

前言
map是Mean Average Precision的缩写,翻译过来是平均精度的平均。有点绕啊,在理解map之前,先问个为什么要引入map,在分类任务中,常使用精确率和召回率作为评价指标,也称查准率和查全率,这是一个简单直接的统计量。目标检测任务稍有不同的是,即使目标检测器检测到猫和狗,没有定位,这也是没有用的。所以我们评价这个目标检测器的性能,不仅要评价它检测的对不对,还要评价它定位的准确性,这里就引入了map这个指标。
map最早出现在 信息检索系统,引入AP是为了衡量相关条目出现在不同位置时搜索结果的差异性。对于目标检测来说,其GT数量不定(一张图片可能有多类多个label),网络输出也不确定(经过NMS输出数量可能大不相同),在这种情况下如何去评价检测模型的性能?肯定不能用分类问题的Accuracy,最直观的想法就是 计算PR曲线。
map的定义
经过一系列的训练过后,怎么才能判断我们目标检测训练模型的效果呢,首先我们要有 包含标签的验证集,没有标签就没办法评价;其次知道目标检测任务是用来干嘛的,如在植物大战僵尸中,坚果+地雷是绝佳配合。


但是坚果要放在地雷前面才有效果,我们需要检测地雷和坚果以及两者的位置。如下图。
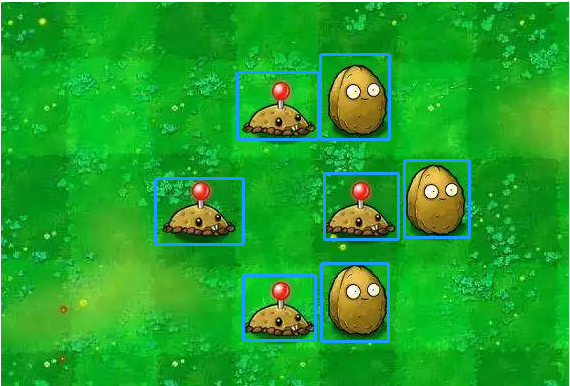
评价目标模型的效果,是要评价出检测的准确性。预测框有三个信息: 位置、类别、对应类别的置信度,首先ap计算是分类别计算的,先抽出某一类别的预测框和gt框,分两步:第一步 预测框与gt框的匹配,第二步进行 相关precision 、recall以及ap的计算。
; 1.预测框与gt框的匹配
假设预测出的框如下(红色),先做 单一类别的ap计算,抽出坚果的预测框(红色1,2,3,4, 5,6,7)和坚果的真实框。
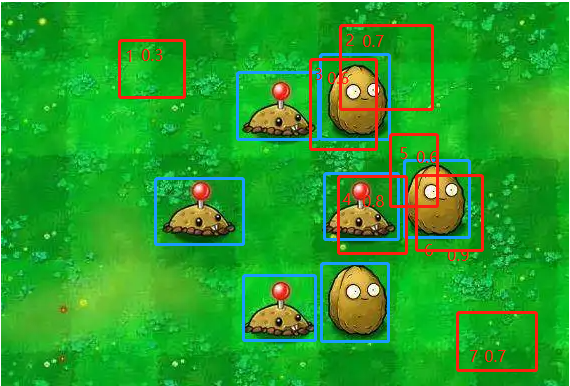
框完全重合,但是考虑实际中像素级偏差可以忽略,人工标注gt的偏差,很难完全重合,这里使用的是 IOU,两个框的交并比,关于IOU的理解可以参见这篇,当然也可以将IOU换成IOU系列的G-IOU,D-IOU等,这样的话就不是单纯的map了,不过可以试试用于自己项目中的评价图片。
先计算各预测框与gt框的IOU值,设IOU阈值为0.5,则过滤掉1、2、4和7框,1,5,7框因为IOU小于阈值,4框虽然和地刺的gt框重合,但是他检测的类别是坚果的,也是不行的,3,5和6均满足IOU值,一个gt只能匹配到一个预测框(主要用于后面计算recall),在一般的目标检测过程中,会先通过nms将预测框过滤掉后再计算map, 这里假设没有过滤完全,取score高的作为匹配框。则3和6框为匹配到的预测框。
匹配完坚果,以同样的方式匹配到地刺。
2. 指标计算
这里先了解下混淆矩阵,这块有点绕,对目标检测来说:

P和N是对应预测框被预测成正样本还是负样本,T和F是预测框预测的对不对,是否被正确的分类,
目标检测中,训练时通过人为定义正负样本,去让模型学习哪些是目标,哪些是背景,如与gt的IOU值高于阈值的图像区域为正样本,小于阈值的图像区域为负样本,有正负样本之分(TN)。在验证测试时,输入是整张图像,只有gt对应的真实正样本,没有真实负样本。先通过置信度阈值来区分预测框为预测正样本还是预测负样本,再对预测为正样本的框,判断是否预测正确。
所有大于置信度阈值的框均为预测 正样本(P), 与gt的iou高于iou阈值的为TP,反之为FP。没有预测出来的框都是N,目标检测一般不区分TN和FN。因为目标检测预测对应的框为背景是正确的似乎也没多大意义。因此,目标检测中,一般不考虑TN。
对于坚果类别:
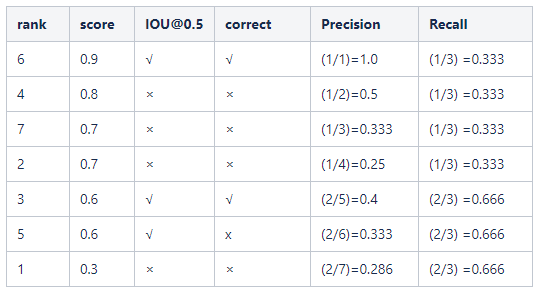
True Positive (TP): 真的正样本,实际为正样本,检测为正样本,目标检测上是IOU>=阈值的检测框,这里的3和6框
False Positive (FP): 假的正样本,实际为负样本,检测为正样本,目标检测上: IOU
; 3. ap 的计算
如何计算每 个类别的ap呢,首先 ap的定义是PR曲线围成的面积,所以我们需要先求PR曲线,对于PR曲线的采样点,voc10前后有两种不同的方式,voc08只选取Recall >= 0, 0.1, 0.2, …, 1共11个点时的Precision最大值,然后AP就是这11个Precision的平均值,称为 Interplolated AP。如我们上面预测的坚果:
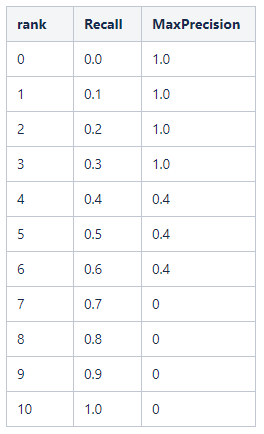
在voc10年之后,按照score值从上往下排列,对应的准确率和召回率如下:这里需要注意rank5这个框虽然是score和IOU均满足,但是它因为和6框同属于预测同一个gt框,所以按照score值的大小,将其定义成负样本。
根据上述的 PR列表,画图如下:
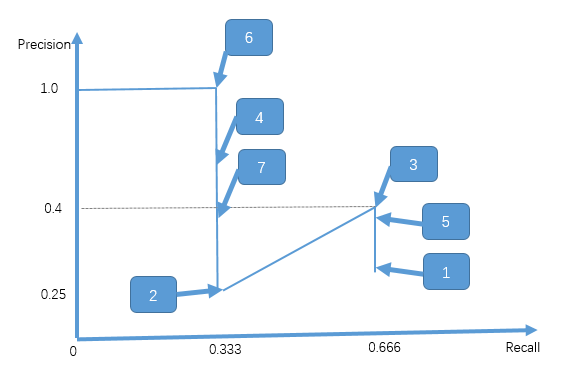
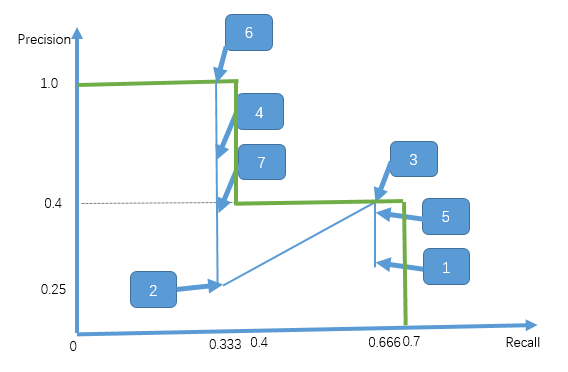
ap为PR曲线下围城的面积:
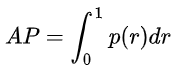
10.333+(0.25+0.4)0.333/2 =0.441
voc08是如下这样的图:
ap为:(4 _1+3_0.4)/11=0.472,两者之间相差3个点,voc08计算ap时简单粗暴,但是有精度上的损失,特别是对样本稀疏的情况下。所以这种方法在2009年的Pascalvoc之后便不再采用了。在Pascal voc 2010之后,便开始采用第一种精度更高的方式。
4. map 计算
在计算完 每个类别的ap后,对于整个数据集的 map,采用对各类别ap的平均值,这里面有人考虑对整个数据的计算(GT, TP,FP)后,获得整个数据集的ap作为map,这里实际上是不合理的。
举个例子,数据集有A、B两个类,样本量分别占90%、10%;有两个待评估模型①和②,
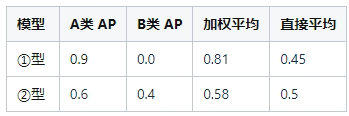
如果选”加权平均”则会认为①更好,但是①在少数类(B类)的表现太差,所以还是②更好,所以类别的直接平均作为map是合理的。
同时在 coco数据集上,使用的也是 Interplolated AP的计算方式[1]。与Voc 2008不同的是,为了提高精度,在PR曲线上采样了 101个点进行计算,
recall = 0.00, 0.01, 0.02 , ⋯, 1.00 时对应的最大precision值,然后计算这101个值得平均值,就得到了该验证集上某类的ap值。
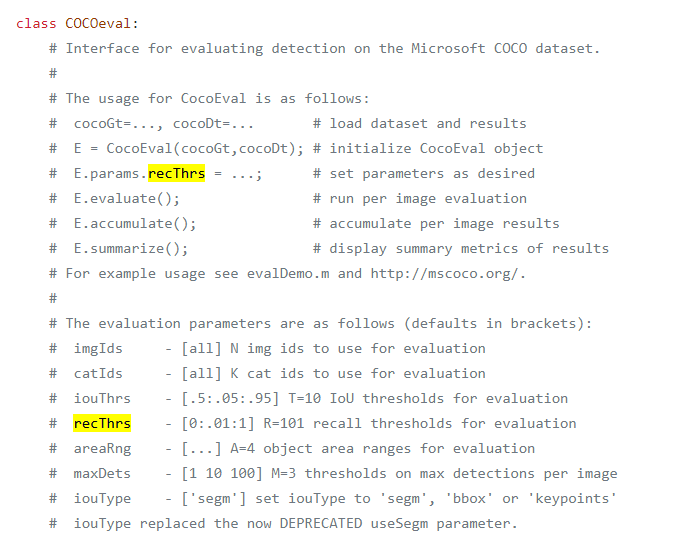
在coco官网上,对map有以下几个评价指标:
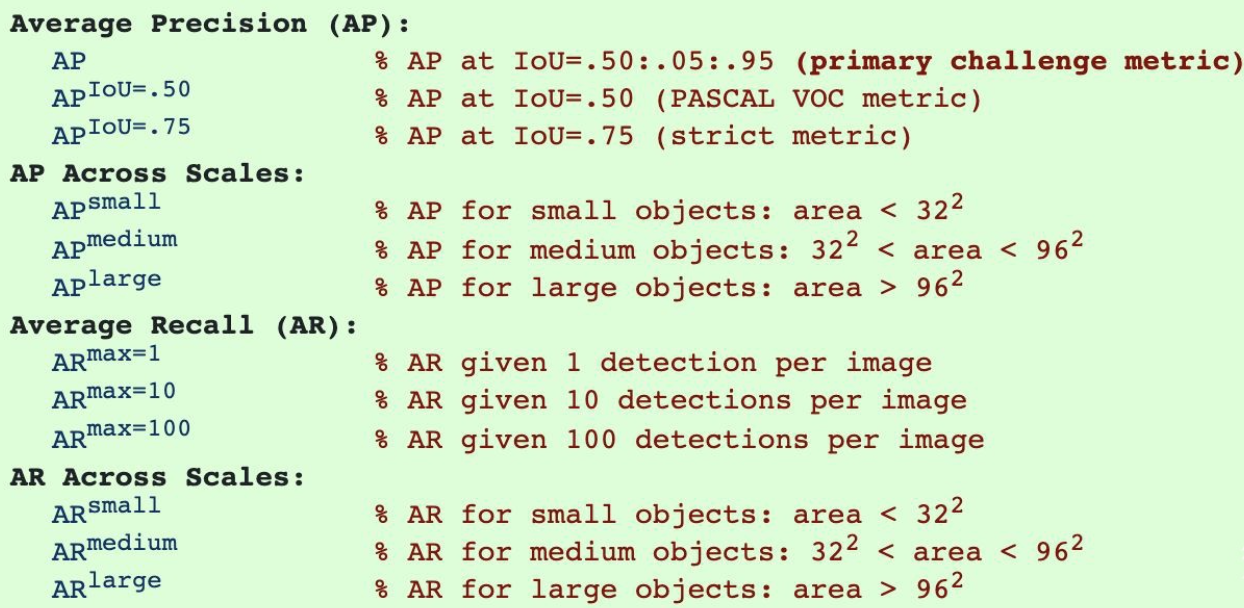
第一个map为Iou的阈值从固定的0.5调整为在 0.5 – 0.95 的区间上每隔0.5计算一次AP的值,取所有结果的平均值作为最终的结果。
第二个map为不同尺寸的物体的mAP。包括小物体、中等物体、大物体,后面描述了物体对应的像素值的大小。
第三为平均召回率,和AP相似,但这个不太常用。
; 3. map的实现
map的实现网上有很多实现方式,这里使用简单的方法:
sorted_ind = np.argsort(-confidence)
BB = BB[sorted_ind, :]
image_ids = [image_ids[x] for x in sorted_ind]
nd = len(image_ids)
tp = np.zeros(nd)
fp = np.zeros(nd)
for d in range(nd):
R = class_recs[image_ids[d]]
bb = BB[d, :].astype(float)
ovmax = -np.inf
BBGT = R['bbox'].astype(float)
if BBGT.size > 0:
ixmin = np.maximum(BBGT[:, 0], bb[0])
iymin = np.maximum(BBGT[:, 1], bb[1])
ixmax = np.minimum(BBGT[:, 2], bb[2])
iymax = np.minimum(BBGT[:, 3], bb[3])
iw = np.maximum(ixmax - ixmin + 1., 0.)
ih = np.maximum(iymax - iymin + 1., 0.)
inters = iw * ih
uni = ((bb[2] - bb[0] + 1.) * (bb[3] - bb[1] + 1.) +
(BBGT[:, 2] - BBGT[:, 0] + 1.) *
(BBGT[:, 3] - BBGT[:, 1] + 1.) - inters)
overlaps = inters / uni
ovmax = np.max(overlaps)
jmax = np.argmax(overlaps)
if ovmax > ovthresh:
if not R['difficult'][jmax]:
if not R['det'][jmax]:
tp[d] = 1.
R['det'][jmax] = 1
else:
fp[d] = 1.
else:
fp[d] = 1.
fp = np.cumsum(fp)
tp = np.cumsum(tp)
rec = tp / float(npos)
prec = tp / np.maximum(tp + fp, np.finfo(np.float64).eps)
最终得到一系列的precision和recall值,并且这些值是按照置信度降低排列统计的,可以认为是取不同的置信度阈值(或者rank值)得到的。然后据此可以计算AP:
def voc_ap(rec, prec, use_07_metric=False):
"""Compute VOC AP given precision and recall. If use_07_metric is true, uses
the VOC 07 11-point method (default:False).
"""
if use_07_metric:
ap = 0.
for t in np.arange(0., 1.1, 0.1):
if np.sum(rec >= t) == 0:
p = 0
else:
p = np.max(prec[rec >= t])
ap = ap + p / 11.
else:
mrec = np.concatenate(([0.], rec, [1.]))
mpre = np.concatenate(([0.], prec, [0.]))
for i in range(mpre.size - 1, 0, -1):
mpre[i - 1] = np.maximum(mpre[i - 1], mpre[i])
i = np.where(mrec[1:] != mrec[:-1])[0]
ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1])
return ap
结语
根据 mAP 的高低,我们只能较为概括地知道网络整体性能的好坏,但比较难分析问题具体在哪。举个例子:如果网络输出的框很贴合,选择合适的 Confidence 阈值时,检出和召回也较均衡,但是目标的类别判断错误较多。由于首先根据类别结果分类处理,只要类别错了,定位、检出和召回都很好,mAP 指标也不会高。但从结果观察,并不能很明确知道,问题出在类别判断上还是定位不准确上面。
mAP 指标关注的点,与实际应用时关注的点,并不完全吻合,mAP 会统计所有 Confidence 值下的 PR值,而实际使用时, 会设定一个 Confidence 阈值,低于该阈值的目标会被丢弃,这部分目标在统计 mAP 时也会有一定的贡献。部分针对比赛刷榜的涨点技巧,会关注这部分检测结果对 mAP 的影响。
所以针对具体的目标检测项目需求,map仅仅只能大概的评估模型性能,还需要其他的评价指标。
参考:
参考:
[1] https://github.com/cocodataset/cocoapi/blob/master/PythonAPI/pycocotools/cocoeval.py
[2] https://www.zhihu.com/question/53405779
[3] https://www.cnblogs.com/boligongzhu/p/15065738.html
[4] https://zhuanlan.zhihu.com/p/365840197

Original: https://blog.csdn.net/zqwwwm/article/details/124408093
Author: 所向披靡的张大刀
Title: 从零讲解目标检测的评价指标map及实现
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/519871/
转载文章受原作者版权保护。转载请注明原作者出处!