

一、ResNet简介
残差神经网络(Residual Network, ResNet)是由 微软研究院的 何恺明、张祥雨、任少卿、 孙剑等人提出的。ResNet 在 2015年的ILSVRC(ImageNet Large Scale Visual Recognition Challenge)中取得了 冠军。(何凯明大佬对于深度学习的贡献是非常巨大的,很多库函数都是他贡献的,感兴趣的读者可以去了解一下。)
残差神经网络(Residual Network, ResNet)的提出是CNN图像史上的一件 里程碑事件,让我们先看一下ResNet在ILSVRC和COCO 2015上的战绩:
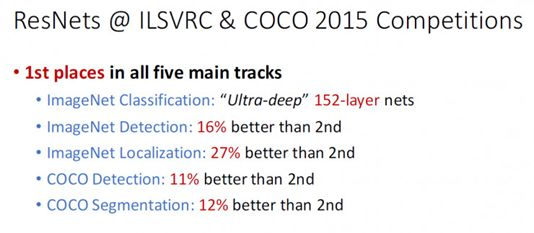

ResNet取得了 5项第一,并又一次刷新了CNN模型在ImageNet上的历史:

残差神经网络(ResNet)的主要贡献是发现了” 退化现象(Degradation)“,并针对退化现象发明了 ” 快捷连接(Shortcut connection)“,极大的消除了深度过大的神经网络训练困难问题。神经网络的”深度” 首次突破了100层、最大的神经网络甚至 超过了1000层。(史诗级的突破—— 神经网络深度)
- 论文地址: https://arxiv.org/pdf/1512.03385.pdf
- 本文代码地址:链接:https://pan.baidu.com/s/1DzF3XrwRuUJfcBTFYIjheQ 提取码:s4xn
ResNet 的核心思想
自从2012年的ILSVRC挑战赛中, AlexNet取得了冠军,并且大幅度领先于第二名。人们心中就诞生出了一种 信仰—— “越深网络准确率越高”。之后出现的优秀 经典神经网络:VGGNet、Inception v1、Inception v2、Inception v3等一直延续这个信仰,不断验证、不断强化,得到越来越多的认可。
学者们在不断追求更深的神经网络模型的路上突然发现了一个 严重问题。随着网络层不断的加深,模型的准确率先是不断的提高,达到最大值( 准确率饱和),然后随着网络深度的继续增加,模型准确率毫无征兆的出现 大幅度的降低。具体情况如下图:

从上图可以看出,56层的网络比20层网络效果还要差。这不会是 过拟合问题 (过拟合一般指因为训练迭代次数过多,导致权重过度偏向训练集),因为56层网络的训练误差同样高。我们知道深层网络存在着梯度消失或者爆炸的问题,这使得深度学习模型很难训练。
ResNet团队把这一现象称为 “退化(Degradation)”。ResNet团队把退化现象归因为深层神经网络难以实现” 恒等变换( y = x )“(即过深的神经网络不能进行简单的映射)
退化现象让我们对 非线性转换进行反思,非线性转换极大的提高了数据分类能力,但是,随着网络的深度不断的加大,我们在非线性转换方面已经走的太远, 竟然无法实现线性转换。
最终, ResNet团队在ResNet模块中增加了 快捷连接分支,在线性转换和非线性转换之间寻求一个 平衡。
按照这个思路,ResNet团队分别构建了带有” 快捷连接(Shortcut Connection)“的ResNet构建块以及 降采样的ResNet构建块(降采样构建块的主杆分支上增加了一个 1×1的卷积操作 )。
Residual Block的设计
F(x)+x构成的 block称之为 Residual Block,即 残差块,如下图所示,多个相似的Residual Block 串联构成ResNet。

一个残差块有2条路径 F(x)和 x, F(X)路径拟合残差,不妨称之为残差路径, x路径为identity mapping 恒等映射,称之为” shortcut“。 图中的⊕为element-wise addition,要求参与运算的F(x)和x的尺寸要相同。
在原论文中,残差路径可以 大致分成2种,一种有bottleneck结构,即下图右中的1×1 卷积层,用于先降维再升维,主要出于降低计算复杂度的现实考虑,称之为” bottleneck block“,另一种没有bottleneck结构,如下图左所示,称之为” basic block“。basic block由2个3×3卷积层构成,bottleneck block由1×1

shortcut路径大致也可以分成2种,取决于残差路径 是否改变了feature map数量和尺寸,一种是将输入x原封不动地输出,另一种则需要经过1×1卷积来升维 or/and 降采样,主要作用是将输出与F(x)路径的输出保持shape一致,对网络性能的提升并不明显,两种结构如下图所示:
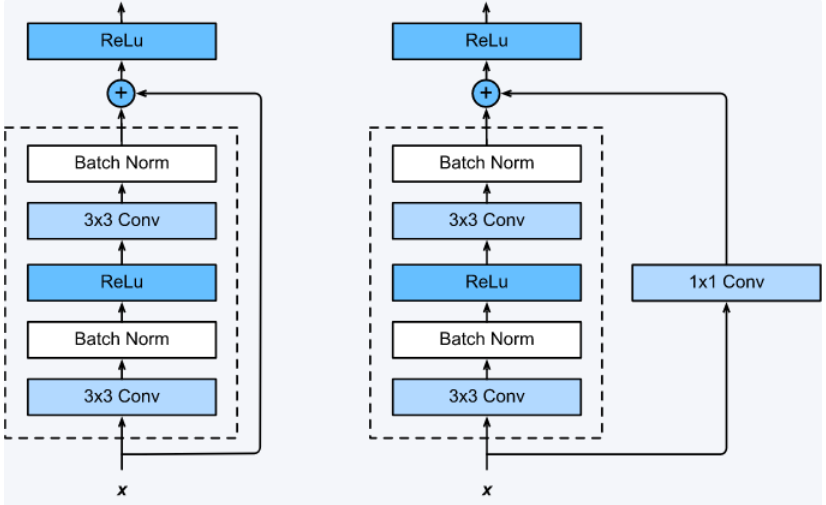
ResNet 网络结构
经过发展,ResNet出现了 多种深度的网络模型。这里,我们以最为经典的 ResNet34为例:
ResNet为多个 Residual Block的 串联,下面直观看一下ResNet-34与34-layer plain net和VGG的对比,以及堆叠不同数量Residual Block得到的不同ResNet。
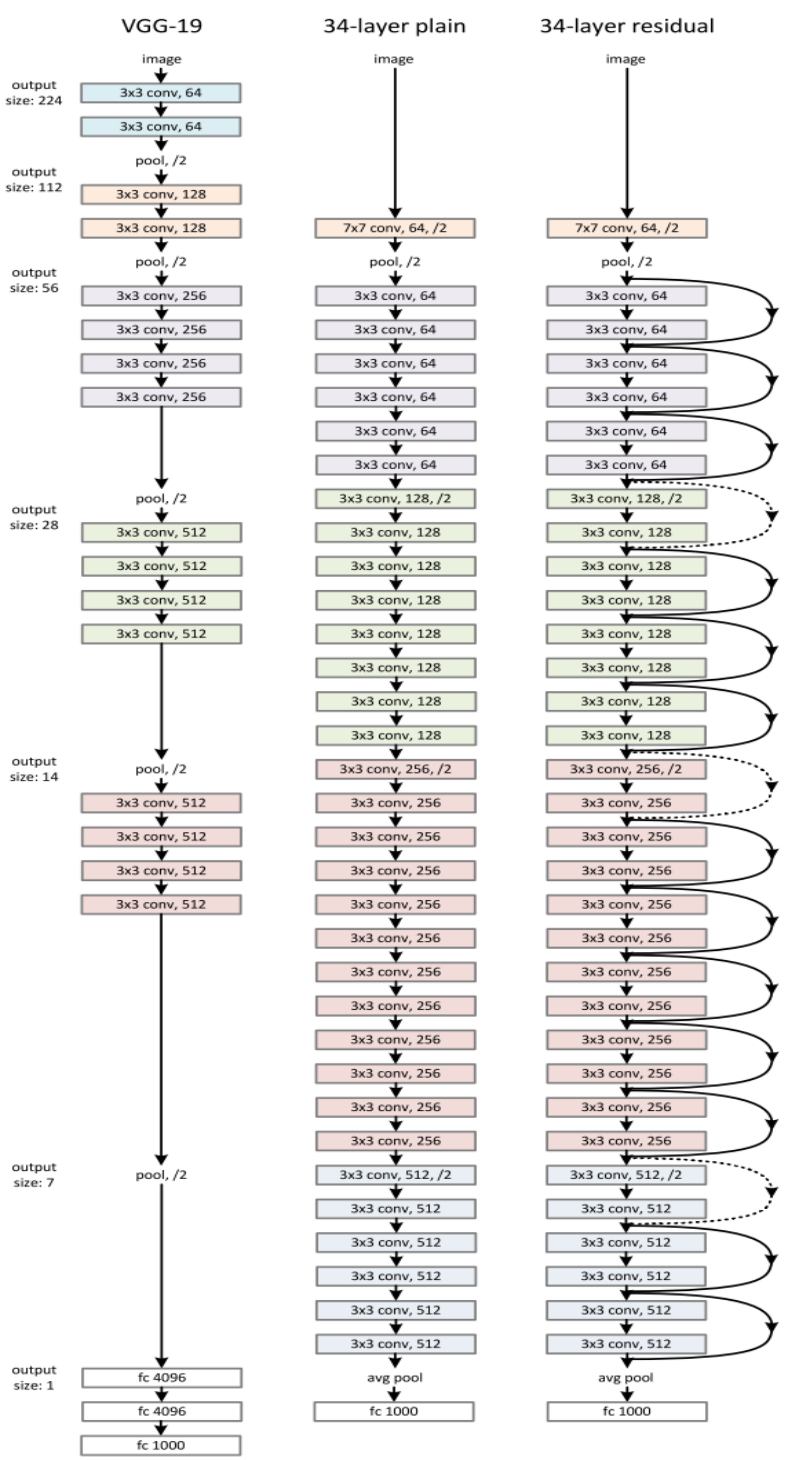
ResNet的设计有如下特点:
- 与plain net相比,ResNet多了很多”旁路”,即shortcut路径,其首尾圈出的layers构成一个 Residual Block;
- ResNet中,所有的Residual Block都没有pooling层, 降采样是通过conv的stride实现的;
- 分别在conv3_1、conv4_1和conv5_1 Residual Block,降采样1倍,同时feature map数量增加1倍,如图中虚线划定的block;
- 通过Average Pooling得到最终的特征,而不是通过全连接层;
- 每个卷积层之后都紧接着BatchNorm layer,为了简化,图中并没有标出;
ResNet的特点
提出残差学习的思想:
ResNet网络模型同样具备 模块化设计,结构非常容易 修改和扩展,通过调整block内的channel数量以及堆叠的block数量,就可以很容易地调整网络的 宽度和深度,来得到不同表达能力的网络,而不用过多地担心 网络的”退化”问题,只要训练数据足够,逐步加深网络,就可以获得更好的性能表现。同时,简化学习目标和难度。
二、ResNet代码实现
特别说明:笔者以下代码都是基于Pytorch实现的,如若需要其他框架下的代码,可以私聊笔者,笔者无偿提供。
mode.py
import torch.nn as nn
import torch
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_channel, out_channel, stride=1, downsample=None, **kwargs):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel,
kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channel)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel,
kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channel)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out += identity
out = self.relu(out)
return out
class Bottleneck(nn.Module):
"""
注意:原论文中,在虚线残差结构的主分支上,第一个1x1卷积层的步距是2,第二个3x3卷积层步距是1。
但在pytorch官方实现过程中是第一个1x1卷积层的步距是1,第二个3x3卷积层步距是2,
这么做的好处是能够在top1上提升大概0.5%的准确率。
可参考Resnet v1.5 https://ngc.nvidia.com/catalog/model-scripts/nvidia:resnet_50_v1_5_for_pytorch
"""
expansion = 4
def __init__(self, in_channel, out_channel, stride=1, downsample=None,
groups=1, width_per_group=64):
super(Bottleneck, self).__init__()
width = int(out_channel * (width_per_group / 64.)) * groups
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=width,
kernel_size=1, stride=1, bias=False) # squeeze channels
self.bn1 = nn.BatchNorm2d(width)
# -----------------------------------------
self.conv2 = nn.Conv2d(in_channels=width, out_channels=width, groups=groups,
kernel_size=3, stride=stride, bias=False, padding=1)
self.bn2 = nn.BatchNorm2d(width)
# -----------------------------------------
self.conv3 = nn.Conv2d(in_channels=width, out_channels=out_channel*self.expansion,
kernel_size=1, stride=1, bias=False) # unsqueeze channels
self.bn3 = nn.BatchNorm2d(out_channel*self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out += identity
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self,
block,
blocks_num,
num_classes=1000,
include_top=True,
groups=1,
width_per_group=64):
super(ResNet, self).__init__()
self.include_top = include_top
self.in_channel = 64
self.groups = groups
self.width_per_group = width_per_group
self.conv1 = nn.Conv2d(3, self.in_channel, kernel_size=7, stride=2,
padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(self.in_channel)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, blocks_num[0])
self.layer2 = self._make_layer(block, 128, blocks_num[1], stride=2)
self.layer3 = self._make_layer(block, 256, blocks_num[2], stride=2)
self.layer4 = self._make_layer(block, 512, blocks_num[3], stride=2)
if self.include_top:
self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) # output size = (1, 1)
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
def _make_layer(self, block, channel, block_num, stride=1):
downsample = None
if stride != 1 or self.in_channel != channel * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.in_channel, channel * block.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(channel * block.expansion))
layers = []
layers.append(block(self.in_channel,
channel,
downsample=downsample,
stride=stride,
groups=self.groups,
width_per_group=self.width_per_group))
self.in_channel = channel * block.expansion
for _ in range(1, block_num):
layers.append(block(self.in_channel,
channel,
groups=self.groups,
width_per_group=self.width_per_group))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
if self.include_top:
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def resnet34(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnet34-333f7ec4.pth
return ResNet(BasicBlock, [3, 4, 6, 3], num_classes=num_classes, include_top=include_top)
def resnet50(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnet50-19c8e357.pth
return ResNet(Bottleneck, [3, 4, 6, 3], num_classes=num_classes, include_top=include_top)
def resnet101(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnet101-5d3b4d8f.pth
return ResNet(Bottleneck, [3, 4, 23, 3], num_classes=num_classes, include_top=include_top)
def resnext50_32x4d(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnext50_32x4d-7cdf4587.pth
groups = 32
width_per_group = 4
return ResNet(Bottleneck, [3, 4, 6, 3],
num_classes=num_classes,
include_top=include_top,
groups=groups,
width_per_group=width_per_group)
def resnext101_32x8d(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnext101_32x8d-8ba56ff5.pth
groups = 32
width_per_group = 8
return ResNet(Bottleneck, [3, 4, 23, 3],
num_classes=num_classes,
include_top=include_top,
groups=groups,
width_per_group=width_per_group)
这部分的网络模型提供了 多级别的ResNet模型,读者朋友可以根据自己的需要去更改,这里默认选用最经典的 ResNet34模型。代码语义可以查看注释,如有疑问欢迎留言!
train.py
import os
import sys
import json
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import transforms, datasets
from tqdm import tqdm
from model import resnet34
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {} device.".format(device))
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),
"val": transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])}
data_root = os.path.abspath(os.path.join(os.getcwd(), "./")) # get data root path
image_path = os.path.join(data_root, "data_set", "flower_data") # flower data set path
assert os.path.exists(image_path), "{} path does not exist.".format(image_path)
train_dataset = datasets.ImageFolder(root=os.path.join(image_path, "train"),
transform=data_transform["train"])
train_num = len(train_dataset)
# {'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4}
flower_list = train_dataset.class_to_idx
cla_dict = dict((val, key) for key, val in flower_list.items())
# write dict into json file
json_str = json.dumps(cla_dict, indent=4)
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
batch_size = 16
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers
print('Using {} dataloader workers every process'.format(nw))
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size, shuffle=True,
num_workers=nw)
validate_dataset = datasets.ImageFolder(root=os.path.join(image_path, "val"),
transform=data_transform["val"])
val_num = len(validate_dataset)
validate_loader = torch.utils.data.DataLoader(validate_dataset,
batch_size=batch_size, shuffle=False,
num_workers=nw)
print("using {} images for training, {} images for validation.".format(train_num,
val_num))
net = resnet34()
# load pretrain weights
# download url: https://download.pytorch.org/models/resnet34-333f7ec4.pth
model_weight_path = "./resnet34-pre.pth"
assert os.path.exists(model_weight_path), "file {} does not exist.".format(model_weight_path)
net.load_state_dict(torch.load(model_weight_path, map_location='cpu'))
# for param in net.parameters():
# param.requires_grad = False
# change fc layer structure
in_channel = net.fc.in_features
net.fc = nn.Linear(in_channel, 5)
net.to(device)
# define loss function
loss_function = nn.CrossEntropyLoss()
# construct an optimizer
params = [p for p in net.parameters() if p.requires_grad]
optimizer = optim.Adam(params, lr=0.0001)
epochs = 3
best_acc = 0.0
save_path = './resNet34.pth'
train_steps = len(train_loader)
for epoch in range(epochs):
# train
net.train()
running_loss = 0.0
train_bar = tqdm(train_loader, file=sys.stdout)
for step, data in enumerate(train_bar):
images, labels = data
optimizer.zero_grad()
logits = net(images.to(device))
loss = loss_function(logits, labels.to(device))
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1,
epochs,
loss)
# validate
net.eval()
acc = 0.0 # accumulate accurate number / epoch
with torch.no_grad():
val_bar = tqdm(validate_loader, file=sys.stdout)
for val_data in val_bar:
val_images, val_labels = val_data
outputs = net(val_images.to(device))
# loss = loss_function(outputs, test_labels)
predict_y = torch.max(outputs, dim=1)[1]
acc += torch.eq(predict_y, val_labels.to(device)).sum().item()
val_bar.desc = "valid epoch[{}/{}]".format(epoch + 1,
epochs)
val_accurate = acc / val_num
print('[epoch %d] train_loss: %.3f val_accuracy: %.3f' %
(epoch + 1, running_loss / train_steps, val_accurate))
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net.state_dict(), save_path)
print('Finished Training')
if __name__ == '__main__':
main()
权重训练文件,本实验选取了较为 经典入门的花类识别,同时方便与之前经典的神经网络模型的识别效果进行对比。
predict.py
import os
import json
import torch
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
from model import resnet34
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
data_transform = transforms.Compose(
[transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
# load image
img_path = "./1.png"
assert os.path.exists(img_path), "file: '{}' dose not exist.".format(img_path)
img = Image.open(img_path)
plt.imshow(img)
# [N, C, H, W]
img = data_transform(img)
# expand batch dimension
img = torch.unsqueeze(img, dim=0)
# read class_indict
json_path = './class_indices.json'
assert os.path.exists(json_path), "file: '{}' dose not exist.".format(json_path)
with open(json_path, "r") as f:
class_indict = json.load(f)
# create model
model = resnet34(num_classes=5).to(device)
# load model weights
weights_path = "./resNet34.pth"
assert os.path.exists(weights_path), "file: '{}' dose not exist.".format(weights_path)
model.load_state_dict(torch.load(weights_path, map_location=device))
# prediction
model.eval()
with torch.no_grad():
# predict class
output = torch.squeeze(model(img.to(device))).cpu()
predict = torch.softmax(output, dim=0)
predict_cla = torch.argmax(predict).numpy()
print_res = "class: {} prob: {:.3}".format(class_indict[str(predict_cla)],
predict[predict_cla].numpy())
plt.title(print_res)
for i in range(len(predict)):
print("class: {:10} prob: {:.3}".format(class_indict[str(i)],
predict[i].numpy()))
plt.show()
if __name__ == '__main__':
main()
预测函数,用于对图片的识别。
预测结果:
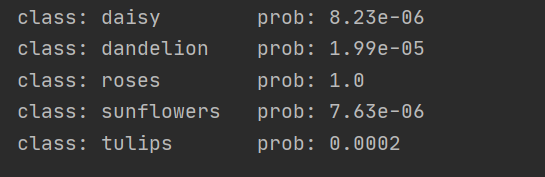

总结:
从预测结构对rose图片的计算可能性就可以看出,ResNet拥有着极高的识别精度与效果。
ResNet残差神经网络模型是由华人何凯明博士提出的史诗级巨作,它的是深度学习领域的一个 里程碑。 残差块的提出帮助了超深度神经网络模型的出现,解决了神经网络 “退化”现象。 残差块这一模块为后续很多 神经网络模型以及 yolo目标检测模型所完美继承。可以说,ResNet的出现是深度学习领域史诗级向前一步走。
Original: https://blog.csdn.net/black_sneak/article/details/125571024
Author: 混分巨兽龙某某
Title: 手把手搭建经典神经网络系列(4)——ResNet
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/519925/
转载文章受原作者版权保护。转载请注明原作者出处!