

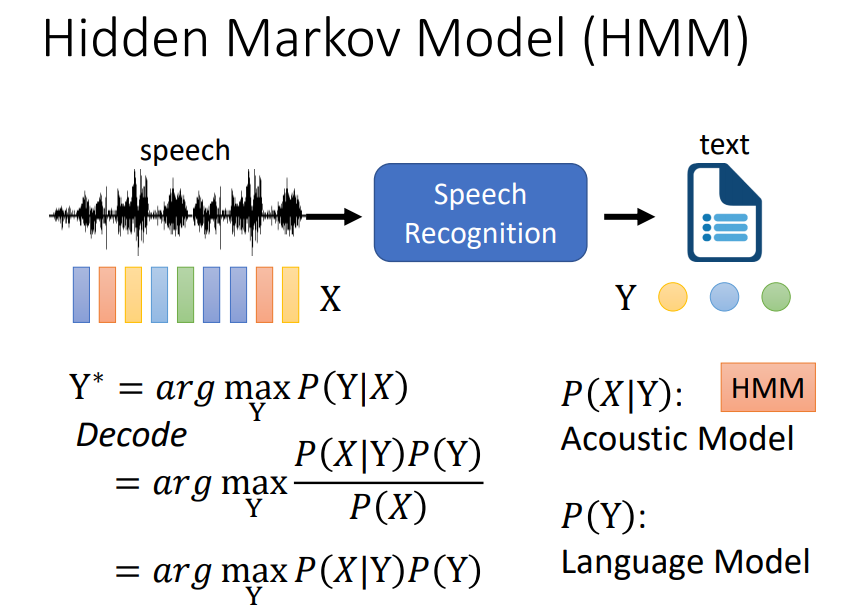

语音识别,输入是声学特征的序列,上图中X是经过一定规则提取的39维mfcc向量组成的矩阵,矩阵大小是不固定的,因为输入语音长度不一样,提取的语音帧就不一样,比如有100 _39,1000_39, 一般按照25ms一帧,10ms一个帧移,所以一秒中语音有100帧。由于人说话字数不固定的,所以一句话说完时长不一样,这样得到帧矩阵大小就不一样。所以语音识别是典型的seq2seq问题。
上图中X是提取的mfcc向量序列,Y是token序列,token的粒度可以是字符,字,词,音素。传统的语音识别一般将Y转换为S,S是相对于因素更小的单位。
根据X穷举可能Y序列,并找到概率最大序列作为识别结果,这个是宏观公式,是没法直接结算的,不过现在研究方法通过e2e方法也能算了。所以通过贝叶斯转换,将后验概率转换为先验概率和极大似然估计相乘的形式。
先验概率求解叫做语言模型,也就是求解中Y序列像不像一句正常的话。极大似然估计是一个token序列的发音特征向量矩阵的概率。语言模型可以通过统计token词典,通过统计方法求取。但是声学模型极大似然估计是没法通过统计模型求取,因为y序列x的发音这种人工是没法标记的。于是对照发音字典,将Y更细化,音标和发音特征之间是能对应的,哪些音标发什么音这个是特定的。所以将y装换位为S。从Y到S转换只需设计发音词典就行,发音词典语言学家早就设计好了。
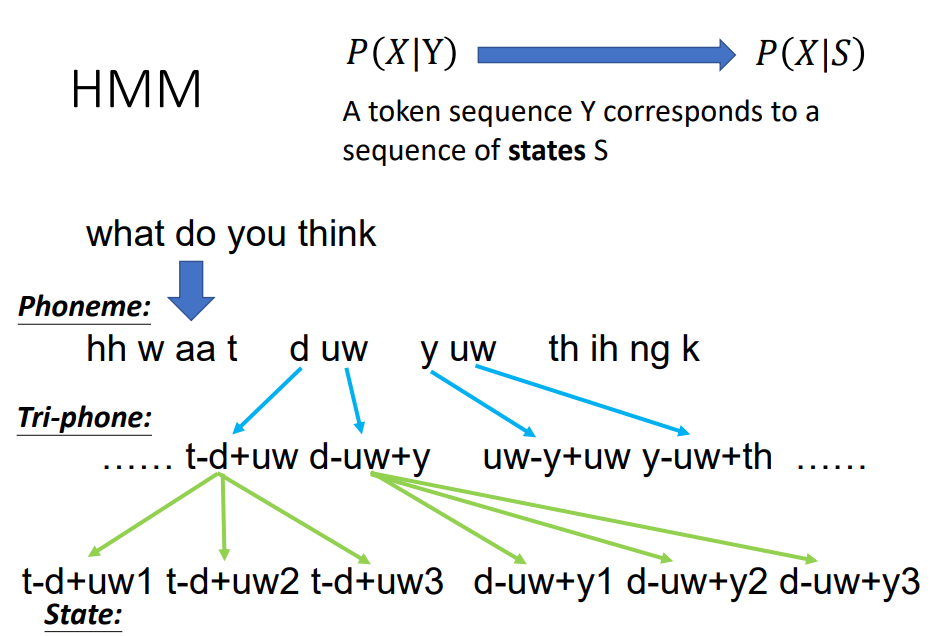
S的状态如果是phoneme的,由于有的phoneme受上下文的影响,发音还不一样,这样导致计算phoneme对应的声学概率有问题,所以还需要将phoneme进一步细化到tri-phone, tri-phone并不是将phoneme的前后相连起来,它就是比phone更小的单位,发音是唯一的, 每个tri-phone还有1,2,3个状态。每个tri-phone的状态就对应一帧语音数据。之前讲到每个token可能对应多条语音帧,这个对应是没法人工标记的,但tri-phone的3个状态对应声学特征可以通过gmm来拟和这个概率。tri-phone的状态对应声学特征分布基本是唯一的了,所以这个时候才可以通过gmm来拟和。
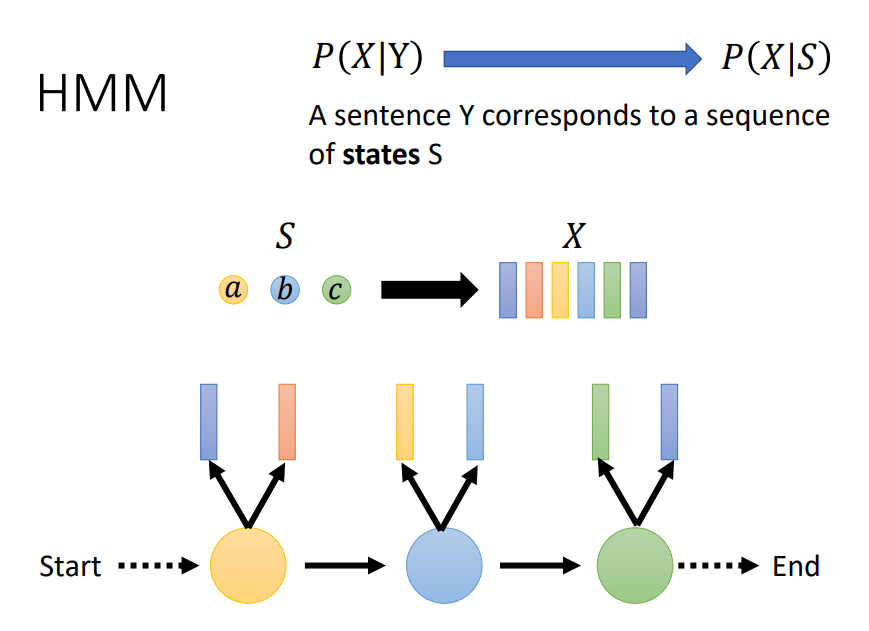
tri-phone的三个状态对应的语音帧也有多种对应关系
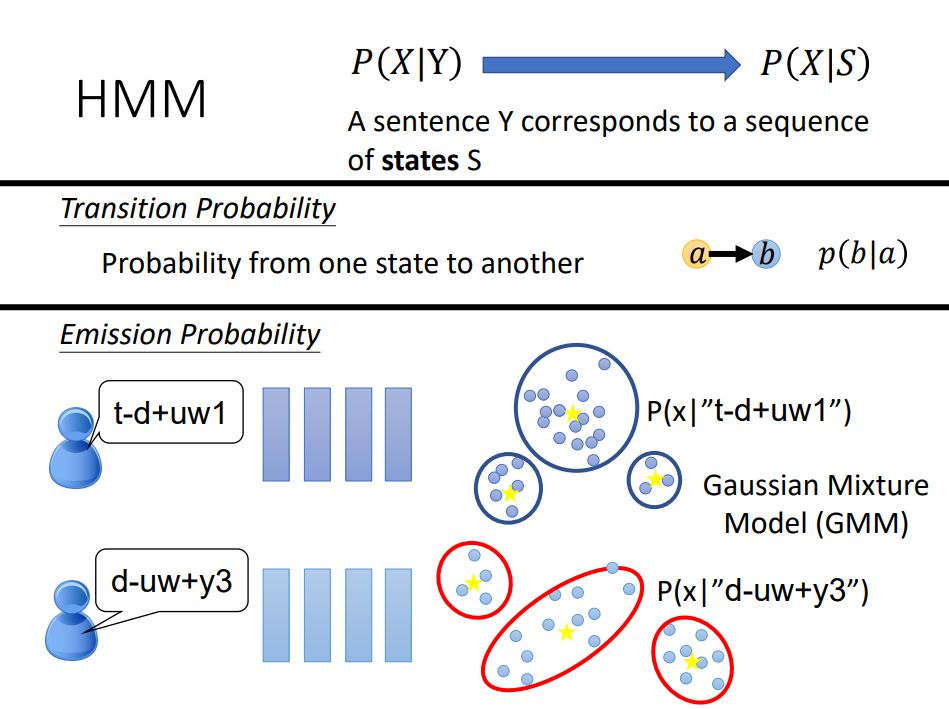
tri-phone每个状态对应声学特征是符合某种分布的,而且是固定分布,可以通过gmm来拟和这种分布。
每个状态之间跳转是transition probability, 又tri-phone的s产生x的概率叫做发射概率,emission probabiliy。

状态绑定是将s的声学分布一样的发射概率指向同一个gmm. 如果不做绑定,一个tri-phone对应三个s状态,如果又N个tri-phone,每个s状态需要一个gmm, 这样就有N^3次方个gmm, 导致gmm模型数量暴增。所以选择让一些s共享要给gmm,减少gmm模型数量,具体让哪些s公用要给gmm,这个可以通过规则或者决策树聚类的方法将具有相同分布的s共享一个gmm模型。讲到这里其实还是没法计算P(X|S),还差最重要一点,就是哪些帧对应哪些s,看下面这幅图
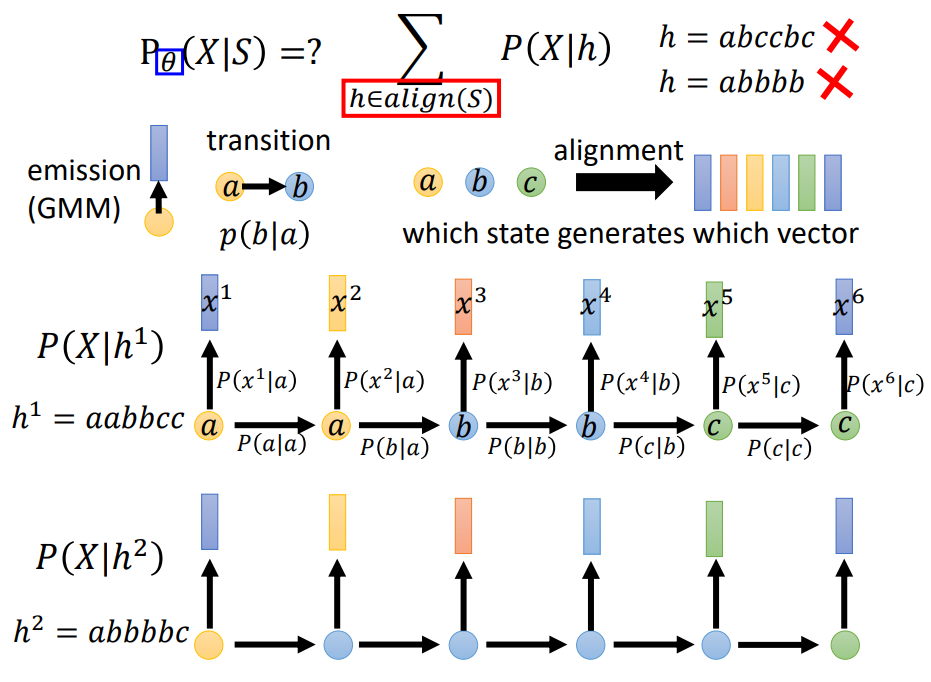
假设模型已经学习到emission, transition,那么可以通过穷举所有可能对齐来计算p(X|H), 但是有的对齐是无效的,因为语音时序性,如图中三个状态abc发生有时序性,发生c以后不可能在发生b,所以将有效对齐的序列的概率加起来就是最后的计算结果,这个就是解码。这个对齐不仅在传统语音识别hmm-gmm中用到,在dnn-hmm中也用到。事实上语音识别只要解决对齐问题,所有问题都ok了。
Original: https://blog.csdn.net/q_xiami123/article/details/117257650
Author: ai-ai360
Title: 语音识别训练和解码——声学特征与文本标记如何对齐
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/516131/
转载文章受原作者版权保护。转载请注明原作者出处!