

Flink常用API之转换算子的Split算子
原创
wx62be9d88ce294博主文章分类:大数据 ©著作权
文章标签 flink scala big data 数据集 数据 文章分类 Hadoop 大数据
©著作权归作者所有:来自51CTO博客作者wx62be9d88ce294的原创作品,请联系作者获取转载授权,否则将追究法律责任
Split 和 select [DataStream->SplitStream->DataStream]
Split 算子是将一个 DataStream 数据集按照条件进行拆分,形成两个数据集的过程, 也是 union 算子的逆向实现。每个接入的数据都会被路由到一个或者多个输出数据集中。如 下图所示,将输入数据集根据颜色切分成两个数据集。
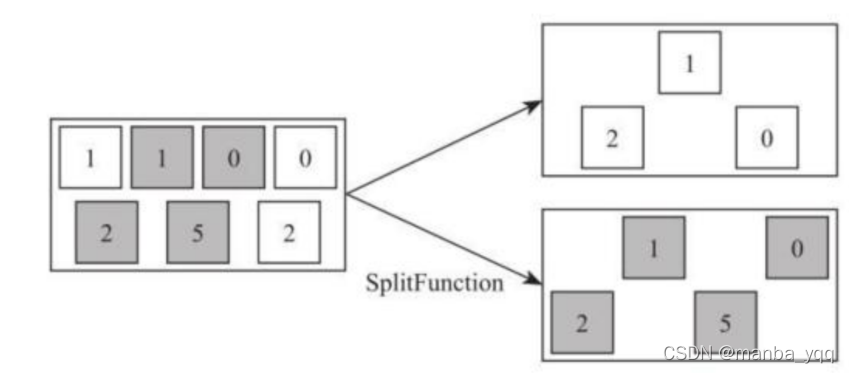

在使用 split 函数中,需要定义 split 函数中的切分逻辑,通过调用 split 函数,然后 指定条件判断函数,
package transformationimport org.apache.flink.streaming.api.scala.StreamExecutionEnvironmentimport source.{MyCustomerSource, StationLog} object Transformation02 { def main(args: Array[String]): Unit = { val en = StreamExecutionEnvironment.getExecutionEnvironment en.setParallelism(1) import org.apache.flink.streaming.api.scala._ val stream = en.addSource(new MyCustomerSource) val result: SplitStream[StationLog] = stream.split( log => { if (log.callType.equals("success")) Seq("success") else Seq("no success") } ) val stream1: DataStream[StationLog] = result.select("success") val stream2: DataStream[StationLog] = result.select("no success") stream1.print("通话成功") stream2.print("通话不成功") en.execute() }}
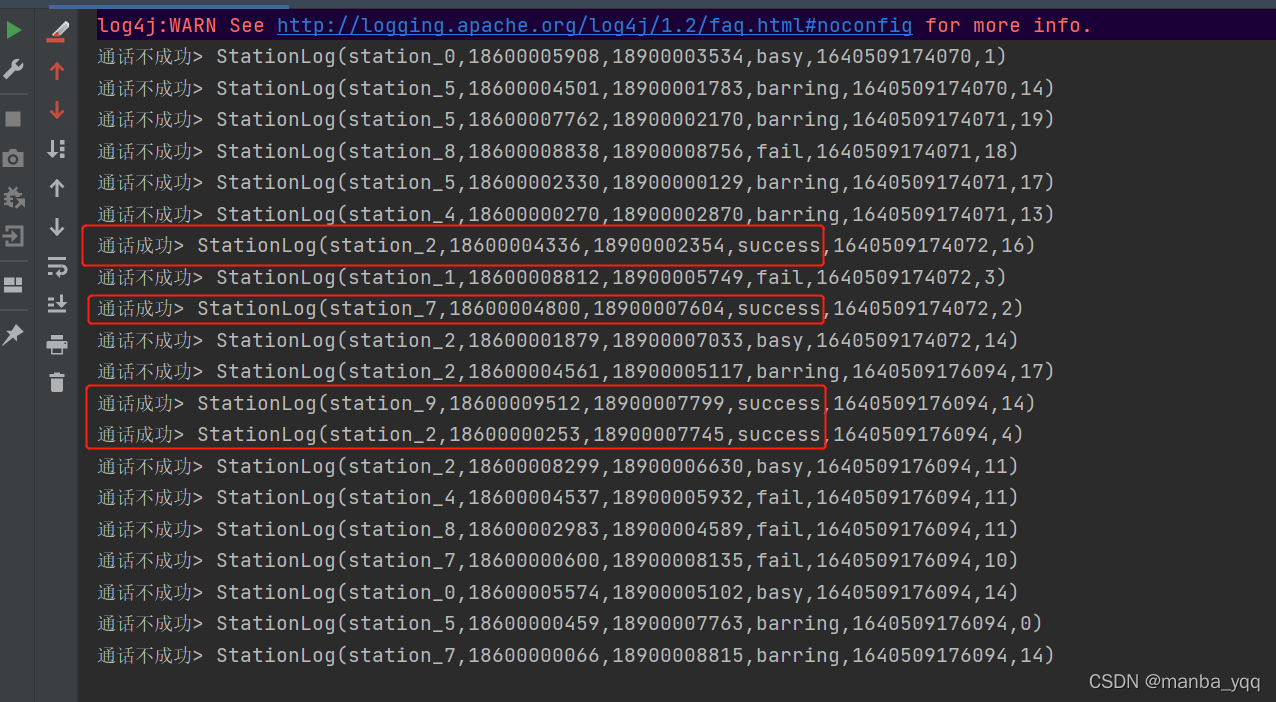
split 函数本身只是对输入数据集进行标记,并没有将数据集真正的实现切分,因此需 要借助 Select 函数根据标记将数据切分成不同的数据集。
- 赞
- 收藏
- 评论
- *举报
Original: https://blog.51cto.com/u_15704423/5434846
Author: wx62be9d88ce294
Title: Flink常用API之转换算子的Split算子
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/516966/
转载文章受原作者版权保护。转载请注明原作者出处!