

【主要贡献】
1.视频实例分割第一次被正式定义和探索
2.创建了第一个大规模视频实例分割数据集 2.9k视频 40个目标类别
3.提出一种新的视频实例分割算法MaskTrack R-CNN,在Mask R-CNN引入一个新的分支,同时检测,分割和跟踪视频中的实例。
4.实时,两阶段
【Introduction】
图像实例分割同时检测和分割图像中的对象实例。视频实例分割同时检测、分割和跟踪视频中的对象实例。


与VIS相关的任务定义区别Image Instance Segmentation
将像素分组为不同的语义类,还将它们分组为不同的对象实例。
通常采用两阶段模式,首先使用区域建议网络RPN生成对象建议,然后使用聚集的ROI特征预测对象的边界框和masks。
图像级处理
视频实例分割需在每一帧中分割对象实例,还需确定跨帧对象的对应关系。
VOT(Video Object Tracking)
DBT(Detection by Tracking):同时进行检测和跟踪。
DFT(Detection-Free Tracking):在第一帧给定初始边界框,无需检测器进行追踪。
只进行检测,不进行分割VOD(Video Object Detection)检测视频中的对象,目标身份信息用来提升检测算法的鲁棒性,但评估指标仅限于每帧检测。
没有分割和追踪
VSS(Video Semantic Segmentation)
在每一帧进行语义分割,采用光流等时间信息来提高语义分割模型的准确性或效率。不需要跨帧显式匹配对象实例。VOS(Video Object Segmentation)
半监督:使用一个mask跟踪和分割一个给定对象,提取视觉相似性,运动线索和时间一致性,以识别视频中的同一对象。
无监督:不需要给第一帧mask,不需要区分实例,只需要分割出单个目标即可
没有考虑实例信息
【YouTube-VIS】
利用现有的YouTube VOS大型视频对象分割数据集,建立的数据集YouTube-VIS中有 40 个常见类别标签作为类别集。然后从40个类中抽取大约2.9k个样本,目标包括人 动物 车辆 有4883个独立视频实例 和 131k 高质量masks,可以用于视频实例分割,视频语义分割,视频对象检测。
【Video Instance Segmentation】
定义:
定义一个类别预定义标签集 set C={1,,,K},K为类别数量,给定一个T帧的视频,假设有属于C的N个对象,对于每一个对象i,令
表示其类别标签 ,令表示其二进制分割masks,p∈[1, T],q∈[p, T],表示开始和结束时间,假设视频实例算法产生H个实例假设,对于每一个假设 j,它需要有一个预测的类别标签和一个confidence score ,以及一系列的masks ,confidence score 将用于评估指标。
评估方法:
平均准确度AP,AP定义为精准召回曲线下的面积,自信度得分用于绘制曲线。AP是多个IOU阈值上的平均值,遵循COCO评估,在50%到95%使用10个IOU阈值,步长为5%。
平均召回率AR,定义为给定每个视频一定数量的分割实例的最大召回率。IOU的计算不同于图像实例分割,因为每个实例都包含一系列masks,要计算一个ground truth实例
和一个假设实例 之间的IOU。
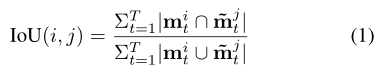
可以考虑为在 T帧的视频中,对每一帧的ground truth和假设实例的交集求和 和 并集求和。达到 如成功检测到对象masks,但未能跨帧跟踪对象,将获得一个较低的IOU 的效果。
【MaskTrack R-CNN】
基于Mask R-CNN构建,除了最初用于对象分类,边界框回归和masks生成三个分支外,添加第四个分支与外部内存一起,以跨帧跟踪对象实例。
跟踪分支主要利用外观相似性,提出了一种简单有效的方法,将其语义一致性和空间相关性等其他线索相结合,以大幅提高跟踪精度。
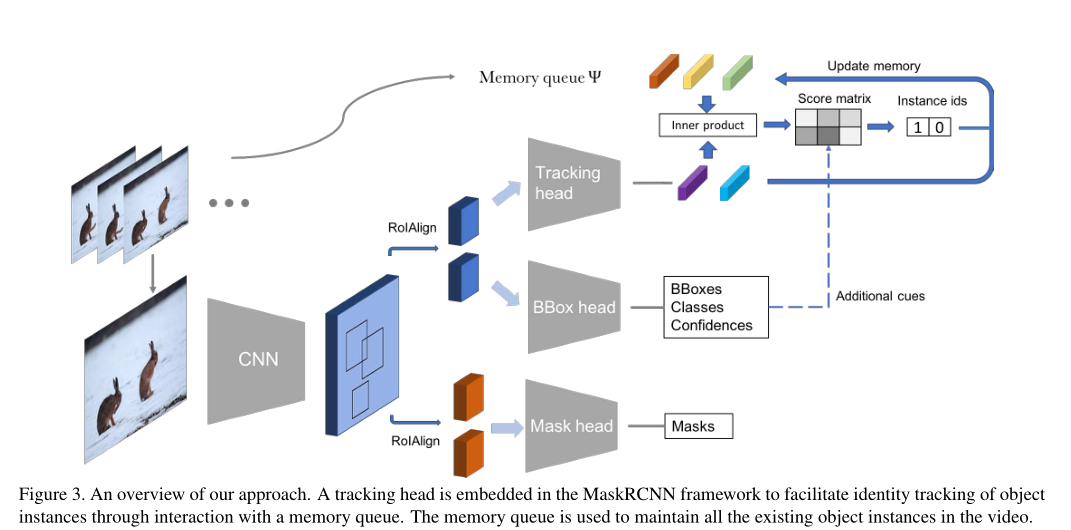
网络整体分为两个阶段,第一阶段为在每帧生成一组对象边界框。第二阶段为添加一个并行的分支Tracking head,其为两个全连接层,为每个候选框指定一个实例标签。
假设已经有N个实例在之前的帧被定义,新实例将分配新的标识。可比作多类分类问题,有N+1个类,N个已识别的实例,一个新的实例,由数字0表示。将标签分配给候选框的概率,定义为
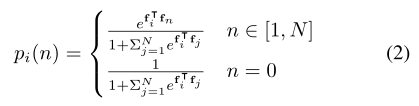 和分别表示跟踪分支从 当前帧的候选框的ROI Align提取的特征和 保存在外部存储器的从前的帧中N个被定义的实例的特征,两个全连接层的加入使得Roi提取的特征映射投影到新特征中。交叉熵损失用来约束跟踪分支,是 ground truth 实例标签。
和分别表示跟踪分支从 当前帧的候选框的ROI Align提取的特征和 保存在外部存储器的从前的帧中N个被定义的实例的特征,两个全连接层的加入使得Roi提取的特征映射投影到新特征中。交叉熵损失用来约束跟踪分支,是 ground truth 实例标签。
当一个新的候选框被分配一个实例标签时,动态地更新外部内存。如果候选框属于现有实例,将使用新的特征更新存储在内存中的实例特征,新的特征代表实例的最新状态。如果为候选对象分配了标签0,我们会将候选对象的特征插入内存,并将 已识别实例的数量 +1。
使用从训练视频中随机抽样的一对帧。其中一个帧被随机选取为参考帧,而另一个帧被选取为查询帧。在参考帧上,不生成任何候选框,只提取特征从它的ground truth实例区域和保存它们到外部内存中。在查询帧上,第一阶段生成候选框,然后只将 positive 候选框与内存中的实例标签匹配。positive 候选框是指与任何ground truth对象框至少有70%IoU重叠的框。整个网络都经过了端到端的培训,四个分支的损失加在一起
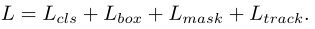
对于一个新的候选框 i,让
分别表示边界框预测,类别标签和置信度,数据来自网络的bounding box branch 和 the classification branch,对于一个被识别的实例带有标签n,让和表示边界框预测和与内存中保存的特征关联的类别标签。然后分配给标签n到候选框i一个分数为
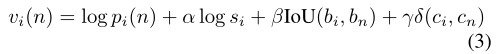
仅在测试阶段使用,对网络训练没有帮助。还有其他可能的方法来整合这些线索,例如,将所有线索作为输入,训练一个端到端的网络,这将作为一个有趣的未来研究。
在给定一个新的测试视频时,外部内存设置为空,识别的实例数设置为0。方法以在线方式顺序处理每一帧。在每一帧,网络首先生成一组实例假设。非最大值抑制(NMS)(50%重叠阈值)用于减少假设。然后,剩余的假设与来自之前的帧的已确定的实例根据等式 3 进行匹配,方法可以匹配多个假设从一个单独的帧到一个实例标签,只保留一个在假设中得分最高的假设,同时丢弃其他假设。
处理所有帧后,方法生成一组实例假设集,每个假设包含一个唯一的实例标签,以及一系列二进制masks、类别标签和检测置信度。使用平均检测置信度作为整个序列的置信度得分,并使用类别标签的多数投票作为实例的最终类别标签。
【Main Results】
方法对比结果
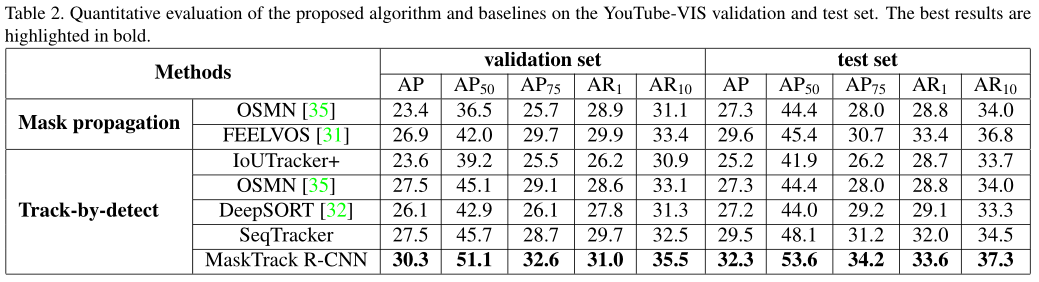
样本结果

(a),(b),(c)和(d)表示正确的预测,而(e)和(f)表示错误情况。a 中预测在前两帧中给出了错误的结果,其中熊被预测为”鹿”和”海豹”。视频级别预测通过所有帧的多数投票来纠正这些错误。在视频 c 中,冲浪板在多帧中被海浪遮挡,算法能够在冲浪板消失和再次出现后跟踪冲浪板。在视频 d 中,展示了一个新对象在中间进入视频的情况,算法能够将第二帧中的鹿检测为新对象,并将其添加到外部存储器中。在视频 e 中,在不同的姿势中有着完全不同的外观,并且算法无法识别相同的对象并认为它们是两个不同的对象。在视频 f 中,多条类似的鱼在四处游动,并相互遮挡。算法在第二帧和第三帧中将两条鱼分成一组,并在稍后与对象身份混淆。
【Ablation Study】
不同因素使用结果
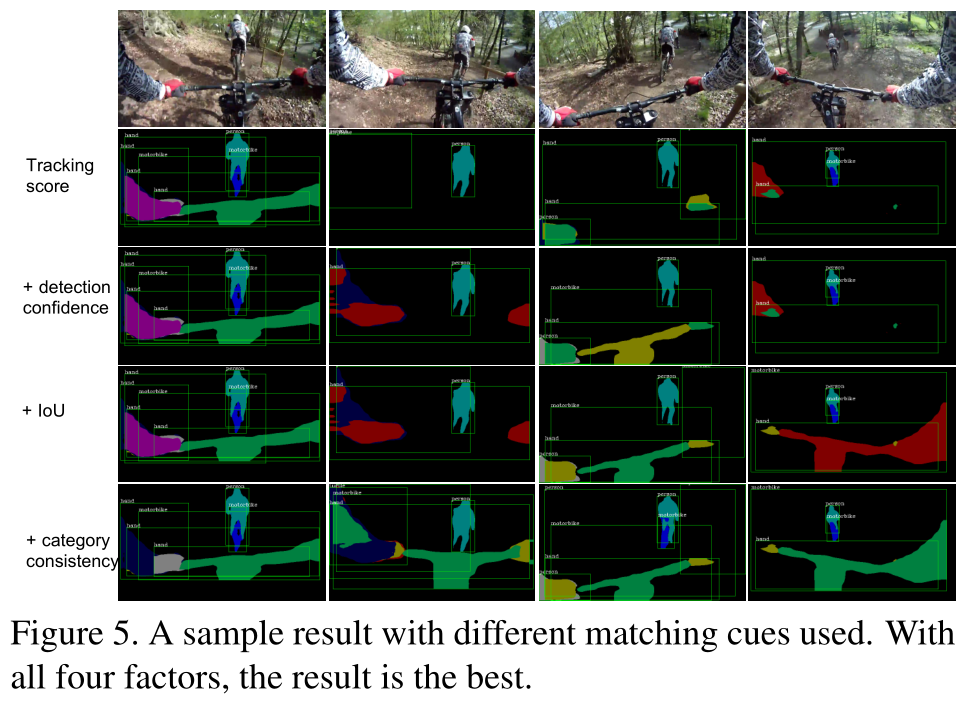
可视化这三个因素的影响,还对一个特定样本逐个添加这三个因素来生成预测,前三种变体无法很好地跟踪”绿色”摩托车的身份,而带有四种不同提示的变体能够在整个视频中跟踪它。
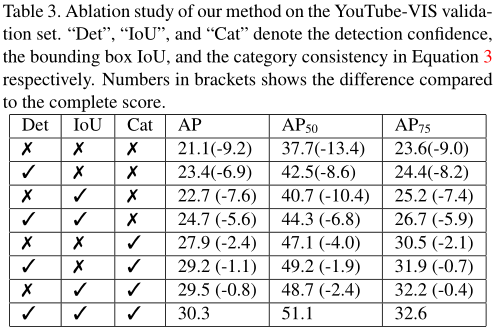
边界框IoU和类别一致性对方法的性能最为重要。
Original: https://blog.csdn.net/linlinsss/article/details/124083428
Author: linlinsss
Title: 视频实例分割paper(一)《Video Instance Segmentation》
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/520572/
转载文章受原作者版权保护。转载请注明原作者出处!