

Nonparallel Emotional Speech Conversion Using VAE-GAN
from INTERSPEECH 2020 – Ping An Technology
关键词:语音生成、语音情感、网络生成、自编码
[En]
Keywords: speech generation, voice emotion, generation against network, self-encoder
摘要
概括: 采用GAN模型生成情感语音
主要内容: 本文采用的是VAE-GAN框架,采用encoder提取内容相关表示,采用监督的方式提取情感相关信息,利用CycleGAN来进行语音情感域间的转换。最后将内容表示和情感表示结合生成目标情感语音。
简介
- 介绍了什么是VC(Voice Conversion)和ESC(Emotional Speech Conversion)
- 有很多ESC的方法,包括两种:基于 规则的方法和基于 神经网络的方法,但是需要精准对齐的平行语料库
为什么语音生成需要平行语料库,为什么要对齐? 这里有对平行语库的解释知乎-语音转换综述,意思是必须样例和结果说话的内容相同才可以 - VAE(Variational AutoEncoder)将模型的表征分离,过程分为编码和解码过程
- 对抗学习能够使得转换出的语音更加自然,CycleGAN不再使用平行语料
本文的创新点
- 将VAE-GAN结构和CycleGAN结合
- 提出了一个更加可靠提取情感相关特征的监督学习策略
相关工作
- VAE(Variational AutoEncoder)介绍:变分自编码器,具体介绍在:知乎-VAE 知乎-自编码器
- CycleGAN2:相关内容:CycleGAN-知乎李宏毅视频笔记
其中3个LOSS:Adversarial Loss(用于两阶段对抗生成,其中提到oversmoothing,一般发生在图卷积网络中)、Cycle-consistency Loss(用于提升生成语音的连续性)、Identity Mapping Loss(保留身份信息) - VAE-GAN:将VAE和GAN进行结合,AVE产生的是正常但是模糊的样本,GAN产生的是怪异但是清晰的样本,将两者结合能够取其优点、去其糟粕
- 本文中采用F0基音频率、aperiodicity与频谱特征作为转换模型所需的特征
方法
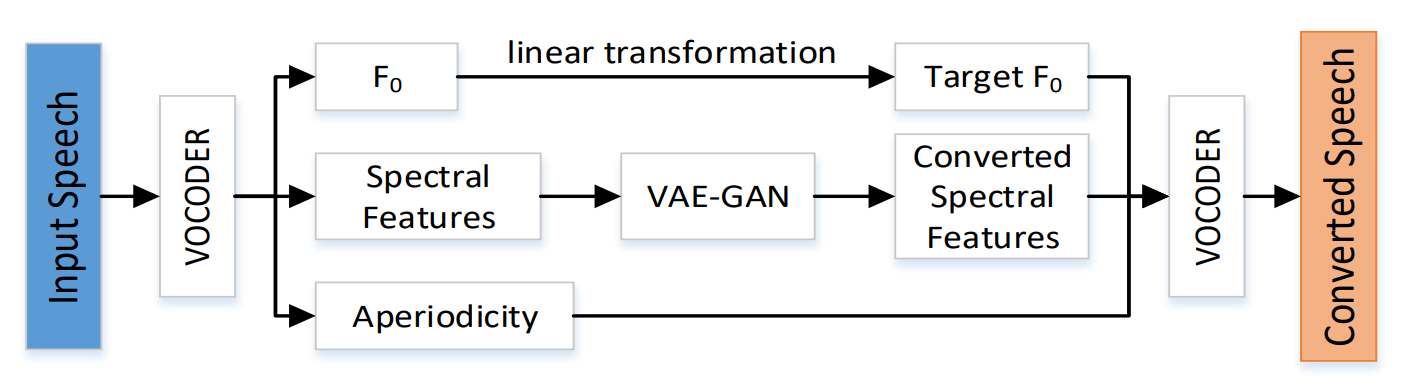

采用WORLD提取F0、Spectral Features和Aperiodicity特征,这三个特征采用不同模型进行转换,F0采用logarithm Gaussian Normalized Transformation:
f t r g = e x p ( ( l o g f s r c − μ s r c ) ∗ δ t r g δ s r c + μ t r g ) f_{trg}=exp((log{f_{src}-\mu_{src}})*\frac{\delta_{trg}}{\delta_{src}}+\mu_{trg})f t r g =e x p ((l o g f s r c −μs r c )∗δs r c δt r g +μt r g )
其中aperiodity并没有改变,因为其对语音情感转换影响不大。
对于频谱特征采用VAE-GAN进行转换,其核心思想是通过非监督方式提取内容特征,通过监督方法提取情感特征。本文在训练和转换的过程中使用了情感标签,如图中所示。转换模型有三部分:编码器、解码器和判别器。编码器将声谱特征转换为内容相关的表征,频谱特征片段的情感标签作为情感相关表征,这两种表征随后进入一个解码器,输出结果再输入到判别器分辨是否为假。解码器和判别器部分可以看作一种CycleGAN2的变形。
LOSS设计部分:

这个部分对于不了解CycleGAN的读者来说并不是很清楚,看不出训练的过程。

; 实验
数据库: INEMOCAP,4种情感:Happy、Angry、Sad、Neutral
训练集: 随机从每个语者的每种情感中随机抽取30个样本
cycle loss和identity loss的权重分别设为10和5,这里的权重是如何进行选择的?
网络结构: 其中IN(instance normalization)层,用来做归一化去除说话人的情感信息,只关注于内容相关特征的提取。
优化器: Adam
Batch-Size: 1
评估的三个方面是: 生成音质、 说话人相似度和 情感转换能力
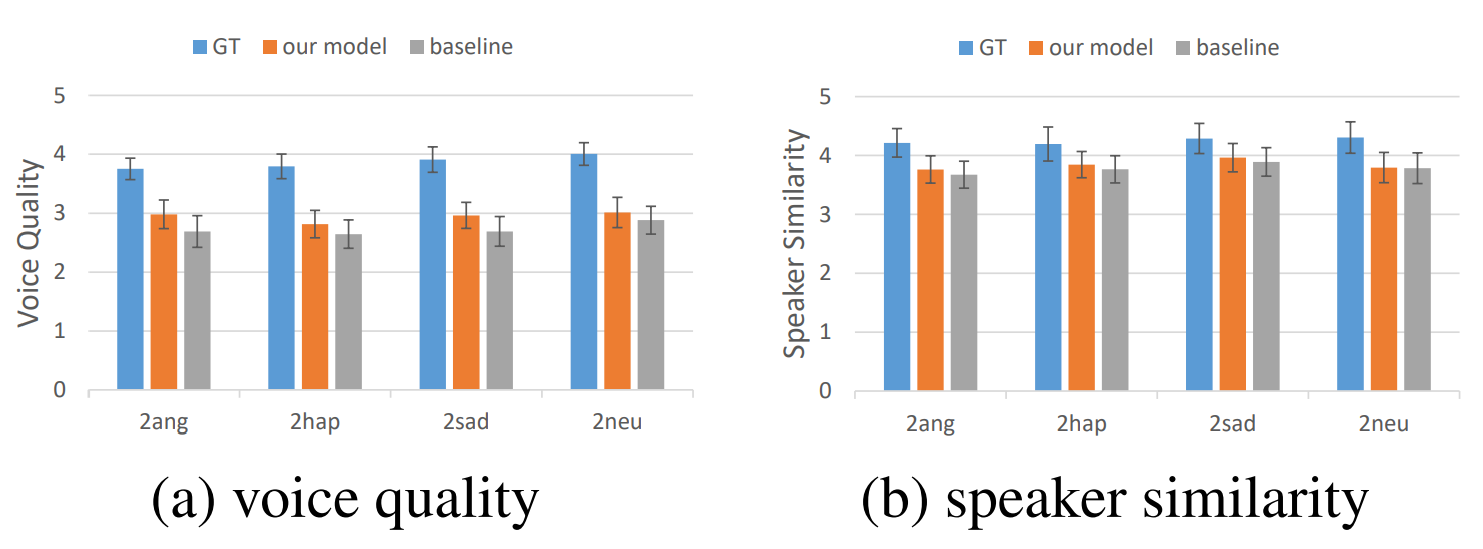
- 生成音质和说话人相似度: MOS方法,是一种主观人工评分的方法,每个情感转换为其他情感共4*3=12组实验,30个评判者,180条测试语音。结果显示在95%的置信区间之内,语音质量和说话人相似度都有较好效果,语音质量的提升可能归因于两步的adversarial loss,说话人相似度可能提升较少。
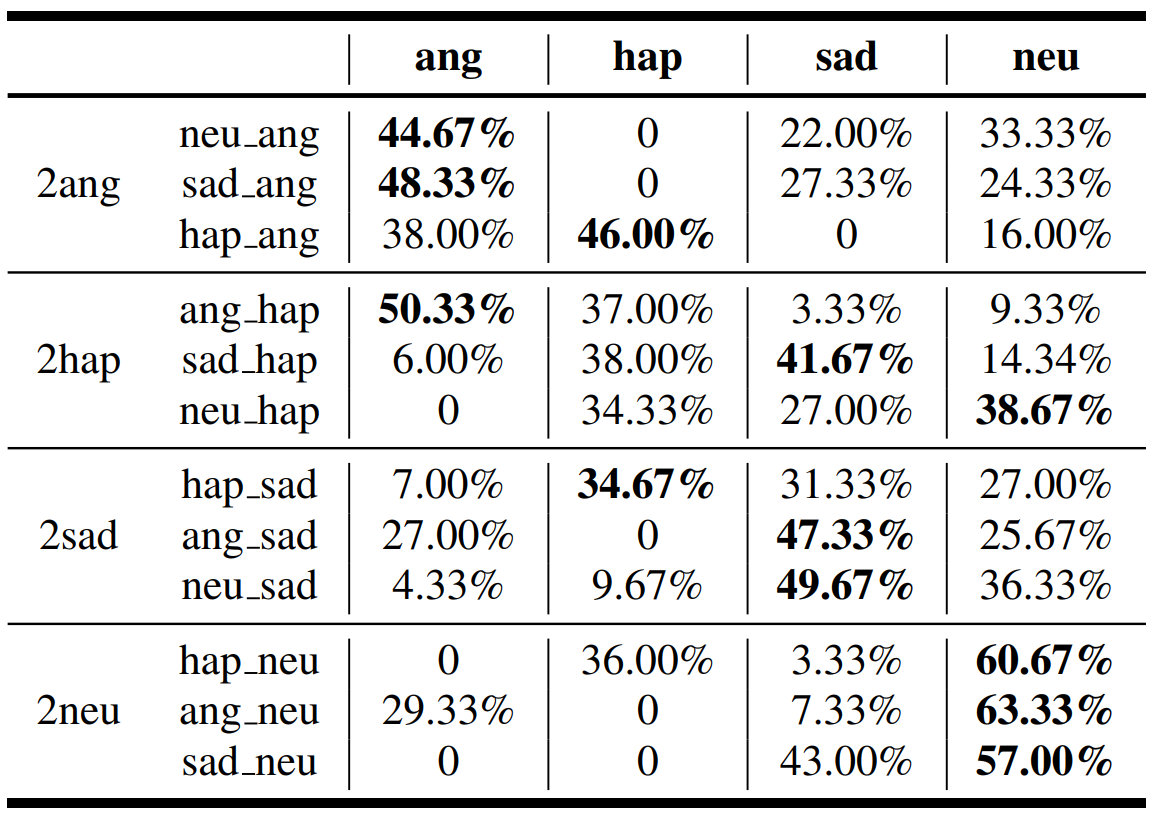
- 情感转换能力: 采用的依然是人工评分的方法,12种情感转换,每种随机抽取10句话作为测试集,结果表明监督学习的方式能够更多提取情感相关表征。
问题
- 文中仅仅提到利用了类似CycleGAN的原理和loss,但未在图中描述训练过程。
- 文中所说的情感相关特征提取是监督学习,意思是采用了情感标签结合模型进行训练,这算监督吗?其实是必须要输入的情感标签作为情感转换信息。
- 人工评分是否不可靠,可以进行修改?一般来说人工评分后会进行显著性测试,以保证结果的分布可靠?
- 情感转换那里用的数据那么少,还是人工标注,结果真的可靠吗?
Original: https://blog.csdn.net/cherreggy/article/details/121335611
Author: 你的宣妹
Title: 【论文笔记】Nonparallel Emotional Speech Conversion Using VAE-GAN 基于VAE-GAN的非平行情感语音生成
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/513136/
转载文章受原作者版权保护。转载请注明原作者出处!