

如果你写过read或load音频文件的程序,你会发现,音频数组和采样率通常会同时出现。如果你不知道采样率是什么,可以看看这篇文章。
作为一名炼金术士,对参数的敏感性已成为一种条件反射。一个自然浮现在脑海中的问题是:采样率是否会影响模型的识别结果?答:是的。
[En]
As an alchemist, sensitivity to parameters has become a conditioned reflex. A natural question that comes to mind is: will the sampling rate affect the recognition results of the model? A: yes.
除了采样率,音频的属性还有采样深度、通道数等,音频的格式也各种各样,比如wav、mp3、flac等,这些会影响模型的识别吗?答:都会,但影响程度不一样。
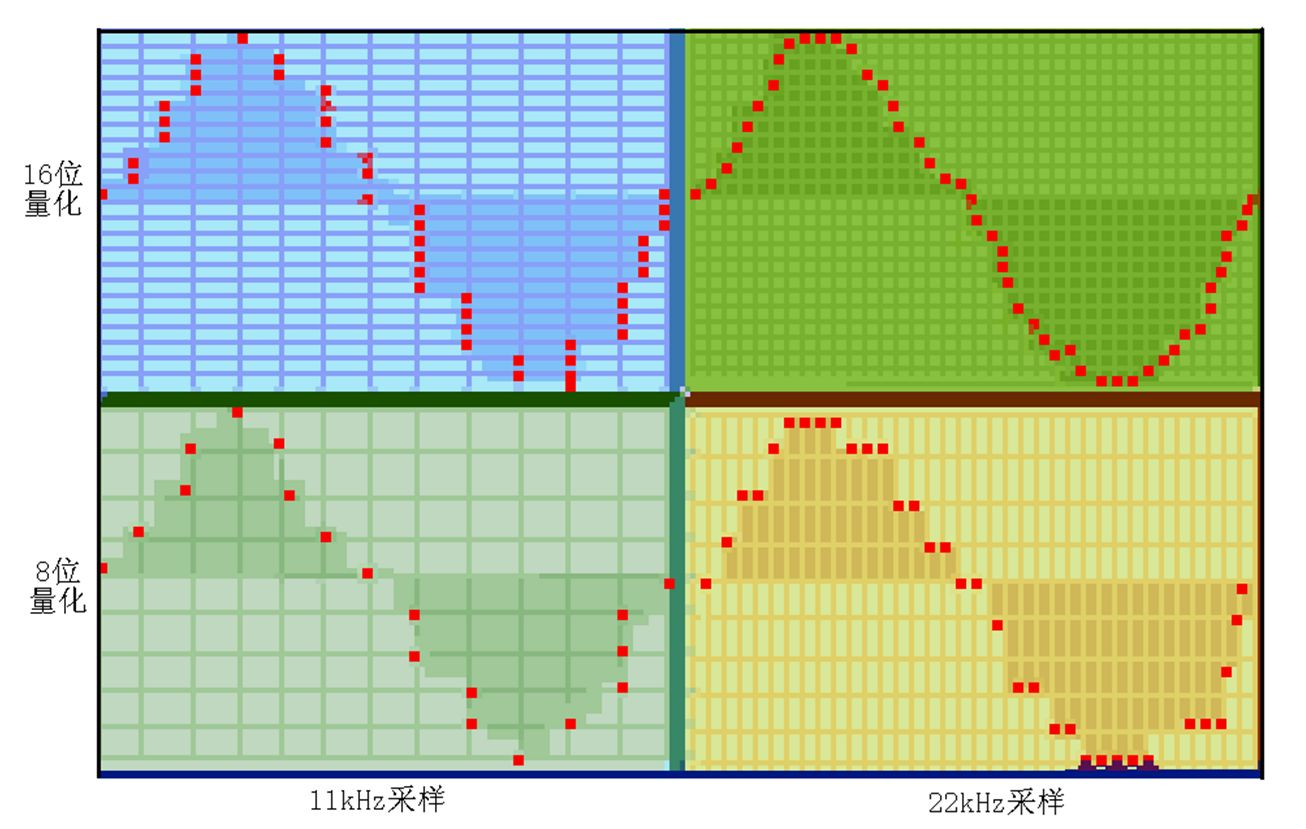

采样率
采样率,简单地说,就是每秒采样的数量。语音识别场景常见的采样率有8000、16000、32000等。以采样率16000为例,一秒钟的语音(假设单通道)就是一个长度为1.6w的数组。
如果给你一个长1.6w的数组,不告诉你采样率,你没法确定这段语音的时长是多少。那这跟模型有什么关系呢?或者说,采样率怎么影响语音识别模型呢?
如果用采样率1.6w的语音训练一个模型,而测试集语音的采样率是8k,那测试集的语音每两秒被模型当做一秒,相当于语速加快了一倍,这会导致什么样的后果呢?
想象一下,你正在房间里背诵古文,你的母亲走进来,问你正在读什么,你说的是文言文。你妈妈一言不发就是一记耳光,你敢叫我滚出去吗?你很委屈,你明明说了两个字,但因为速度太快,她以为你只说了一个字。
[En]
Imagine you are reciting ancient prose in your room, your mother comes in and asks you what you are reading, and you say classical Chinese. Your mother is a slap in the face without saying a word, dare you tell me to get out of here? You are very aggrieved, you clearly said two words, but because the speed is too fast, she thought you only said one word.
因此,训练集和测试集的采样率必须统一。
[En]
Therefore, the sampling rate of the training set and the test set must be unified.
统一多少比较好?没有固定的标准,语音识别一般使用16000。如果追求精度,请使用高采样率;如果追求效率,请使用低采样率。
[En]
How much is better to unify? There is no fixed standard, speech recognition generally uses 16000. If you pursue precision, use a high sampling rate; if you pursue efficiency, use a low sampling rate.
采样深度
在图像识别任务中,图像输入模型之前,要进行归一化处理,最简单的方式就是image/255,因为像素取值范围是0~255。
在语音识别任务中,也需要对语音进行归一化处理。与图像识别的不同之处在于,语音样本的范围不是固定的,这取决于采样深度。
[En]
In the speech recognition task, it is also necessary to normalize the speech. The difference from image recognition is that the range of speech samples is not fixed, which depends on the sampling depth.
如果采样深度是16位,那么语音样本的取值范围是[ − 2 15 , 2 15 − 1 ] [-2^{15}, 2^{15}-1][−2 1 5 ,2 1 5 −1 ],简单的归一化就是a u d i o / 2 15 audio/2^{15}a u d i o /2 1 5;相应的,32位的采样深度对应的取值范围是[ − 2 31 , 2 31 − 1 ] [-2^{31}, 2^{31}-1][−2 3 1 ,2 3 1 −1 ],归一化便是a u d i o / 2 31 audio/2^{31}a u d i o /2 3 1。
因此,采样深度影响语音数据的归一化。
[En]
Therefore, sampling depth affects the normalization of speech data.
不过,很多时候read或load出来的语音数据本身就是[-1,1]之间的浮点数,这是因为已经做了归一化处理。
通道数
语音识别一般采用单声道语音,如果您的音频是多声道,则应转换为单声道。
[En]
Speech recognition generally uses single-channel voice, if your audio is multi-channel, it should be converted to single-channel.
如何从多渠道转变为单渠道?理想情况下,您想要识别的语音在某个通道中,并且您知道它是哪个通道,因此只需调出该通道的数据,这样您就可以避免其他与通道无关的信息对识别的干扰。
[En]
How to change from multi-channel to single-channel? Ideally, the voice you want to recognize is in a channel, and you know which channel it is, so just bring up the data from that channel, so that you can avoid the interference of other channel-independent information to the recognition.
理想的情况通常并不存在,但实际情况是所有通道都有声音出现,或者你不知道哪个通道会发出声音,但处理方法也是简单粗略的,即对每个通道的值进行平均得到一个通道。
[En]
The ideal situation usually does not exist, but the actual situation is that voice appears in all channels, or you do not know which channel will produce voice, but the processing method is also simple and rough, that is, averaging the values of each channel to get a channel.
音频格式
音频的格式有很多种,mp3、wav、flac、ogg等。我们知道,不同格式的音频的编码是不一样的。这对语音识别有没有影响呢?比如,用mp3音频训练的模型,再用wav的音频测试,会不会因为格式不同导致准确率低或者模型完全听不懂呢?答:几乎不会。
我们知道,同一张图的jpg和png两种格式,虽然编码方式不一样,但是解码后展示出来的图是差不多的,一般肉眼看不出什么差别。用png图片训练模型,用jpg图像测试模型,完全没问题。
音频也是一样,用wav音频训练模型,用MP3音频测试模型,也是没有问题。
最后
推荐一个可以修改音频采样率、采样深度、通道数的python脚本:
https://github.com/wapping/SpeechUtils/blob/master/audio/reset.py
支持多种音频格式,支持单次或批量音频转换。
[En]
Support multiple formats of audio, support single or batch audio conversion.
脚本依赖pydub库,而pydub依赖ffmpeg,所以要安装pydub和ffmpeg。
Original: https://blog.csdn.net/lhp171302512/article/details/122722942
Author: warpin
Title: 音频格式对ASR模型的影响
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/515125/
转载文章受原作者版权保护。转载请注明原作者出处!