

Flink常用API之Collection的Source
原创
wx62be9d88ce294博主文章分类:大数据 ©著作权
文章标签 flink scala big data apache 文章分类 Hadoop 大数据
©著作权归作者所有:来自51CTO博客作者wx62be9d88ce294的原创作品,请联系作者获取转载授权,否则将追究法律责任
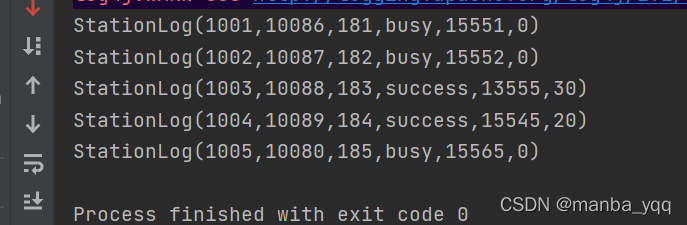
package sourceimport org.apache.flink.streaming.api.scala.StreamExecutionEnvironment case class StationLog(sid:String,callOut:String,callInput:String,callType:String,callTime:Long,duration:Long)object CollectionSource { def main(args: Array[String]): Unit = { val ev: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment ev.setParallelism(1) import org.apache.flink.streaming.api.scala._ val list: DataStream[StationLog] = ev.fromCollection(Array( new StationLog("1001", "10086", "181", "busy", 15551, 0), new StationLog("1002", "10087", "182", "busy", 15552, 0), new StationLog("1003", "10088", "183", "success", 13555, 30), new StationLog("1004", "10089", "184", "success", 15545, 20), new StationLog("1005", "10080", "185", "busy", 15565, 0) )) list.print() ev.execute("array") }}

- 赞
- 收藏
- 评论
- *举报
上一篇:Flink中Window详解之Window的聚合函数ReduceFunction
Original: https://blog.51cto.com/u_15704423/5434844
Author: wx62be9d88ce294
Title: Flink常用API之Collection的Source
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/516970/
转载文章受原作者版权保护。转载请注明原作者出处!