

参考博客1:DDcGAN:用于多分辨率图像融合的双判别器生成对抗网络
DDcGAN文章内容



G: 如图所示,输入可见图像v 和红外图像 i,经过生成器G得到融合图像f.
生成器由2个反卷积层(提高i的分辨率,并使i,v分辨率一样,进行通道相连作为编码器的输入),一个编码器网络(特征提取和融合,生成融合的featuremap)和一个对应的解码器网络(featuremap重构,融合图像f具有与可见图像相同的分辨率)组成,如下图所示。
D: 使用2个鉴别器,是为了分别
以v作为条件,去判断f;
以i作为条件,去判断f;
在训练时,要考虑D和G的对抗,以及,Dv和Di的平衡.
Dv和Di有同样的结构,卷积层的stride为2,最后一层使用Tanh函数生成标量,代表是源图像(real)而不是生成图像(fake)的概率.
; 对抗目标和损失函数
作者不将源图像v和i作为条件信息(condition) 提供给Dv 和 Di, 即判别器的输入时 单通道,而不是一次能输入 样本数据+作为条件信息的双通道。
因为当条件与待识别样本相同时,判别任务被简化为判断输入图像是否相同,这对于神经网络来说太简单了。当生成器不能欺骗鉴别器时,对抗性关系就不能建立,生成器将倾向于随机生成。因此,该模型将失去其原来的意义。对抗的目标如下:
[En]
Because when the condition is the same as the sample to be identified, the discrimination task is simplified to determine whether the input image is the same, which is too simple for the neural network. When the generator cannot deceive the discriminator, the adversarial relationship cannot be established, and the generator will tend to generate randomly. Therefore, the model will lose its original meaning. The targets of confrontation are as follows:
min G max D v , D i { E [ log D v ( v ) ] + E [ log ( 1 − D v ( G ( v , i ) ) ) ] + E [ log D i ( i ) ] + E [ log ( 1 − D i ( ψ G ( v , i ) ) ) ] } \begin{gathered} \min {G} \max {D_{v}, D_{i}}\left{\mathbb{E}\left[\log D_{v}(v)\right]+\mathbb{E}\left[\log \left(1-D_{v}(G(v, i))\right)\right]\right. \left.+\mathbb{E}\left[\log D_{i}(i)\right]+\mathbb{E}\left[\log \left(1-D_{i}(\psi G(v, i))\right)\right]\right} \end{gathered}G min D v ,D i max {E [lo g D v (v )]+E [lo g (1 −D v (G (v ,i )))]+E [lo g D i (i )]+E [lo g (1 −D i (ψG (v ,i )))]}
ψ表示下采样操作,对应上方结构图。G 的训练目标可以表述为最小化,D的训练目标是使其最大化。注意:
上面没有条件, 不是
E[logDv(v|y)]
损失函数
L G = L G a d v + λ L c o n \begin{gathered} \mathcal{L}{G}=\mathcal{L}{G}^{a d v}+\lambda \mathcal{L}{c o n} \end{gathered}L G =L G a d v +λL c o n
L G a d v = E [ log ( 1 − D v ( G ( v , i ) ) ) ] + E [ log ( 1 − D i ( ψ G ( v , i ) ) ) ] \mathcal{L}{G}^{a d v}=\mathbb{E}\left[\log \left(1-D_{v}(G(v, i))\right)\right]+\mathbb{E}\left[\log \left(1-D_{i}(\psi G(v, i))\right)\right]L G a d v =E [lo g (1 −D v (G (v ,i )))]+E [lo g (1 −D i (ψG (v ,i )))]
L con = E [ ∥ ψ G ( v , i ) − i ∥ F 2 + η ∥ G ( v , i ) − v ∥ T V ] \mathcal{L}{\text {con }}=\mathbb{E}\left[\|\psi G(v, i)-i\|{F}^{2}+\eta\|G(v, i)-v\|_{T V}\right]L con =E [∥ψG (v ,i )−i ∥F 2 +η∥G (v ,i )−v ∥T V ]
上面是针对生成器的损失,下面是判别器Dv 与 Di 的损失:
L D v = E [ − log D v ( v ) ] + E [ − log ( 1 − D v ( G ( v , i ) ) ] L D i = E [ − log D i ( i ) ] + E [ − log ( 1 − D i ( ψ G ( v , i ) ) ] \begin{gathered} \mathcal{L}{D{v}}=\mathbb{E}\left[-\log D_{v}(v)\right]+\mathbb{E}\left[-\log \left(1-D_{v}(G(v, i))\right]\right. \ \mathcal{L}{D{i}}=\mathbb{E}\left[-\log D_{i}(i)\right]+\mathbb{E}\left[-\log \left(1-D_{i}(\psi G(v, i))\right]\right. \end{gathered}L D v =E [−lo g D v (v )]+E [−lo g (1 −D v (G (v ,i ))]L D i =E [−lo g D i (i )]+E [−lo g (1 −D i (ψG (v ,i ))]
conditional GAN:从纯生成到条件生成
参考文章2:【GAN专题】GAN系列一:条件生成
参考文章3:GAN的几个变种
CGAN概览
应用场景:
基于GAN的可控样本的生成
如:
根据一段文字描述,生成相应的图片。
图像翻译或图像与转换
如:
风格迁移:经典的工作包括马与斑马互换(CycleGAN)
StarGAN人脸属性编辑(换妆、换头发颜色、添加/去除眼镜、加胡子、变爷们或者女性化等)
用GAN换脸
从语义分割的图生成街景图、风景图(Pix2PixHD,GauGAN)
训练时:
通常我们会使用一个网络来对输入 z做预测,回归出一个条件 y 2 y_2 y 2 ,再与条件 y做某种误差计算,从而优化G的生成。
生成器G:
输入: 潜在分布z,如 图片,和条件y,如 文字描述
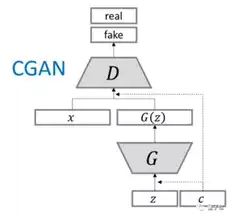
在实际输入时,z可能从高斯分布中采样得到; y可以为一个one-hot向量(某个位为1,表示要复合某种条件,可以是类别,也可以是特征),或者一个数值。
; 判别器D:
D ( x ∣ y ) D(x|y)D (x ∣y ),其中x x x是生成样本,或者原始数据。
对
真实样本与标签的配对需要接近于1,
对于生成样本与标签需要接近于0,
对于真实样本与不相符的标签,D的输出应该接近于0。
原始CGAN论文中

图片x x x以及条件y y y ,如果
标签与真实图片的标签相同,输出的数越接近于1越好,否则越接近于0,
第二项,包含了D ( G ( z ∣ y ) ∣ y ) D(G(z|y)|y)D (G (z ∣y )∣y ) ,用生成样本和标签y来优化D和G(在训练D时优化D,训练G时优化G)。
还可以使用两个判别器,分别判断图片是 真实/生成的,以及 输出条件,通过设置条件损失函数来对G生成的图片进行条件约束。
损失函数
D的损失函数:
V ~ = 1 m ∑ i = 1 m log D ( c i , x i ) + 1 m ∑ i = 1 m log ( 1 − D ( c i , x ~ i ) ) + 1 m ∑ i = 1 m log ( 1 − D ( c i , x ^ i ) \tilde{V}=\frac{1}{m} \sum_{i=1}^{m} \log D\left(c^{i}, x^{i}\right)+\frac{1}{m} \sum_{i=1}^{m} \log \left(1-D\left(c^{i}, \tilde{x}^{i}\right)\right)+\frac{1}{m} \sum_{i=1}^{m} \log \left(1-D\left(c^{i}, \hat{x}^{i}\right)\right.V ~=m 1 i =1 ∑m lo g D (c i ,x i )+m 1 i =1 ∑m lo g (1 −D (c i ,x ~i ))+m 1 i =1 ∑m lo g (1 −D (c i ,x ^i )
其中,
第一项( c , x ) (c,x)(c ,x )是正确条件与真实图片的 pair,应该给高分;
第二项是正确条件c c c与仿造图片G ( c , z ) G(c,z)G (c ,z )的pair,应该给低分(于是加上了”1-“);
第三项是错误条件c c c与真实图片的 pair,也应该给低分。
可以明显的看出,CGAN 与 GANs 在判别器上的不同之处就是多出了第三项
G的损失函数:
V ~ = 1 m ∑ i = 1 m log ( D ( G ( c i , z i ) ) ) \tilde{V}=\frac{1}{m} \sum_{i=1}^{m} \log \left(D\left(G\left(c^{i}, z^{i}\right)\right)\right)V ~=m 1 i =1 ∑m lo g (D (G (c i ,z i )))
G想要骗过D,因此,这个得分越大越好。
算法实现


; 输入

- 为了把图片和条件结合在一起,往往会把
x丢入一个网络产生一个 embedding,condition也丢入一个网络产生一个 embedding,然后把这两个 embedding 拼在一起丢入一个网络中,这个网络既要判断第一个 embedding 是否真实,同时也要判断两个 embedding 是否逻辑上匹配,最终给出一个分数。 - 另外一种情况,可以将
图片x送入一个网络,得到real/fake分数,再将网络中间输出与条件一起送到另一个网络,判断条件c与图片是否符合一致,从而得到另一个Conditional fulfillment分数。
在有些任务上,对condition的描述非常细致,不是通过010101这类编码来标记的标签,比如连续标签,通常我们会使用一个网络来对输入 x做预测,回归出一个条件 y 2 y_2 y 2 ,再与条件 c做某种误差计算,从而优化G的生成。如做人脸属性编辑的StarGAN、STGAN就是使用了交叉熵损失,而非0/1的损失。GauGAN使用了语义图作为条件,也是用了这一类的损失函数。
代码理解
首先理解CGan

参考博文:
参考文章4:tf: 详解GAN代码之搭建并详解CGAN代码
参考文章5:Pytorch CGAN代码
下面是一些代码摘抄,为了展示算法的结构,仅有一些使用条件
y的核心代码:
; tf版的
生成器:
def generator(image, gf_dim=64, reuse=False, name="generator"):
input_dim = int(image.get_shape()[-1])
dropout_rate = 0.5
with tf.variable_scope(name):
if reuse:
tf.get_variable_scope().reuse_variables()
else:
assert tf.get_variable_scope().reuse is False
e1 = batch_norm(conv2d(input_=image, output_dim=gf_dim, kernel_size=4, stride=2, name='g_e1_conv'), name='g_bn_e1')
........
e8 = batch_norm(conv2d(input_=lrelu(e7), output_dim=gf_dim*8, kernel_size=4, stride=2, name='g_e8_conv'), name='g_bn_e8')
d1 = deconv2d(input_=tf.nn.relu(e8), output_dim=gf_dim*8, kernel_size=4, stride=2, name='g_d1')
.......
d8 = deconv2d(input_=tf.nn.relu(d7), output_dim=input_dim, kernel_size=4, stride=2, name='g_d8')
return tf.nn.tanh(d8)
判别器:
def discriminator(image, targets, df_dim=64, reuse=False, name="discriminator"):
with tf.variable_scope(name):
if reuse:
tf.get_variable_scope().reuse_variables()
else:
assert tf.get_variable_scope().reuse is False
dis_input = tf.concat([image, targets], 3)
h0 = lrelu(conv2d(input_ = dis_input, output_dim = df_dim, kernel_size = 4, stride = 2, name='d_h0_conv'))
.......
h3 = lrelu(batch_norm(conv2d(input_ = h2, output_dim = df_dim*8, kernel_size = 4, stride = 1, name='d_h3_conv'), name='d_bn3'))
output = conv2d(input_ = h3, output_dim = 1, kernel_size = 4, stride = 1, name='d_h4_conv')
dis_out = tf.sigmoid(output)
return dis_out
在生成器和判别器中, image参数就是指的条件 y,
在生成器的输入中,随机噪声被去除(只输入条件)
[En]
And in the input of the generator, the random noise is removed (only the condition is entered)
在判别器的输入中, 条件image 和 待判别的图像targets被拼接(concat)了起来。
调用如下:
gen_label = generator(image=train_picture, gf_dim=64, reuse=False, name='generator')
dis_real = discriminator(image=train_picture, targets=train_label, df_dim=64, reuse=False, name="discriminator")
dis_fake = discriminator(image=train_picture, targets=gen_label, df_dim=64, reuse=True, name="discriminator")
EPS = 1e-12
gen_loss_GAN = tf.reduce_mean(-tf.log(dis_fake + EPS))
gen_loss_L1 = tf.reduce_mean(l1_loss(gen_label, train_label))
gen_loss = gen_loss_GAN * args.lamda_gan_weight + gen_loss_L1 * args.lamda_l1_weight
dis_loss = tf.reduce_mean(-(tf.log(dis_real + EPS) + tf.log(1 - dis_fake + EPS)))
pytorch版的
生成器
ngpu = 1
device = torch.device("cuda:0" if (torch.cuda.is_available() and ngpu > 0) else "cpu")
class Generator(nn.Module):
def __init__(self, ngpu):
self.ngpu = ngpu
super(Generator,self).__init__()
self.gen=nn.Sequential(
....
)
def forward(self, x):
x=self.gen(x)
return x
netG = Generator(ngpu).to(device)
判别器:
class Discriminator(nn.Module):
def __init__(self, ngpu):
super(Discriminator, self).__init__()
self.ngpu = ngpu
self.main = nn.Sequential(
......
)
def forward(self, x):
return self.main(x)
netD = Discriminator(ngpu).to(device)
训练阶段
real_label = 1
fake_label = 0
criterion = nn.BCELoss()
netD.zero_grad()
real_cpu = data[0].to(device)
b_size = real_cpu.size(0)
label = torch.full((b_size,), real_label, device=device)
output = netD(real_cpu)
real_label_label = output[:, 0]
errD_real = criterion(real_label_label, label)
fake = netG(noise)
label.fill_(fake_label)
real_label_label = output[:, 0]
errD_fake = criterion(real_label_label, label)
output = netD(fake.detach())
real_label_pic = output[:, 1:]
errD_fake_pic = criterion_pic(real_label_pic, data[1].cuda(device))
errD = errD_real + errD_fake + errD_fake_pic
然后,是DDcGan
详细代码在参考博文1中有,再贴一遍:
GitHub-official-Tensorflow
GitHub-unofficial-PyTorch
生成器
class Encoder(object):
def __init__(self, scope_name):
self.scope = scope_name
...
def encode(self, image):
...
class Decoder(object):
def __init__(self, scope_name):
self.scope = scope_name
...
def decode(self, image):
...
class Generator(object):
def __init__(self, sco):
self.encoder = Encoder(sco)
self.decoder = Decoder(sco)
def transform(self, vis, ir):
img = tf.concat([vis, ir], 3)
code = self.encoder.encode(img)
self.target_features = code
generated_img = self.decoder.decode(self.target_features)
return generated_img
判别器:
class Discriminator1(object):
def __init__(self, scope_name):
self.scope = scope_name
...
def discrim(self, img, reuse):
...
class Discriminator2(object):
def __init__(self, scope_name):
self.scope = scope_name
...
def discrim(self, img, reuse):
...
训练时:
with tf.Graph().as_default(), tf.Session() as sess:
SOURCE_VIS = tf.placeholder(tf.float32, shape = (BATCH_SIZE, patch_size, patch_size, 1), name = 'SOURCE_VIS')
SOURCE_IR = tf.placeholder(tf.float32, shape = (BATCH_SIZE, patch_size, patch_size, 1), name = 'SOURCE_IR')
G = Generator('Generator')
generated_img = G.transform(vis = SOURCE_VIS, ir = SOURCE_IR)
D1 = Discriminator1('Discriminator1')
grad_of_vis = grad(SOURCE_VIS)
D1_real = D1.discrim(SOURCE_VIS, reuse = False)
D1_fake = D1.discrim(generated_img, reuse = True)
D2 = Discriminator2('Discriminator2')
D2_real = D2.discrim(SOURCE_IR, reuse = False)
D2_fake = D2.discrim(generated_img, reuse = True)
G_loss_GAN_D1 = -tf.reduce_mean(tf.log(D1_fake + eps))
G_loss_GAN_D2 = -tf.reduce_mean(tf.log(D2_fake + eps))
G_loss_GAN = G_loss_GAN_D1 + G_loss_GAN_D2
LOSS_IR = Fro_LOSS(generated_img - SOURCE_IR)
LOSS_VIS = L1_LOSS(grad(generated_img) - grad_of_vis)
G_loss_norm = LOSS_IR /16 + 1.2 * LOSS_VIS
G_loss = G_loss_GAN + 0.6 * G_loss_norm
D1_loss_real = -tf.reduce_mean(tf.log(D1_real + eps))
D1_loss_fake = -tf.reduce_mean(tf.log(1. - D1_fake + eps))
D1_loss = D1_loss_fake + D1_loss_real
D2_loss_real = -tf.reduce_mean(tf.log(D2_real + eps))
D2_loss_fake = -tf.reduce_mean(tf.log(1. - D2_fake + eps))
D2_loss = D2_loss_fake + D2_loss_real
sess.run(tf.global_variables_initializer())
for epoch in range(EPOCHS):
np.random.shuffle(source_imgs)
for batch in range(n_batches):
step += 1
current_iter = step
VIS_batch = source_imgs[batch * BATCH_SIZE:(batch * BATCH_SIZE + BATCH_SIZE), :, :, 0]
IR_batch = source_imgs[batch * BATCH_SIZE:(batch * BATCH_SIZE + BATCH_SIZE), :, :, 1]
VIS_batch = np.expand_dims(VIS_batch, -1)
IR_batch = np.expand_dims(IR_batch, -1)
FEED_DICT = {SOURCE_VIS: VIS_batch, SOURCE_IR: IR_batch}
it_g = 0
it_d1 = 0
it_d2 = 0
if batch % 2==0:
sess.run([D1_solver, clip_D1], feed_dict = FEED_DICT)
it_d1 += 1
sess.run([D2_solver, clip_D2], feed_dict = FEED_DICT)
it_d2 += 1
else:
sess.run([G_solver, clip_G], feed_dict = FEED_DICT)
it_g += 1
g_loss, d1_loss, d2_loss = sess.run([G_loss, D1_loss, D2_loss], feed_dict = FEED_DICT)
if batch%2==0:
while d1_loss > 1.7 and it_d1 < 20:
sess.run([D1_solver, clip_D1], feed_dict = FEED_DICT)
d1_loss = sess.run(D1_loss, feed_dict = FEED_DICT)
it_d1 += 1
while d2_loss > 1.7 and it_d2 < 20:
sess.run([D2_solver, clip_D2], feed_dict = FEED_DICT)
d2_loss = sess.run(D2_loss, feed_dict = FEED_DICT)
it_d2 += 1
d1_loss = sess.run(D1_loss, feed_dict = FEED_DICT)
else:
while (d1_loss < 1.4 or d2_loss < 1.4) and it_g < 20:
sess.run([G_GAN_solver, clip_G], feed_dict = FEED_DICT)
g_loss, d1_loss, d2_loss = sess.run([G_loss, D1_loss, D2_loss], feed_dict = FEED_DICT)
it_g += 1
while (g_loss > 200) and it_g < 20:
sess.run([G_solver, clip_G], feed_dict = FEED_DICT)
g_loss = sess.run(G_loss, feed_dict = FEED_DICT)
it_g += 1
print("epoch: %d/%d, batch: %d\n" % (epoch + 1, EPOCHS, batch))
if batch % 10 == 0:
elapsed_time = datetime.now() - start_time
lr = sess.run(learning_rate)
print('G_loss: %s, D1_loss: %s, D2_loss: %s' % (
g_loss, d1_loss, d2_loss))
print("lr: %s, elapsed_time: %s\n" % (lr, elapsed_time))
result = sess.run(merged, feed_dict=FEED_DICT)
writer.add_summary(result, step)
if step % logging_period == 0:
saver.save(sess, save_path + str(step) + '/' + str(step) + '.ckpt')
is_last_step = (epoch == EPOCHS - 1) and (batch == n_batches - 1)
if is_last_step or step % logging_period == 0:
elapsed_time = datetime.now() - start_time
lr = sess.run(learning_rate)
print('epoch:%d/%d, step:%d, lr:%s, elapsed_time:%s' % (
epoch + 1, EPOCHS, step, lr, elapsed_time))
Original: https://blog.csdn.net/weixin_42433809/article/details/120463578
Author: 天蓝蓝的本我
Title: 第三篇: DDcGAN-用于多分辨率图像融合的双判别器生成对抗网络
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/514140/
转载文章受原作者版权保护。转载请注明原作者出处!