

说话人识别综述阅读
Deep learning methods in speaker recognition: a review
摘要
本文总结了深度学习在验证和识别领域的应用实践。语音识别是语音技术广泛应用的课题。在过去的5-6年里,已经开展了许多研究工作,但进展甚微。然而,随着深度学习技术在大多数机器学习领域的进步,以前的最先进的方法在说话人识别方面也被它们所取代。深度学习似乎成为了现在最先进的说话者验证和识别的解决方案。标准的x向量,除了i向量,在大多数新作品中被用作基线。收集的数据数量的增加为DL开辟了领土,在那里它们是最有效的。
介绍
Speaker identification (SI) and verification (SV)
它是一个热门的研究课题,有着广泛的应用,如安全、取证、生物特征认证等。目前,这方面的研究很多,也提出了很多方法,所以这一领域最先进的技术还相当成熟。
[En]
It is a popular research topic with a variety of applications, such as security, forensics, biometric authentication. At present, there is a lot of research in this field, and many methods have been proposed, so the most advanced technology in this field is still quite mature.
如今,随着深度学习的硬件解决方案,深度学习(DL)的普及不断上升,它开始渗透到适用机器学习的每一个主题中。所以这是非常自然的使用深度学习的方法进行说话人识别。
本研究的目的是从最早的解决方案到最新的解决方案,对应用于说话人识别和确认任务的深度学习方法进行综述。
[En]
The purpose of this study is to review the deep learning methods applied to speaker recognition and verification tasks from the earliest to the latest solutions.
说话人的识别( identification)与验证(verification )
说话人识别是从一组已知的说话人中识别出一个未知的说话人的任务:找到其声音最接近测试样本的说话人。
[En]
Speaker recognition is the task of identifying an unknown speaker from a group of known speakers: finding the speaker whose sound is closest to the test sample.
当给定集合中的所有说话人都已知时,这称为闭合集合(或集中)场景。或者,如果这组已知说话人可能不包含潜在的测试对象,则称为开放集合(或集合外)说话人识别
[En]
When all speakers in a given set are known, it is called a closed set (or centralized) scenario. Or, if this set of known speakers may not contain potential test objects, it is called open set (or out-of-set) speaker recognition
在说话人验证中,任务是验证自称具有身份的说话者是否真的属于该身份。 换句话说,我们必须验证对象是否真的是他或她所说的那个人。 这意味着比较两个语音样本/话语,并确定它们是否由相同的说话者说出来。 这是 – 在一般说话人验证实践中 – 通常通过将测试样本与给定说话人的样本和通用背景模型进行比较来完成(Reynolds 等,1995)。
数据库
所用数据库的问题很严重。很难评估和比较不同方法的性能,如果数据不一致,则训练和评估数据集需要不同的考虑。
[En]
The problem with the database used is critical. It is difficult to evaluate and compare the performance of different methods, and if the data are inconsistent, training and evaluating data sets require different considerations.
在表I中,列出了当前可用的组合以及它们公开发现的不同属性。有些一些数据集是免费的,有些只免费用于研究。 ????表1呢
主要为自动语音识别(ASR)而创建的绳索也可以用于训练(和评估)SR方法,然而,大多数研究使用的数据集特别是关注说话者识别和验证领域。
语音识别和说话人识别的训练集不同,语音识别包含更多的语音信息和更少的说话人信息,而说话人识别拥有尽可能多的说话人,减少了每个人的记录材料。
[En]
The training sets of speech recognition and speaker recognition are different, speech recognition contains more speech information and less speaker information, while speaker recognition has as many speakers as possible and reduces the recording material of each person.
说了一些数据库情况,使用干净的数据库进行训练测试,从现实世界的使用角度来看可能不太合适,但也适合于评估SR方法和特性
较短的历史:GMM-UBM和i-向量
第一种自动说话人识别方法是基于高斯混合模型(GMM),GMM是高斯概率密度函数(PDFs)的组合,通常用于建模多变量数据,它使用无监督的方法来聚类数据,并给出高斯概率密度函数,通过对未知样本的概率函数估计,就可以知道说话者。
GMM是由一些均值向量、协方差矩阵和权值参数化的高斯PDFs的混合物:
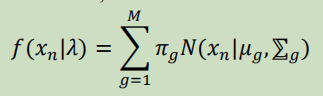

第g个混合分量的权重、平均向量和协方差矩阵
对于一系列声学特征,其概率计算如下
[En]
For a series of acoustic features, their probabilities are calculated as
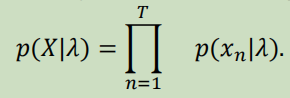
; GMM 超向量
由于语音样本可能有不同的持续时间,因此我们在开发可以从可变长度的样本中获得固定数量的特征的方法中投入了大量的精力。在说话人识别中表现最好的方法之一是形成GMM超向量(坎贝尔等。al,2006)。
超向量是通过连接GMM(平均向量)的参数来创建的。这个固定长度的”超向量”被赋予了一种强制性的机器学习技术。在深度神经网络开始得到广泛关注之前,支持向量机(SVM)(Cortes和Vapnik,1995)被发现是性能最好的技术。
i-向量
语音识别的,先不写…
LR test
它是关于说话人验证的,现在还不要写。
[En]
It’s about speaker verification, and don’t write it yet.
说话人验证的测量
在说话者识别(特别是在验证中)中,有两种相似性度量,如果测试观察结果是否来自目标说话者,它们通常被用来计算概率。几乎所有新的DL方法都使用这些度量(在说话者验证方案中):向量的余弦距离和PLDA(概率线性判别分析)。
余弦距离
余弦距离只是简单地计算目标和测试i向量( 𝑤 𝑡𝑎𝑟𝑔𝑒𝑡 and 𝑤 𝑡𝑒𝑠𝑡 )的归一化点积,它提供了一个匹配分数
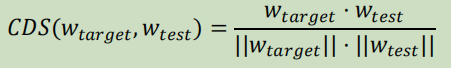
; 概率线性判别性分析PLDA
LDA(线性判别分析)(Bishop,2006)用于寻找正交轴,以最小化类内变异和最大化类间变异
PLDA,作为LDA的扩展(Tipping和Bishop,1997;Ioffe,2006),是一种采用同一方法的概率方法
PLDA有能力被应用于比较任意向量,所以它被用于DL方法中。在这里,我们使用传统的i向量方法作出了一个简要的描述。
给定一组d维长度归一化的i向量𝑋 = {𝑥𝑖𝑗; 𝑖 = 1, . . . , 𝑁;𝑗 = 1, . . . , 𝐻𝑖} 从n个说话者,i-向量可以被写成下面的形式:

其中𝑍={𝑧𝑖;𝑖=1,…,𝑁}为潜在变量,𝜔={𝜇,𝑊,𝛴}为模型参数,𝑊为𝐷𝑥𝑀矩阵(称为因子加载矩阵),𝜇is为𝑋,𝑧𝑖’的全局均值称为说话人因子,𝜖𝑖𝑗为均值和𝛴协方差为零的高斯分布噪声。
给定一个测试i向量𝑥𝑡 和,一个目标说话者i向量𝑥𝑠,可以计算LR分数:
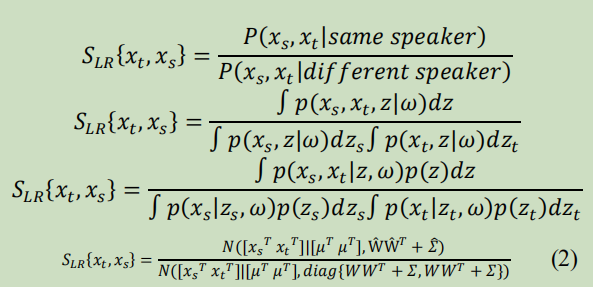
其中W=[𝑊𝑇𝑊𝑇]𝑇and𝛴=𝑑𝑖𝑎𝑔{𝛴,𝛴}。使用方程。(2)和块矩阵逆的标准公式,对数似然RL评分由(Ioffe,2006)给出:
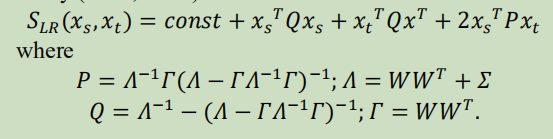
说话者识别中的深度学习
一般来说,说话者识别中的深度学习有两个主要方向。 一种方法是用深度学习方法代替i-向量计算机制作为特征提取。这些工作使用声学特征(如MFCCs或光谱)作为输入,说话者id作为目标变量,对说话者样本进行训练网络,通常使用内部隐藏层的输出作为i向量替代, 并应用余弦距离或PLDA作为决策。 另一种主要策略是使用深度学习进行分类和决策,比如用有区别的深度网络取代余弦距离和PLDA。
自动说话人识别系统的性能通常通过等误差率(EER) 和决策成本函数(DCF)来评估
EER是一个生物识别安全系统算法
当比率相等时,共同值被称为 相等错误率。 该值表示错误接受的比例等于错误拒绝的比例。 等错误率值越低,生物识别系统的准确度越高。 或者,决策成本函数考虑目标说话人出现的先验概率、目标和非目标说话人的比例。检测成本函数是区分和校准的同时度量。 通常,DCF 曲线的最小值称为 minDCF。
用于特征提取的深度学习
(Chen and Salman, 2011)使用具有多个子集的深度神经网络创建瓶颈特征(说话人模型),每一个子集都是一个深度的自动编码器。
提出了一种混合学习策略:通过代价函数在多个输入(相邻帧)之间分担中间层的权重:
[En]
A hybrid learning strategy is proposed: the weight of the middle layer is shared among multiple inputs (adjacent frames) through the cost function:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-b00frHj5-1631870164079)(E:\book\blog\说话人识别综述阅读\image-20210917142119013.png)]
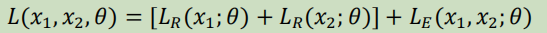
𝐿𝑅(𝑥𝑖; 𝜃)是输入i的经过网络的损失, 𝐿𝐸(𝑥1, 𝑥2; 𝜃) 是一个损失函数,优化学习相同的说话人表示(模型),从中提取说话人模型特征。
实验采用TIMIT、NTIMIT、KING、NKING、CHN和Rus数据集。结果表明,该方法在所有数据集的情况下都优于GMM-UBM基线系统
; d-向量
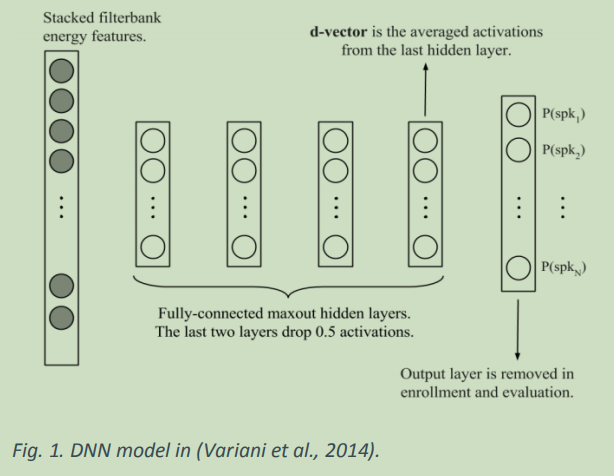
在(Variani等人。al,2014)选择具有多个完全连接层的网络的 最后一个隐藏层的平均激活作为特征,称为”d向量”
d-向量的使用方式与i-向量的使用方式相同,说话人通过余弦距离进行验证。首先,利用13维感知线性预测(PLP)特征,附加Δ和ΔΔ值作为帧级特征向量
最后的输出层被删除,并且激活函数之后的最后一层的值被用作特征。
[En]
The last output layer is deleted, and the value of the last layer after the activation function is used as a feature.
结果表明,一般的i向量系统主要优于新提出的d向量系统。
j-向量
很难直接识别说话人,但实际上,不同的说话人在每个音节或单词上都有自己的风格。
[En]
It is difficult to identify the speaker directly, but in fact, different speakers have their own style on each syllable or word.
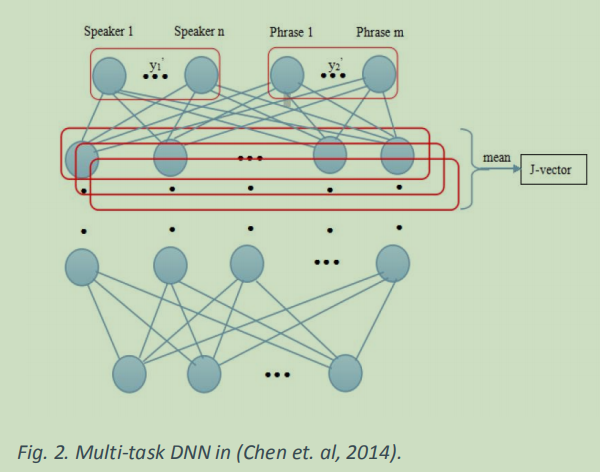
因此,不仅在多学习设置中,使用说话者id,而且使用文本作为目标,可以提高说话者的验证性能。
损失函数:
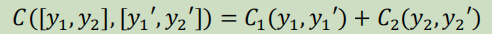
C 1 C_1 C 1 和C 2 C_2 C 2 是是说话人和文本的两个交叉熵标准,y 1 y_1 y 1 和y 2 y_2 y 2 是说话人和文本的真是标签,y 1 , y_1^,y 1 ,和y 2 , y_2^,y 2 ,是两个目标值的输出。
提取特征的方法和d-向量一致。去除输出层,并将最后一个隐藏层的输出作为特征向量,定义为j向量(联合向量)。
RSR2015 database 上进行训练。结果表明,j向量方法优于d向量方法。d向量和j向量的EERs分别为21.05%和9.85%
; x-向量
另一个隐藏层提取的特征向量称为x向量(Snyderetal.,2018;Fang,2019)。
它基于DNN嵌入,它采用了多层DNN体系结构(具有完全连接的层),每个层都有不同的时间上下文(他们称之为”框架”)
由于更广泛的时间上下文,该架构被称为时间延迟神经网络 (TDNN)。
主要结果表明,x向量优于一般的基于ivector的系统(i向量和x向量的eer分别为9.23%和8.00%)。
对于短言语话语,(Kanangundaram等,20al.,2019)将第六层和第七层(”第6段”和”第7段”)的维度改为150,以适应较短的持续时间。结果发现,在5秒长话语的情况下,片段6和片段7的较低维度有助于说话者验证,但在原始长话语上获得了较高的EER(使用NISTSRE2010数据集)。另一方面,(Garcia-Romero等人,2019)试图通过DNN细化方法优化长话语(2-4秒)的DNN向量系统,更新DNN参数的子集,并修改DNN架构,生成为余弦距离评分优化的嵌入。结果表明,该方法产生较低的minDCF(最小决策成本函数),但EER略高于基线x向量方法。
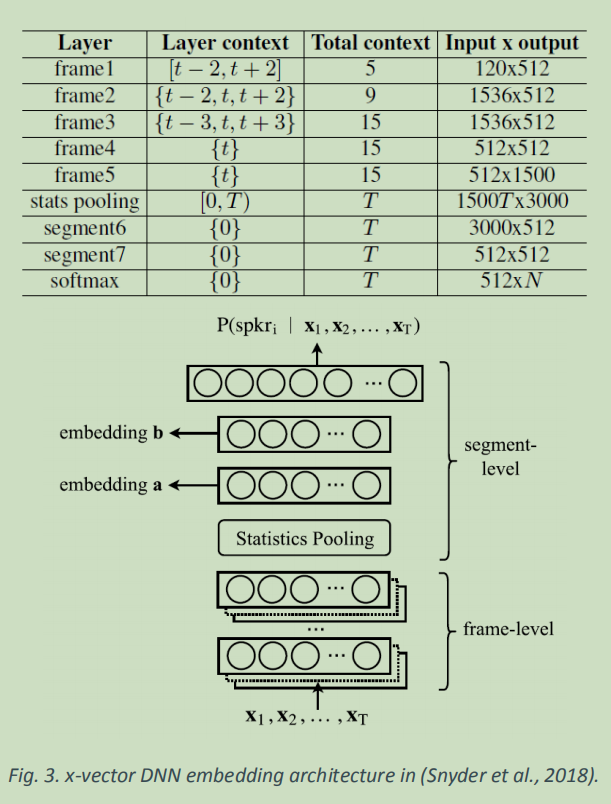
End-to-end systems
为了进行说话人验证,提取嵌入并在标准后端中使用,例如,PLDA。然而,理想情况下,应该直接培训说话者验证任务
(Heigold et al., 2016) 不使用余弦距离或 PLDA 分类,而是应用端到端解决方案进行说话人验证与深度网络,以获得说话人表示向量,基于最多 N 个注册话语估计说话人模型和 也用于验证(余弦相似性/逻辑回归)。 架构如图 4 所示。 DNN(与 d-vector 提取中使用的网络相同)和 LSTM 都应用于说话人表征计算,网络使用端到端损失进行优化:
𝑙𝑒2𝑒 = −𝑙𝑜𝑔 𝑝(𝑡𝑎𝑟𝑔𝑒𝑡)
$𝑝(𝑎𝑐𝑐𝑒𝑝𝑡) = (1 + 𝑒^{−𝑤𝑆(𝑋,𝑠𝑝𝑘)−𝑏})−1 $, 𝑝(𝑟𝑒𝑗𝑒𝑐𝑡) = 1− 𝑝(𝑎𝑐𝑐𝑒𝑝𝑡)
具有验证阈值的值−𝑏/𝑤对应。𝑆(𝑋,𝑠𝑝𝑘)是说话者表示和说话者模型之间的余弦相似性。
‘ok, google’ dataset with more than 73M utterances and 80 000 speakers.
结果表明,如果使用相同的特征提取器(DNN),则端到端架构的性能与d向量方法相似
然而,与DNN方法相比,LSTM降低了EERs:DNN和LSTM的EERs分别为2.04%和1.36%
在 (Yun et al., 2019) 中提出了另一个端到端系统,其中训练是通过 余弦相似性辅助的三元组损失完成的。 说话人嵌入网络接受原始语音波形的馈送,生成 嵌入向量。 该网络使用 LibriSpeech 通过 1.5-2.0 秒 uttarence 块进行预训练。 然后使用 CHiME 2013 数据库(Vincent 等人,2013 年)仅使用特定的 2 到 4 个关键字进行说话人验证评估。 关键字由 ASR 确定,该 ASR 以对抗方式用于说话人嵌入系统的训练,迫使嵌入向量与说话人无关。 结果喜忧参半。 三元组损失和 ASR 对抗训练在 2 个关键字的情况下没有提高 EER,只是在检查 3 或 4 个关键字时
; 深信网络
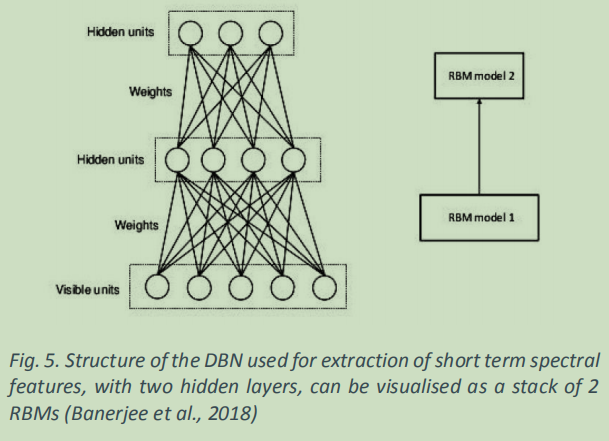
深度信念网络 (DBN) 是另一种用于说话人识别的深度学习网络(Ali 等人,2018 年;Banerjee 等人,2018 年)。 深度信念网络是具有 多层潜在变量的生成模型,这些潜在变量通常是二元的。 同一层中的神经元不相连,相邻层之间的连接是无向的。 由于从隐藏(潜在)层推断后验分布的困难性,DBN 的训练很困难。 堆叠受限玻尔兹曼机 (RBM) 可用作 DBN 架构( 图 5)。 有关更多详细信息,请参阅(Hinton 等人,2006 年)。 DBN 的目标是学习未标记输入数据的抽象层次表示。在(Banerjeeetal.,2018)中,应用PCA变换降维后,将光谱图(25ms窗口大小,10ms时间步长)作为输入语音数据。RBM的第一层和第二层的激活被用作特征(单独的和一起的特征),附加到共同的MFCC特征中。
特征提取后,使用 GMM-UBM 进行说话人识别。 作者使用了 ELSDSR 数据集和 22 个说话者。 基于结果,从 RBM 中提取的特征有助于识别:分别使用单独的 MFCC 和混合的 MFCC+RBM 特征获得 90% 和 95% 的最终准确率。
(Ali et al., 2018) 也使用相同的声学特征提取方法,但它增加了一个 词袋方法,以便 将不同长度的数据转换为相同维度的向量(使用 k 均值聚类技术)。 SVM 被用作分类器。 实验是在乌尔都语数据集 (Appen, 2007) 上完成的,有 10 个说话者。 在这里,混合 (MFCC+DBN) 特征也表现最好:MFCC 和 MFCC+DBN 特征分别获得了 88.6% 和 92.60% 的准确率。
在 (Liu et al., 2015) 中,使用 深度受限玻尔兹曼机 (RBM)、 语音判别深度神经网络、说话人判别神经网络和多任务联合对用于深度特征提取的多种 DNN 方法进行了广泛评估。 学习了深度神经网络。 RBM 的使用方式与上一节相同(Ali 等人,2018 年;Banerjee 等人,2018 年)。 应用语音判别 DNN,文本标签作为训练数据,三音素状态作为目标。 这种情况在依赖于文本的说话人验证任务中很有用。 最后一个隐藏层的输出用作特征。 在说话人判别 DNN 的情况下,语音判别网络的输出更改为说话人 ID。这样,就可以获得一个更特定的说话者的特征集,这是说话者验证的一个更自然的选择。在多任务设置中,前面提到的(说话人id和三角电话)输出都被用作目标。采用使用PLP特征训练的标准i向量系统作为基线(具有余弦相似性的GMM-UBM)。新提出的深度特征分别在RSR2015年的数据集上进行了测试(Larcheretal.,2012年)。
CLNets
在 (Wen et al., 2018) 中,提出了一种深度校正学习网络 (CLNet),通过循环形式来分析独立样本。 每个新实例都会进行校正预测,以更新根据先前数据所做的预测。 这意味着使用增量策略而不是对说话者的片段进行平均结果。 CLNet 使用卷积层进行说话人验证。 NIST SRE 2004-2010 语料库用于实验。 通过使用余弦相似度,与标准 i-vector 系统相比,获得了约 2.5% 的 EER(i-vector、标准 CNN 和 CLNets 的 EER 分别为 7.3%、5.18% 和 4.87%)。 但是,使用 PLDA,i-vector 表现更好。
Text dependency 文本依赖性
尽管如此,i-vector 系统在 独立于文本的场景中仍优于 DNN(Snyder 等人,2016 年)。 因此,以标准 i-vector PLDA 系统为基础,(Rohdin et al., 2018) 提出了一种端到端的 DNN,可以学习 GMM-UBM 的足够统计数据并提供 i-vector。 在网络的第一部分,GMM 后验通过多层架构学习,然后使用标准 i 向量作为目标,以余弦距离作为损失函数
Deep learning for classification 深度学习分类
与其应用深度特征提取来交换公共 i 向量以获得更健壮和性能更好的说话者表示,DNN 还可以用于替换后端系统进行评分和比较(如 PLDA 和余弦距离)。 此类作品在文献中比与特征提取相关的作品更稀少。
Variational autoencoder 变分自编码器
变分自编码器 (VAE)(Kingma 和 Welling,2013 年;Rezende 等人,2014 年)是一种用于信号(和语音)建模的生成模型。 它用于语音转换(Hsu 等,2017a;Hsu 等,2017b)、语音识别以及说话人识别(Villalba 等,2017;Pekhovsky 和 Korenevsky,2017)。 VAE 不仅使用确定性层,还包含随机神经元。 LLR 评分通过以下方式进行:
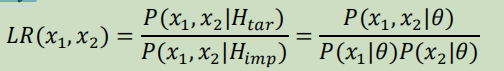
其中,𝐻𝑡𝑎𝑟,𝐻𝑖𝑚𝑝 是假设𝑥1,𝑥2是分别与相同或不同的说话者相关的事实,𝜃是为说话者模型的参数。结果显示,变量似乎并不优于PLDA评分
; Multi-domain features 多域功能
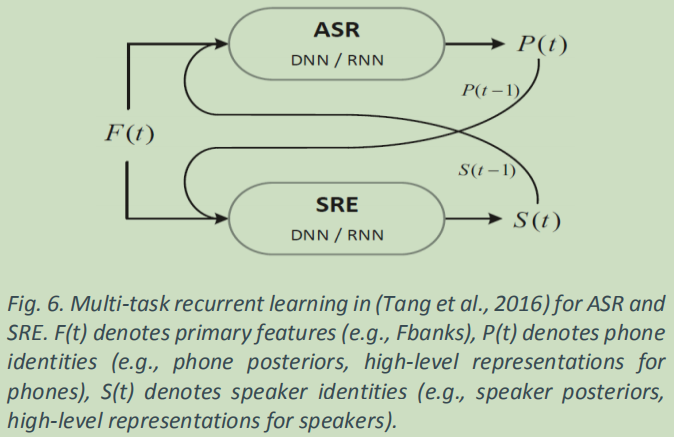
使用文本相关数据来帮助学习说话人 ID 也被用于说话人识别任务中的分类,(Tang 等人,2016)使用 ASR 的输出来提高说话人识别的性能。 图 6 显示了提出的多任务学习。 ASR(phoneposteriors)的输出被送入 SRE 系统,反之亦然。 每个任务的输入是提取的帧级谱(分别用于 ASR 和 SRE 的滤波器组和 MFCC)。 实验是在 WSJ 数据集上完成的。 基于结果,所提出的方法实现了与 i-vector 基线相同或略好的 EER(ivector 和多任务方法分别为 0.57% 和 0.55%)。
Replacing UBM with DNN 用DNN替换UBM
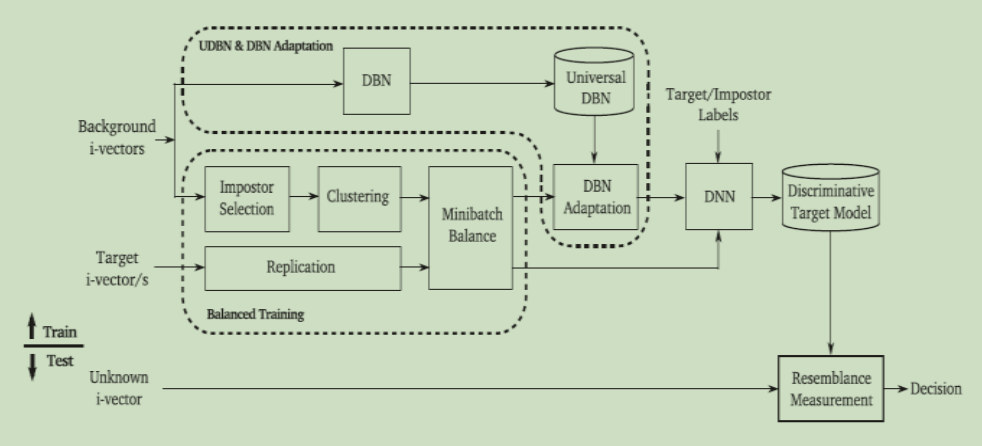
DNN 也可用于替代 UBM。 通用深度信念网络 (UDBN)(Ghahabi 和 Hernando,2017 年)用作后端,其中针对每个目标说话者训练二类混合 DBN-DNN ti 增加了目标 i-vector/s 和 i- 其他 soeakers(非目标/冒名顶替者)的向量。 图 7 显示了所提出方法的训练/测试阶段。 首先,训练一个无监督的通用 DBN,然后通过特殊的平衡训练过程使其适应目标说话者。 在测试阶段,未知 i 向量与适应的目标 i 向量匹配。 基于对 NIST SRE 2006 和 2014 数据集所做的评估,所提出的算法没有实现比 i-vector PLDA 基线方法更好的性能。 然而,将 DNN 方法与 PLDA(i-vector)方法相融合,显示出比单独使用 i-vector 更好的性能。
; Using Contrastive loss for vector comparison 利用对比损失进行向量比较
由于说话人识别被视为一个简单的分类任务,因此可以应用 softmax 层来创建 DNN 后端系统。然而,在说话人验证中,两个(说话人建模)向量的比较是必要的。在 DNN 中,可以通过这种方式实现的一种方法是使用对比损失(Chopra 等,2005)作为深度特征的损失函数。卷积网络(即 VGG(Simonyan 和 Zisserman,2014;Yadav 和 Rai,2018))(Nagrani 等,2017)和 ResNets(He 等,2015;Chung 等,2018)可以通过这种方式进行训练执行说话人验证任务。在 VoxCeleb 和 VoxCeleb2 数据集上,获得的 EER 低于标准 i-vector PLDA 系统:i-vector、CNN 和 ResNet 的 EER 分别为 8.8%、7.8% 和 3.95%。然而,在 (Chung et al., 2018) 中,ResNet 和基线系统没有在同一个数据集上训练(RestNet:VoxCeleb2,i-vector:VexCeleb1),因此这种增加可能来自更大音频材料的影响。
wei wan …
Original: https://blog.csdn.net/qq_40967961/article/details/120339014
Author: lc520xyp
Title: 说话人识别综述阅读1
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/515131/
转载文章受原作者版权保护。转载请注明原作者出处!