

最近用python做了VQLBG的说话人识别实验,记录一下。若是有错恳请指出。
矢量量化的基本原理
将几个标量数据形成一个向量(或从一帧语音数据中提取的特征向量),并在多维空间中作为一个整体进行量化,从而可以在较少信息损失的情况下压缩数据量。矢量量化有效地利用了矢量中元素之间的相关性,因此比标量量化具有更好的压缩效果。
[En]
Several scalar data are formed into a vector (or the feature vector extracted from a frame of speech data) and quantized as a whole in multi-dimensional space, so that the amount of data can be compressed with less information loss. Vector quantization effectively applies the correlation between the elements in the vector, so it can have a better compression effect than scalar quantization.
设有N N N个K K K维特征矢量X = { X 1 , X 2 , ⋯ , X N } X={X_1,X_2,\cdots,X_N}X ={X 1 ,X 2 ,⋯,X N }(X X X在K K K维欧几里德空间R K R^K R K中),其中第i i i个矢量可记为:
X i = { x 1 , x 2 , ⋯ , x K } , i = 1 , 2 , ⋯ , N X_i={x_1,x_2,\cdots,x_K},i=1,2,\cdots,N X i ={x 1 ,x 2 ,⋯,x K },i =1 ,2 ,⋯,N
X i X_i X i 可被看作是语音信号中某帧参数组成的矢量。将K K K维欧几里得空间R K R^K R K无遗漏地划分成J J J个互不相交的子空间R 1 , R 2 , ⋯ , R J R_1,R_2,\cdots,R_J R 1 ,R 2 ,⋯,R J ,即满足
{ ⋃ j = 1 J R j = R K R i ⋂ R j = ∅ , i ≠ j \begin{cases} \bigcup^J_{j=1} R_j=R^K \ R_i\bigcap R_j=\emptyset,i\neq j \end{cases}{⋃j =1 J R j =R K R i ⋂R j =∅,i =j
这些子空间R j R_j R j 称为胞腔。在每一个子空间R j R_j R j 找一个代表矢量Y j Y_j Y j ,则J J J个代表矢量可以组成矢量集为:
Y = { Y 1 , Y 2 , ⋯ , Y J } Y={Y_1,Y_2,\cdots,Y_J}Y ={Y 1 ,Y 2 ,⋯,Y J }
这样,Y Y Y就组成了一个矢量量化器,被称为码书或码本;Y j Y_j Y j 成为码失或码字;Y Y Y内矢量的个数J J J,则叫做码本长度或码本尺寸。不同的划分或不同的代表矢量选取方法就可以构成不同的矢量量化器。
当矢量量化器输入一个任意矢量X i ∈ R K X_i\in R^K X i ∈R K进行矢量量化时,矢量量化器首先判断它属于哪个子空间R j R_j R j ,然后输出该子空间R j R_j R j 的代表矢量Y j Y_j Y j 。也就是说,矢量量化过程就用Y j Y_j Y j 代表X i X_i X i 的过程,或者说把X i X_i X i 量化成Y j Y_j Y j ,即
Y j = Q ( X i ) , 1 ≤ j ≤ J , i ≤ i ≤ N Y_j=Q(X_i), 1\leq j\leq J,i\leq i\leq N Y j =Q (X i ),1 ≤j ≤J ,i ≤i ≤N
式中,Q ( X i ) Q(X_i)Q (X i )为量化器函数。由此可知,矢量量化的全过程就是完成一个从K K K维欧几里得空间R K R^K R K中的矢量X i X_i X i 到K K K维空间R K R_K R K 有限子集Y Y Y的映射:
Q : R K ⊃ X → Y = { Y 1 , Y 2 , ⋯ , Y J } Q:R^K\supset X\rightarrow Y={Y_1,Y_2,\cdots,Y_J}Q :R K ⊃X →Y ={Y 1 ,Y 2 ,⋯,Y J }
下面以K = 2 K=2 K =2为例来说明矢量量化过程。当K = 2 K=2 K =2时,所得到的是二维矢量。
即我们有N个二维的特征矢量X X X,第i i i个二维矢量为X i = { x i 1 , x i 2 } X_i={x_{i1},x_{i2}}X i ={x i 1 ,x i 2 },则所有可能的X i = { x i 1 , x i 2 } X_i={x_{i1},x_{i2}}X i ={x i 1 ,x i 2 }就是一个二维空间。
矢量量化就是先把这个平面划分成J J J块互不相交的子区域R 1 , R 2 , ⋯ , R J R_1,R_2,\cdots,R_J R 1 ,R 2 ,⋯,R J ,然后从每一块中找出一个代表矢量Y j ( j = 1 , 2 , ⋯ , J ) Y_j(j=1,2,\cdots,J)Y j (j =1 ,2 ,⋯,J ),这就构成了一个有J J J块区域的二维矢量量化器,下图就是一个码本尺寸为J = 7 J=7 J =7的二维矢量量化器,共有7块区域和7个码字表示代表值,码本是Y = { Y 1 , Y 2 , ⋯ , Y 7 } Y={Y_1,Y_2,\cdots,Y_7}Y ={Y 1 ,Y 2 ,⋯,Y 7 }。
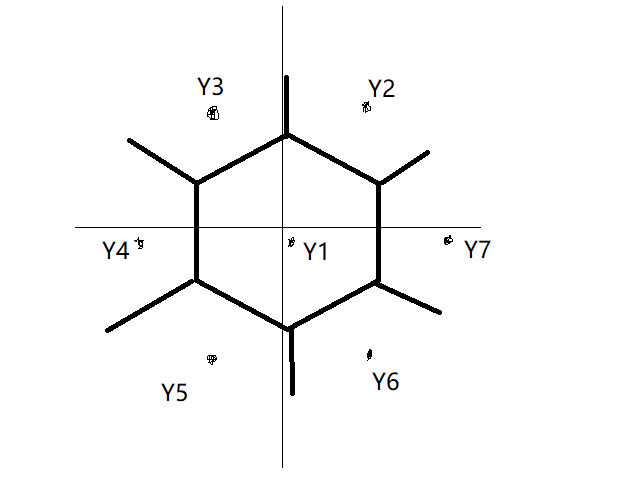

如果利用该量化器对一个矢量X i = { x i 1 , x i 2 } X_i={x_{i1},x_{i2}}X i ={x i 1 ,x i 2 }进行量化,那么首先要选择一个合适的失真测度,然后根据最小失真原理,分别计算用各码矢Y j Y_j Y j 代替X i X_i X i 所带来的失真。其中,产生最小失真值时所对应的那个码矢,就是矢量X i X_i X i 的重构矢量(或称恢复矢量),或者成为矢量X i X_i X i 被量化成了那个码矢。
说话人识别系统通常包括两个过程:训练和识别。而关键在于培训。
[En]
Speaker recognition system usually includes two processes: training and recognition. And the key lies in training.
; 训练步骤
步骤:
- 从训练语音提取特征矢量,得到特征矢量集。
- 选择合适的失真测度,并通过码本优化算法生成码本。
- 重复训练修正优化码本。
- 存储码本。
如果用d ( X , Y ) d(X,Y)d (X ,Y )表示训练用特征矢量X X X与训练出的码本的码字Y Y Y之间的畸变,那么最佳码本设计就是再一定的条件下,使得畸变的统计平均值D = E [ d ( X , Y ) ] D=E[d(X,Y)]D =E [d (X ,Y )]达到最小。这里,E [ ⋅ ] E[·]E [⋅]表示对X X X的全体所构成的集合以及码本的所有码字Y Y Y进行统计平均。为了实现这一目的,应该遵循以下两条原则:
- 根据X X X选择相应的码字Y l Y_l Y l 时应遵从最近邻准则,可表示为:
d ( X , Y l ) = min j d ( X , Y j ) d(X,Y_l)=\underset{j}{\text{min}}d(X,Y_j)d (X ,Y l )=j min d (X ,Y j ) - 设所有选择码字Y l Y_l Y l (即归属于Y l Y_l Y l 所表示的区域)的输入矢量X X X的集合为S l S_l S l ,那么Y l Y_l Y l 应使此集合中的所有矢量与Y l Y_l Y l 之间的畸变值最小。如果X X X与Y Y Y之间的畸变值等于他们的欧式距离,那么容易证明Y l Y_l Y l 应等于S l S_l S l 中所有矢量的质心,即Y l Y_l Y l 应由下式表示:
Y l = 1 N ∑ X ∈ S l X , ∀ l Y_l=\frac{1}{N}\sum_{X\in S_l}X,\forall l Y l =N 1 X ∈S l ∑X ,∀l
这里N N N代表S l S_l S l 中所包含的矢量的个数。
根据这两条原则,可以得到一种码本设计的递推算法——LBG算法。整个算法实际上就是上述两个条件的反复迭代过程,即从初始码本中寻找最佳码本的迭代过程。它由对初始码本进行迭代优化开始,一直到系统性能满足要求或不再有明显的改进为止。
LBG步骤
具体实现步骤如下:
- 设定码本和迭代训练参数:设全部输入训练矢量X X X的集合为S S S;设置码本的尺寸为J J J;设置迭代算法的最大迭代次数为L L L;设置畸变改进阈值为δ \delta δ。
- 设定初始化值:设置J J J个码字的初值Y 1 ( 0 ) , Y 2 ( 0 ) , ⋯ , Y J ( 0 ) Y_1^{(0)},Y_2^{(0)},\cdots,Y_J^{(0)}Y 1 (0 ),Y 2 (0 ),⋯,Y J (0 );设置畸变初值D ( 0 ) = ∞ D^{(0)}=\infty D (0 )=∞;设置迭代次数初值m = 1 m=1 m =1。
- 假定根据最近邻准则将S S S分成了J J J个子集S 1 ( m ) , S 2 ( m ) , ⋯ , S J ( m ) S_1^{(m)},S_2^{(m)},\cdots,S_J^{(m)}S 1 (m ),S 2 (m ),⋯,S J (m ),即当X ∈ S l ( m ) X\in S_l^{(m)}X ∈S l (m )时,下式应成立:
d ( X , Y l ( m − 1 ) ) ≤ d ( X , Y i ( m − 1 ) ) , ∀ i , i ≠ l d(X,Y_l^{(m-1)})\leq d(X,Y_i^{(m-1)}),\forall i,i\neq l d (X ,Y l (m −1 ))≤d (X ,Y i (m −1 )),∀i ,i =l - 计算总畸变D ( m ) D^{(m)}D (m ):
D ( m ) = ∑ l = 1 J ∑ x ∈ S l ( m ) d ( X , Y l ( m − 1 ) ) D^{(m)}=\sum^J_{l=1}\sum_{x\in S_l^{(m)}}d(X,Y_l^{(m-1)})D (m )=l =1 ∑J x ∈S l (m )∑d (X ,Y l (m −1 )) - 计算畸变改进量Δ D ( m ) \Delta D^{(m)}ΔD (m )的相对值δ ( m ) \delta^{(m)}δ(m ):
δ ( m ) = Δ D ( m ) D ( m ) = ∣ D ( m − 1 ) − D ( m ) ∣ D ( m ) \delta^{(m)}=\frac{\Delta D^{(m)}}{D^{(m)}}=\frac{|D^{(m-1)}-D^{(m)}|}{D^{(m)}}δ(m )=D (m )ΔD (m )=D (m )∣D (m −1 )−D (m )∣ - 计算新码本的码字Y 1 ( m ) , Y 2 ( m ) , ⋯ , Y J ( m ) Y_1^{(m)},Y_2^{(m)},\cdots,Y_J^{(m)}Y 1 (m ),Y 2 (m ),⋯,Y J (m )
Y l ( m ) = 1 N l ∑ X ∈ S l i ( m ) X Y_l^{(m)}=\frac{1}{N_l}\sum_{X\in S^{(m)}_{li}}X Y l (m )=N l 1 X ∈S l i (m )∑X - 判断δ ( m ) \delta^{(m)}δ(m )是否小于δ \delta δ。若是,转入(9)执行;否则转入(2)执行。
- 判断m m m是否小于L L L。若否,转入(9)执行;否则,令m = m + 1 m=m+1 m =m +1,转入(3)执行。
- 迭代终止;输出Y 1 ( m ) , Y 2 ( m ) , ⋯ , Y J ( m ) Y_1^{(m)},Y_2^{(m)},\cdots,Y_J^{(m)}Y 1 (m ),Y 2 (m ),⋯,Y J (m )作为训练成的码本的码字,并且输出总畸变D ( m ) D^{(m)}D (m )。
识别步骤
识别步骤如下:
- 录制音频,提取音频特征
- 与所有码本进行距离计算,产生最小的距离的码本即是最相像的人。
gitee
https://gitee.com/squid_feng/VQLBG.git
只要运行VQSystem.py文件即可体验。
Original: https://blog.csdn.net/weixin_43142450/article/details/122116942
Author: Squid _
Title: 基于矢量量化(VQ)的说话人识别(python)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/515033/
转载文章受原作者版权保护。转载请注明原作者出处!