

声纹识别,也称为说话人识别(speaker recognition),是一种基于语音中能表征说话人的信息,来判别说话人身份的生物特征识别技术,相比其他生理特征在远程身份认证中具有先天优势。
拨云见日–初识声纹
生活中对于声纹最直观认识就是:我们在打电话时,一声”喂?”就能分辨出接电话的人是谁。从直觉上来讲,说话人语音的差异并不如人脸、指纹的差异那么直观,但是由于每个人的声道、口腔、鼻腔都各具差异,这些个体差异可以直接反映到人们的发音上。
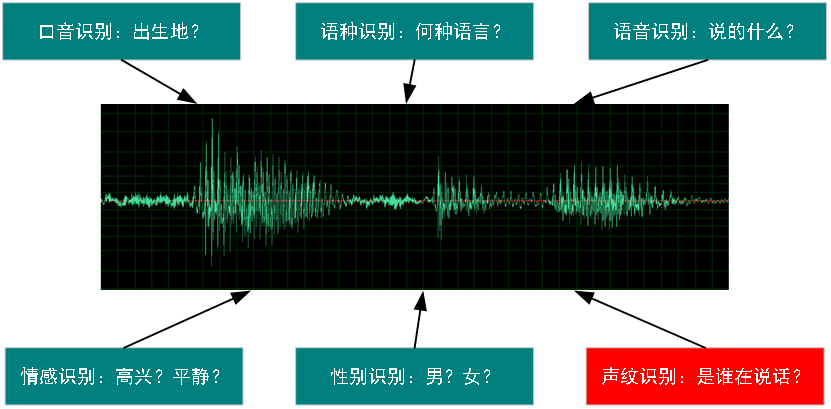
人脸识别和指纹识别都是基于图像的二维信号,而语音是一种时变的一维信号,其表现形态简单,但蕴含的语音信息非常丰富。以下图为例,展示的是贝壳的唤醒词”hey,小贝”的时域波形图,其承载的首先是语意信息,即唤醒词,其次它还可以包含语种(中文、英文)信息,性别信息,情感信息(高兴、悲伤……)等等,而在这成百上千的语音信息背后只对应了一个唯一不变的身份信息。

继续观察”hey,小贝”的波形特征,比较不同人说话之间的差异。图1是说话人A对应的”贝”,图2是说话人B对应的”贝”,
Original: https://blog.csdn.net/weixin_32047681/article/details/112415288
Author: 科学火箭叔
Title: 语音识别中代价函数_【语音算法系列】声纹识别助力身份认证
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/515719/
转载文章受原作者版权保护。转载请注明原作者出处!