

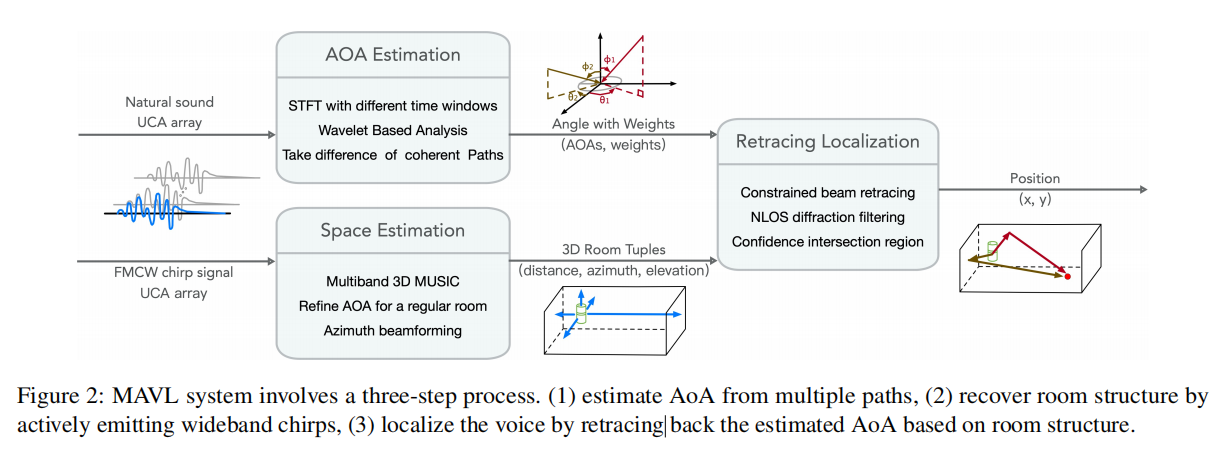
MAVL: Multiresolution Analysis of Voice Localization
- i 文章地址
- ii 常见术语
- iii 文章目录
- Abstract
- 1.introduction
- 2. Primer on AoA Estimation
* - 2.1 Antenna Array Model
- 2.2 AoA Estimation Algorithms
- 2.3 Modeling Multipath Propagation
- 2.4 Challenges
- 3.Multipath Voice Localization
* - 3.1 AoA Estimation of Voice Signals
- 3.2 Room Structure Estimation
– - 3.3 Constrained Beam Retracing
- 4.Implementation
- 5. Evaluation
* - 5.1 Performance of AoA Estimation
- 5.2 Performance of Room Estimation
- 5.3 Overall localization results
- 6. Related Work
- 7. Conclusion
- 8.ACKNOWLEDGMENTS
i 文章地址
MAVL: Multiresolution Analysis of Voice
Localization
ii 常见术语
AoA:到达信道的角度(也就是 DoA)
xH:x的共轭转置
iii 文章目录
Abstract
智能音箱能够根据用户的声音对其进行定位,这为许多新的应用程序打开了大门。在本文中,我们提出了一个新的系统,MAVL定位人的声音。它由三个主要部分组成:
(1)首先建立了一种新的多分辨率分析方法来估计来自多个传播路径的时变低频相干语音信号的AoA;
(2)然后通过发出声音信号和开发改进的3D音乐算法来自动估计房间结构;
(3)最终使用估计的AoA和房间结构重新跟踪路径,以定位语音。
我们使用一个扬声器和一个统一的圆形麦克风阵列实现了一个原型系统。结果表明,对于前两个AOA估计,它实现了1.49°和3.33°的中值误差,并且在视线(LoS)情况下实现了0.31m的中值定位误差,在非视线(NLoS)情况下实现了0.47m的中值定位误差。
1.introduction
1. 动机:
由于物联网设备、语音商务和互联网连接的日益普及,智能音箱的普及率在过去几年中呈指数级增长。
定位人类声音的能力在很多方面都有利于智能音箱。首先,知道用户的位置允许智能音箱向用户发射波束,以便它既能听到远方用户的声音,也能向远方用户发射。其次,用户位置提供了上下文信息,这可以帮助我们更好地解释用户的意图。例如, 如图1所示,当用户发出打开灯的命令时,智能音箱可以解决模糊性问题,并根据用户的位置决定打开哪个灯。此外,了解位置还可以实现基于位置的服务。例如,智能音箱可以自动调整用户附近的温度和照明条件。此外,位置信息还可以通过提供重要的上下文信息来帮助语音识别和自然语言处理。例如,当用户在厨房里说”orange”时,它知道这是指水果;当同一用户在其他地方说”orange”时,它可能会将其解释为一种颜色。


尽管基于声学的跟踪工作取得了重大进展,但定位人类声音提出了新的挑战:
(1)许多现有系统需要传输已知信号 (e.g., chirps, OFDM symbols, sine waves).相比之下,我们既不能控制也不能预测用户的语音信号,包括其时间、频率和内容。这使得应用传统的基于信道估计和距离估计的方法具有挑战性。
(2)为了定位用户,我们需要估计多个传播路径的到达角(AoA),以便我们可以追踪这些路径来定位用户。通过多路径的信号是相干的,这大大降低了AoA估计方法的精度(如MUSIC要求所有信号都是独立的)。
(3)为了能够使用多个AOA来追溯位置,我们还需要首先估计室内环境。然而,深度传感器并没有在家庭中广泛部署,基于视觉的方法引起了隐私方面的担忧。
(4)用户可能不在智能扬声器的视线(LoS)内(例如,用户在墙后或在不同的房间)。由于低信噪比和绕道传播路径,使用声信号在非视线中定位用户仍然是一个开放的问题。
3. 我们的方法:
我们选择AoA是因为它消除了距离估计的需要,而距离估计在我们不知道传输信号的情况下是很有挑战性的。我们使用广泛应用于智能音箱上的麦克风阵列来收集接收到的信号。虽然已经提出了许多AoA算法,但低频语音信号和相干路径的存在带来了重大的新挑战。为了减少路径的相干性和分离性,我们捕获完成速度较快的语音信号,使通过最短路径遍历的信号与通过较长路径遍历的信号很少或没有重叠。我们无法控制用户说了多少单词。相反,我们可以选择在短时间内占据某些频率的语音信号。这需要良好的时间和频率分辨率。由于没有单一的方法可以同时实现良好的时间和频率分辨率,我们在不同的时间窗口进行小波和短时傅里叶变换分析,以从低相干性的瞬态信号和高累积能量的长信号中受益。我们进一步利用差分在时频域对信号进行消去,以降低相干性,从而提高AoA精度。
接下来,我们需要估计房间轮廓,即墙壁的距离和方向。研究人员使用深度传感器、摄像机或多个传感器来估计室内轮廓。然而,这些系统需要额外的传感器,有些还需要大量的计算成本。这也引发了重大的隐私问题。声学已经被应用于物体形状的成像。利用声信号捕捉房间轮廓是很有前景的。我们的系统发射宽带调频连续波(FMCW)线性调频信号,并提出宽带3D音乐来同时估计多个传播路径。宽频带不仅提高了距离分辨率,而且使我们能够利用频率分集来估计相干信号的AOA。我们利用矩形房间的假设改进了AoA估计(这在现实世界场景中很常见),并利用波束形成改进了到墙壁的距离估计。
最后,我们提出了一种基于AoA候选点和房间结构的约束波束追踪算法。我们只使用一次性反射在传播路径的交叉处对用户进行定位。我们的回溯可以有效地识别出可能的用户位置。
我们在消音室、会议室、卧室和客厅实施和评估我们的AoA和定位方法。我们的结果表明,我们的AoA估计在LOS最高的两条路径上的中位数误差为1.49°和3.33°,在NLOS下产生的中值误差为2.75°和6.49°。此外,我们的回溯算法可以对用户进行定位,LoS和NLoS的中值误差分别为0.31m和0.47m。
其贡献可描述如下:
(1)我们开发了一种多分辨率分析来估计多径的AoA。它将不同窗口大小的STFS 与小波相结合,以减少信号之间的相干性。
(2)我们开发了一种有效的方法来估计房间结构,并根据估计的AoA和房间结构来回溯(找出)用户。
(3)我们实现了一个系统,只使用一个智能扬声器,而不需要额外的硬件,就可以主动绘制室内房间地图并定位语音源。我们的原型系统可以在直瞄(LOS)和非直瞄(NLOS)中定位语音。据我们所知,这是第一个适用于非视距(NLoS)场景的室内声源定位系统。
- Primer on AoA Estimation
在本节中,我们将介绍AoA估计问题、现有方法和挑战。
2.1 Antenna Array Model
(天线阵列模型)
我们可以使用天线阵列来估计AoA。天线阵列可以采用不同的形式,如均匀圆形阵列(UCA)、均匀线性阵列(ULA),甚至是非均匀阵列。本文采用由N个麦克风组成的均匀圆形阵列,如图3所示。圆的半径为r。信号到达的方位角和仰角分别为θ和φ。

单源接收信号的一般模型为
x(t) = a(θ,φ)s(t) +n(t),
其中a是阵列方向矢量,n(t)是噪声矢量。UCA的转向矢量如下所示:
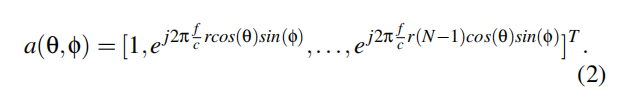
式中f为中心频率,c为声速。对于M个独立源信号S(t)=[S1(t),…,SM(t)]T,我们可以将转向矢量扩展为一个转向矩阵,a(θ,φ) = [a(θ1,φ1),…,a(θM,φM)],其中第i列为与第i个信号相关的转向矢量。
; 2.2 AoA Estimation Algorithms
(AoA估计算法)
有几种AoA估计算法,包括相位、MUSIC、ESPIRIT和波束形成等。基于子空间的MUSIC算法是最精确的。为了应用MUSIC,我们将接收信号x的自相关矩阵R计算为xH x,其中xH是x的共轭变换,R的大小为N×N。然后,我们对R进行特征值分解,并根据相应特征值的大小按降序对特征向量进行排序。由前M个特征向量跨越的空间称为信号空间,由其他特征向量跨越的空间称为噪声空间。设RN表示噪声空间矩阵,其ith列为噪声空间的ith特征向量。可以得出
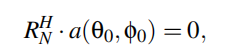
当θ0和φ0为入射方位角和俯仰角时。根据这个性质,我们可以定义混合信号的伪谱为
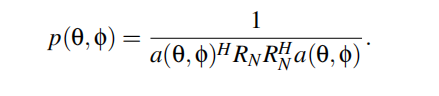
然后我们可以通过定位伪谱中的峰值来估计AoA。
2.3 Modeling Multipath Propagation
(多径传播模型)
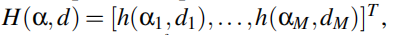
式中,αi,di和
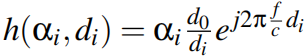
分别为i – th路径的衰减、传播延迟和通道。接收到的多径信号x(t)为:
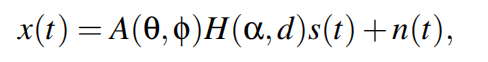
对于上式方程中多径情况下的阵列模型,我们定义了一个变换矩阵T=a∗H捕捉阵列流形矩阵A和传播路径H。变换矩阵T为
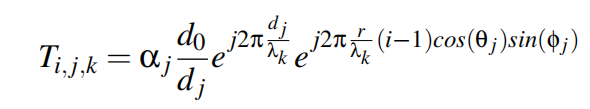
式中,1≤i≤N为麦克风指标,1≤j≤M为jth到达路径,k为频率单元指标。变换矩阵T有三个维度:空间维度i,时间维度j的路径延迟和频率维度k,这使得我们可以在时域进行消去。
频率fk上从所有传入路径到麦克风mi的接收信号为:
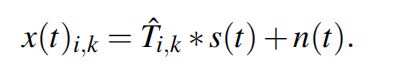
其中
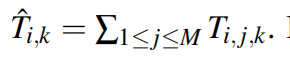
为了估计多路径的AoA,我们需要将^Ti,k解卷积到每个传播路径Ti, j,k。
; 2.4 Challenges
- 相干信号: AoA误差的一个主要来源是传入信号的相干性。在我们的上下文中,接收到的信号来自同一个语音源,只在传播路径上有所不同。这种强相关性会显著降低AoA的估计精度。在人声频率范围内,我们量化了相干信号对几种著名的AoA估计方案的影响。我们使用半径为9.6cm的UCA,约为2kHz的半波长。这两个信号在方位角和仰角上分别是(70,120)和(30,60)。图4(a)和(b)为两个非相干信号的五种AoA算法的方位角和仰角功率分布图,图4©和(d)为来自同一源的两个相干多径信号的方位角和仰角功率分布图。MUSIC在所有场景中表现最好。然而,当出现相干性时,所有算法的估计误差都会增加。例如,在这种情况下,MUSIC中的两个峰值合并为一个峰值,LP甚至给出了错误的结果。

– 频率的影响: 声音的低频率也是造成错误的部分原因。现有的声学跟踪方案使用16kHz或更高的频率。相比之下,人声通常在6kHz以下,大部分能量集中在100Hz-3kHz。相应的波长范围在11厘米到3.4米之间。到达角的分辨率由波长归一化的天线分离距离决定。因此,由于话筒和dm级波长之间的厘米级间隔,AoA分辨率非常粗糙。 - 总结: 以上评价表明,MUSIC在AoA估计精度方面具有较强的竞争力。然而,其精度仍不足以支持相干低频语音信号。基于这些观察,接下来我们将设计明确解决这些主要挑战的方法。
3.Multipath Voice Localization
我们将我们的方法分解为以下三个步骤:(i)估计相干低频语音信号的AoA, (ii)估计房间结构,(iii)回溯路径以定位用户。下面我们依次描述每一步。
3.1 AoA Estimation of Voice Signals
(语音信号的AoA估计)
如第2节所示,我们应该解决人声AoA估计中的两个主要挑战:(i)接收到的信号具有强相关性;(ii)由于人声频率较低,分辨率有限。下面我们依次介绍我们的部分。
- 现有工作的限制: 最近,Voloc[37]提出了一种迭代延迟和抵消算法来对齐和抵消相关路径,从而在时域内分离多径信号。他们的第一步,称为ICA,是在与第二反射混合之前,通过使用初始记录样本来估计第一反射的AoA。然而,这种方法引入了两个主要问题。首先,为了在时域中进行消去,我们需要使用一个足够小的时间窗口,在这个时间窗口中只包含直接路径的样本,通常只有几十个样本。少量样本限制了AoA估计的准确性。而且,人类的声音慢慢地提高。这意味着初始清晰的音频样本具有较低的信噪比,这也限制了估计的准确性。此外,人声的循环自相关特性较大,这表明较小的对准误差会导致较大的对消误差。因此,Voloc报告第一条路径AoA的误差超过10度,并依赖于其第二步,该步骤使用基于墙几何体的联合优化来细化估计结果。这有几个限制:(i)独立的AoA估计准确性有限,(ii)第二步需要探索一个很大的搜索空间,这非常耗时(例如,估计墙壁参数需要数小时,定位声音需要5秒)。
- 概述: 与[37]不同的是,我们使用时频分析来减少语音信号的相干性,因为在时间或频率上不同的信号将被分离出来。如式6中变换矩阵Ti, j,k所示,Voloc下IAC算法对每个麦克风i进行相位对齐,消除路径延迟dj,得到第二个反射路径。我们首先分离不同频率单元中的相干,然后通过取两个连续时间窗口之间的差来抵消每个频率单元中的路径。这对于语音信号特别有用,因为不同的音高可能在不同的时间出现。时频分析中的一个重要决策是选择时间窗口和频率单元的大小来进行分析。
一方面,在更大的时间窗口和更大的频率面元上聚集信号可以提高信噪比,进而根据CramerRao界证明AoA估计精度。另一方面,更大的时间窗口和更大的频率单元也意味着更多的相干信号。此外,语音信号的频率随着时间的推移会发生不可预测的变化,这使得确定固定的时间窗口和频率区间具有挑战性。
为了分离具有不同延迟的路径,我们需要良好的时间分辨率。小时间窗具有良好的时间分辨率,但频率分辨率较差。为了分离具有不同频率的路径,我们需要良好的频率分辨率。小频率箱具有良好的频率分辨率,但时间分辨率较差。因此,没有一个单一的时间窗口或频率单元在所有情况下都能很好地工作。
为了应对这一挑战,我们使用多分辨率分析,如图5所示。具体来说,我们使用具有不同窗口大小的短期傅里叶变换(STFT)和小波,因为它们是互补的。虽然大窗口STFT结果具有更多的相干信号,从而导致更多的异常值,但其峰值也包括接近地面真实值的点,这可能是由于更强的累积能量。我们的第二种方法是使用较小的窗口进行频率分析,并在相邻窗口之间取差,以减少相干信号并改进相干多径下的AoA估计。我们的第三种方法使用小波。对于频率较高的信号,它具有较高的时间分辨率。这使我们能够捕获具有低相干或无相干的瞬态语音信号,从而减少MUSIC AoA估计中的异常值。然而,由于暂态信号累积能量低,导致不可忽略的AoA估计误差,我们将小波变换与不同窗口大小的STFT相结合。下面我们将详细阐述这三种方法。
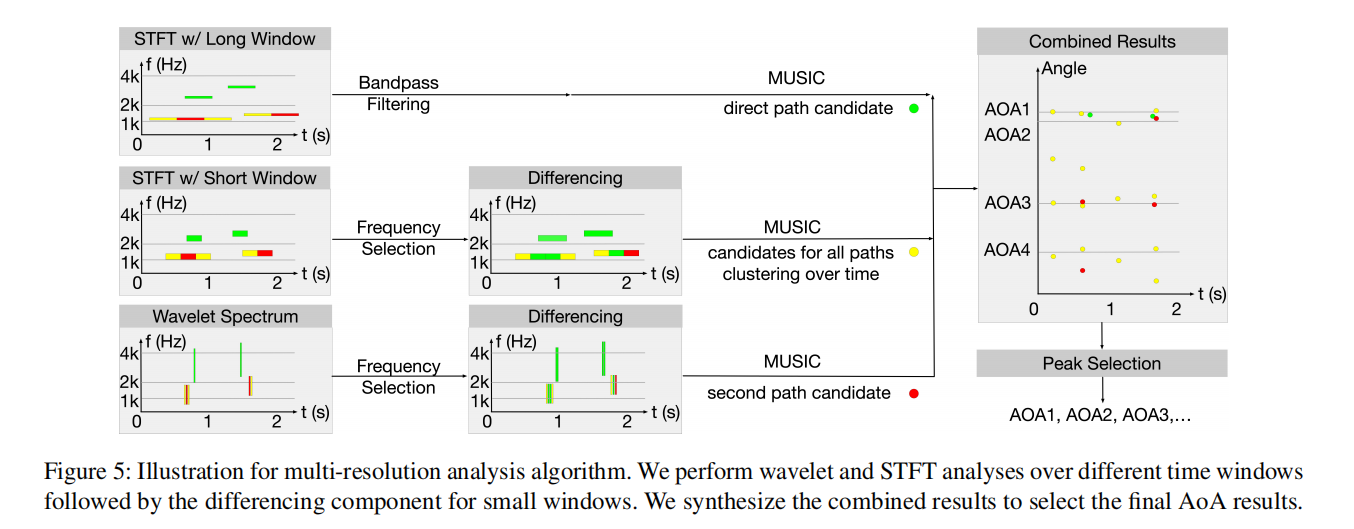
(1) 使用大窗口大小的STFT: 我们使用更大的时间窗来执行STFT。根据Cramer-Rao边界,窗口越大,信噪比越高,精度越高。另一方面,窗口越大,多径相干性越强,可能会降低精度。这如图4(c)所示,我们在图中看到一个靠近地面的合并峰。因此,这种方法可以提供有关直接路径的AoA的信息,但仅凭其自身是不够的。
(2) 使用小窗口的STFT: 使用较小的时间窗口可以提供良好的时间分辨率,并有助于分离具有不同延迟的路径。我们选择使用较小的时间窗,并在时频域中选择消逝音高,以减少相干性带来的误差。下一步是通过在每个天线的两个连续时间窗之间取差来进一步减少相干信号。该方法在时频域中对具有不同时延的路径进行消去,比单独在时域进行消去更有效。如果两个相邻窗口之间的差异大于任意两条路径的延迟差异,则此过程可以删除旧路径。这种消除并不完美,因为振幅可能随时间变化,每个窗口可能包含不同的路径集。然而,它在短时间内降低了相干性。
(3) 基于小波分析: 小波是一种多分辨率分析。我们可以使用短基函数来隔离信号不连续,也可以使用长基函数来进行详细的频率分析。它对相对高频的信号有超分辨率。瞬态信号在小时间窗内能量较小,误差较大。为了提高精度,我们还在两个连续的时间窗口内对小波谱进行差分,进一步降低相干性。

; 3.2 Room Structure Estimation
(房间结构估计)
为了对用户进行定位,我们不仅需要语音信号传播路径的AoAs,还需要房间结构信息,以便对路径进行回溯。在本节中,我们使用宽带3D MUSIC算法估计房间轮廓。我们通过利用方位AoA的约束和应用波束形成来提高精度。
3.2.1 3D MUSIC
除非移动到新位置,否则智能扬声器音箱只会对房间结构进行一次估计。智能音箱通过发送FMCWchirps来估计房间结构。设fc, B和T表示中心频率、频带和chirp持续时间。接收到反射信号后,采用3D MUSIC算法。

其中i是阵列索引,N是麦克风数量,r是麦克风阵列的半径,c是声速,Ns是子采样率,Ms是时间平滑窗口,Ts是时间间隔。
3.2.2 Our Enhancements
然而,在室内环境中应用3D MUSIC算法存在一些挑战。首先,麦克风的数量和尺寸都是有限的,这就限制了3D MUSIC的分辨率。其次,在室内场景中存在明显的混响。第三,精确的距离估计需要较大的带宽,而MUSIC需要窄带信号进行AoA估计。因此,我们开发了三种技术来改进3D MUSIC算法:(i)利用频率分集,(ii)结合房间通常为矩形的事实,以及(iii)使用波束形成来改进距离估计。
(i) 多波段3D MUSIC
我们使用1kHz到3kHz的FMCW信号进行AoA估计。为了满足MUSIC算法[35]的窄带要求,我们将2khz带宽分成20个子带,每个子带100Hz。由于FMCW信号的频率随时间线性增加,我们可以将FMCW信号在时域分成多个子频带,在每个子频带上运行3D MUSIC,然后对所有子频带的MUSIC廓线进行求和。
为了在3D MUSIC中使用100Hz的子频带,我们应该将发射信号与接收信号正确对齐,使它们跨同一个子频带。排列是由距离决定的。因此,我们在方位角和距离上搜索3D MUSIC轮廓中的一个峰值,该轮廓是通过将接收信号与发射信号混合得到的,发射信号是在δT之前发送的,其中δT是传播延迟,根据距离确定。
我们使用来自3D MUSIC的方位AoA和距离输出。图7显示了方位角-距离剖面的示例。注意,我们调整仰角到水平AoA,因为从UCA(所有天线在同一水平面上)估计的仰角AoA不是很准确。然而,尽管在仰角AoA上存在较大的误差,但3D MUSIC在路径分离方面比2D MUSIC更有效。
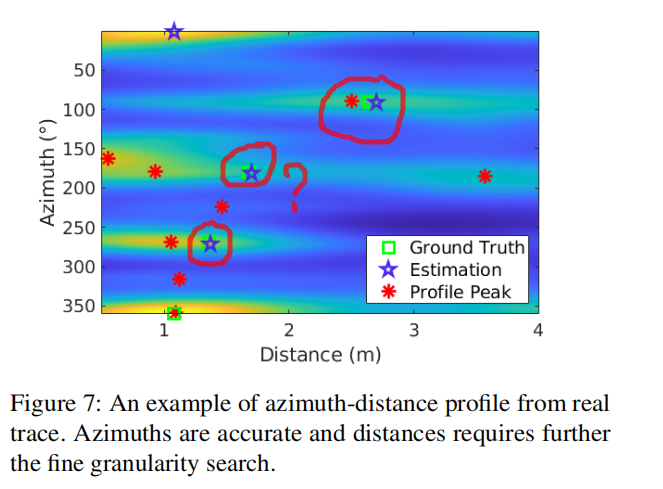
(ii) 为常规房间改进AoA: 由于多路径,MUSIC剖面可能是有噪声的,这使得很难确定正确的峰值来用于墙壁的距离和AoA估计。因为大多数房间都是矩形的,所以我们利用这一信息来改进峰值选择。具体而言,我们选择峰值,使两个连续峰值的方位角AoA差尽可能接近90°。也就是说,我们从3D MUSIC的轮廓中搜索4个峰值{θ0,θ1,θ2,θ3},以最大限度减小矩形房间的拟合误差((即min∑i |PhaseDif f (θi−θi+1)−π/2|,其中PhaseDif f(.)是考虑到每2π的相位包时两个角之间的差值。在找到这些峰值以后,我们进一步调整解,使相邻AoA之间的差正好是π/2。这个可以通过寻找θ’1使∑i |PhaseDif f (θ’1+π/2(i-1)-θi)|最小,且最终的AoA设为(θ’1,θ’1+π/2,θ’1 +π,θ’1 +3/2π)来实现。
(iii) 通过波束形成改进距离估计: 精确的距离估计需要较大的带宽和较高的信噪比。因此,为了改进距离估计,我们发送1kHz- 10kHz的FMCW chrips。其中,我们仅使用1KHz ~ 3KHz进行AoA估计,以减少计算成本,因为MUSIC需要昂贵的特征值分解,而使用整个FMCW进行距离估计。
我们使用波束形成来提高信噪比。我们使用延迟和(DAS)和波束形成算法来估计方位AOA。然后我们在波束形成的FMCW剖面中搜索一个峰值。我们发现波束形成后,峰值幅值显著增大,得到了更准确的距离估计。
; 3.3 Constrained Beam Retracing
(约束波束回溯)
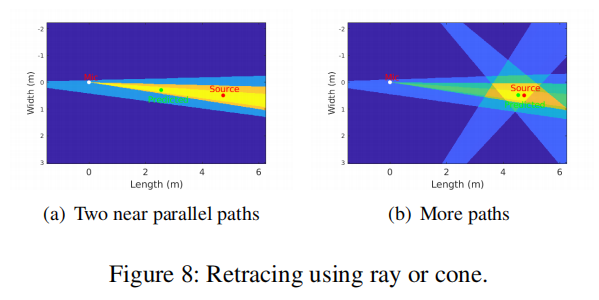
我们可以利用语音信号和房间结构估计的AoA来回溯路径来定位用户。如图8左图所示,我们首先可以通过估计出的AoA的传播路径找到壁面上的反射点。然后根据声音信号的反射特性,回溯出声音信号在墙反射前的入射路径。如果我们至少有两条路径,用户将被定位在传入路径的交叉点。然而,上述方法对AoA估计误差不具有鲁棒性。在模拟回溯算法时,我们发现即使2条路径的AoA估计误差仅为0.5°,在4米的距离上也会造成超过60cm的定位误差。一个小的AoA错误可能导致一个大的定位错误在很远的距离。此外,输出路径上的AoA误差会导致传入路径上的误差,从而进一步放大这种效果。为了增强对AoA估计的鲁棒性,我们采用了两种策略。首先,我们不将每个传播路径视为由估计AoA定义的射线,而是将其视为一个圆锥,其中圆锥中心由估计AoA决定,圆锥宽度由MUSIC峰值宽度决定。这使我们能够捕获AoA估计中的不确定性。
第二,虽然理论上两条路径就可以进行三角剖分,但是如何选择正确的三角剖分路径是一个挑战。因此,我们不是过早地选择错误的路径,而是让AoA估计程序返回更多的路径,这样我们就可以合并房间结构,对使用哪些路径进行定位做出明智的决定。具体来说,对于我们的AoA估计返回的每一个K条路径,我们使用如图8所示的锥结构进行跟踪。我们观察到方位角AoA对于最强路径是可靠的,这是视距内的直接路径或从用户到天花板,然后到非视距内的麦克风路径。因此,我们在最强路径对应的锥内寻找一个点O,以0.5m为圆心的点与其他K – 1路径对应的最大锥数重叠。我们将用户定位在点O。我们的评估集K = 4。
4.Implementation
设置: 我们在Bela平台上实现了我们的系统。它连接一个JBL Clip 3或一个回波点扬声器和一个带有8个麦克风的圆形麦克风阵列。图9显示了在会议室中设置的示例。每个麦克风的采样率为22.05kHz。许多商用智能音箱都有类似数量的音箱和麦克风。我们使用两个麦克风阵列测试我们的系统:一个大的阵列半径为9.6厘米,一个小的阵列半径为5.0厘米。我们使用较小的阵列与VoLoc进行比较,因为它的大小与它们的设置类似。Bela板采用1ghz ARM Cortex-A8单核处理器。Bela与一台搭载英特尔I5处理器和8GB内存的笔记本电脑相连。利用javaosc协议,将封装在OSC包中的WAV格式音频信号通过USB实时传输到笔记本电脑上,并在笔记本电脑上运行MATLAB中的处理程序,导出AoAs并对用户进行定位。在MAVL中,AoA估计需要2.35秒,房间估计需要87秒,回溯需要0.16秒。相比之下,VoLoc估计墙体参数花费数小时,AoA估计5秒。

评估环境: 我们在不同的环境中评估我们的系统,包括消音室、会议室、卧室和客厅。这些房间有不同的大小:2.5m×3.5m, 3.5m×4.0m和5.1m×7.5m。如图9所示,在NLoS案例中,我们使用木板作为堵塞物。我们让人们在距离麦克风阵列1 – 6米远的地方说话。我们还改变距离、用户、声音类型(例如,男人、女人、孩子和掌声)、智能音箱的位置、杂波和噪音水平来评估它们的影响。
基本事实: 我们使用测量龙头来测量智能扬声器、用户和墙壁的相对位置。我们推导了在视距场景中直接路径和5条反射路径(即从4个侧墙和天花板的路径)的地面真实AOA。在非视距场景中,我们推导了4条反射路径和1条衍射路径的AOA。
指标: 我们使用AoA估计误差和定位误差对误差进行量化。定位误差根据地面真值和估计位置之间的欧氏距离计算。
; 5. Evaluation
在本节中,我们将评估我们的AoA估计、房间轮廓估计和语音定位精度。
5.1 Performance of AoA Estimation
(AoA估计的性能)
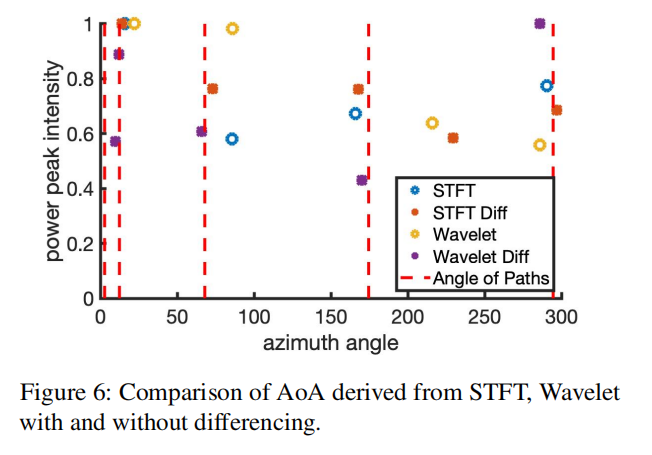
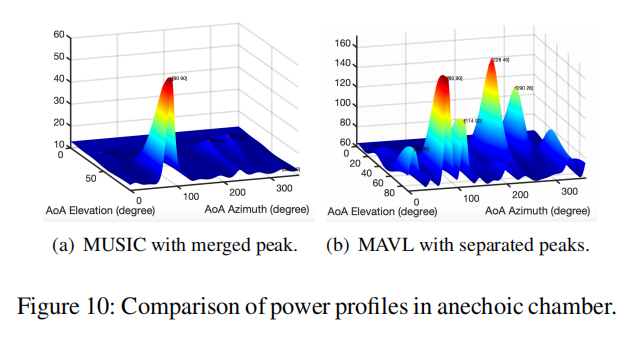
消声室的两条路径。我们首先在暗室中测试AoA估计算法,在暗室中没有反射。我们将麦克风阵列放在地面上,并放置一块亚克力板作为墙来引入反射路径。两个角的地面真值分别是81.95°和112.68°。图10显示了MUSIC功率剖面。它有一个90度左右的单一合并峰值,这会导致两条路径的8度和22.68度误差。相比之下,我们的算法对这两条路径的估计误差在1.5°以内。我们可以清楚地看到,在图10的MUSIC功率剖面中有两个单独的峰值。我们也将亚克力板反射器更换到其他地方,发现只有当两个地面真值角的差大于90°时,MUSIC才能将两条路径分开。该分辨率不足以进行语音定位,因为它很可能在90°内有反射路径。相比之下,只要两条路径相距30度,我们的方法就可以将它们分开。
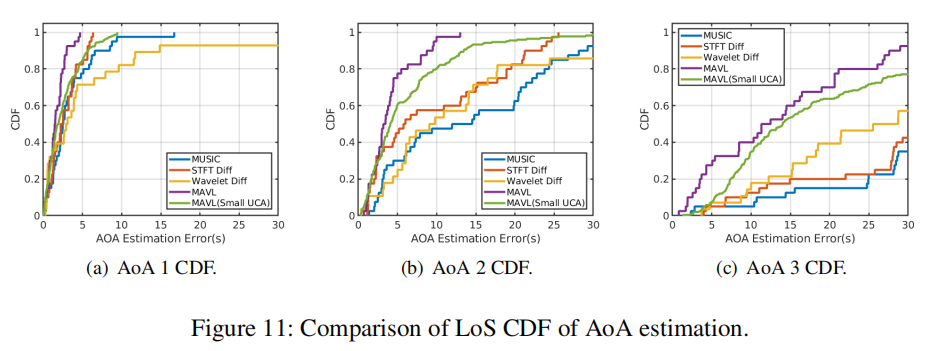
视距和非视距的AoA精度:接下来我们在三个房间进行实验。图11显示了六种方法对所有实验中前3个角度的视距AoA估计误差的CDF。我们使用一个半径为9.6厘米的大型UCA,可与亚马逊Echo Studio、谷歌Home Max和苹果HomePod媲美。我们的方法对前两条路径的中值误差分别为1.49°和3.33°。这种精度足以进行回溯。相比之下,MUSIC对应的数值为2.55°和14.54°,明显较差。
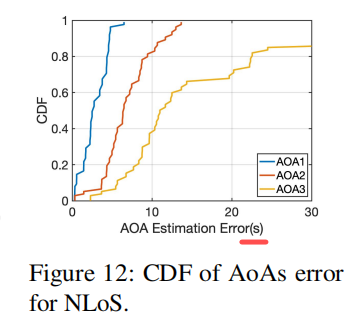
我们还使用半径为5cm的较小UCA评估了MAVL,其大小与Echo Dot、Amazon Echo和Google home相当。图13将第一条路径的AoA精度与使用小型UCA的MAVL、仅使用ICA算法的VoLoc和使用联合估计的VoLoc进行了比较。采用我们的方法,第一条路径的AoA误差中值为1.98°,第二条路径的AoA误差中值为4.08°,均大于较大UCA的误差中值1.49°和3.33°。相比之下,Voloc在联合优化前后的中值误差分别为18.04°和5.28°,远远大于MAVL。

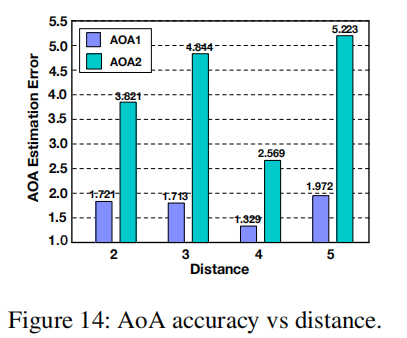
AoA性能与距离: 图14绘制了在7.5m × 5.1m的会议室中,用户与智能扬声器之间的距离与AoA误差的关系。总的来说,当用户离开麦克风阵列时,精度会略有下降。声音的信噪比并不是一个严重的问题,因为它的频率很低,在空气中衰减很慢。当用户靠近房间中央时,在距离约4m处收集测量值,这使得反射路径的传播延迟与直接路径分离,并减轻相干效应。当用户靠近墙壁时,在更大的距离(例如5m)采集数据,且直接路径和反射路径之间的差异较小,这使得在MUSIC剖面中更难分离。
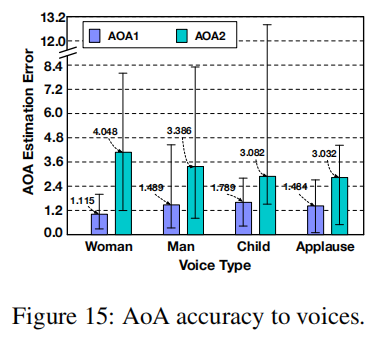
不同声音的表现: 我们把测量结果分为四组:男人、女人、小孩和掌声。图15显示了对不同用户声音的敏感性。这些条位于平均误差的中心,它们的两端表示所有轨迹的最小值和最大值。我们的系统在用户和他们发出的声音中都相当健壮。我们还对掌声进行了评估,发现两条路径的AoA误差分别为1.4°和3.0°。掌声声音的AoA误差较小,因为它比人声短,这降低了相干性并提高了AoA估计精度。
智能扬声器位置的影响: 麦克风阵列和墙壁之间的相对位置直接影响多个传播路径。VoLoc要求麦克风阵列靠近墙壁,以确保前两条路径比其他路径来得早。我们评估了MAVL对智能扬声器位置的鲁棒性。我们在三个位置评估UCA设置:
(1)中心:距离最近的两面墙2.35米和2.92米;
(2)靠近一面墙:距离最近的两面墙0.3m和2.4m;
(3)转角:距离最近的两面墙0.26m和0.39m。
当智能扬声器位于中心、靠近一面墙和转角时,MAVL(第一条路径)直接路径的AoA中值误差分别为1.80°、1.97°和2.08°;第二路径AoA的误差分别为3.07°、4.51°、4.37°。MAVL在中信表现最好,在转角处表现最差。后者是因为第二和第三条路径的信噪比相当,AOA更接近直接路径,从而增加了相干性。但总的来说,它对不同的布局相当健壮。相比之下,当UCA靠近一面墙放置时,VoLoc在联合优化前的中值AoA误差为18.04°(对于直接路径)。它不能在中心或转角工作。只有当UCA靠近一面墙而用户不靠近任何一面墙时,VoLoc才有效。
; 5.2 Performance of Room Estimation
(房间评估的性能)
接下来,我们使用不同的房间大小和麦克风放置来评估我们的房间结构估计算法。
总体房间估算性能: 我们使用的房间尺寸为2.5m×3.5m、3.5m×4.0m和5.1m×7.5m。所有墙壁的中间距离误差为2.8cm,方位角误差为1.8°。我们可以利用房间形状的知识将方位角误差减少到1.4°(即,对于矩形房间,墙壁的方位角相差90度)。VoLoc联合估计墙参数。我们按照VoLoc的设置,UCA靠近一面墙。我们使用5个命令来找到最佳参数。距离误差为2.5cm,方位误差为12°。它的性能对初始样本的选择和窗口大小非常敏感。
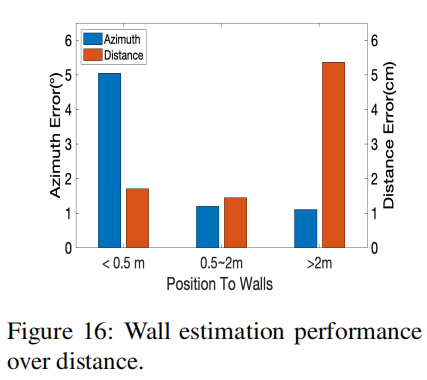
智能扬声器位置的影响: 我们还改变智能扬声器在房间中的位置,以评估其影响。当我们将智能扬声器与墙壁之间的距离从5cm变为20cm时,我们在图16中绘制出中值AoA和距离误差。我们发现在距离误差和方位误差之间有一个有趣的平衡。对于最短距离(< 0.5m),距离误差较小,为1.5cm,方位误差较大,为5.1°。对于最远距离(> 2m),方位误差为1.1°,距离误差为5.4cm。较远壁的距离误差对最终定位误差影响不大,因为来自该壁的反射信号总是具有更低的信噪比,并且这些结果很少用于回溯(追踪)。
5.3 Overall localization results
(整体的定位结果)
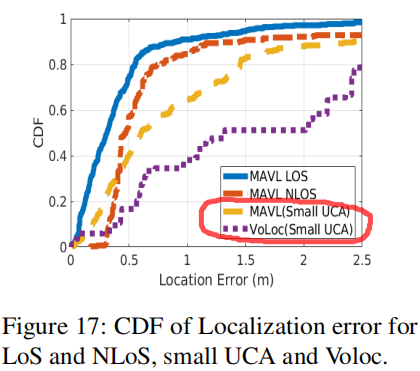
定位精度: 图17显示了在LoS(蓝线)和NLoS(橙线)情况下,MAVL定位误差的CDF。在我们的评估中,在所有范围和环境中,视距和非视距的中值误差分别为0.31m和0.47m。与视距相比,非视距情况下的精度略有下降,因为绕射路径的信噪比较低。在MAVL中,较小UCA的总体定位误差为0.56m。VoLoc报告了在视距下的总体中值误差为0.44米,大距离(>4米)的中值误差为1.7米。在我们的设置中,我们将智能扬声器靠近一面墙,这是VoLoc唯一可以工作的设置,并找到1.32 m的中间误差。由于距离和环境不同,此误差可能大于中报告的错误。
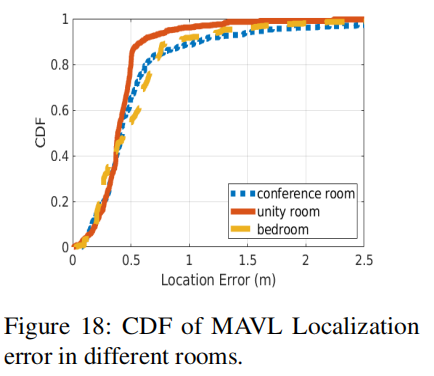
不同房间的性能: 图18显示了不同房间中定位错误的CDF。我们选择了三种具有代表性的环境:一个7.5米x 5.1米的会议室,有一张大桌子和许多椅子;一个4米x 3.5米的卧室,带有强反射器,如显示器和木制家具;一个3.5米x 2.5米的多功能室,带有软反射器。我们可以看到,定位误差随着房间大小和强反射器数量的增加而增加。房间越大,信噪比越低。对于大房间中的许多位置,反射路径的方向彼此接近,这使得分离不同路径更加困难。墙壁和大型家具的强烈反射可能会在MUSIC剖面中产生合并的峰值。然而,对于复杂的卧室,MAVL仍然达到0.45米的中间误差。
UCA大小的影响: 如前所述,较小的UCA大小会降低AOA的准确性。较小UCA的总体定位误差为0.56m。图17中的黄线显示了小型UCA在我们的系统中是如何工作的。尽管其比较大的UCA尺寸更差,但该误差仍然可以支持许多室内定位应用(例如,为语音识别和波束形成提供有用的上下文信息以增强信噪比)。
UCA不同位置的影响: 麦克风阵列的位置对房间轮廓估计和源AoA估计都有影响。我们将UCA放置在三个预定义的位置,即中心、靠近一面墙和转角,并评估我们的系统。中心、靠近一面墙和转角处的定位误差中值分别为0.41m、0.59m、0.76m。当UCA位于中心位置时,我们的系统工作得最好。由于相干性增强,如果将UCA放置在转角处,则精度会显著降低。当UCA靠近一面墙放置时,VoLoc报告总误差为0.44m,超过4m的误差为1.7m。但在我们的设置中,房间大小和距离都较大,VoLoc产生的中值误差为1.32米。VoLoc依赖于直接路径和来自背面封闭墙的反射路径。当使用这两条路径回溯时,一个小的AoA误差可能会导致一个大的定位误差。注意,重要的不是到墙的绝对距离,而是到墙的距离和房间大小之间的比例。例如,对于5.1m×7.5m的房间,距离墙壁0.5m被视为较近,对于2m×3m的房间,距离墙壁0.5m被视为较大。我们的系统在中心位置最有效,但也适用于其他位置。因此它可以支持更灵活的放置。
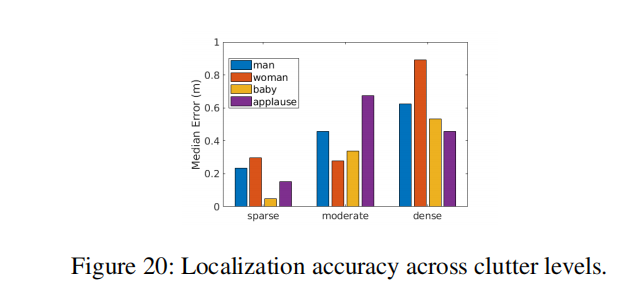
杂乱水平的性能: 附近物体引入多路径,这使得AoA估计更具挑战性。图20显示了杂波水平如何影响不同类型语音的最终定位错误。正如我们预期的那样,增加杂乱水平会增加定位误差。

噪声级性能: MAVL对不同背景噪声具有鲁棒性。图21显示了不同背景噪音和噪音等级的影响。即使信噪比低至-10dB,白噪声也会略微降低准确度,背景音乐的影响比白噪声更大,因为歌曲中有人声。我们的方法对于背景音乐是相当稳健的,除非信噪比太低(例如,
; 6. Related Work
声学传感: 已经提出了许多利用声学信号跟踪移动设备的系统。最近有几个系统使用声音信号实现无设备跟踪。许多系统产生不可听见的声音用于运动跟踪。有些使用多普勒频移(例如AAMouse)、飞行时间(例如BeepBeep)或组合(例如CAT)。Covertband主动发送基于OFDM的听不见信号,并建立在MUSIC之上,以提高感知能量。BreathJunior将FMCW编码为白噪声以检测婴儿的运动和呼吸。这些系统需要控制传输的声音信号,不适合跟踪人的声音。与我们最相关的工作是VoLoc。我们的工作在几个重要方面推动了VoLoc。首先,我们利用时频域的多分辨率分析,将AoA精度从10度提高到1.5度。其次,提出了一种新的空间轮廓自动估计方法。这大大简化了部署工作。第三,我们可以在LoS(视距)和NLoS(非视距)定位用户,而他们只支持LoS。
基于射频的定位: 基于射频的定位方法的准确性主要受到商品WiFi基础设施的大波长和传播速度快的限制。Chronos可以通过反转NDFT实现分米级定位精度。Spotfi采用了新的滤波和估计技术来识别直接路径的AoA。Arraytrack[48]设计了一种新的多径抑制算法,以消除客户端和AP之间的反射。然而,它们使用三个以上的接入点和16根天线,并且需要控制发射的信号。此外,他们的方法侧重于消除多路径,而不是单独估计每个多路径。
声源定位: 目前已有一些声源定位工作。[14]搭建了一个实时系统来检测不同声源的AoAs。[2]需要一个Kinect深度传感器来建立一个空房间的3D网格模型。该算法利用立方体麦克风阵列估计多径AoAs,并进行三维反向射线跟踪来定位语音。其定位误差约为1.12m。[1]考虑了衍射路径,并将均匀衍射理论应用于语音定位。其误差为0.82m。这些工作要么需要多个专门的传感器来获取室内环境,要么只估算AoAs而不是定位。它们没有解决多路径产生的相干性,因此它们的AOA不可靠。MAVL可以使用单个智能扬声器定位用户,而无需额外硬件,并明确解决多路径的一致性问题。
视听室内表示学习: 最近的工作将声音和视觉结合在多模态学习框架中,以更好地理解环境,从而能够跟踪视听目标,定位视频中与声音相关的像素,并导航室内环境。VisualEchoes发出3毫秒的啁啾声,将多路径和不同位置的图像组合在一起,在无需人工监督的情况下学习空间表示。Soundspaces将多模态深度强化学习应用于以自我为中心的视听观察流。我们的工作使用一个独立的智能扬声器,不需要视觉数据或预先训练。
- Conclusion
在本文中,我们开发了一个系统,MAVL,使用类似智能扬声器的设备根据用户的语音对用户进行定位。我们的设计包括一种新的基于多分辨率的AoA估计算法、一种易于使用的基于声学的房间结构估计方法以及一种基于估计的AoA和房间结构的鲁棒回溯来定位用户。我们使用不同的声源、房间大小、智能扬声器设置、噪声和杂波水平来评估MAVL,以证明其有效性。
8.ACKNOWLEDGMENTS
这项工作得到了NSF资助CNS-1718585和CNS-2032125的部分支持。我们感谢Shyam Gollakota教授和匿名评论员提出的富有洞察力的意见和建议。
Original: https://blog.csdn.net/me_andy/article/details/120666893
Author: Hermione’
Title: 论文阅读:MAVL: Multiresolution Analysis of Voice Localization
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/515980/
转载文章受原作者版权保护。转载请注明原作者出处!