

Voice Recognition
2021年3月21日
HowardXue
语音模型发展:模板匹配(DTW) -> 统计模型(GMM高斯-HMM隐马) -> 深度学习(DNN-HMM,E2E)
音频编码:常用格式PCM的wav格式
语音采样率8khz 或16khz
6阵列mac 声源定位 有空间指向性,定位后,可有效抑制其他方向的声音干扰(旁边的其他人声音)
开源工具:HTK,Kaldi, Espnet(python)
音速序列:英语48个音素 20元音 28辅音,汉语32个音素,10个元音
离散傅里叶变换(DFT) 时域信号 -> 频域信号, 逆傅里叶变换 将频域信号恢复为时域
实际可以用快速傅里叶变换(FFT) 简化计算复杂度
加窗:分帧处理
常用的声学特征:MFCC,FBank,语谱图
HMM马尔科夫链:只根据当前事件,预测下一事件。 –双重随机过程
HMM是声学模型 -> 语音数据
RNN是语言模型 -> 文本数据,词与词之间的组合概率关系,基于统计语言模型
解码器:传统动态网络解码器Viterbi -> WFST静态网络解码器
WFST把发音词典、声学模型、语言模型(三大组件)合并成统一的静态网络 ->解码速度快
DNN的输出节点与HMM的状态节点一一对应,通过DNN的输出得到每个状态的观察值概率
不同音素(a e I …o)统一关联到DNN的输出节点
DNN使用CNN:语谱图 -> 变为图像处理,提取时域、频域feature map局部特征
RNN – LSTM, GRU
TDNN时延神经网络
CNN – TDNN-F 组合网络,CNN先提取局部频域特征,然后TDNN-F提取上下文的时域特征
E2E ASR Model,只需要输入端的语音特征和输出端的文本信息,将传统ASR三大组件融合成一个网络模型
E2E常用模型:CTC、RNN-T、Transformer
RNN-T联合建模:语音识别+说话人区别(识别后的文字后带有说话人ID)
Attention机制跟人类翻译文章时候的思路有些类似,即将注意力关注于我们翻译部分对应的上下文
序列对序列问题(sequence-to-sequence, seq2seq),通过Encoder/Decoder对输入特征和输出结果进行序列建模
加入Attention机制,改进了seq2seq,
Espnet,特征提取:直接用kaldi原生脚本,可以进行MFCC/FBank/PLP特征的提取
特征提取后,还需对特征进行倒普均值归一化(CMVN)来使特征服从高斯分布(均值为0,方差为1)
语音数据增强:音量干扰和速度干扰(变速)
[En]
Voice data enhancement: volume disturbance and velocity disturbance (variable speed)
词典生成:数字对应字符
data2json.sh: 映射文件都打包保存在data2json.sh脚本中
Train.yaml:训练配置文件,例如选择哪个声学模型,选择CTC/Attention/Transformer结构等
Lm_train.py:语言模型训练,输出是:rnnlm.model.best
Asr_train.py: 声学模型训练
默认使用的编码器:BLSTM
Asr.recog.py: 语言识别解码器
模型部署到Edge:编译Kaldi生成动态库.so/dll -> 嵌入式ARM Linux平台编译移植Kaldi
Transformer:
Transformer: 在每个Decoder和Encoder中都采用Attention机制,特别是在Encoder,把传统的RNN完全用Attention替代
Transformer 本质上还是seq2seq结构:


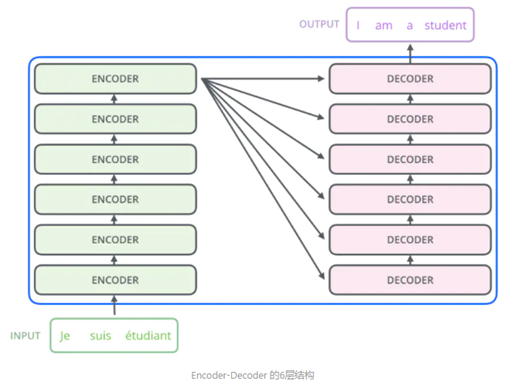


未完待续。。。
Original: https://blog.csdn.net/HowieXue/article/details/117389549
Author: HowieXue
Title: 语音识别 平常笔记
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/515238/
转载文章受原作者版权保护。转载请注明原作者出处!