

文章目录
- SVTR: Scene Text Recognition with Single Visual Model
- 基本信息
- 摘要
- 模型结构
* - Patch Embedding
- Mixing Block
- Combining and Prediction
- 其他细节
- 实验
- 总结
SVTR: Scene Text Recognition with Single Visual Model
基本信息
- 论文链接:arxiv
- 发表时间:2022 – IJCAI
- 应用场景:自然场景文字识别
摘要
存在什么问题解决了什么问题1. 目前自然场景文字识别的SOTA模型一般都会包含一个vision model(抽取视觉特征)和一个sequence model(用于文字转录),甚至还会带上一个language model。这些模型往往设计比较复杂,因此也导致了性能差的缺陷。1. 提出了一个仅依靠视觉特征就能够完成文字识别任务的SVTR场景文字识别模型,精度高(部分dataset达到SOTA),速度快等优点。
- 中文场景下识别任务表现出色,也达到了SOTA。
模型结构
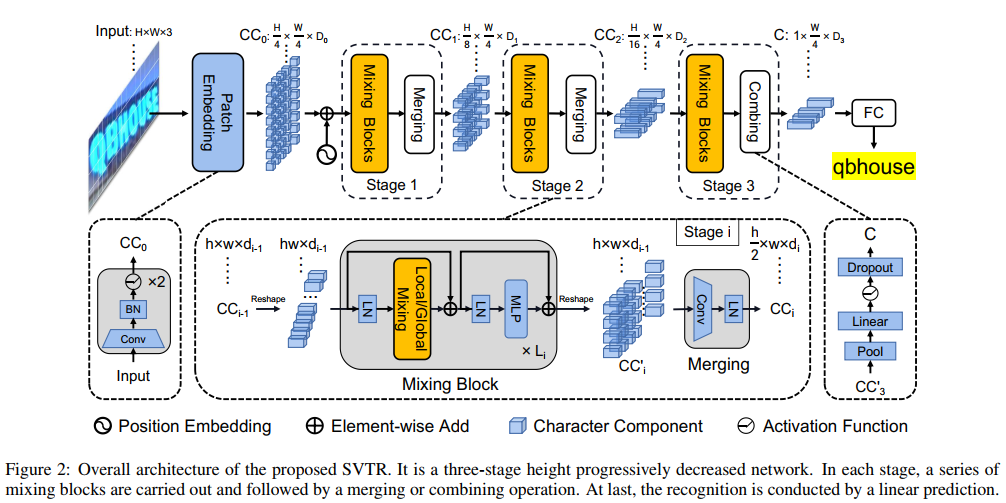

; Patch Embedding
输入图片shape=[h,w,3],patch embedding的作用是输出一个shape=[h//4,w//4,d]的patches。
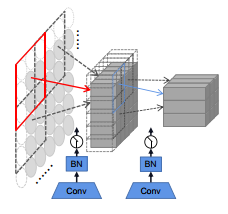
鉴于文字识别是一个细粒度任务,对图像细节的描述有一定的要求,这里作者摒弃了VIT中直接用大卷积核生成这些pathes,而采用了ResNetv1d中的stem结构来产生这些patch,比较简单,不再赘述。后面作者也做了消融实验验证了这样做是最优的。
; Mixing Block
经过Patch Embedding后shape=[h//4w//4,d],即token的长度为h//4w//4。
送入1d position embedding模块(作者用的是可学习position embedding)。
现在可以输入给transformer encoder了,并且做了一些优化,pipeline如下:
- 整体上采用 先局部特征抽取,再全局特征抽取的思想(局部特征抽取在我看来其实就是在encoder mask上做了一点点文章。。。类似于LongFormer,根据先验知识,赋予attention map上每个点人为设定的若干个特定响应点)
- 局部特征抽取(Local Mixing):attentoion map上的每个token只和其作为中心的h=7(沿query方向), w=11(沿key方向)的局部box内像素点响应,其余token全部mask掉。后面再接FFN。
- 全局特征抽取(Global Mixing):就是普通的transformer encoder(MHSA+FFN),不知道为啥还要单独取个名。
- 注意不论是Local Mixing还是Global Mixing,都会堆叠若然次构成级联后再进入mergeing模块。
- 接着就是merging模块了,先reshape成4d图像,然后做conv3x3(stride_w=1,stride_h=2)下采样操作,降低token数量为原先的1/2,且只在高度方向降采样,保留了图像宽度上的信息的完整性,融合了临近token的信息,另外由于token数量减少了,类似于卷积神经网络,此时会让channel增大,补偿丢失的信息。最后再reshap回序列。
Combining and Prediction
在完成2个完整的stage后,此时高度降采样为原先的1/16,宽度仍然保持1/4。最后的merging被替换成了pool2d(将高度变为1,宽度仍然不变)+全连接+非线性激活函数。
作者说这里不继续用merging的原因是高度此时为2(输入高度32,32/16=2),高度太小对卷积操作不太友好。所以这么做。。。
最后再接一个输出channel= 预测字符数+1的FC,用于识别,此时shape=[w//4,char_num+1]
其他细节
- 采用CTC Loss进行训练,所以输出channel=预测字符数+1。因此预测的时候也就自然的依照CTC的解码规则。
- 网络最前面有TPS变换。
实验
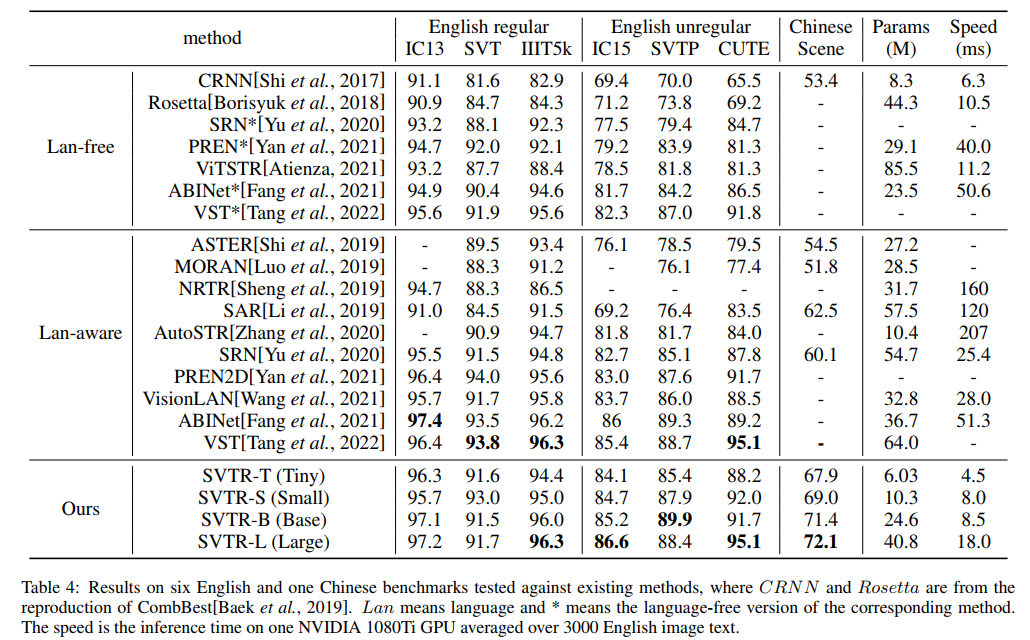
若干个benchmark上取得SOTA,小模型速度最快,大模型精度高。
PatchEmbedding上的消融实验,验证了当前方案是最好的。
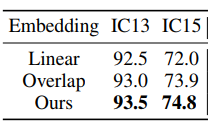
Merging上的消融实验,验证了conv不仅能够降低token数量,而且还能提升精度。
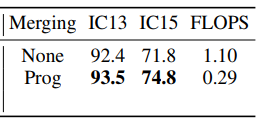
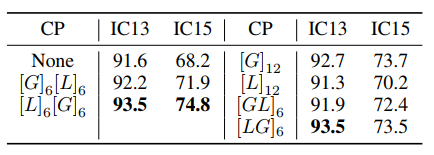
关于Local Mixing和Global Mixing如何堆叠的实验,验证了先Local重复若干次,再Global重复若干次是最优的。
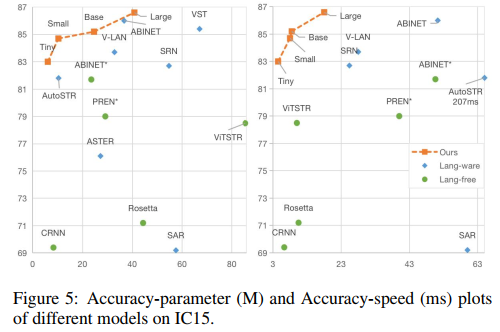
SVTR和各主流场景文字识别模型在精度和速度上的比较,SVTR差不多是当前综合来看最好的?
; 总结
- 基于VIT,提出了一个仅用单一视觉模型完成场景文字识别的方案,并且在精度和速度上取得了优秀的trade-off,若干个数据集上达到SOTA,中文场景识别效果优秀。
- 论文读下来感觉有一些失望:
- 一个transformer encoder的冷饭能讲一大堆。。。
- 7×11的window size也没有做实验,直接说了7×11是最好的,但是这个7×11和图像上我们常说的7×11可不是一回事啊。
- 最关键的STN没有做消融实验,因为模型最后将高度downsample到1了,已经变成序列,没有了2d空间特征,按常理来说对于irregular text的识别效果应该是有限的。这就不得不去怀疑是不是STN正确的矫正了图像,但是没有做实验验证呀!
- 另外贴的图还能出现标记错误也是醉了。。
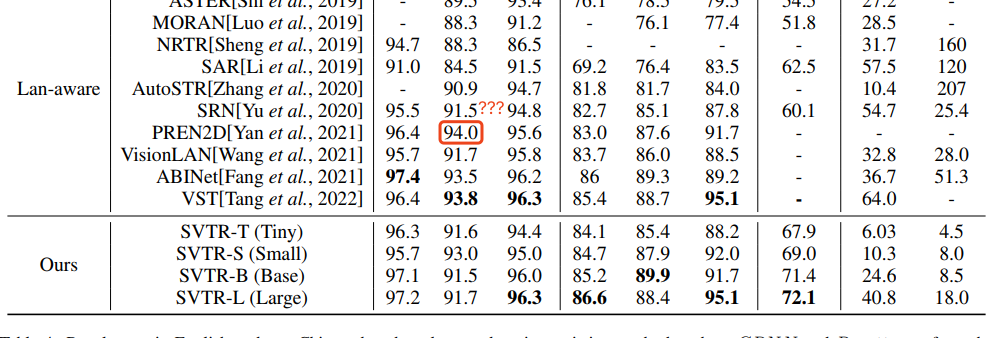
- 不过有一说一,从指标上看确实不错,能被PaddleOCR收录作为PPOCRv3的核心算法也是很厉害了。就是论文干货确实不多啊啊啊啊!
Original: https://blog.csdn.net/OneYearIsEnough/article/details/124878882
Author: 每天想peach
Title: 【论文笔记】SVTR: Scene Text Recognition with Single Visual Model
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/518957/
转载文章受原作者版权保护。转载请注明原作者出处!