

Broker
一台kafka服务器就是一个broker。一个集群由多个broker组成。
Kafka集群包含一个或多个服务器,这种服务器被称为broker。broker端不维护数据的消费状态,提升了性能。直接使用磁盘进行存储,线性读写,速度快:避免了数据在JVM内存和系统内存之间的复制,减少耗性能的创建对象和垃圾回收。
Topic
每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)
Topic 就是数据主题,可以理解为消息的类别,所有的消息按照消息的类别进行存放,主题只是逻辑上的概念,就是消息属于哪个Topic.
kafka建议根据业务系统将不同的数据存放在不同的topic中!Kafka中的Topics总是多订阅者模式,一个topic可以拥有一个或者多个消费者来订阅它的数据。一个大的Topic可以分布式存储在多个kafka broker中!Topic可以类比为数据库中的库!
Partition分区
分区是消息的物理上的概念,比如说这个消息在磁盘的哪里存放着.
分区就是我们可以将一个Topic划分为多个区(Partition),比如说我有一个主题是 Hello,Hello可以分为三个区,这个时候在你Kafka 实例(Broker)的磁盘上会生成三个目录,这个目录的命名是按 “主题-分区名字” 的.比如说 “Hello-1″ 和”Hello-2” , 这个目录就是分区目录, 你的数据就在这个分区目录里面产生一个文件.
此外通过分区还可以让一个topic被多个consumer进行消费!以达到并行处理!分区可以类比为数据库中的表!
kafka只保证按一个partition中的顺序将消息发给consumer,不保证一个topic的整体(多个partition间)的顺序。
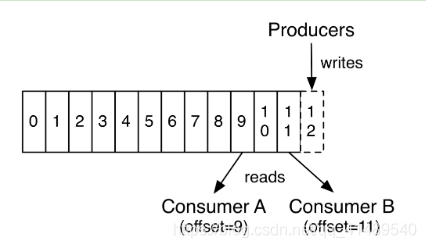
Offset
简单说就是每一个消息的唯一id,有序不可变.
数据会按照时间顺序被不断第追加到分区的一个结构化的commit log中!每个分区中存储的记录都是有序的,且顺序不可变!
这个顺序是通过一个称之为offset的id来唯一标识!因此也可以认为offset是有序且不可变的!
在每一个消费者端,会唯一保存的元数据是offset(偏移量),即消费在log中的位置.偏移量由消费者所控制。通常在读取记录后,消费者会以线性的方式增加偏移量,但是实际上,由于这个位置由消费者控制,所以消费者可以采用任何顺序来消费记录。例如,一个消费者可以重置到一个旧的偏移量,从而重新处理过去的数据;也可以跳过最近的记录,从”现在”开始消费。
这些细节说明Kafka 消费者是非常廉价的—消费者的增加和减少,对集群或者其他消费者没有多大的影响。比如,你可以使用命令行工具,对一些topic内容执行 tail操作,并不会影响已存在的消费者消费数据。
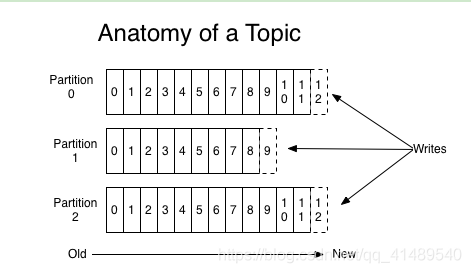

消息在写到目录的时候会 生成一个 int类型的id号, 这个id号就是 Offset , 后写的消息也会有Offset,是唯一递增的.
持久化
Kafka的数据都会存到磁盘的,一旦消费者消费了数据,Kafka也不会被删除,但是你可以设置保留策略
举个例子, 如果保留策略设置为2天,一条记录发布后两天内,可以随时被消费,两天过后这条记录会被清除并释放磁盘空间。
Kafka的性能和数据大小无关,假如说你磁盘存了50T的数据和存了100T的数据的性能是没关系的,所以长时间存储数据没有什么问题。
副本机制
我们数据是存到Partiton(分区)里面的,Partition在磁盘的体现就是目录,Kafka 可以设置每个主题的副本,设置之后,一个Partition(目录)会存在多个副本,
假设三个副本,是在三个Broker(Kafka服务器)里面,每个Broker里面存一份副本.
这个时候我向Partition进行读写操作的时候, 三个服务器都有数据,我到底是读哪个机器的数据?这个时候三个副本里面就会有角色划分了.
三个副本里面会自动选举出一个服务器作为Leader,其余都是Follwers, Leader必须有一个,Follwers你有零个也行(相当于我副本数量为1),
不管读写都是由Leader来负责, 处理一切对 partition (分区)的读写请求,而follwers只需被动的同步leader上的数据来保证数据是一致的.
当leader宕机了,followers 中的一台服务器会自动成为新的 leader。通过这种机制,既可以保证数据有多个副本,也实现了一个高可用的机制.
基于安全考虑,每个分区的Leader和follower一般会错开在在不同的broker(相当于负载均衡)
Producer
消息生产者,就是向kafka broker发消息的客户端。生产者负责将记录分配到topic的指定 partition(分区)中
Consumer
消息消费者,向kafka broker取消息的客户端。每个消费者都要维护自己读取数据的offset。
低版本0.9之前将offset保存在Zookeeper中,0.9及之后保存在Kafka的”__consumer_offsets”主题中。两者区别就是存到Zookeeper里面的话需要使用Zookeeper客户端查询,如果是存到Kafka的话,你就需要用消费者消费主体来获取最新的Offset记录.
Consumer Group
一个消费者组可以同时订阅多个topic主题, 一旦一个组订阅了多个主题, 假如说这个消费者组里面有两个消费者线程,比如说C1和C2, 这C1和C2是可以消费多个分区的.
比如,我当前订阅了两个主题,topicA和topicB, topicA有两个分区,topicB有三个分区,我消费者组里面只有一个消费者线程C1,C1就负责消费topicA和topicB里面的所有的分区.
Original: https://blog.51cto.com/u_14861909/5439588
Author: wx5efd5423d18bb
Title: Kafka核心概念
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/516798/
转载文章受原作者版权保护。转载请注明原作者出处!