

一、概述
1)什么是任务调度?
大数据平台技术框架支持的开发语言多种多样,开发人员的背景差异也很大,这就产生出很多不同类型的程序(任务)运行在大数据平台之上,如:MapReduce、Hive、Pig、Spark、Java、Shell、Python 等。
这些任务需要不同的运行环境,并且除了定时运行,各种类型之间的任务存在依赖关系,一张简单的任务依赖图如下:


2)常见任务调度工具
Crontab(Linux 自带命令,使用方式简单, 适合不是非常复杂的场景,比如只按照时间来调度)Oozie( Hadoop 自带的开源调度系统,使用方式比较复杂, 适合大型项目场景)Azkaban(一个开源调度系统,使用方式比较简单, 适合中小型项目场景)- 企业定制开发(企业自研的调度系统,不开源)
3)什么是Azkaban
Azkaban是由Linkedin开源的一个批量工作流任务调度器,Azkaban来自LinkedIn公司, 用于管理他们的Hadoop批处理工作流。日常生产环境中,为了得到想要的数据,通常需要执行很多作业,一批作业执行完毕,再将中间结果进一步处理,最后得到有价值的数据,因此 作业之间执行有先后顺序和依赖关系。这样的一组作业称为一个工作流, Azkaban就是用来构建、运行和管理工作流的工具,它提供友好的Web用户界面来维护和跟踪用户的工作流程。Azkaban已经在LinkedIn运行了好几年,管理着很多Hadoop和数据仓库作业流,具有很强的可用性。
官方文档: https://azkaban.readthedocs.io/en/latest/ https://azkaban.github.io/azkaban/docs/latest/
简单来讲,它有几个特点:
- 分布式多执行器
- MySQL重试
- 友好的用户界面
- 有条件的工作流
- 数据触发
- 高安全
- 支持插件扩展,从Web UI到作业执行
- 全作者身份管理系统
二、Azkaban 与 Oozie 对比
Azkaban 和 Oozie 是市面上最流行的两种调度器。总体来说, Ooize 相比 Azkaban 是一个重量级的任务调度系统,功能全面,但部署和使用也更复杂,比较适合作为大型项目的任务调度系统。而 Azkaban 相对而言,配置和使用更为简单,能够满足常见的任务调度,比较适合作为中小型项目的任务调度系统。
对比如下:
对比项目 Azkaban Oozie 功能 两者均可以调度 mapreduce,pig,java,脚本工作流任务两者均可以定时执行工作流任务 跟Azkaban一样 工作流定义 Azkaban 使用 Properties 文件定义工作流 Oozie 使用 XML 文件定义工作流 工作流传参 Azkaban 支持直接传参 Oozie 支持参数和 EL 表达式 定时执行 Azkaban 的定时执行任务是基于时间的 Oozie 的定时执行任务基于时间和输入数据 资源管理 Azkaban 有较严格的权限控制,如用户对工作流进行读/写/执行等操作 Oozie 暂无严格的权限控制 工作流执行 Azkaban 有两种运行模式,分别是单机模式和集群模式 Oozie 作为工作流服务器运行,支持多用户和多工作流 工作流管理 Azkaban 支持浏览器以及 ajax 方式操作工作流 Oozie 支持命令行、HTTP REST、Java API、浏览器操作工作流
三、Azkaban 运行模式及架构

Azkaban 三大核心组件
- 关系型元数据库(MySQL)
- Azkaban Web Server
- Azkaban Executor Server
1)Azkaban Web Server
AzkabanWebServer 是 Azkaban 的主要管理者,负责项目管理、身份验证、调度和监控执行,并且为用户界面
2)Azkaban Executor Server
提交和执行工作流,记录工作流日志,和 Azkaban WebServer 可以在同一台服务器,也可部署在独立的机器。把 Executor 单独分开有几个好处:
- 在多 Executor 模式下可以方便扩展
- 工作流在某一个 Executor 挂掉,可以在另一个 Executor 上重试
- 可以滚动升级,从而不影响调度
3)关系型元数据库(MySQL)
负责存储azkaban系统的数据,包括用户上传的工作流文件、作业执行的日志等。Executor Server和Web Server都通过jdbc频繁地对其操作。
Azkaban 元数据库
表名 描述 active_executing_flows 记录当前执行中的flow对应每次执行的exejid execution_flows Azkaban flow的执行记录 executionjobs Azkaban flow中的job的执行记录 executionjogs Azkaban flow中的执行日志记录 executors 配置的executor的信息,多执行器模式有多条记录 project_files 保存项目的文件 project_flows 项目中的flow信息 project_permissions 项目中用户的权限 project_versions 项目的版本,上传用户,上传时间等 projects 项目信息 triggers 调度信息
四、Azkaban安装部署
在3.0版本之后,我们提供了两种模式: 独立的”单独服务器”模式和 分布式多执行器模式。下面介绍两种模式的区别。
- solo server mode(单机模式):该模式中 Web Server和Executor Server运行在同一个进程中,进程名AzkabanSingleServer。可以使用 自带的H2数据库或者配置mysql数据。该模式的使用。
- multiple executor mode(多执行器模式),。它的数据库应该由设置了主从关系的MySQL实例进行备份。 Web Server和Executor Server运行在不同的进程中,这样升级和维护就不会影响到用户。这种多主机设置为阿兹卡班带来了健壮和可伸缩的方面。
目前我们采用的是 multiple executor mode方式,分别在不同的主机上部署多个Azkaban ExecutorServer以应对高并发定时任务执行的情况,从而减轻单个服务器的压力。
安装步骤如下:
- 设置数据库
- 配置数据库以使用多个执行程序
- 为数据库中配置的每个Executor下载并安装Executor Server
- Azkaban安装插件
- 安装Web服务器
官方文档:https://azkaban.readthedocs.io/en/latest/getStarted.html
1)solo server mode安装
1、下载
$ cd /opt/bigdata/hadoop/software
$ git clone https://github.com/azkaban/azkaban.git
2、构建Azkaban安装包
$ cd azkaban; ./gradlew build installDist

【温馨提示】如果编译失败了,就多执行几次
3、启动服务
$ cd azkaban-solo-server/build/install/azkaban-solo-server
$ ./bin/start-solo.sh
$ netstat -tnlp|grep 8081
### 停止服务,这里不执行
$ ./bin/shutdown-solo.sh

检查进程
$ jps

4、web访问验证
- 访问http://ip:8081 (默认端口是
8081) - zkaban默认登录名/密码:
azkaban/azkaban

5、配置https并重启服务
阿兹卡班独立服务器默认不使用SSL。但你也可以在独立的web服务器上用同样的方法设置它。Azkaban web服务器支持SSL套接字连接器,这意味着必须提供密钥存储库,您可以按照以下步骤生成这里提供的有效的jetty密钥存储库:
创建ssl配置
$ keytool -keystore keystore -alias jetty -genkey -keyalg RSA
1.输入密钥库口令: 123456
2.再次输入新口令: 123456
3.[Unknown]: azkaban
4.[Unknown]: azkaban
5.[Unknown]: azkaban
6.[Unknown]: shenzhen
7.[Unknown]: guangdong
8.[Unknown]: CN
9.[no]: Y
10.(如果和密钥库口令相同, 按回车):
修改Azkaban 配置文件 azkaban.properties或 azkaban.private.properties(推荐)。
$ cd /opt/bigdata/hadoop/software/azkaban/azkaban-solo-server/build/install/azkaban-solo-server/conf
$ touch azkaban.private.properties
在 azkaban.private.properties(文件需要创建)配置如下:
根据上面设置的填,keystore文件会自动生成
ssl 文件名
jetty.keystore=/opt/bigdata/hadoop/software/azkaban/azkaban-solo-server/build/install/azkaban-solo-server/keystore
jetty.password=123456
jetty.keypassword=123456
文件名
jetty.truststore=/opt/bigdata/hadoop/software/azkaban/azkaban-solo-server/build/install/azkaban-solo-server/keystore
jetty.trustpassword=123456
在 azkaban.properties修改如下配置:
jetty.use.ssl=true
jetty.ssl.port=8443
重启服务
$ ./bin/shutdown-solo.sh ; ./bin/start-solo.sh
$ jps
$ netstat -tnlp|grep 8443
web访问验证

2)multiple executor mode安装(推荐)
先停掉上面的服务
$ /opt/bigdata/hadoop/software/azkaban/azkaban-solo-server/build/install/azkaban-solo-server/bin/shutdown-solo.sh
部署规划
hostname IP 节点属性 hadoop-node1 192.168.0.113 Azkaban Web Server/Azkaban Executor Server hadoop-node2 192.168.0.114 Azkaban Executor Server
1、把编译好的包copy到其它目录
$ mkdir /opt/bigdata/hadoop/server/azkaban
$ cd /opt/bigdata/hadoop/software/azkaban/
$ cp ./azkaban-web-server/build/distributions/azkaban-web-server-3.91.0-313-gadb56414.tar.gz /opt/bigdata/hadoop/server/azkaban/
$ cp ./azkaban-exec-server/build/distributions/azkaban-exec-server-3.91.0-313-gadb56414.tar.gz /opt/bigdata/hadoop/server/azkaban/
$ cp ./azkaban-db/build/distributions/azkaban-db-3.91.0-313-gadb56414.tar.gz /opt/bigdata/hadoop/server/azkaban/
### 解压并改名
$ cd /opt/bigdata/hadoop/server/azkaban

2、安装mysql
因为我之前安装过了mysql,不清楚的可以参考我之前的文章:大数据Hadoop之——数据仓库Hive

3、初始化azkaban表
#【温馨提示】一般公司禁止mysql -u root -p123456这种方式连接,在history里有记录,存在安全隐患,小伙伴不要被公司安全审计哦,切记!!!
$ mysql -u root -p
输入密码:123456
CREATE DATABASE azkaban;
CREATE USER 'azkaban'@'%' IDENTIFIED BY 'azkaban';
GRANT SELECT,INSERT,UPDATE,DELETE ON azkaban.* to 'azkaban'@'%' WITH GRANT OPTION;
Mysql数据包大小可能需要重新配置。默认情况下,MySQL允许的包大小可能低得离谱。要增加它,您需要将属性
max_allowed_packet设置为一个更大的数字,比如1024M。要在linux中配置,请打开/etc/my.cnf或者/etc/my.cnf.d/mysql-server.cnf(推荐),在mysqld后面的某个地方,添加以下内容:
[mysqld]
max_allowed_packet=1024M

重启mysql服务
$ systemctl restart mysqld
$ netstat -tnlp|grep 3306

开始初始化azkaban表
$ cd /opt/bigdata/hadoop/server/azkaban/azkaban-db
连接mysql
$ mysql -u root -p
密码:123456
use azkaban
可能版本不一样,sql文件也不太一样,create-all-sql-*.sql
source create-all-sql-3.91.0-313-gadb56414.sql

4、安装 Azkaban Executor Server(hadoop-node1)
$ cd /opt/bigdata/hadoop/server/azkaban/azkaban-exec
mysql配置,如果不一样,就需要调整
$ grep mysql conf/azkaban.properties

修改 conf/azkaban.properties配置文件
### 修改时区
default.timezone.id=Asia/Shanghai
### 修改mysql host
mysql.host=hadoop-node1
### webserver.url
azkaban.webserver.url=https://hadoop-node1:8443
### executor.port不设置就是随机值了,不方便管理,所以这里还是固定一个端口号,看资料大部分都是使用12321这个端口,这里也随大流
executor.port=12321
启动服务
【温馨提示】必须进入到azkaban-exec目录下执行启动重启命令,因为配置文件中有些路径用的是相对路径
$ cd /opt/bigdata/hadoop/server/azkaban/azkaban-exec
重启
$ ./bin/shutdown-exec.sh ; ./bin/start-exec.sh
AzkabanExecutorServer
$ jps
$ telnet -tnlp|grep 12321


通过接口的方式去激活,不能直接改表字段值,切记!!!
记得换成自己的IP或域名
$ curl -G "hadoop-node1:12321/executor?action=activate" && echo

【温馨提示】重启Azkaban Executor Server得重新激活
5、安装 另一台Azkaban Executor Server(hadoop-node2)
- 【第一步】先登录
hadoop-node2创建azkaban目录
$ mkdir -p /opt/bigdata/hadoop/server/azkaban
- 【第二步】登录到
hadoop-node1copy 安装目录到hadoop-node2
$ cd /opt/bigdata/hadoop/server/azkaban
$ scp -r azkaban-exec hadoop-node2:/opt/bigdata/hadoop/server/azkaban/
- 【第三步】启动Executor Server
登录到hadoop-node2 切换到azkaban目录
$ cd /opt/bigdata/hadoop/server/azkaban/azkaban-exec
$ ./bin/start-exec.sh
$ jps
$ netstat -tnlp|grep 12321

- 【第四步】激活Executor Server
记得换成自己的IP或域名
$ curl -G "hadoop-node2:12321/executor?action=activate" && echo

【温馨提示】重启Azkaban Executor Server得重新激活
6、安装Azkaban Web Server(hadoop-node1)
$ cd /opt/bigdata/hadoop/server/azkaban/azkaban-web
mysql配置,如果不一样,就需要调整
$ grep mysql conf/azkaban.properties

修改 conf/azkaban.properties配置文件
### 修改时区
default.timezone.id=Asia/Shanghai
### 修改mysql host
mysql.host=hadoop-node1
### azkaban.executorselector.filters调度策略
把MinimumFreeMemory去掉,因为MinimumFreeMemory是6G,自己电脑资源有限,如果小伙伴的机器资源雄厚,可以保留
StaticRemainingFlowSize:根据排队的任务数来调度任务到哪台executor机器
CpuStatus:跟据cpu空闲状态来调度任务到哪台executor机器
azkaban.executorselector.filters=StaticRemainingFlowSize,CpuStatus
启动服务
$ ./bin/start-web.sh
$ jps
$ netstat -tnlp|grep 8081

7、配置HTTPS
跟上面的一样
$ keytool -keystore keystore -alias jetty -genkey -keyalg RSA
1.输入密钥库口令: 123456
2.再次输入新口令: 123456
3.[Unknown]: azkaban
4.[Unknown]: azkaban
5.[Unknown]: azkaban
6.[Unknown]: shenzhen
7.[Unknown]: guangdong
8.[Unknown]: CN
9.[no]: Y
10.(如果和密钥库口令相同, 按回车):
配置
在 azkaban-web/azkaban.private.properties(文件需要创建)配置如下:
根据上面设置的填,keystore文件会自动生成
ssl 文件名
jetty.keystore=/opt/bigdata/hadoop/server/azkaban/azkaban-web/keystore
jetty.password=123456
jetty.keypassword=123456
文件名
jetty.truststore=/opt/bigdata/hadoop/server/azkaban/azkaban-web/keystore
jetty.trustpassword=123456
在 azkaban-web/azkaban.properties修改如下配置:
jetty.use.ssl=true
jetty.ssl.port=8443
修改 azkaban-exec/conf/azkaban.properties
jetty.port=8443
Where the Azkaban web server is located
azkaban.webserver.url=https://hadoop-node1:8443
重启服务
$ ./bin/shutdown-web.sh ; ./bin/start-web.sh
$ jps
$ netstat -tnlp|grep 8443

web访问验证:https://192.168.0.113:8443

8、Web 用户与角色
官方文档:https://azkaban.readthedocs.io/en/latest/userManager.html
$ cd /opt/bigdata/hadoop/server/azkaban/azkaban-web
$ cat conf/azkaban-users.xml

配置一个管理员用户,增加如下一行

重启web服务
$ ./bin/shutdown-web.sh ; ./bin/start-web.sh

五、Azkaban实战
官方文档:https://azkaban.readthedocs.io/en/latest/createFlows.html
1)HelloWorld示例(单个工作流)
1、在windows环境,新建 helloworld.project文件,编辑内容如下:
azkaban-flow-version: 2.0
【温馨提示】该文件作用,是采用新的Flow-API方式解析flow文件,内容基本上是固定的,2.0版本xxx.flow是yaml格式,2.0之前的版本是key=value格式,示例如下:
type=command
command=echo 'hello'
2、新建 helloworld.flow文件,内容如下:
nodes:
- name: jobA
type: command
config:
command: echo "Hello World"
【温馨提示】注意缩进的空格
- Name:job名称
- Type:job类型。command表示你要执行作业的方式为命令





2)工作量依赖案例
- DependentWorkflow.flow
nodes:
- name: jobA
type: command
config:
command: echo "jobA"
- name: jobB
type: command
config:
command: echo "jobB"
- name: jobC
type: command
dependsOn:
- jobA
- jobB
config:
command: echo "jobC"
- DependentWorkflow.project
azkaban-flow-version: 2.0
- 创建project,并把zip文件上传到azkaban执行

- 执行(执行完jobA和jobB才执行jobC)

4)自动失败重试案例
执行一个不存在的脚本/tmp/retry.sh,则任务失败,间隔10000ms,重试3次,其实总共会执行4次,1+3(重试3次)
- AutoFailed2Retry.flow
nodes:
- name: JobA
type: command
config:
command: echo "This is JobA."
- name: JobB
type: command
dependsOn:
- JobA
config:
command: echo "This is JobB."
- name: JobC
type: command
dependsOn:
- JobB
config:
command: sh /tmp/retry.sh
- name: JobD
type: command
dependsOn:
- JobC
config:
command: echo "This is JobD."
- name: JobE
type: command
dependsOn:
- JobD
config:
command: echo "This is JobE."
- name: JobF
type: command
dependsOn:
- JobE
config:
command: echo "This is JobF."
- ManualFailed2Retry.project
azkaban-flow-version: 2.0
- 创建project,并把zip文件上传到azkaban执行

- 执行


- 手动创建这个/tmp/retry.sh脚本,每个Executor都创建这个脚本,因为不确定会调度到哪个Executor
$ echo "echo 'This is JobC.'" > /tmp/retry.sh

可以看到,之前JobA和JobB执行成功的就不再执行了。正是预期效果。
6)JavaProcess工作流案例
【温馨提示】
type不单单只有command,还有javaprocess,当然还有其它type,例如:noop等。可以参考官方文档 【概述】
JavaProcess类型可以运行一个自定义主类方法,type类型为 javaprocess,可用的配置为:
- Xms:最小堆内存
- Xmx:最大堆内存
- classpath:类路径,可以省略,省略的话,是flow当前文件路径
- java.class:要运行的Java对象,其中必须包含Main方法
- main.args:main方法的参数
- 新建azkaban的maven工程或者module
- 创建
com.bigdata.AzTest类,内容如下:
【示例】
package com.bigdata;
public class AzTest {
public static void main(String[] args) {
System.out.println("This is Azkaban Test!!!");
}
}
- 打包成jar包azkaban-1.0-SNAPSHOT.jar

- 新建com.bigdata.testJava.flow,内容如下:
nodes:
- name: az_javaprocess_test
type: javaprocess
config:
Xms: 100M
Xmx: 200M
java.class: com.bigdata.AzTest
- JavaprocessTest001.project,project文件是固定的也是并不可少的。
azkaban-flow-version: 2.0
- 把三个文件打包成zip包

- 把zip包上传到azkaban上执行

六、Azkaban进阶(条件工作流)
1)条件工作流概述
条件工作流功能允许用户自定义执行条件来决定是否运行某些Job,条件可以由当前Job的父Job输出的运行时参数构成,也可以使用预定义宏。在这些条件下,用户可以在确定Job执行逻辑时获取得更大的灵活性,例如:只要父Job之一成功,就可以运行当前Job。
1、基本原理
- 父Job将参数写入
JOB_OUTPUT_PROP_FILE环境变量所指向的文件 - 子Job使用${jobName.param}来获取父Job输出的参数并定义执行条件
2、支持的条件运算符:
- == 等于
- != 不等于
*大于
*
= 大于等于 - < 小于
3、示例
【示例一】 需求:JobA执行一个shell脚本。JoB执行一个shell脚本,但JobB不需要每天都执行,而只需要每周一执行。
- 新建JobA.sh
#!/bin/bash
echo "do JobA"
wk=date +%w
echo "{\"wk\":$wk}" > $JOB_OUTPUT_PROP_FILE
获取当前周第几天,0:周日,1表示周一,则JobB需要到周一才执行,今天不执行

- 新建JobB.sh
#!/bin/bash
echo "do JoB"
- 新建condition.flow
nodes:
- name: JobA
type: command
config:
command: sh JobA.sh
- name: JobB
type: command
dependsOn:
- JobA
config:
command: sh JobB.sh
condition: ${JobA:wk} == 1
- 将JobA.sh、JobB.sh、condition.flow和azkaban.project打包成xxx.zip

- 创建condition项目=》上传xxx.zip文件=》执行作业=》观察结果

2)预定义宏
1、宏概念
Azkaban中预置了几个特殊的判断条件,称为预定于宏。
预定于宏会根据所有父Job的完成情况进行判断,再决定是否执行。可用的预定义宏如下:
all_success:表示父Job全部成功才执行(默认)all_done:表示父Job全部完成才执行all_failed:表示父Job全部失败才执行one_success:表示父Job至少一个成功才执行one_failed:表示父Job至少一个失败才执行
2、示例
需求:
- JobA执行一个shell脚本
- JobB执行一个shell脚本
- JobC执行一个shell脚本,要求JobA、JobB中有一个成功即可执行
步骤如下:
- 新建JobA.sh
#!/bin/bash
echo "do JobA"
- 新建JobB.sh(不创建,验证)
#!/bin/bash
echo "do JobB"
- 新建JobC.sh
#!/bin/bash
echo "do JobC"
- 新建marco.flow
nodes:
- name: JobA
type: command
config:
command: sh JobA.sh
- name: JobB
type: command
config:
command: sh JobB.sh
- name: JobC
type: command
dependsOn:
- JobA
- JobB
config:
command: sh JobC.sh
condition: one_success
- 新建marco.project
azkaban-flow-version: 2.0
- 把文件打包成zip文件,并上传到azkaban上执行

- 执行


3)定时执行工作流



4)邮件报警
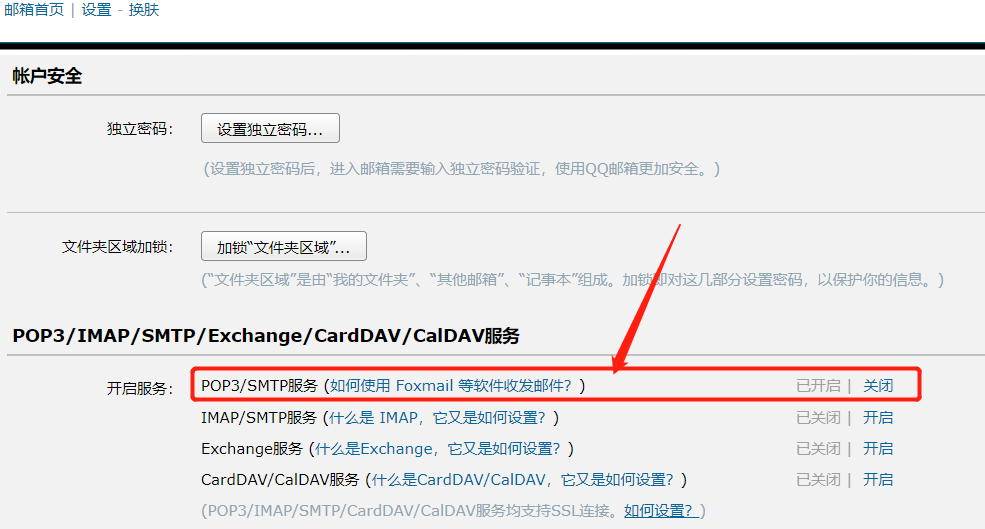
1、开启邮箱协议SMTP服务
2、修改azkaban-web配置,配置发送邮件信息
$ cd /opt/bigdata/hadoop/server/azkaban/azkaban-web
$ vi conf/azkaban.properties
修改的内容如下:
mail.sender=2920992033@qq.com
mail.host=smtp.qq.com
下面两行没有需要增加
mail.user=2920992033@qq.com
password就换成上面截图的授权码(自己邮箱授权码)
mail.password=xxxx

重启web服务生效
$ ./bin/shutdown-web.sh ; ./bin/start-web.sh
3、azkaban配置邮件接受人

5)电话报警
因为azkaban默认是不支持电话报警的,所以这里使用[睿象云]做中转实现电话报警。
1、登录睿象云官网注册并登录配置




2、配置通知策略

3、设置azkaban配置

能收到告警电话,验证ok。小伙伴可以自己试试。
总结
原生的 Azkaban 支持的plugin类型有以下这些:
- command:Linux shell命令行任务
- javaprocess:原生java任务
- gobblin:通用数据采集工具
- hadoopJava:运行hadoopMR任务
- hive:支持执行hiveSQL
- pig:pig脚本任务
- spark:spark任务
- hdfsToTeradata:把数据从hdfs导入Teradata
- teradataToHdfs:把数据从Teradata导入hdfs
上面我们示例中用到了command和javaprocess,其中最简单而且最常用的是
command类型。
Azkaban基础部分就先到这了,后续会有更多相关的文章,请小伙伴耐心等待~
Original: https://blog.51cto.com/liugp/5437979
Author: 大数据老司机
Title: 大数据Hadoop之——任务调度器Azkaban(Azkaban环境部署)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/516826/
转载文章受原作者版权保护。转载请注明原作者出处!