

StyleGAN 架构解读(重读StyleGAN)精【1】_马鹏森的博客-CSDN博客_stylegan网络结构
StyleGAN 架构解读(重读StyleGAN)精【2】_马鹏森的博客-CSDN博客
StyleGAN 架构解读(重读StyleGAN)精【3】(总结StyleGAN1和StyleGAN2)_马鹏森的博客-CSDN博客
paper:StyleGAN versions
一、StyleGAN解决的问题
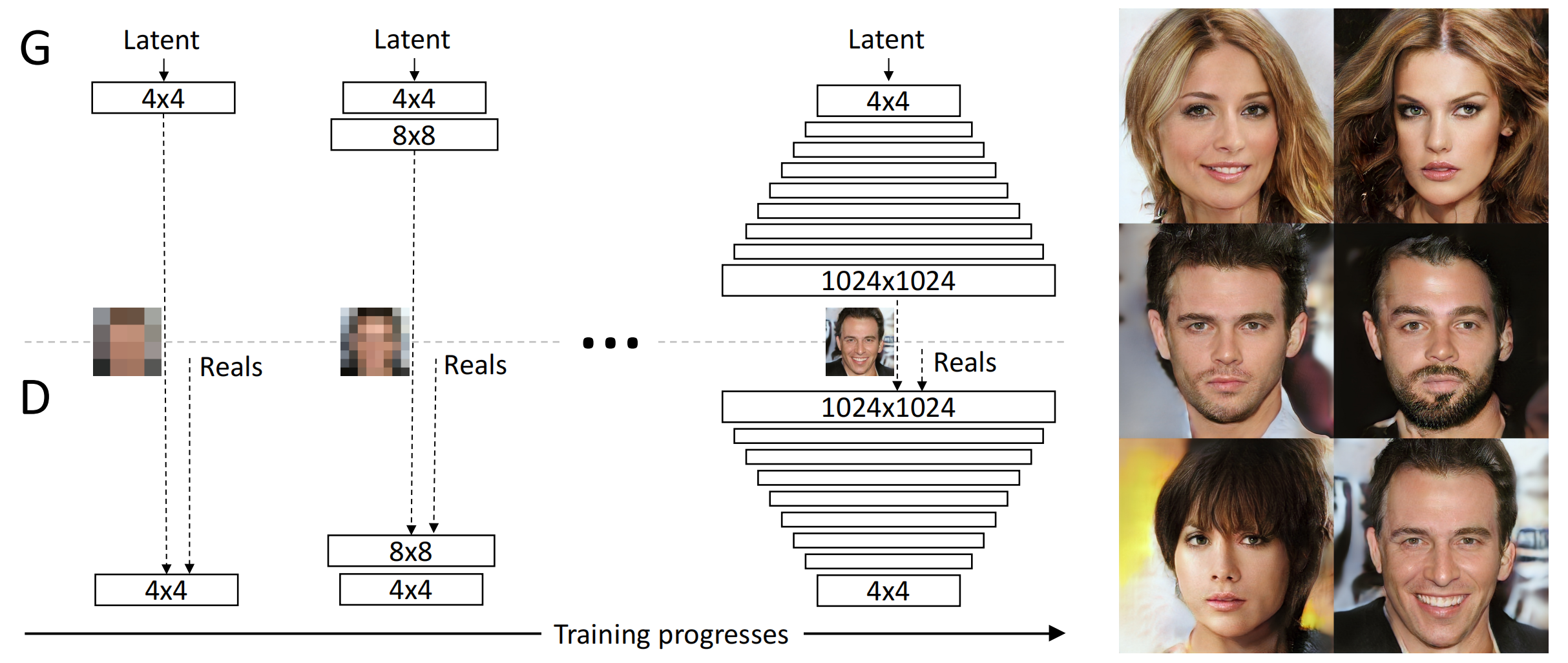

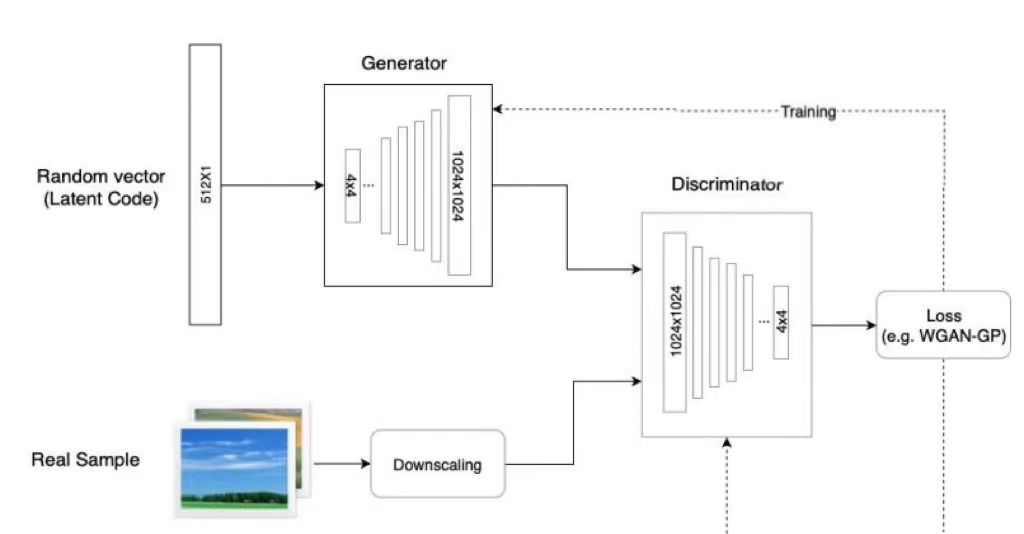
我们先来反思一下上一节介绍的 ProGAN 有什么缺陷,由于 ProGAN 是逐级直接生成图片,我们没有对其增添控制,我们也就无法获知它在每一级上学到的特征是什么,这就导致了它控制所生成图像的特定特征的能力非常有限( 即ProGAN 容易发生特征纠缠,则使用下面的映射网络Mapping Network)。换句话说,这些特性是互相关联的,因此尝试调整一下输入,即使是一点儿,通常也会同时影响多个特性。
我们希望有一种更好的模型,能让我们控制住输出的图片是长什么样的(例如:眼睛、嘴巴、鼻子…),也就是在生成图片过程中每一级的特征,要能够特定决定生成图片某些方面的表象,并且相互间的影响尽可能小。于是,在 ProGAN 的基础上,StyleGAN 作出了进一步的改进与提升。
★ StyleGAN 算法总体预览
StyleGAN 用风格(style)来影响人脸的姿态、身份特征等,用噪声 ( noise ) 来影响头发丝、皱纹、肤色等细节部分。
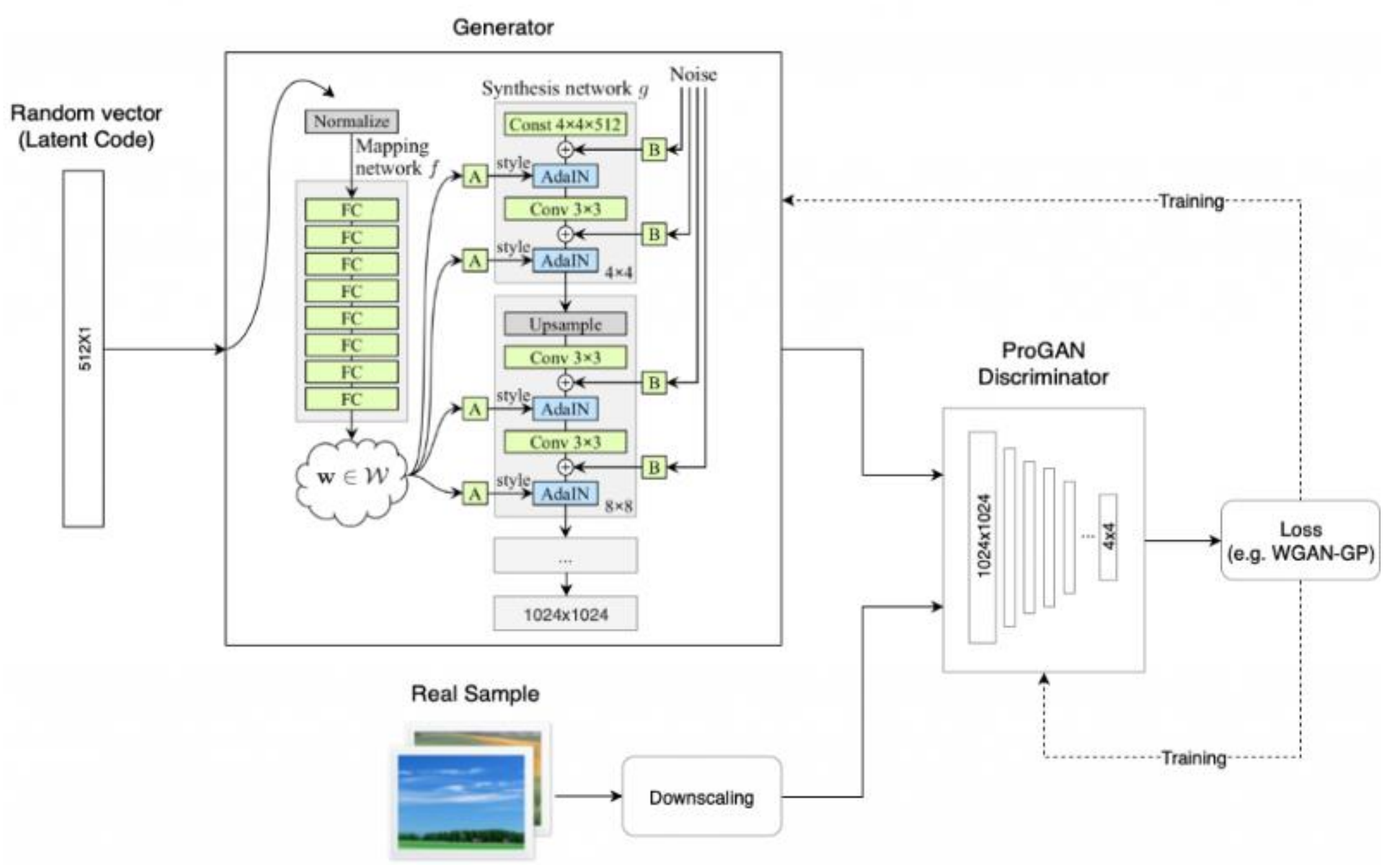
StyleGAN 的网络结构包含两个部分,第一个是 Mapping network,即下图 (b)中的左部分,由隐藏变量 z 生成 中间隐藏变量 w的过程,这个 w 就是用来控制生成图像的style,即风格,为什么要多此一举将 z 变成 w 呢,后面会详细讲到。 第二个是 Synthesis network,它的作用是生成图像,创新之处在于给每一层子网络都喂了 A 和 B, A 是由 w 转换得到的仿射变换,用于控制生成图像的风格(1.2),B 是转换后的随机噪声,用于丰富生成图像的细节,例如:雀斑、皱纹(1.4), 即每个卷积层都能根据输入的A来调整”style”,通过B来调整细节。整个网络结构还是保持了 PG-GAN (progressive growing GAN)的结构。
二、 StyleGAN 模型架构
StyleGAN 首先重点关注了 ProGAN 的生成器网络,它发现, 渐进层的一个潜在的好处是,如果使用得当,它们能够控制图像的不同视觉特征。 层和分辨率越低,它所影响的特征就越粗糙。简要将这些特征分为三种类型:
1、粗糙的——分辨率不超过 8^2,影响姿势、一般发型、面部形状等;
2、中等的——分辨率为 16^2 至 32^2,影响更精细的面部特征、发型、眼睛的睁开或是闭合等;
3、高质的——分辨率为 64^2 到 1024^2,影响颜色(眼睛、头发和皮肤)和微观特征;
然后,StyleGAN 就在 ProGAN 的生成器的基础上增添了很多附加模块。
1.1 映射网络(改进点1:加入了 Mapping Network )
Mapping network 要做的事就是对隐藏空间(latent space)进行解耦
首先理解latent code :
latent code 简单理解就是:为了更好的对数据进行分类或生成,需要对数据的特征进行表示,但是数据有很多特征,这些特征之间相互关联,耦合性较高,导致模型很难弄清楚它们之间的关联,使得学习效率低下,因此需要寻找到这些 表面特征之下隐藏的深层次的关系,将这些关系进行解耦,得到的隐藏特征,即latent code。由 latent code组成的空间就是 latent space。
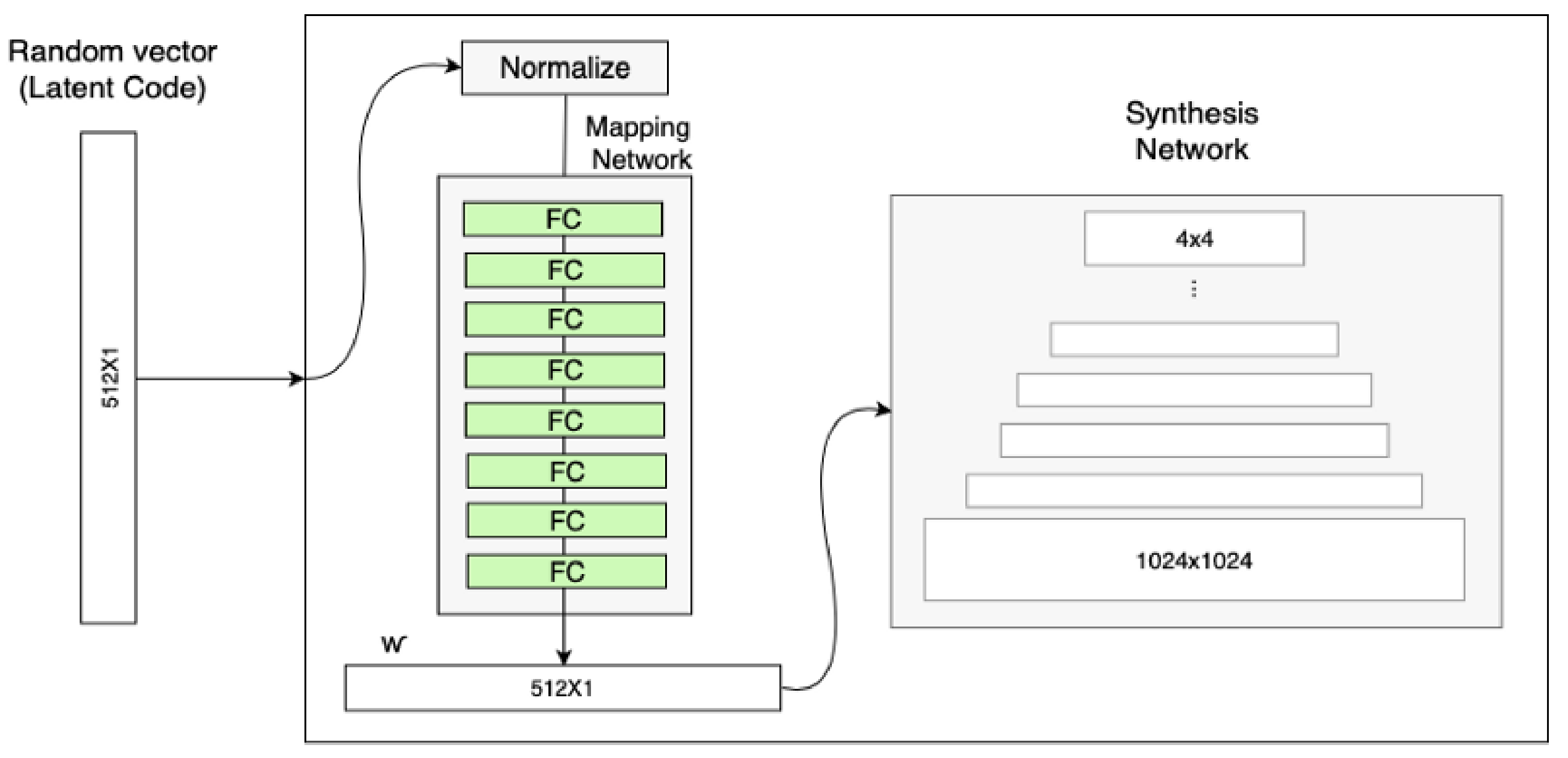
StyleGAN的第一点改进是,给Generator的输入加上了由8个全连接层组成的Mapping Network,并且 Mapping Network 的输出 W’ 与输入层(512×1)的大小相同。
添加 Mapping Network 的目标是将输入向量编码为中间向量,并且中间向量后续会传给生成网络得到 18 个控制向量(为什么18个? 看1.2AdaIN),使得该控制向量的不同元素能够控制不同的视觉特征。为何要加 Mapping Network 呢?因为 如果不加这个 Mapping Network 的话,后续得到的 18个控制向量之间会存在特征纠缠的现象——比如说我们想调节 88 分辨率上的控制向量(假设它能控制人脸生成的角度),但是我们会发现 3232 分辨率上的控制内容(譬如肤色)也被改变了,这个就叫做特征纠缠。所以 Mapping Network 的作用就是为输入向量的特征解缠提供一条学习的通路。
★ 为何 Mapping Network 能够学习到特征解缠呢?简单来说,如果仅使用输入向量来控制视觉特征,能力是非常有限的,因此它必须遵循训练数据的概率密度。
例如,如果黑头发的人的图像在数据集中更常见,那么更多的输入值将会被映射到该特征上。因此,该模型无法将部分输入(向量中的元素)映射到特征上,这就会造成特征纠缠。然而,通过使用另一个神经网络,该模型可以生成一个不必遵循训练数据分布的向量,并且可以减少特征之间的相关性。
1.2 样式模块(AdaIN)(改进点2:加入了样式模块AdaIN )
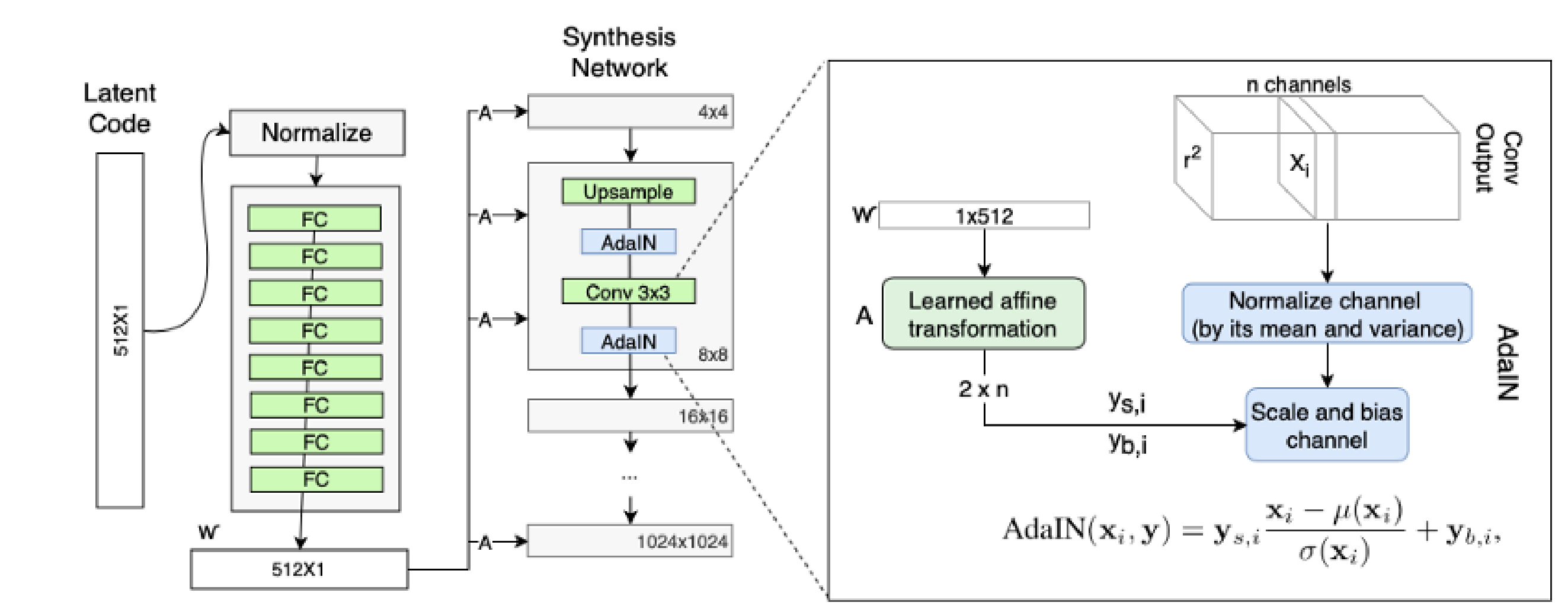
StyleGAN 的第二点改进是,将特征解缠后的中间向量𝑊′变换为样式控制向量,从而参与影响生成器的生成过程。
生成器由于从 44 ,变换到 88 ,并最终变换到 1024*1024 ,所以它由 9 个生成阶段组成,而每个阶段都会受两个控制向量(A )对其施加影响,其中一个控制向量在 Upsample之后对其影响一次,另外一个控制向量在 Convolution 之后对其影响一次,影响的方式都采用 AdaIN (自适应实例归一化)。因此,中间向量 𝑊 ′ 总共被变换成 18 个控制向量(A)传给 生成器。
其中 AdaIN 的具体实现过程如上右图所示:将 𝑊 ′通过一个可学习的仿射变换(A,实 际上是一个全连接层)扩变为放缩因子 y 𝑠,𝑖 与偏差因子 y 𝑏,𝑖,这两个因子会与标准化之后的卷积输出做一个加权求和,就完成了一次 𝑊 ′ 影响原始输出 x 𝑖的过程。而这种影响方式能够实现样式控制,主要是因为它让 𝑊 ′ (即变换后的 y 𝑠,𝑖 与 y𝑏,𝑖)影响图片的全局信息(注意标准化抹去了对图片局部信息的可见性),而保留生成人脸的关键信息由上采样层和卷积层来决定, 因此 𝑊 ′ 只能够影响到图片的样式信息。
1.3 删除传统输入(改进点3:删除了最开始进入4*4的输入A,并用常量值代替 )
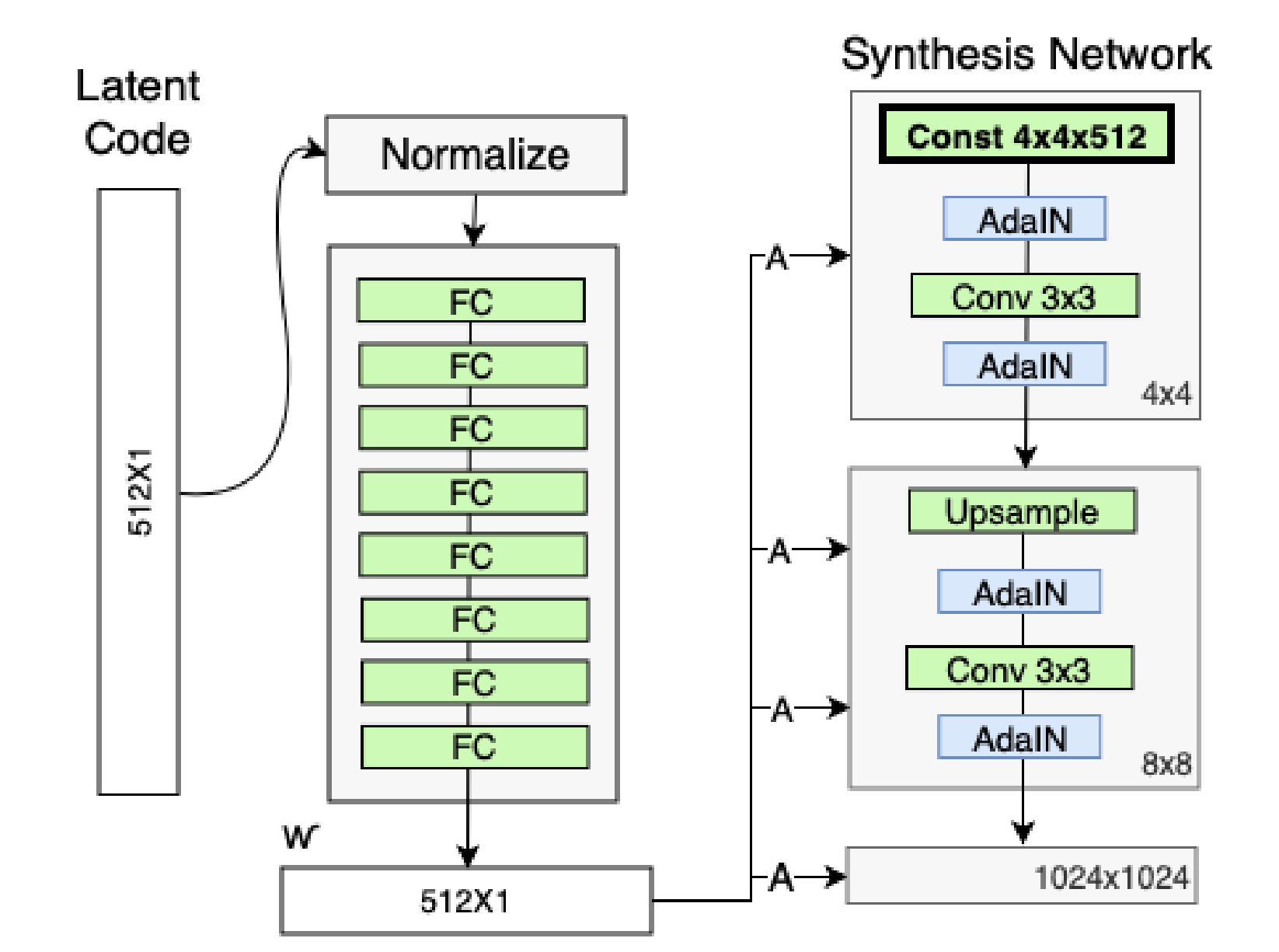
既然StyleGAN 生成图像的特征是由𝑊′和 AdaIN 控制的,那么生成器的初始输入可以被忽略,并用常量值替代。这样做的理由是,首先可以降低由于初始输入取值不当而生成出一些不正常的照片的概率(这在GANs 中非常常见),另一个好处是它有助于减少特征纠缠, 对于网络在只使用𝑊′不依赖于纠缠输入向量的情况下更容易学习。
1.4 随机变化(改进点4: 在 AdaIN 模块之前向每个通道添加一个缩放过的噪声 )
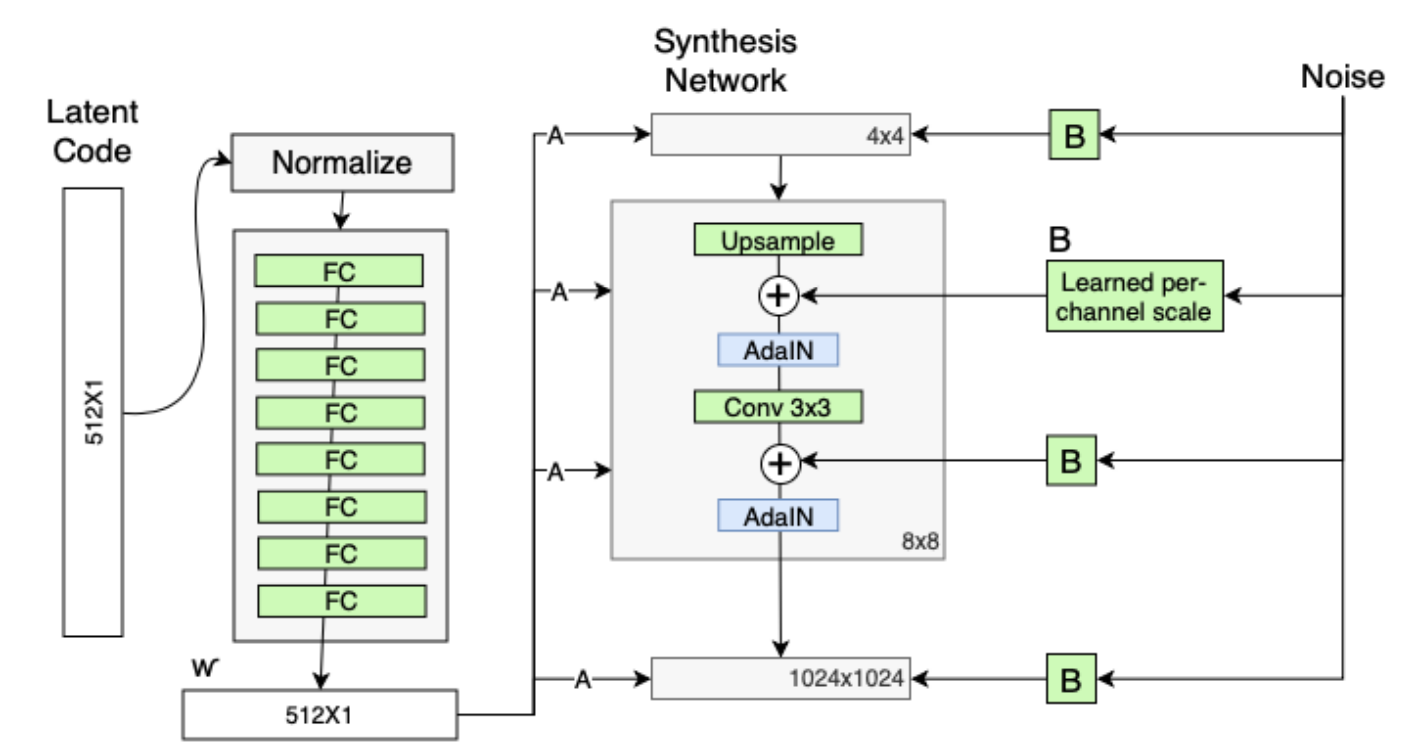
人们的脸上有许多小的特征,可以看作是随机的,例如:雀斑、发髻线的准确位置、皱纹、使图像更逼真的特征以及各种增加输出的变化。将这些小特征插入 GAN 图像的常用方法是在输入向量中添加随机噪声。为了控制噪声仅影响图片样式上细微的变化,StyleGAN 采用类似于 AdaIN 机制的方式添加噪声,即在 AdaIN 模块之前向每个通道添加一个缩放过的噪声,并稍微改变其操作的分辨率级别特征的视觉表达方式。加入噪声后的生成人脸往往更加逼真与多样。
1.5 样式混合

为了进一步明确风格控制,StyleGAN采用混合正则化手段(AdaIN),即在训练过程中使用两个随机潜码W而不仅仅是一个。在生成图像时,只需在 synthesis network 中随机选一个中间的交叉点,把一个潜码切换到另一个潜码(称为风格混合)即可。具体来说,通过Mapping Network生成两个潜码z1和z2,得到相应的W1和W2(分别代表两种不同的 style)控制风格,然后W1被用在网络所被选择的位置点之前,W2在该位置点之后使用。
StyleGAN 生成器在合成网络的每个级别中使用了中间向量,这有可能导致网络学习到这些级别是相关的。为了降低相关性,模型随机选择两个输入向量,并为它们生成了中间向量𝑊 ′ 。然后,它用第一个输入向量来训练一些网络级别,然后(在一个随机点中)切换到另 一个输入向量来训练其余的级别。随机的切换确保了网络不会学习并依赖于一个合成网络级别之间的相关性。 虽然它并不会提高所有数据集上的模型性能,但是这个概念有一个非常有趣的副作用——它能够以一种连贯的方式来组合多个图像。 该模型生成了两个图像 A 和 B(第一行的第一张图片和第二行的第一张图片),然后通过从 A 中提取低级别的特征并从 B 中提取其余特征再组合这两个图像,这样能生成出混合了 A 和 B 的样式特征的新人脸。
根据交叉点选取位置的不同,style组合的结果也不同。下图中分为三个部分,
- 第一部分是 Coarse styles from source B,分辨率(4×4 – 8×8)的网络部分使用B的style,其余使用A的style, 可以看到图像的身份特征随souce B,但是肤色等细节随source A;
- 第二部分是 Middle styles from source B,分辨率(16×16 – 32×32)的网络部分使用B的style,这个时候生成图像不再具有B的身份特性,发型、姿态等都发生改变,但是肤色依然随A;
- 第三部分 Fine from B,分辨率(64×64 – 1024×1024)的网络部分使用B的style,此时身份特征随A,肤色随B。
由此可以 大致推断, 低分辨率的style 控制姿态、脸型、配件 比如眼镜、发型等style,高分辨率的style控制肤色、头发颜色、背景色等style。
1.2.6 在 W 中的截断技巧
Truncation Trick 不是StyleGAN提出来的,它很早就在GAN里用于图像生成了。从数据分布来说,低概率密度的数据在网络中的表达能力很弱,直观理解就是,低概率密度的数据出现次数少,能影响网络梯度的机会也少,但并不代表低概率密度的数据不重要。可以提高数据分布的整体密度,把分布稀疏的数据点都聚拢到一起,类似于PCA,做法很简单,首先找到数据中的一个平均点,然后计算其他所有点到这个平均点的距离,对每个距离按照统一标准进行压缩,这样就能将数据点都聚拢了( 相当于截断了中间向量𝑊′,迫使它保持接近”平均”的中间向量𝑊′ 𝑎𝑣𝑔), 但是又不会改变点与点之间的距离关系。
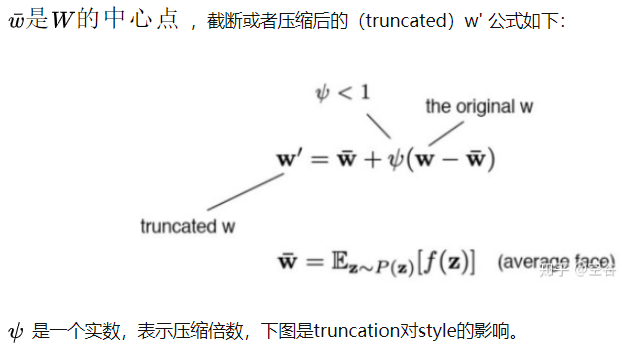

在生成模型中的一个挑战,是处理在训练数据中表现不佳的地方。这导致了生成器无法学习和创建与它们类似的图像(相反,它会创建效果不好的图像)。为了避免生成较差的图像,StyleGAN 截断了中间向量𝑊′,迫使它保持接近”平均”的中间向量(上图左 4)。
对模型进行训练之后,通过选择多个随机的输入,用映射网络生成它们的中间向量,并计算这些向量的平均值,从而生成”中间向量”的平均值 𝑊 ′ 𝑎𝑣𝑔 。当生成新的图像时,不用直接使用映射网络的输出,而是将值 𝑊 ′ 转换为 𝑊 ′ 𝑛𝑒𝑤 = 𝑊 ′ 𝑎𝑣𝑔 + 𝞧( 𝑊 ′ − 𝑊 ′ 𝑎𝑣𝑔 ) ,其中𝞧的值定义了图像与”平均”图像的差异量(以及输出的多样性)。有趣的是,在仿射转换块之前,通过对每个级别使用不同的 𝞧 ,模型可以控制每个级别上的特征值与平均特征值的差异量。
1.2.7 微调超参数
StyleGAN的另外一个改进措施是更新几个网络超参数,例如训练持续时间和损失函数, 并将图片最接近尺度的缩放方式替换为双线性采样。
综上,加入了一系列附加模块后得到的 StyleGAN 最终网络模型结构图如下(对比一下StyleGAN 和 PGGAN):
StyleGAN:
PGGAN:
reference:StyleGAN 和 StyleGAN2 的深度理解 – 知乎
Original: https://blog.csdn.net/weixin_43135178/article/details/116331140
Author: 马鹏森
Title: StyleGAN 架构解读(重读StyleGAN )精细
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/519468/
转载文章受原作者版权保护。转载请注明原作者出处!