

Flink 是一个默认就有状态的分析引擎,例如 WordCount 案例可以做到单词的数量的累加,其实是因为在内存中保证了每个单词的出现的次数,这些数据其实就是状态数据。但是如果一个 Task 在处理过程中挂掉了,那么它在内存中的状态都会丢失,所有的数据都需 要重新计算。从容错和消息处理的语义(At -least-once 和 Exactly-once)上来说,Flink 引入了 State 和 CheckPoint。
State 一般指一个具体的 Task/Operator 的状态,State 数据默认保存在 Java 的堆内存中。
CheckPoint(可以理解为 CheckPoint 是把 State 数据持久化存储了)则表示了一个 Flink Job 在一个特定时刻的一份全局状态快照,即包含了所有 Task/Operator 的状态。
Flink 有两种常见的 State 类型,分别是:
(1)keyed State(键控状态)
(2)Operator State(算子状态)
- Keyed State(键控状态)
Keyed State:顾名思义就是基于 KeyedStream 上的状态,这个状态是跟特定的 Key 绑 定的。KeyedStream 流上的每一个 Key,都对应一个 State。Flink 针对 Keyed State 提供了 以下可以保存 State 的数据结构:
1 .ValueState: 保存一个可以更新和检索的值(如上所述,每个值都对应到当前的输 入数据的 key,因此算子接收到的每个 key 都可能对应一个值)。 这个值可以通过 update(T) 进行更新,通过 T value() 进行检索。
2 .ListState: 保存一个元素的列表。可以往这个列表中追加数据,并在当前的列表上 进行检索。可以通过 add(T) 或者 addAll(List) 进行添加元素,通过 Iterable get() 获得整个列表。还可以通过 update(List) 覆盖当前的列表。
3 .MapState - Operator State(算子状态)
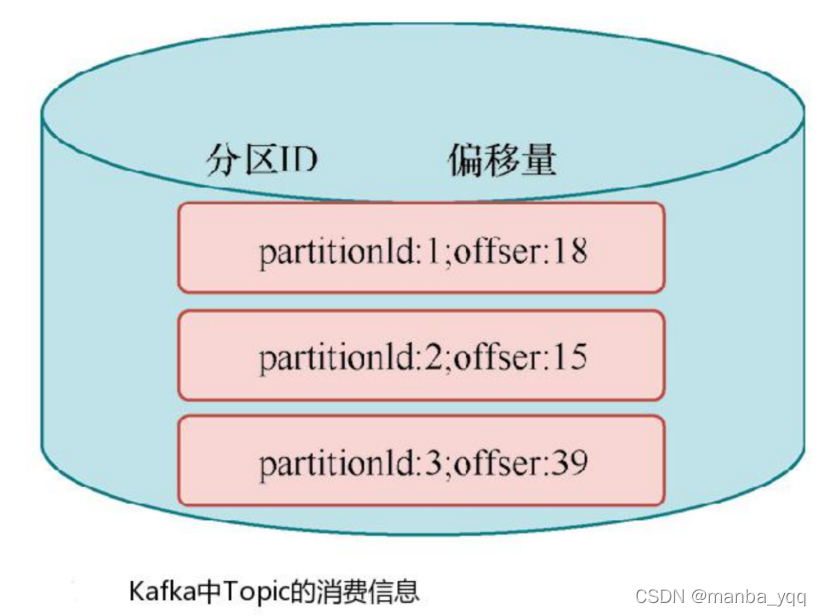
Operator State 与 Key 无关,而是与 Operator 绑定,整个 Operator 只对应一个 State。 比如:Flink 中的 Kafka Connector 就使用了 Operator State,它会在每个 Connector 实例 中,保存该实例消费 Topic 的所有(partition, offset)映射。

Original: https://blog.51cto.com/u_15704423/5434852
Author: wx62be9d88ce294
Title: Flink State 管理与恢复
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/516956/
转载文章受原作者版权保护。转载请注明原作者出处!