
一、什么是mapreduce
组件
说明
HDFS
分布式存储系统
MapReduce
分布式计算系统
YARN
hadoop 的资源调度系统
Common
三大[HDFS,Mapreduce,Yarn]组件的底层支撑组件,
主要提供基础工具包和 RPC 框架等
Mapreduce 是一个分布式运算程序的编程框架,是用户开发”基于 hadoop 的数据分析应用”的核心框架,Mapreduce 核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的 分布式运算程序,并发运行在一个 hadoop 集群上.
二、为什么需要mapreduce
- 海量数据在单机上处理因为硬件资源限制,无法胜任
- 而一旦将单机版程序扩展到集群来分布式运行,将极大增加程序的复杂度和开发难度
- 引入 MapReduce 框架后,开发人员可以将绝大部分工作集中在业务逻辑的开发上,而将 分布式计算中的复杂性交由框架来处理
三、mapreduce程序运行实例
在 MapReduce 组件里, 官方给我们提供了一些样例程序,其中非常有名的就是 wordcount 和 pi程序。这些 MapReduce程序的代码都在hadoop-mapreduce-examples-2.6.4.jar包里,这个jar包在 hadoop安装目录下的/share/hadoop/mapreduce/目录里
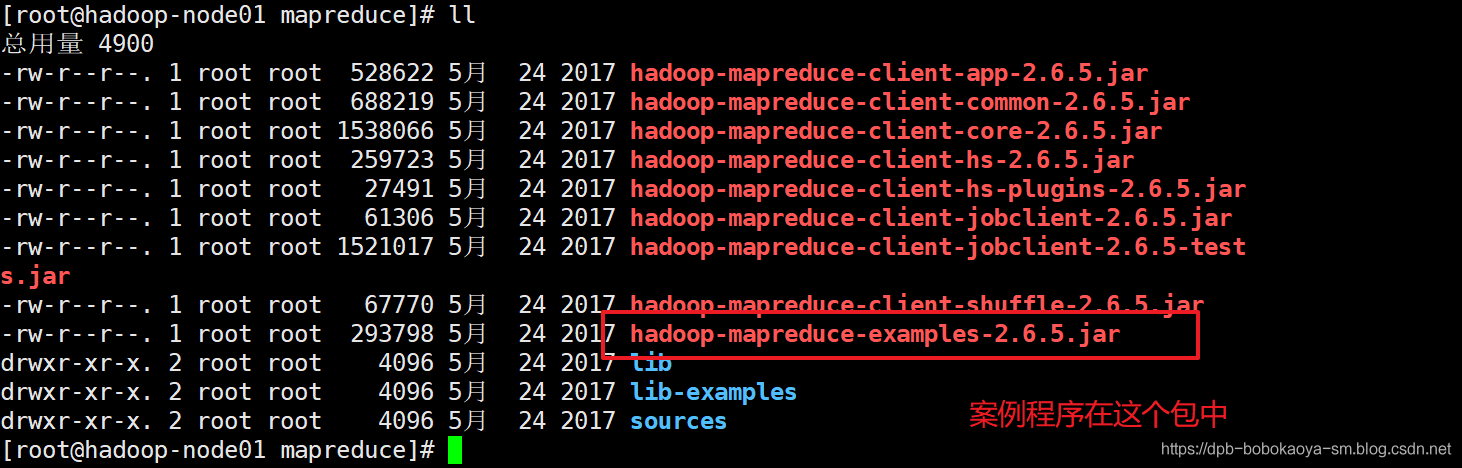

wordcount案例
执行wordcount案例来统计文件中单词出现的次数.
1.准备数据

2.HDFS中创建对应的文件夹
在hdfs中创建文件夹存储需要统计的文件,及创建输出文件的路径
hadoop fs -mkdir -p /wordcount/input hadoop fs -put a.txt /wordcount/input/

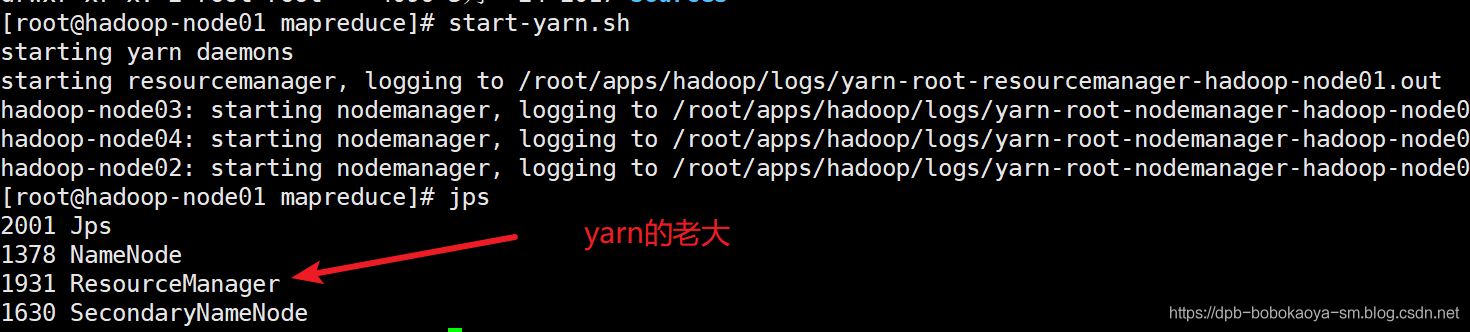
3.启动yarn
要做分布式运算必须要启动yarn
start-yarn.sh
4.执行程序
hadoop jar hadoop-mapreduce-examples-2.6.5.jar wordcount /wordcount/input/ /wordcount/output
输出
[root@hadoop-node01 mapreduce]# hadoop jar hadoop-mapreduce-examples-2.6.5.jar wordcount /wordcount/input/ /wordcount/output19/04/02 23:06:03 INFO client.RMProxy: Connecting to ResourceManager at hadoop-node01/192.168.88.61:803219/04/02 23:06:07 INFO input.FileInputFormat: Total input paths to process : 119/04/02 23:06:09 INFO mapreduce.JobSubmitter: number of splits:119/04/02 23:06:09 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1554217397936_000119/04/02 23:06:10 INFO impl.YarnClientImpl: Submitted application application_1554217397936_000119/04/02 23:06:11 INFO mapreduce.Job: The url to track the job: http://hadoop-node01:8088/proxy/application_1554217397936_0001/19/04/02 23:06:11 INFO mapreduce.Job: Running job: job_1554217397936_000119/04/02 23:06:30 INFO mapreduce.Job: Job job_1554217397936_0001 running in uber mode : false19/04/02 23:06:30 INFO mapreduce.Job: map 0% reduce 0%19/04/02 23:06:46 INFO mapreduce.Job: map 100% reduce 0%19/04/02 23:06:57 INFO mapreduce.Job: map 100% reduce 100%19/04/02 23:06:58 INFO mapreduce.Job: Job job_1554217397936_0001 completed successfully19/04/02 23:06:59 INFO mapreduce.Job: Counters: 49 File System Counters FILE: Number of bytes read=133 FILE: Number of bytes written=214969 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=240 HDFS: Number of bytes written=79 HDFS: Number of read operations=6 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 Job Counters Launched map tasks=1 Launched reduce tasks=1 Data-local map tasks=1 Total time spent by all maps in occupied slots (ms)=11386 Total time spent by all reduces in occupied slots (ms)=9511 Total time spent by all map tasks (ms)=11386 Total time spent by all reduce tasks (ms)=9511 Total vcore-milliseconds taken by all map tasks=11386 Total vcore-milliseconds taken by all reduce tasks=9511 Total megabyte-milliseconds taken by all map tasks=11659264 Total megabyte-milliseconds taken by all reduce tasks=9739264 Map-Reduce Framework Map input records=24 Map output records=27 Map output bytes=236 Map output materialized bytes=133 Input split bytes=112 Combine input records=27 Combine output records=12 Reduce input groups=12 Reduce shuffle bytes=133 Reduce input records=12 Reduce output records=12 Spilled Records=24 Shuffled Maps =1 Failed Shuffles=0 Merged Map outputs=1 GC time elapsed (ms)=338 CPU time spent (ms)=2600 Physical memory (bytes) snapshot=283582464 Virtual memory (bytes) snapshot=4125011968 Total committed heap usage (bytes)=137363456 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=128 File Output Format Counters Bytes Written=79
执行成功,查看结果

[root@hadoop-node01 mapreduce]# hadoop fs -cat /wordcount/output/part-r-000001 12 13 1a 4b 2c 1hadoop 3hdfs 2hello 2java 7mapreduce 1wordcount 2
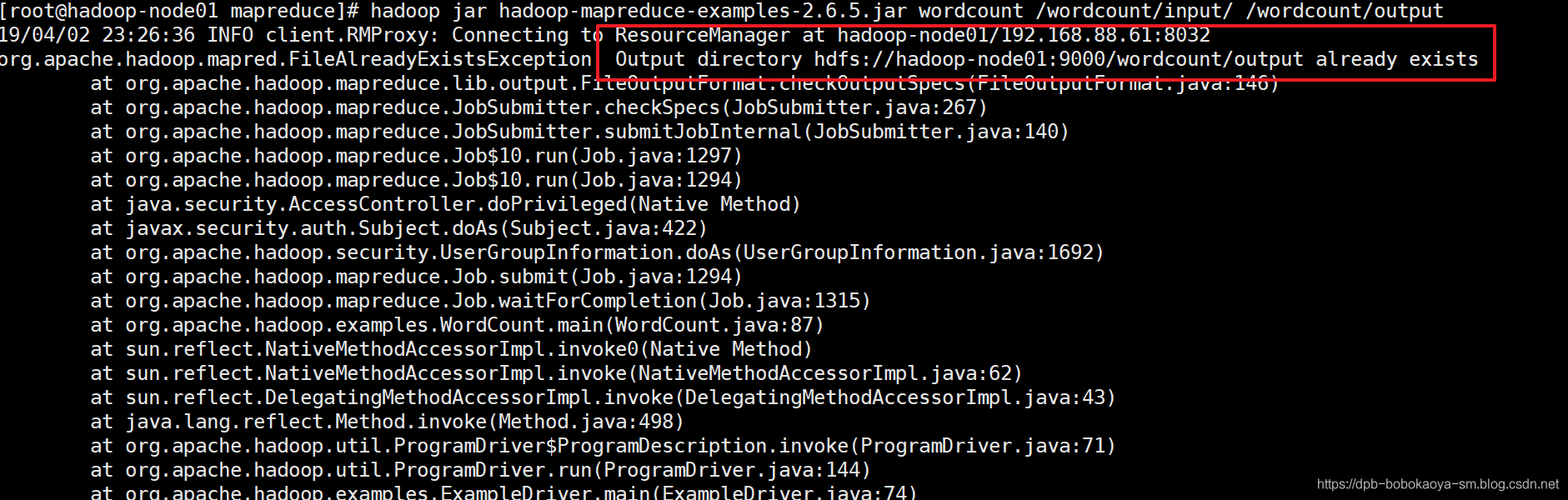
注意:输出的目录不能存在。如果存在会爆如下错误。
源码内容可以自行观看,下篇介绍手动实现wordcount案例~
Original: https://blog.51cto.com/u_15494758/5433342
Author: 波波烤鸭
Title: Hadoop之MapReduce01【自带wordcount案例】
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/516998/
转载文章受原作者版权保护。转载请注明原作者出处!