

python+keras单字语音识别
一、两种思路
就目前的研究而言,语音识别有两种方法。
[En]
As far as the current study is concerned, there are two ways of speech recognition.
1、将语音文件提取mfcc,即转为二维张量形式,然后进行dense全连接层叠层训练,当然这个也可以使用传统机器学习方法。
转为二维张量格式为:
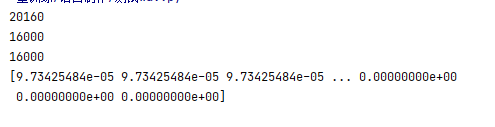

2、将语音文件提取mfcc转为三维张量形式即频谱图,然后进行cnn卷积神经网络训练,看了几个资料,这个似乎准确率更高,但是比较麻烦
因此,请尝试下面的第一种方法。
[En]
So try it in the first way below.
频谱图形式为:

; 二、代码更新
采取第一种思路的代码为大佬南方朗郎:《python+keras实现语音识别》,这个代码有些小问题
1、keras版本问题
报错
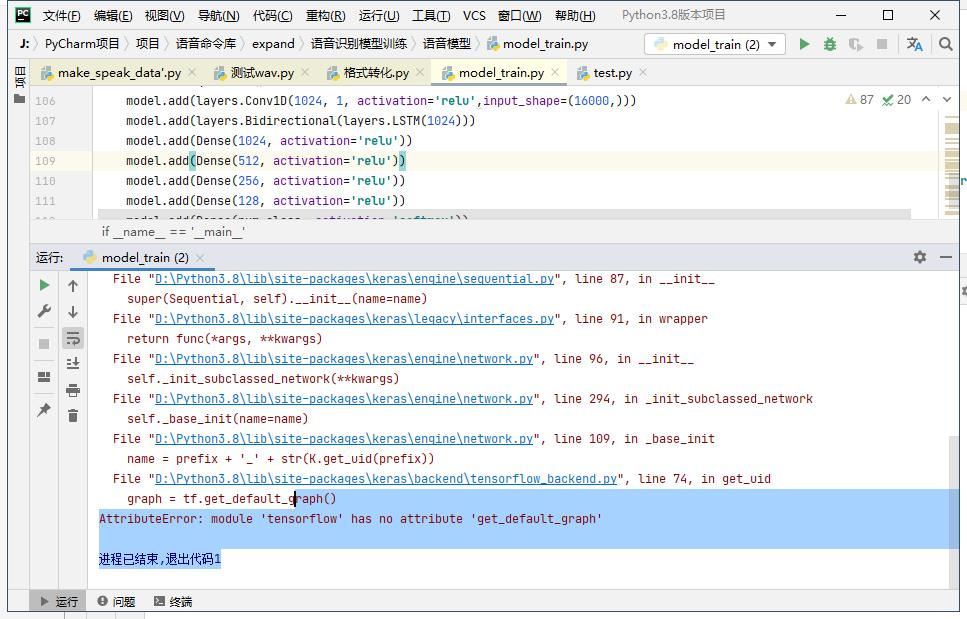
准确的说,这个不是keras版本问题,应该是tensorflow版本的问题,tensorflow是keras的后端,我的python版本是3.8,所以安装的tensorflow版本是2.0以上的,而作者源码是建立在keras后端tensorflow1.0以上的版本,所以出现这样的错误,这样的错误会很多,一个个修改非常麻烦,但是python3.8好像没有支持的tensorflow1.0以上的版本,只有2.0以上的版本。
不过,幸运的是,我有两个python版本,一个3.7,一个3.8,python3.7有支持的tensorflow1.0以上的版本,于是我用python3.7安装了tensorflow1.15.5版本的tensorflow,
这个问题得以解决
2、代码有部分出现缺漏
报错

这个报错是由于num_class没有传递过来,导致label标签one-hot化不成功
打印num_class时发现num_class=0,应该为2的
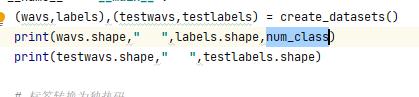

将之传递过来

模型正常训练
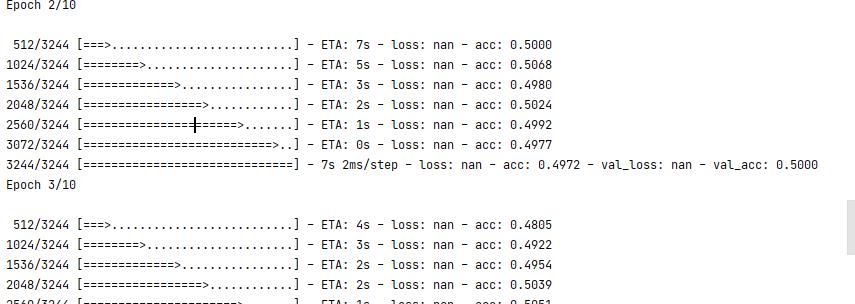
但精确度并不高。笔者曾提到,似乎是因为数据本身的原因,有些数据出现了问题。
[En]
But the accuracy is not good. The author has mentioned that it seems to be because of the data itself, and there are problems with some data.
3、代码特征处理会报list index out of range
这一行

不需要修改作者运行的语音数据集,因为它都是16000,但如果你运行自己的数据集,你必须修改它,因为它不一定是16000。
[En]
There is no need to modify the voice data set run by the author, because it is all 16000, but if you run your own data set, you have to modify it, because it is not necessarily 16000.
修改为:
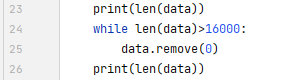
data.remove(0)
dense层模型调控最优的结果为测试集上93%左右
设置为:
model = Sequential()
model.add(Dense(1024, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(512, activation='relu'))
model.add(Dense(256, activation='relu'))
model.add(Dense(128, activation='relu'))
三、汉字语音识别
1、数据集问题
该数据集使用百度语音合成来合成3500个常用汉字,每个汉字大约有8个不同的说话人,然后进行数据增强。
[En]
The dataset uses Baidu speech synthesis to synthesize 3500 commonly used Chinese characters, each with about 8 different speakers, followed by data enhancement.
数据增强主要是对波形、位移以及加噪等处理,可以参见大佬凌逆战:《音频数据增强及python实现》链接: 音频数据增强及python实现.
2、跑的结果
三个数据集,每个数据集有32个音频文件,总共96个,训练集85个,测试集15个,三个分类样本数据平均,测试集结果1.0。
[En]
Three data sets, each data set has 32 audio files, a total of 96, training set 85, test set 15, three classification sample data average, test set result 1.0.


3、问题
这里的问题是,数据增强的体积只是暂时使用的,所以测试集和训练集可能没有差异,导致了这个结果,并且经过噪声添加、波形延伸等之后,精度可能会迅速下降。
[En]
The problem here is that the volume of data enhancement is only used for the time being, so there may be no difference between the test set and the training set, resulting in this result, and the accuracy may decline rapidly after noise addition, waveform elongation, and so on.
Original: https://blog.csdn.net/python__reported/article/details/113406613
Author: python__reported
Title: python+keras汉字单字语音识别
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/515264/
转载文章受原作者版权保护。转载请注明原作者出处!