

摘要:
从高资源语言到低资源语言的跨语言知识转移是自动语音识别(ASR)的一个重要研究问题。我们提出了一种新的转移学习策略,即利用大量高资源语言的语音进行预训练,但其文本被翻译成目标低资源语言。这种简单的脚本映射明确地鼓励增加两种语言输出空间的共享,即使高资源语言和低资源语言来自不相关的语言家族,也是令人惊讶的有效。我们提出的技术的效用在非常低资源的情况下更为明显,在这种情况下,好的初始化能够获得更大的改进。我们在Transformer-ASR架构和最先进的wav2vec2.0 ASR架构上评估了我们的技术,以英语作为高资源语言,以六种语言作为低资源目标。在获得1小时的目标语音后,与现有的迁移学习方法相比,我们获得了高达8.2%的相对误码率降低。
关键词:低资源ASR,音译,微调,迁移学习
- *一、介绍
近年来,端到端(E2E)系统已经成为ASR事实上的建模选择,与传统的级联式ASR系统相比,表现出卓越的性能。然而,E2E系统需要高度资源密集型的训练,需要大量的标记过的语音才能表现良好。这一要求使天平倾向于像英语这样的高资源语言,因为这些语言有大量的标记过的语音库可以公开使用。相反,对于世界上大多数语言来说,只有有限的转录语音可用。通过有效地利用高资源语言中的大量标记语音来提高这种低资源语言的E2E ASR系统的性能,对语音界来说是非常有意义的。
语音识别的迁移学习技术旨在将知识从高资源语言有效地转移到低资源语言,并已被广泛研究。E2E系统中流行的迁移学习模式是在一种(或多种)高资源语言的标记语音上预训练模型,然后在低资源语言的语音上微调全部或部分模型。通常情况下,高资源语言和低资源语言使用非常不同的字形词汇表。在前人的一些工作中,这种输出词汇的差异主要是由于在E2E ASR系统中只使用高资源语言来训练编码器层或同时训练编码器和解码器层来处理。在后一种情况下,输出的softmax层是在高资源的字母表上,在对低资源语言的语音进行微调之前,需要用对应于目标低资源语言的新的字母表来替换。在这些方法中,跨语言的共享是潜在的,而且当不同特定语言的字形不相交时,输出空间是不可控的。
在我们的工作中,我们提出了一种方法,通过将高资源语言的音译结果音译为低资源语言来提高输出语素空间的共享性。以英语为高资源语言,我们使用六种不同的低资源世界语言。在这些语言中,很容易获得一个现成的音译库,可以将任何英语文本转换为这些语言语素,因为音译是一种对大量少数族裔使用者来说很受欢迎的输入打字工具。
[En]
In our work, we propose a method to improve the sharing of output morpheme space by transliterating the transcriptional results of high-resource languages into low-resource languages. With English as the high-resource language, we use six different low-resource world languages. In these languages, a ready-made transliteration library that can convert any English text into these language morphemes is easy to obtain, because transliteration is a popular input typing tool for a large number of minority speakers.
我们使用音译作为第一步,将大型英语语音语料的转录转换为目标语言的文本,然后使用这些英语语音的音译转录对E2E模型进行预训练,紧接着使用有限的目标语言的语音对文本进行微调。这种看似简单的技术有助于模型学习目标语言的良好初始化,并被证明比一系列语言的标准迁移学习技术更有效。强迫英语转录文本采用与目标语言相同的文本,可以在编码器和解码器层之间更好地共享模型参数。即使是现成的、不完美的音译库,通过我们的方法也能够有一定的效果,因为这些音译的数据只在预训练中使用。相比之下,【9】中提出的将低资源语言音译成英语的反向方法则要差的多,因为它最终还是需要将有损失的音译译回到低资源语言,而不是英语。
- *二、相关工作
通过利用高资源语言的标记数据来改进低资源ASR,一直是一个活跃的研究领域,从传统的基于HMM的模型到现代神经系统。虽然最近的一些系统尝试使用具有共享电话层的声学模型或独立的音素层或两者的结合进行转移,但我们在这里的重点是更流行的端到端系统(E2E),在最后一层预测字词。使用高资源语言的标记数据对E2E系统进行迁移学习,已经在三种情况下进行了尝试:(1)对每种语言的字母词汇进行单独的softmax层联合训练,(2)对高资源的字母进行预训练,然后对目标低资源语言进行单独的字母softmax微调以及(3)训练一个共享的softmax层,将所有的字形词汇联合起来,通常在语言共享字形时应用。在所有这些方法中,跨语言的共享是潜在的,当特定语言的字母词汇表不相交时,在输出空间中不能明确控制。
我们试图通过将高资源的字母(英语)音译成低资源的字母来弥补这一缺陷。虽然音译已被广泛用于改善机器翻译、信息检索和跨语言应用,但很少有工作专注于改善语音识别性能。最近,[9]提出了从印度语言到英语的反向音译,并显示出比普通多语言模型的改进。在本文中,我们表明我们从英语的音译方向提供了更高的收益,而反向的方向往往比早期不尝试分享字形的迁移学习方法更差。基于音译的方法也与编码转换的ASR有关。与我们的工作同时,[13]也提出了通过在彼此之间音译低资源的字形来预训练多语言模型。然而,当输入高资源的音频时,他们通过初始的低资源ASR模型获得的字词作为预测。最初的低资源ASR模型是用它自己有限的数据训练出来的,很可能会做出高噪音的预测。用模型自身的噪声预测进行预训练可能会引入负反馈。相比之下,我们提出了一种错误率较低的方法,即通过预先存在的音译库来利用高资源语言的高质量转录文本。
最近另一个有前途的方向是通过对未标记的语音进行预训练来学习可转移的潜在语音表示特征[8]。我们对标记数据的音译文本甚至可以用来进一步微调这些预训练的模型,而且我们在最近的自我监督的 wav2vec2.0[14]的预训练模型上展现了明显的收益。
- *三、提出的方法
我们提出的方法的整体训练程序如图1所示。训练包括两个阶段:预训练,然后是微调。在预训练期间,我们将高资源语言的文本音译为目标低资源语言,并使用原始音频数据和这个音译文本训练ASR模型。接下来,我们在目标语言数据上对预训练的ASR模型进行微调,由于输出词汇发生了变化,我们会重新初始化输出层。
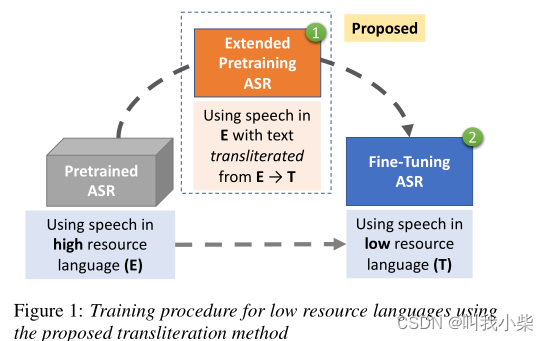

音译被用来将文本从一种文字或语言转换为另一种文字或语言,通常保留了不同语言的声音。通过在预训练阶段使用音译文本进行监督训练,我们希望能够隐含地学习到目标语言的更好的声音和文本的映射。我们打算使用现有的音译工具来支持目标语言的音译。有两种常见的音译方法;基于规则和机器翻译。基于规则的方法依赖于两种文字之间的字符映射,而机器翻译方法则从平行训练数据中学习。为了证明所提出的方法甚至可以在一个简单的音译系统中工作,从而能很容易扩展到其他几种低资源语言,我们使用了现有的简单的现成系统。对于四种印度语言,我们使用了indic-trans[15],对于韩语,我们使用了微软的Azure API1,对于阿姆哈拉语,我们通过google-transliterate-api2 pip包使用了Google Transliterate API。事实上,开发一个基于音素的定制音译系统并没有比使用现成的系统产生任何改进,所以我们坚持使用后者。图2显示了将英语文本音译为相应目标语言的例子。

- *四、实验
…………
- *五、结论
这项工作探索了音译在训练E2E ASR系统中令人惊讶的有效作用。我们提出了一种简单的基于音译的迁移学习技术,很容易适应其他低资源语言,并在两个最先进的ASR系统上展示了我们所提出的方法的效用,尽管使用的是不完善的音译系统,但在性能上比已有的迁移学习方法有了明显的改善。
Original: https://blog.csdn.net/weixin_45091943/article/details/126255860
Author: 叫我小柴
Title: Low Resource ASR: The surprising effectiveness of High Resource Transliteration–低资源ASR:高资源音译的惊人效果
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/513126/
转载文章受原作者版权保护。转载请注明原作者出处!