential) (None, 30, 30, 64) 2048
_________________________________________________________________
sequential_1 (Sequential) (None, 30, 30, 64) 148736
_________________________________________________________________
sequential_2 (Sequential) (None, 15, 15, 128) 526976
_________________________________________________________________
sequential_4 (Sequential) (None, 8, 8, 256) 2102528
_________________________________________________________________
sequential_6 (Sequential) (None, 4, 4, 512) 8399360
_________________________________________________________________
global_average_pooling2d (Gl multiple 0
_________________________________________________________________
Total params: 11,184,778
Trainable params: 11,176,970
Non-trainable params: 7,808
_________________________________________________________________
0 0 loss: 2.304671287536621
0 50 loss: 1.724245309829712
0 acc: 0.4088
1 0 loss: 1.527838110923767
1 50 loss: 1.4276442527770996
1 acc: 0.4767
2 0 loss: 1.4245407581329346
2 50 loss: 1.337162733078003
2 acc: 0.5288
3 0 loss: 1.1859643459320068
3 50 loss: 1.1161954402923584
3 acc: 0.5817
4 0 loss: 1.1631160974502563
4 50 loss: 1.1030761003494263
4 acc: 0.6137
5 0 loss: 1.0337800979614258
5 50 loss: 1.072596788406372
5 acc: 0.637
6 0 loss: 0.9901767373085022
6 50 loss: 0.9797731637954712
6 acc: 0.6291
7 0 loss: 0.9143185019493103
7 50 loss: 0.8440685868263245
7 acc: 0.6566
8 0 loss: 0.9292833209037781
8 50 loss: 0.8220429420471191
8 acc: 0.6946
9 0 loss: 0.7005643248558044
9 50 loss: 0.7470488548278809
9 acc: 0.684
10 0 loss: 0.7359604835510254
10 50 loss: 0.7945782542228699
10 acc: 0.7009
11 0 loss: 0.6502181887626648
11 50 loss: 0.6889203786849976
11 acc: 0.7198
12 0 loss: 0.6140835285186768
12 50 loss: 0.7919586300849915
12 acc: 0.7348
13 0 loss: 0.5944421291351318
13 50 loss: 0.4832625389099121
13 acc: 0.7233
14 0 loss: 0.4902136027812958
14 50 loss: 0.5227885246276855
14 acc: 0.719
15 0 loss: 0.5720866918563843
15 50 loss: 0.5135402679443359
15 acc: 0.7417
16 0 loss: 0.4544442296028137
16 50 loss: 0.44296538829803467
16 acc: 0.7534
17 0 loss: 0.4698091745376587
17 50 loss: 0.5296239852905273
17 acc: 0.7536
18 0 loss: 0.37270843982696533
18 50 loss: 0.3469978868961334
18 acc: 0.7592
19 0 loss: 0.2902595102787018
19 50 loss: 0.38105398416519165
19 acc: 0.7605
20 0 loss: 0.2810669243335724
20 50 loss: 0.26301872730255127
20 acc: 0.7526
21 0 loss: 0.3145701289176941
21 50 loss: 0.24620205163955688
21 acc: 0.7518
22 0 loss: 0.28198641538619995
22 50 loss: 0.21114742755889893
22 acc: 0.735
23 0 loss: 0.2616957426071167
23 50 loss: 0.21654242277145386
23 acc: 0.744
24 0 loss: 0.21215686202049255
24 50 loss: 0.15145476162433624
24 acc: 0.7594
25 0 loss: 0.11127788573503494
25 50 loss: 0.09175924211740494
25 acc: 0.7542
26 0 loss: 0.1439075767993927
26 50 loss: 0.1296052783727646
26 acc: 0.7043
27 0 loss: 0.3256385922431946
27 50 loss: 0.08157408237457275
27 acc: 0.7588
28 0 loss: 0.08700433373451233
28 50 loss: 0.06183788180351257
28 acc: 0.7593
29 0 loss: 0.07082505524158478
29 50 loss: 0.056175511330366135
29 acc: 0.7627
30 0 loss: 0.059344805777072906
30 50 loss: 0.042943716049194336
30 acc: 0.7557
31 0 loss: 0.07505717128515244
31 50 loss: 0.029341526329517365
31 acc: 0.7569
32 0 loss: 0.04519665986299515
32 50 loss: 0.05225048214197159
32 acc: 0.7565
33 0 loss: 0.07314451038837433
33 50 loss: 0.03366083279252052
33 acc: 0.7516
34 0 loss: 0.058682411909103394
34 50 loss: 0.02697981707751751
34 acc: 0.7519
35 0 loss: 0.061525844037532806
35 50 loss: 0.0266877431422472
35 acc: 0.7663
36 0 loss: 0.031200429424643517
36 50 loss: 0.022879503667354584
36 acc: 0.7668
37 0 loss: 0.009555387310683727
37 50 loss: 0.01859653741121292
37 acc: 0.7552
38 0 loss: 0.0918155312538147
38 50 loss: 0.01932132989168167
38 acc: 0.7648
39 0 loss: 0.017598923295736313
39 50 loss: 0.03878815099596977
39 acc: 0.7687
40 0 loss: 0.009030519053339958
40 50 loss: 0.017727570608258247
40 acc: 0.7631
41 0 loss: 0.011112265288829803
41 50 loss: 0.020026404410600662
41 acc: 0.7701
42 0 loss: 0.009108569473028183
42 50 loss: 0.01226227730512619
42 acc: 0.7639
43 0 loss: 0.015250889584422112
43 50 loss: 0.0243426114320755
43 acc: 0.7564
44 0 loss: 0.027732819318771362
44 50 loss: 4.433307647705078
44 acc: 0.693
45 0 loss: 0.5895786285400391
45 50 loss: 0.1955583691596985
45 acc: 0.7488
46 0 loss: 0.153585284948349
46 50 loss: 0.05180424451828003
46 acc: 0.769
47 0 loss: 0.039987921714782715
47 50 loss: 0.028396831825375557
47 acc: 0.767
48 0 loss: 0.025902796536684036
48 50 loss: 0.01162046566605568
48 acc: 0.7735
49 0 loss: 0.02247072197496891
49 50 loss: 0.09147295355796814
49 acc: 0.7611
50 0 loss: 0.035441864281892776
50 50 loss: 0.013712902553379536
50 acc: 0.7764
51 0 loss: 0.004004147835075855
51 50 loss: 0.004538857843726873
51 acc: 0.7768
52 0 loss: 0.0033672843128442764
52 50 loss: 0.0021370549220591784
52 acc: 0.7814
53 0 loss: 0.001501559279859066
53 50 loss: 0.0007496591424569488
53 acc: 0.7863
54 0 loss: 0.00025488107348792255
54 50 loss: 0.00019856236758641899
54 acc: 0.7881
55 0 loss: 8.268196688732132e-05
55 50 loss: 0.0001364000781904906
55 acc: 0.7887
56 0 loss: 6.010473953210749e-05
56 50 loss: 0.00010873028077185154
56 acc: 0.7888
57 0 loss: 6.491036765510216e-05
57 50 loss: 9.812592179514468e-05
57 acc: 0.7895
58 0 loss: 4.1551895265001804e-05
58 50 loss: 7.726388867013156e-05
58 acc: 0.7897
59 0 loss: 5.010869790567085e-05
59 50 loss: 7.193269993877038e-05
59 acc: 0.7893
60 0 loss: 3.908587677869946e-05
60 50 loss: 5.80549385631457e-05
60 acc: 0.7888
61 0 loss: 3.391343489056453e-05
61 50 loss: 6.26129622105509e-05
61 acc: 0.7891
62 0 loss: 3.5259625292383134e-05
62 50 loss: 5.6777396821416914e-05
62 acc: 0.789
63 0 loss: 3.364583244547248e-05
63 50 loss: 3.475776611594483e-05
63 acc: 0.789
64 0 loss: 2.3166179744293913e-05
64 50 loss: 2.7712114388123155e-05
64 acc: 0.7887
65 0 loss: 2.5775960239116102e-05
65 50 loss: 2.7705544198397547e-05
65 acc: 0.7887
66 0 loss: 2.152946763089858e-05
66 50 loss: 3.0488734410027973e-05
66 acc: 0.7884
67 0 loss: 1.9288405383122154e-05
67 50 loss: 2.5093278964050114e-05
67 acc: 0.7885
68 0 loss: 1.5263916793628596e-05
68 50 loss: 3.0639985197922215e-05
68 acc: 0.7886
69 0 loss: 1.8413200450595468e-05
69 50 loss: 2.025911999226082e-05
69 acc: 0.7885
70 0 loss: 1.6915491869440302e-05
70 50 loss: 2.2718446416547522e-05
70 acc: 0.7883
71 0 loss: 1.4103533430898096e-05
71 50 loss: 2.393607428530231e-05
71 acc: 0.7889
72 0 loss: 9.313837836089078e-06
72 50 loss: 1.578830779180862e-05
72 acc: 0.7889
73 0 loss: 1.3327978194865864e-05
73 50 loss: 1.7181047951453365e-05
73 acc: 0.7885
74 0 loss: 1.1357975381542929e-05
74 50 loss: 1.5531280951108783e-05
74 acc: 0.7883
75 0 loss: 1.2431513823685236e-05
75 50 loss: 1.6181302271434106e-05
75 acc: 0.7883
76 0 loss: 9.57650991040282e-06
76 50 loss: 1.6076604879344814e-05
76 acc: 0.7886
77 0 loss: 7.879717486503068e-06
77 50 loss: 1.68419282999821e-05
77 acc: 0.7887
78 0 loss: 1.0160134479519911e-05
78 50 loss: 1.4264564015320502e-05
78 acc: 0.7888
79 0 loss: 7.002170605119318e-06
79 50 loss: 1.1324462320772e-05
79 acc: 0.7887
80 0 loss: 5.99324857830652e-06
80 50 loss: 1.1957747119595297e-05
80 acc: 0.7889
81 0 loss: 6.4048908825498074e-06
81 50 loss: 1.2153735042375047e-05
81 acc: 0.7889
82 0 loss: 7.097715752024669e-06
82 50 loss: 1.0872829079744406e-05
82 acc: 0.789
83 0 loss: 5.83335440751398e-06
83 50 loss: 9.67220330494456e-06
83 acc: 0.789
84 0 loss: 5.3104054131836165e-06
84 50 loss: 7.635369911440648e-06
84 acc: 0.7889
85 0 loss: 5.974447958578821e-06
85 50 loss: 8.027996955206618e-06
85 acc: 0.7889
86 0 loss: 5.102026989334263e-06
86 50 loss: 7.007363819866441e-06
86 acc: 0.789
87 0 loss: 4.800999704457354e-06
87 50 loss: 8.671936484461185e-06
87 acc: 0.789
88 0 loss: 3.821081463684095e-06
88 50 loss: 6.705515261273831e-06
88 acc: 0.7889
89 0 loss: 4.507476660364773e-06
89 50 loss: 8.573748345952481e-06
89 acc: 0.7888
90 0 loss: 3.259776349295862e-06
90 50 loss: 4.626118425221648e-06
90 acc: 0.7888
91 0 loss: 3.923081294487929e-06
91 50 loss: 6.958610811125254e-06
91 acc: 0.7887
92 0 loss: 4.3761529013863765e-06
92 50 loss: 5.4132578952703625e-06
92 acc: 0.7889
93 0 loss: 2.9485074719559634e-06
93 50 loss: 5.121527465234976e-06
93 acc: 0.7889
94 0 loss: 2.927547029685229e-06
94 50 loss: 5.0153935262642335e-06
94 acc: 0.7889
95 0 loss: 2.989472704939544e-06
95 50 loss: 3.7123525089555187e-06
95 acc: 0.7887
96 0 loss: 3.0932810659578536e-06
96 50 loss: 4.320234893384622e-06
96 acc: 0.7887
97 0 loss: 2.5089204882533522e-06
97 50 loss: 3.282322268205462e-06
97 acc: 0.7885
98 0 loss: 2.9338102649489883e-06
98 50 loss: 3.681380803755019e-06
98 acc: 0.7884
99 0 loss: 3.0863438951200806e-06
99 50 loss: 2.678406644918141e-06
99 acc: 0.7883
PS: 这程序真的直接运行了两天两夜,mmp电脑都没合眼,再运行100轮就得冒烟了哈哈
Original: https://blog.csdn.net/weixin_43360025/article/details/120592843
Author: 炎武丶航
Title: 深度学习之卷积神经网络(14)CIFAR10与ResNet18实战
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/520606/
转载文章受原作者版权保护。转载请注明原作者出处!