

一、Vector Set as Input
1、文字处理:

2、One-Hot Encoding(将词汇变成vector的一种编码方式)
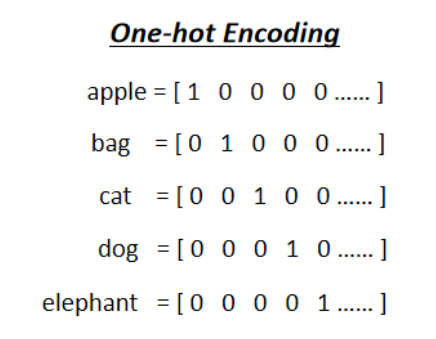
我们可以设计一个非常长的矢量,包含世界上所有的单词,每个维度对应一个单词。(如上所示)
[En]
We can design a very long vector that contains all the words in the world, and each dimension corresponds to a word. (as shown above)
但是这种编码也有一定的缺陷。它所有假设的词汇彼此之间都是相互独立的,在上面几个向量中,Cat跟Dog都是动物所以他们本应该比较相近,但是Cat跟Apple一个是动物一个是植物,他们应该相隔比较远,但是在one-hot encoding中我们无法描述出他们之间的关系。
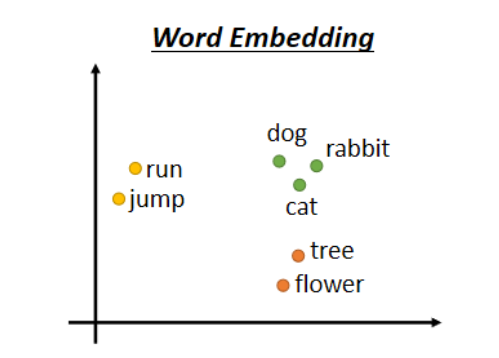
这种编码方式一样是给每一个词汇一个vector,但是这个vector中都是包括了语义资讯的,上图是将Word Embedding可视化之后的样子,所有的植物可能都聚成一团,所有的动词聚成一团等。我们需要明白 Word Embedding就是给每一个词汇一个vector,而每一个句子就是一排长度不一的vector。
3、声音信号处理
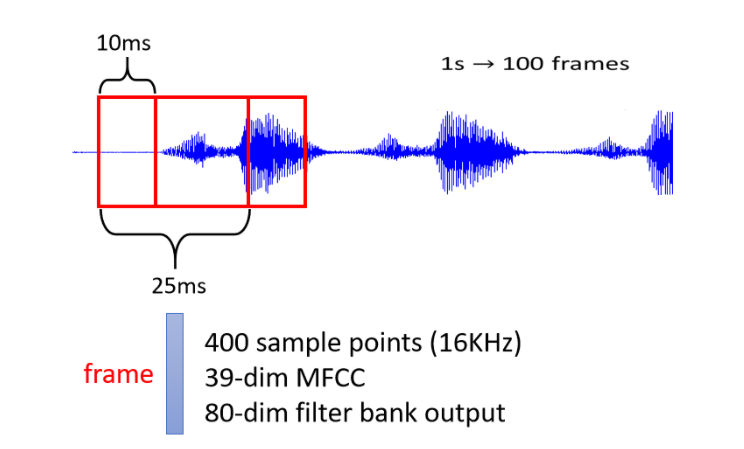
一段声音信号其实就是一排信号,我们可以将一段声音信号取一个范围,这个范围就叫做一个Window,我们将这个Window中的资讯描述成一个向量,这个向量就叫做一个Frame,在语音上,我们会把一个vector叫做一个Frane。通常一个Window的长度就是25个Millisecond。
一段25Millisecond里面的语音信号,为了要描述整个声音信号,我们可以把这个Window向右移动10个Millisecond。
在一段声音信号中,我们用一串向量来表示,而因为每个Window往右是平移10个Milisecond,所以在一秒中的声音信号就有100个向量,因此声音信号是一个很复杂的vector set。
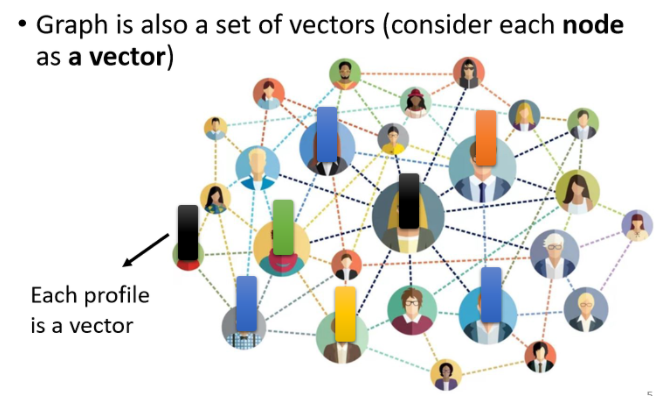
而每一个节点可以看作是一个向量,我们们可以拿其中的任何一个人的,比方说他的个人信息就可以用一个vector来表示)
因此一个Social Network或者Graph也可以看成由一堆向量组成的。(当然分子的信息,我们也可以用graph描述)
; 二、What is the output?
1、每一个向量都有一个对应的一个label
举例来说 在文字处理上,假设你今天要做的是POS Tagging,
POS Tagging就是词性标註,你要让机器自动决定每一个词汇它是什么的词性?(它是名词 还是动词 还是形容词等等)
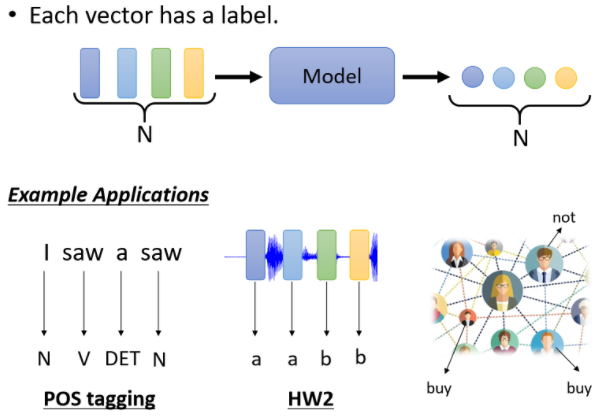
举例来说,你现在看到一个句子, I saw a saw
这个句子意思是:”我看到一个锯子”, 这个第二个saw当名词用的时候,它是锯子,那所以机器要知道,第一个saw是个动词,第二个saw虽然它也是个saw,但它是名词,但是每一个输入的词汇,都要有一个对应的输出的词性
这个任务就是,输入跟输出的长度是一样的Case,这个就是属于第一个类型的输出。
2、一整个Sequence,只需要输出一个Label
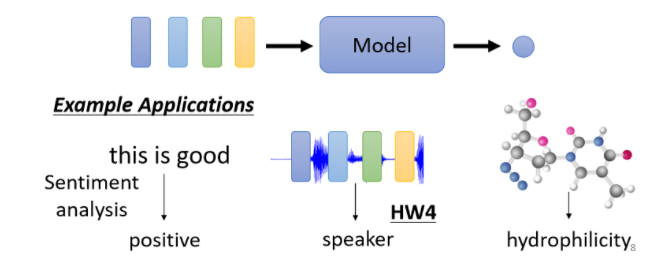
Sentiment Analysis(给机器看一段话,它要决定说这段话是正面的还是负面的)
假设你的公司开发了一个产品,这个产品上线了,你想要知道网友的评价怎么样,但是你又不可能一则一则网友的留言都去分析,那我们就可以使用Sentiment Analysis的技术,让机器自动去判读说,当一则评价里面有提到某个产品的时候,它是正面的还是负面的,那你就可以知道你的产品,在网友心中的评价怎么样,这个是Sentiment Analysis给一整个句子,只需要一个Label,那Positive或Negative,那这个就是第二类的输出。
或者是如果是Graph的话呢,今天你可能想要给一个分子,然后要预测说这个分子,比如说它有没有毒性,或者是它的亲水性如何,那这就是给一个Graph 输出一个Label

翻译就是sequence to sequence的任务,因为输入输出是不同的语言,它们的词汇的数目本来就不会一样多
或者是语音辨识也是,真正的语音辨识也是一个sequence to sequence的任务,输入一句话,然后输出一段文字,这也是一个sequence to sequence的任务
三、Sequence Labeling(输入跟输出数目一样多的状况)
1、解决sequence to sequence问题的方法
直觉的想法就是我们就拿个Fully-Connected的Network
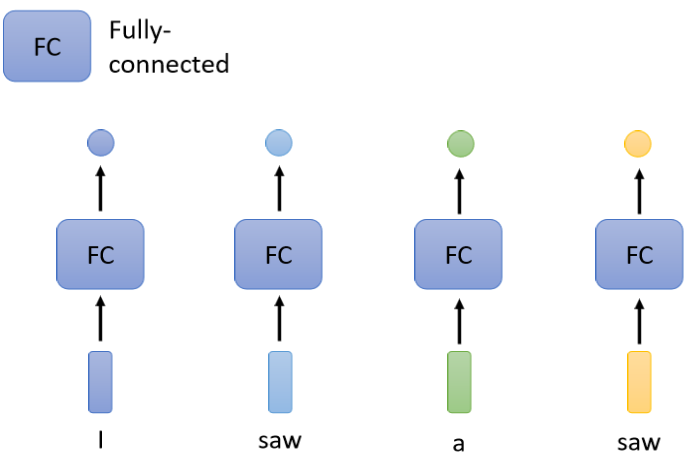
然后虽然这个输入是一个Sequence,但我们就各个击破,不要管它是不是一个Sequence,把每一个向量,分别输入到Fully-Connected的Network里面,然后Fully-Connected的Network就会给我们输出,那现在看看,你要做的是Regression还是Classification,产生正确的对应的输出,就结束了
那这么做显然有非常大的瑕疵,假设今天是,词性标记的问题,你给机器一个句子,I saw a saw,对Fully-Connected Network来说,后面这一个saw跟前面这个saw完全一模一样,它们是同一个词汇,
既然Fully-Connected的Network输入同一个词汇,它没有理由输出不同的东西
但实际上,你期待第一个saw要输出动词,第二个saw要输出名词,但对Network来说它不可能做到,因為这两个saw 明明是一模一样的,你叫它一个要输出动词,一个要输出名词,它会非常地困惑,完全不知道要怎么处理
为了让Fully-Connected的Network,考虑更多的,比如说上下文的Context的资讯把前后几个向量都串起来,一起丢到Fully-Connected的Network就结束了
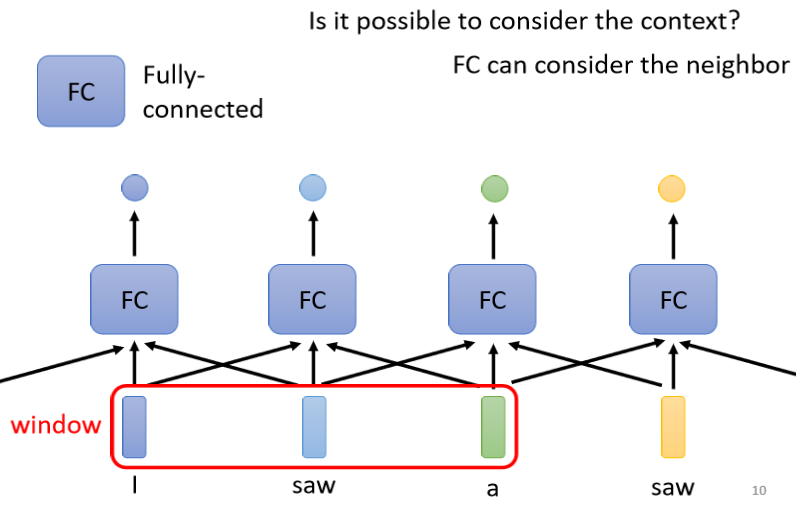
所以我们可以给Fully-Connected的Network,一整个Window的资讯,让它可以考虑一些上下文的,跟我现在要考虑的这个向量,相邻的其他向量的资讯
但是这样子的方法还是有极限,真正的问题,但是如果今天我们有某一个任务,不是考虑一个Window就可以解决的,而是要考虑一整个Sequence才能够解决的话,就算是给你Sequence的资讯,你考虑整个Sequence,你可能也很难再做的更好了。
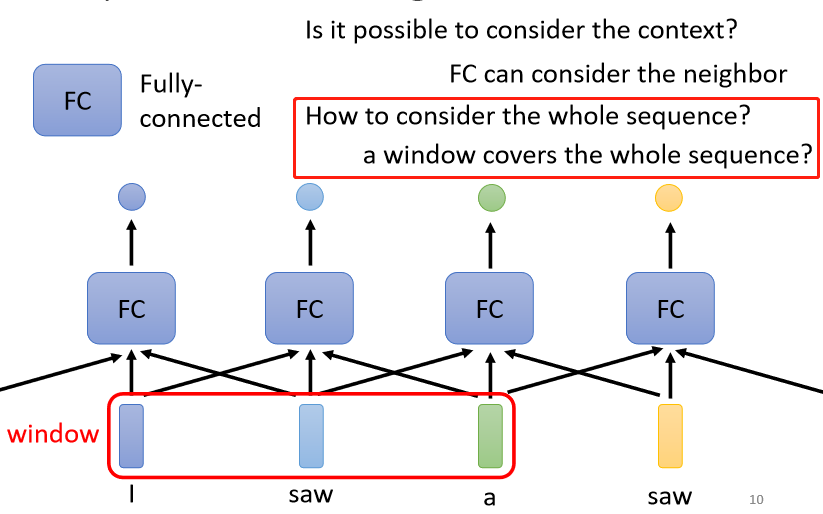
那有人可能会想说这个很容易,我就把Window开大一点,大到可以把整个Sequence盖住就结束了
但是,今天Sequence的长度是有长有短的,我们刚才有说,我们输入给我们的Model的Sequence的长度,每次可能都不一样
如果你今天说我真的要开一个Window,把整个Sequence盖住,那你可能要统计一下你的训练资料,然后看看你的训练资料裡面,最长的Sequence有多长,然后开一个Window比最长的Sequence还要长,你才有可能把整个Sequence盖住
但是你开一个这麼大的Window,意味著说你的Fully-Connected的Network,它需要非常多的参数,那可能不只运算量很大,可能还容易Overfitting
这时候我们可以使用 Self-Attention,考虑整个Input Sequence的资讯
; 四、Self-Attention
Self-Attention的运作方式就是,Self-Attention会”吃”一整个Sequence的资讯
然后你Input几个Vector,它就输出几个Vector,比如说你这边Input一个深蓝色的Vector,这边就给你一个另外一个Vector
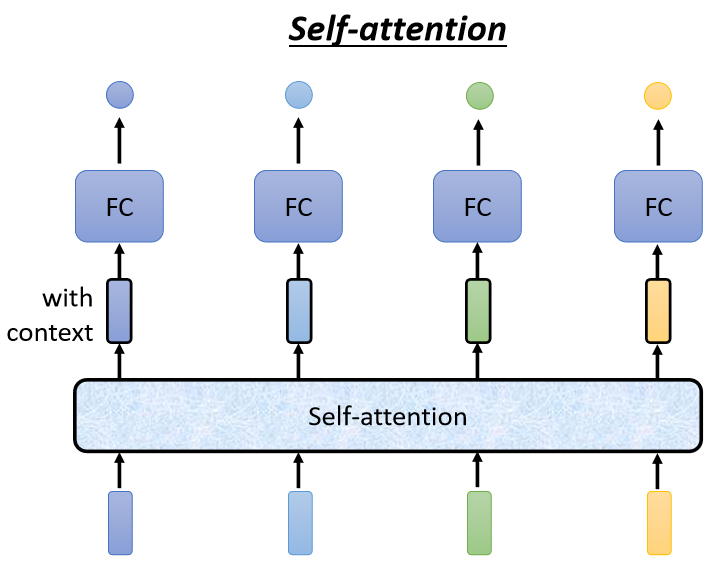
如此一来你这个Fully-Connected的Network,它就不是只考虑一个非常小的范围,或一个小的Window,而是考虑整个Sequence的资讯,再来决定现在应该要输出什么样的结果,这个就是Self-Attention。
Self-Attention不是只能用一次,你可以叠加很多次
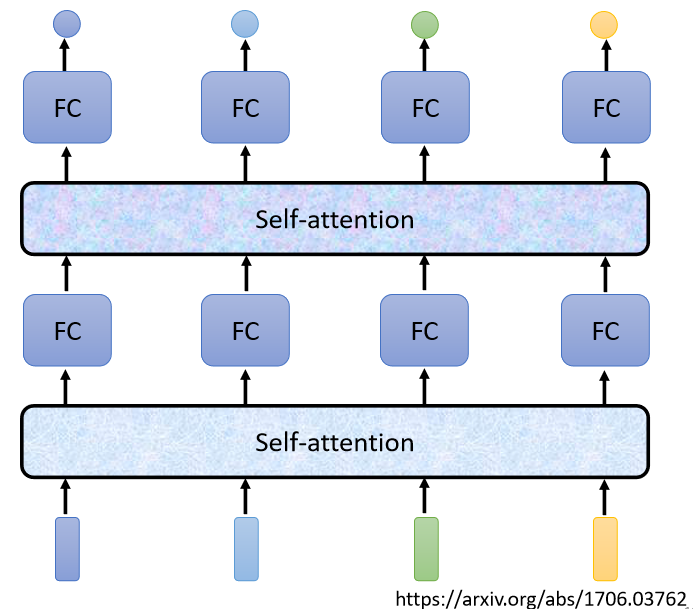
可以Self-Attention的输出,通过Fully-Connected Network以后,再做一次Self-Attention,Fully-Connected的Network,再过一次Self-Attention,再重新考虑一次整个Input Sequence的资讯,再丢到另外一个Fully-Connected的Network,最后再得到最终的结果,所以可以把Fully-Connected的Network,跟Self-Attention交替使用:
1、Self-Attention处理整个Sequence的资讯
2、Fully-Connected的Network,专注于处理某一个位置的资讯
3、再用Self-Attention,再把整个Sequence资讯再处理一次
4、然后交替使用Self-Attention跟Fully-Connected
五、Self-Attention过程
Self-Attention的Input,它就是一串的Vector,那这个Vector可能是你整个Network的Input,它也可能是某个Hidden Layer的Output,所以我们这边不是用x x x来表示它,

我们a a a用来表示它,代表它有可能是前面已经做过一些处理,它是某个Hidden Layer的Output,那Input一排a这个向量以后,Self-Attention要Output另外一排b b b这个向量。
那这每一个b b b都是考虑了所有的a a a以后才生成出来的,所以这边刻意画了非常非常多的箭头,告诉你 b 1 b^{1}b 1 考虑了 a 1 a^{1}a 1 到 a 4 a^{4}a 4 产生的, b 2 b^{2}b 2 考虑 a 1 a^{1}a 1 到 a 4 a^{4}a 4 产生的,b 3 b 4 b^{3} b^{4}b 3 b 4 也是一样,考虑整个input的sequence才产生出来的。
那接下来呢就是要跟大家说明,怎么产生 b 1 b^{1}b 1 这个向量
当我们知道怎么产生 b 1 b^{1}b 1 这个向量以后,你就知道怎么产生 b 1 b 2 b 3 b 4 b^{1} b^{2} b^{3} b^{4}b 1 b 2 b 3 b 4 剩下的向量
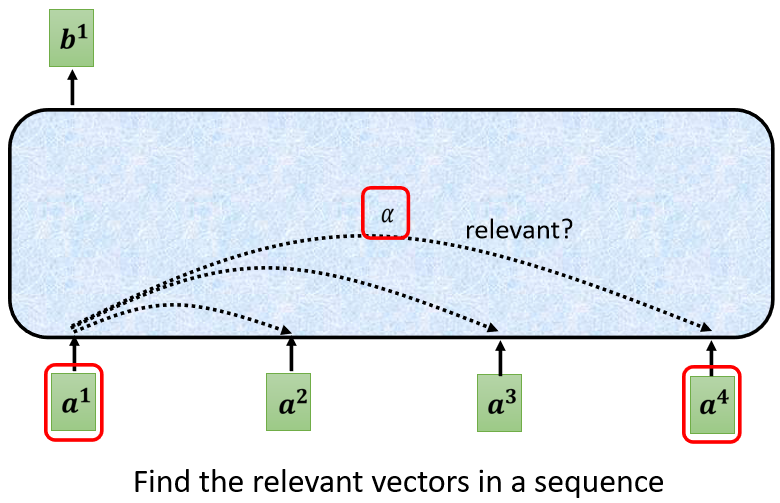
每一个向量跟的关联的程度,用一个数值叫α αα 来表示
这个self-attention的module,怎么自动决定两个向量之间的关联性呢?
你给它两个向量 a 1 a^{1}a 1 跟 a 4 a^{4}a 4, 它怎么决定 a 1 a^{1}a 1 跟 a 4 a^{4}a 4 有多相关,然后给它一个数值α αα,
此时我们需要一个计算attention的模组
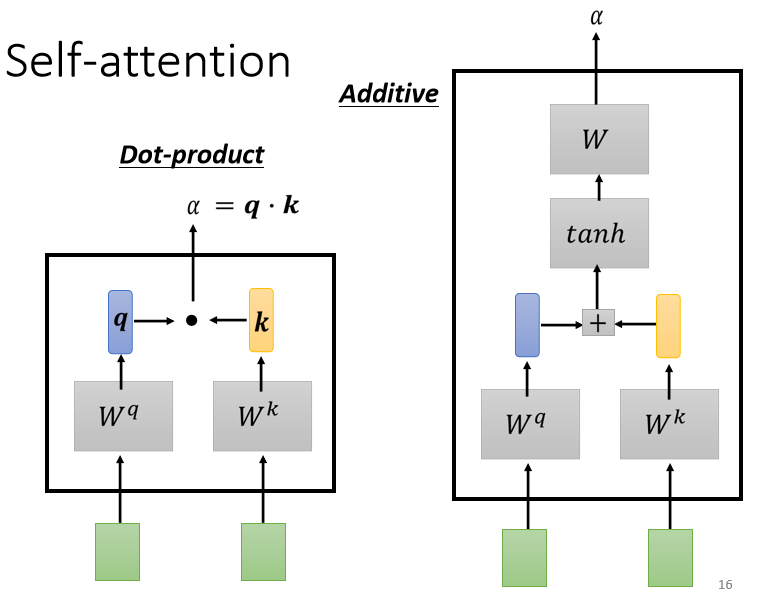
这个计算attention的模组,就是拿两个向量作为输入,然后它就直接输出α αα那个数值,
; 计算这个α αα 的数值有各种不同的做法
1、 dot product(比较常见的作法),输入的这两个向量分别乘上两个不同的矩阵,左边这个向量乘上 W q W^{q}W q 这个矩阵得到矩阵 q q q,右边这 个向量乘上 W k W^{k}W k 这个矩阵得到矩阵 k k k,再把 q q q 跟 k k k 做dot product,就是把他们做element-wise 的相乘,再全部加起来以后就得到一个 scalar,这个scalar就是 a a a, 这是一种计算a的 方式
2、 Additive,它的计算方法就是,把同样这两个向量通过 W q W k W^{q} W^{k}W q W k, 得到 q q q 跟 k k k,那我们不是把它做Dot-Product,是 把它这个串起来,然后丟到这个过一个Activation Function,然后再通过一个Transform,然后得到α αα**
但是在接下来的讨论里面,我们都只用 dot product方法,这也是今日最常用的方法,也是用在Transformer里面的方法
接下来我们要计算一下这一边和这一边的相关性,也就是计算它们之间的α。
[En]
Next, we are going to calculate the correlation between this side and this side, that is, to calculate the α between them.
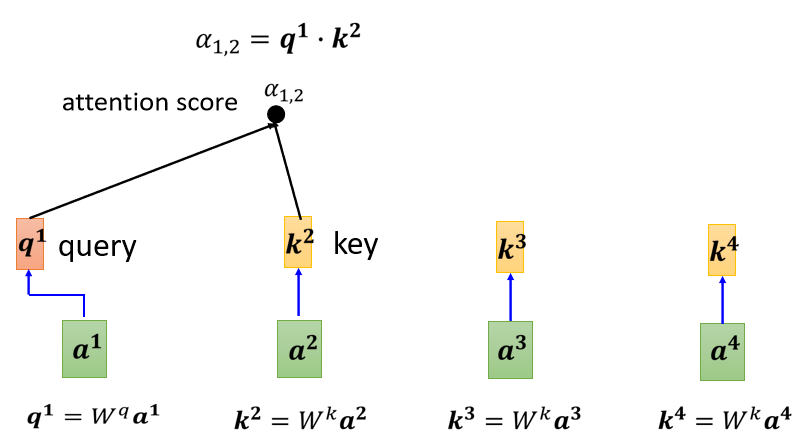
然后接下来 a 2 a 3 a 4 a^{2} a^{3} a^{4}a 2 a 3 a 4 我们都要去把它乘上W k ^{k}k, 得到 k k k 这个Vector, k这个Vectora叫做Key,把这个Query q1,跟这个Key k2,算Inner-product就得到α αα
我们这边用 α 1 , 2 \alpha_{1,2}α1 ,2 来代表说,Query是1提供的,Key是2提供的时候这个1跟2他们之间的关联性,这个a这个关联性叫做Attention的Score, 叫做 Attention的分数,
接下来也要跟 a 3 a 4 a^{3} a^{4}a 3 a 4 来计算
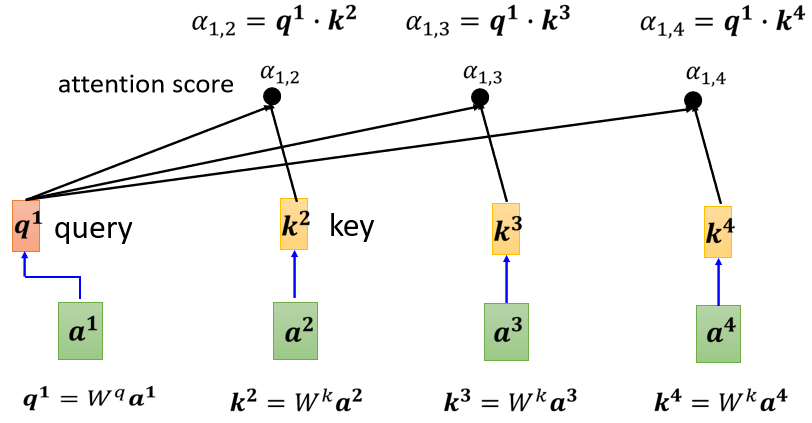
计算出,a1跟每一个向量的关联性以后,接下来这边会接入一个Soft-Max
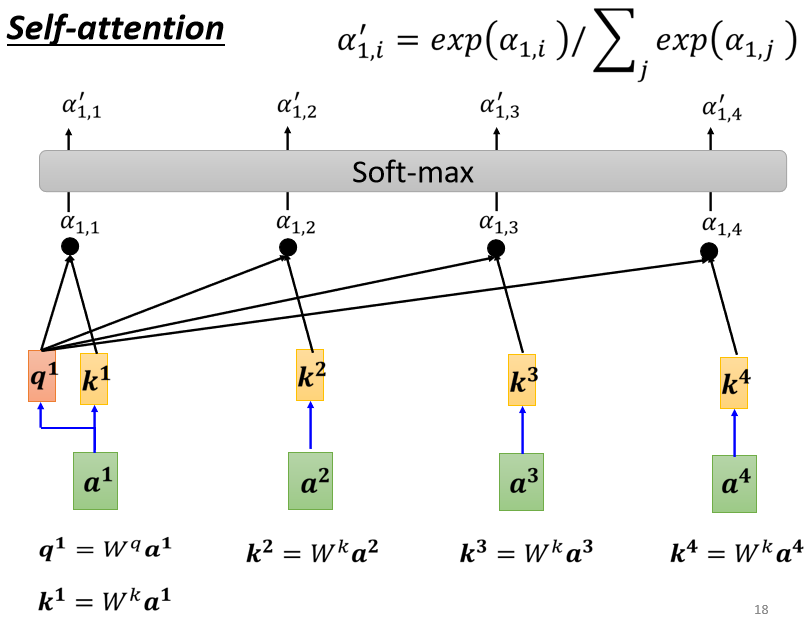
这个Soft-Max跟分类的时候的那个Soft-Max是一模一样的,所以Soft-Max的输出就是一排α αα,所以本来有一排α αα,通过Soft-Max就得到α ′ \alpha^{\prime}α′
这边我们不一定要用Soft-Max,用别的替代也没问题,比如说有人尝试过说做个ReLU,这边通通做个ReLU,那结果发现还比Soft-Max好一点,这边我们要用什么Activation Function都行(Soft-Max是最常见的)。
接下来得到这个α ′ \alpha^{\prime}α′以后,我们就要根据这个α ′ \alpha^{\prime}α′去抽取出这个Sequence里面重要的资讯,
根据这个α 1 \alpha^{1}α1我们已经知道说,哪些向量跟是最有关系的,怎么抽取重要的资讯呢?
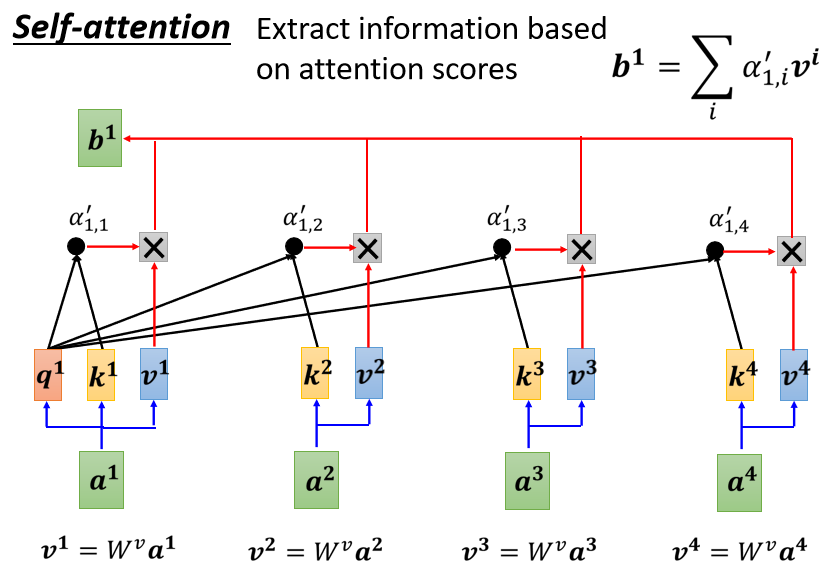
1、首先把 a 1 a^{1}a 1 到 a 4 a^{4}a 4 这边每一个向量,乘上 W v W^{v}W v 得到新的向量,这边分别就是用 v 1 v 2 v 3 v 4 v^{1} v^{2} v^{3} v^{4}v 1 v 2 v 3 v 4 来表示
2、接下来把这边的 v 1 v^{1}v 1 到 v 4 v^{4}v 4,每一个向量都去乘上Attention的分数,都去乘上 α ′ \alpha^{\prime}α′
3、然后再把它加起来,得到 b 1 b^{1}b 1
b 1 = ∑ i α 1 , i ′ v i b^{1}=\sum_{i} \alpha_{1, i}^{\prime} v^{i}b 1 =i ∑α1 ,i ′v i
如果某一个向量它得到的分数越高,比如说如果a 1 a^{1}a 1 跟a 2 a^{2}a 2 的关联性很强,这个α ′ \alpha^{\prime}α′ 得到的值很大,那我们今天在做Weighted Sum以后,得到的b 1 b^{1}b 1 的 值,就可能会比较接近v 2 v^{2}v 2
所以谁的那个Attention的分数最大,谁的那个v就会Dominant你抽出来的结果
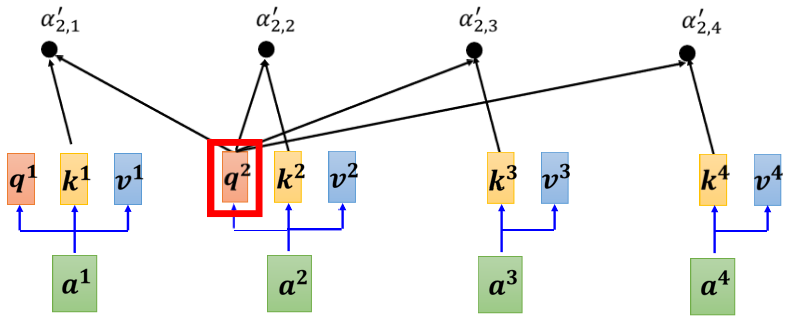
1、把 a 2 a^{2}a 2 乘上一个 matrix,变成 q 2 q^{2}q 2
2、然后接下来根据 q 2 q^{2}q 2,去对 a 1 a^{1}a 1 到 a 4 a^{4}a 4 这四个位置,都去计算 attention 的 score
- 把q 2 q^{2}q 2 跟k 1 k^{1}k 1 做个这个 dot product
- 把q 2 q^{2}q 2 跟k 2 k^{2}k 2 也做个 dot product
- 把q 2 q^{2}q 2 跟k 3 k^{3}k 3 也做 dot product
- 把q 2 q^{2}q 2 跟k 4 k^{4}k 4 也做 dot product,得到四个分数
3、得到这四个分数以后,可能还会做一个 normalization,比如说 softmax,然后得到最后的 attention 的 score, α 2 , 1 ′ α 2 , 2 ′ α 2 , 3 ′ α 2 , 4 ′ \alpha_{2,1}^{\prime} \alpha_{2,2}^{\prime} \alpha_{2,3}^{\prime} \alpha_{2,4}^{\prime}α2 ,1 ′α2 ,2 ′α2 ,3 ′α2 ,4 ′ 那我们 这边用 α ′ \alpha^{\prime}α′ 表示经过 normalization 以后的attention score
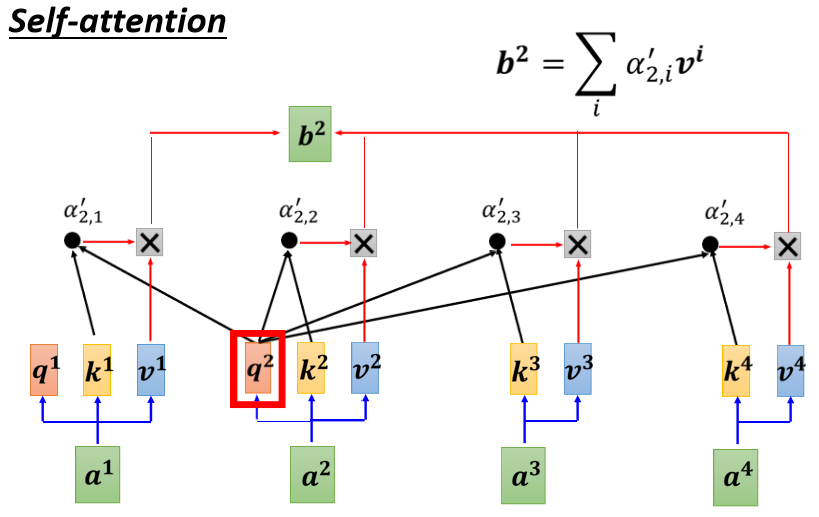
- 把α 2 , 1 ′ \alpha_{2,1}^{\prime}α2 ,1 ′ 乘上v 1 v^{1}v 1
- 把α 2 , 2 ′ \alpha_{2,2}^{\prime}α2 ,2 ′ 乘上v 2 v^{2}v 2
- 把α 2 , 3 ′ \alpha_{2,3}^{\prime}α2 ,3 ′ 乘上v 3 v^{3}v 3
- 把α 2 , 4 ′ \alpha_{2,4}^{\prime}α2 ,4 ′ 乘上v 4 v^{4}v 4,然后全部加起来就是b 2 b^{2}b 2
b 2 = ∑ i α 2 , i ′ v i b^{2}=\sum_{i} \alpha_{2, i}^{\prime} v^{i}b 2 =i ∑α2 ,i ′v i
; 六、从矩阵的角度去计算Self-attention
接下来我们从矩阵乘法的角度,再重分析一下Self-attention 是怎么运作的
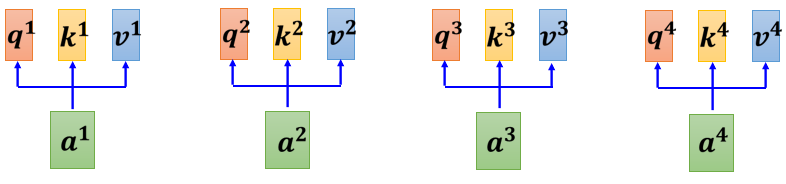
我们每一个 a a a, 都乘上一个矩阵,我们这边用 W q W^{q}W q 来表示它,得到 q i q^{i}q i, 每一个 a a a 都要乘上 W q W^{q}W q, 得到 q i q^{i}q i, 这些不同的a a a 你可以把它合起来,当作一个 矩阵来看待
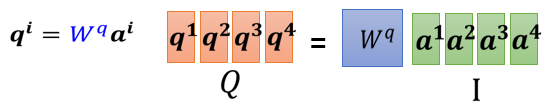
一样 a 2 a 3 a 4 a^{2} a^{3} a^{4}a 2 a 3 a 4 也都乘上 W q W^{q}W q 得到 q 2 q 3 q^{2} q^{3}q 2 q 3 跟 q 4 q^{4}q 4,那你可以把 a 1 \mathrm{a} 1 a 1 到 a 4 \mathrm{a} 4 a 4 拼起来,看作是一个矩阵,这个矩阵我们用 I I I 来表示, 这个矩阵的四个 column 就是 a 1 a^{1}a 1 到 a 4 a^{4}a 4
I I I 乘上 W q W^{q}W q 就得到另外一个矩阵,我们用 Q Q Q 来表示它,这个 Q Q Q 就是把 q 1 q^{1}q 1 到 q 4 q^{4}q 4 这四个 vector 拼起来,就是 Q Q Q 的四个 column
所以我们 从 a 1 a^{1}a 1 到 a 4 a^{4}a 4,得到 q 1 q^{1}q 1 到 q 4 q^{4}q 4 这个操作, 其实就是把I I I 这个矩阵,乘上另外一个矩阵W q W^{q}W q, 得到矩阵 Q ∘ I Q_{\circ} I Q ∘I 这个矩阵它裡面的 column就 是我们 Self-attention 的 input是 a 1 a^{1}a 1 到 a 4 ; ∗ ∗ W q a^{4} ; W^{q}a 4 ;∗∗W q 其实是 network 的参数,它是等一下会被learn出来的 ; Q Q Q 的四个 column,就是 q 1 q^{1}q 1 到 q 4 q^{4}q 4
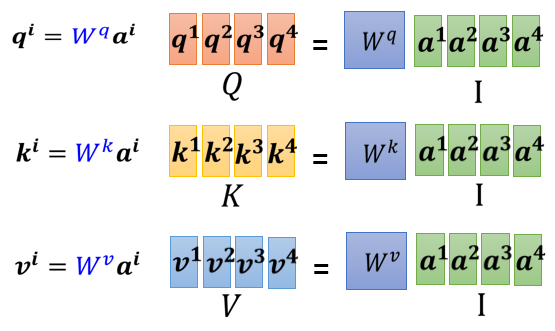
所以每一个 a 得到 q k v ,其实就是把输入的这个,vector sequence 乘上三个不同的矩阵,你就得到了 q,得到了 k,跟得到了 v
下一步是,每一个 q 都会去跟每一个 k,去计算这个 inner product,去得到这个 attention 的分数
那得到 attention 分数这一件事情,如果从矩阵操作的角度来看,它在做什么样的事情呢?
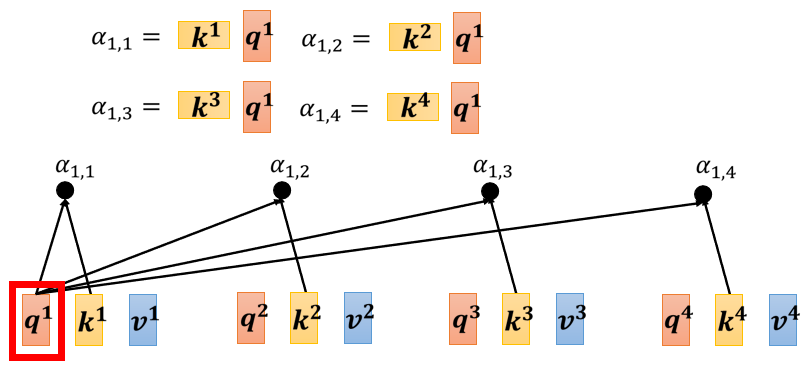
你就是把 q 1 q^{1}q 1 跟 k 1 k^{1}k 1 做 inner product,得到 α 1 , 1 \alpha_{1,1}α1 ,1 ,所以 α 1 , 1 \alpha_{1,1}α1 ,1 就是 q 1 q^{1}q 1 跟 k 1 k^{1}k 1 的 inner product,那这边我就把这个, k 1 k^{1}k 1 它背后的这个向量,把它画成 比较宽一点代表说它是 transpose
同理 α 1 , 2 \alpha_{1,2}α1 ,2 就是 q 1 q^{1}q 1 跟 k 2 k^{2}k 2,做 inner product, α 1 , 3 \alpha_{1,3}α1 ,3 就是 q 1 q^{1}q 1 跟 k 3 k^{3}k 3 做 inner product,这个 α 1 , 4 \alpha_{1,4}α1 ,4 就是 q 1 q^{1}q 1 跟 k 4 k^{4}k 4 做 inner product 那这个四个步骤的操作,你其实可以把它拼起来,看作是矩阵跟向量相乘
那这个四个步骤的操作,你其实可以把它拼起来,看作是 矩阵跟向量相乘
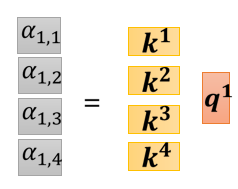
这四个动作,可以看作是我们把 k 1 k^{1}k 1 到 k 4 k^{4}k 4 拼起来,当作是一个矩阵的四个 row
那我们刚才讲过说我们不只是 q 1 q^{1}q 1,要对 k 1 k^{1}k 1 到 k 4 k^{4}k 4 计算 a t t e n t i o n , q 2 , q 3 , q 4 \mathrm{attention}, q^{2}, q^{3}, q^{4}a t t e n t i o n ,q 2 ,q 3 ,q 4 也要对 k 1 k^{1}k 1 到 k 4 k^{4}k 4 计算 attention,操作其实都是一模一样的

所以这些 attention 的分数可以看作是两个矩阵的相乘一个矩阵它的 row,就是 k 1 k^{1}k 1 到 k 4 k^{4}k 4,另外一个矩阵它的 column
我们会在 attention 的分数,做一下 normalization,比如说你会做 softmax,你会对这边的每一个 column,每一个 column 做 softmax,让每 一个 column 裡面的值相加是 1
之前有讲过说 其实这边做 softmax不是唯一的选项,你完全可以选择其他的操作,比如说 ReLU 之类的,那其实得到的结果也不会比较差,通 过了 softmax 以后,它得到的值有点不一样了,所以我们用 A ′ A^{\prime}A ′,来表示通过 softmax 以后的结果
我们已经计算出 A ′ A^{\prime}A ′
那我们把这个 v 1 v^{1}v 1 到 v 4 v^{4}v 4 乘上这边的 a a a 以后,就可以得到 b b b
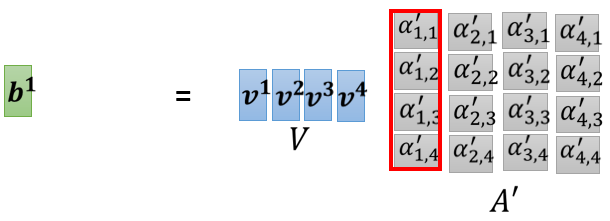
如果熟悉线性代数的话,你知道说把这个 A ′ A^{\prime}A ′ 乘上 V V V, 就是把 A ′ A^{\prime}A ′ 的第一个 column,乘上 V V V 这一个矩阵,你会得到你 output 矩阵的第一个 column
而把 A \mathrm{A}A 的第一个 column乘上 V \mathrm{V}V 这个矩阵做的事情,其实就是把 V \mathrm{V}V 这个矩阵里面的每一个 column,根据第 A ′ A^{\prime}A ′ 这个矩阵里面的每一个 column 里面每一个 element,做 weighted sum,那就得到 b 1 b^{1}b 1
那就是这边的操作,把 v 1 v^{1}v 1 到 v 4 v^{4}v 4 乘上 weight,全部加起来得到 b 1 b^{1}b 1,
如果我们是用矩阵操作的角度来看它,就是把 A ′ A^{\prime}A ′ 的第一个 column 乘上 V \mathrm{V}V,就得到 b 1 b^{1}b 1,然后接下来就是以此类推
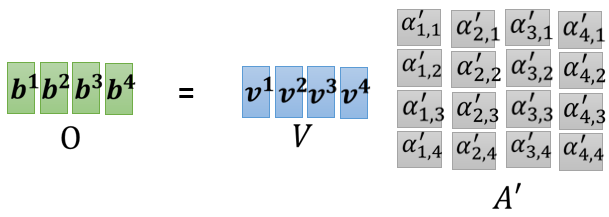
就是以此类推,把 A ′ A^{\prime}A ′ 的第二个 column 乘上 V \mathrm{V}V, 就得到 b 2 , A ′ b^{2}, A^{\prime}b 2 ,A ′ 的第三个 column 乘上 V V V 就得到 b 3 , A ′ b^{3}, A^{\prime}b 3 ,A ′ 的最后一个 column 乘上 V V V,就得到 b 4 b^{4}b 4 所以我们等于就是把 A ′ A^{\prime}A ′ 这个矩阵,乘上 V V V 这个矩阵,得到 O O O 这个矩阵,O 这个矩阵里面的每一个 column,就是 Self-attention 的输出,也就是 b 1 b^{1}b 1 到 b 4 b^{4}b 4
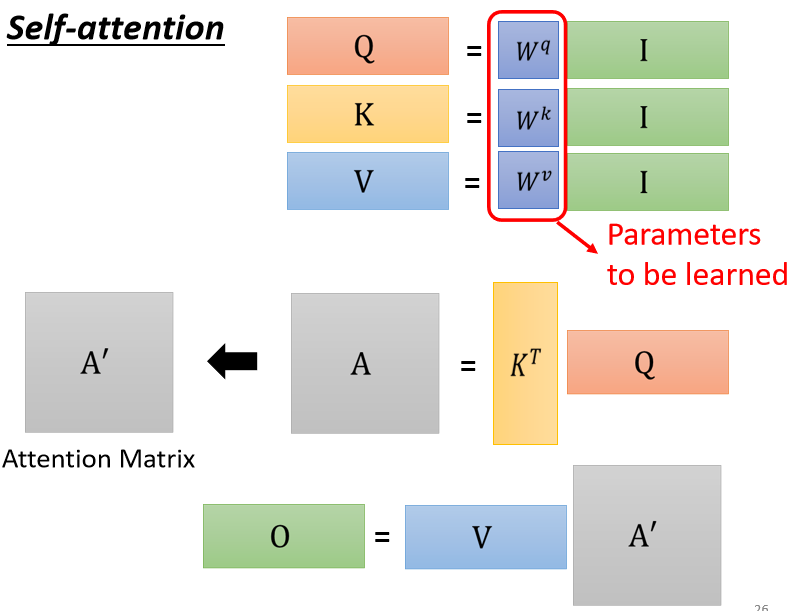
- I 是 Self-attention 的 input,Self-attention 的 input 是一排的vector,这排 vector 拼起来当作矩阵的 column,就是 I
- 这个 input 分别乘上三个矩阵,W q W k W^{q} W^{k}W q W k 跟W v W^{v}W v,得到 Q K V
- 这三个矩阵,接下来Q \mathrm{Q}Q 乘上K \mathrm{K}K 的 transpose,得到A \mathrm{A}A 这个矩阵,A \mathrm{A}A 的矩阵你可能会做一些处理,得到A ′ A^{\prime}A ′,那有时候我们会把这个A ′ A^{\prime}A ′, 叫做 Attention Matrix, 生成Q矩阵就是为了得到Attention的score
- 然后接下来你把A ′ A^{\prime}A ′ 再乘上V V V,就得到 O,O 就是 Self-attention 这个 layer 的输出,生成V是为了计算最后的b, 也就是矩阵O \mathrm{O}O
所以 Self-attention 输入是 l,输出是 O,我们发现说虽然是叫 attention,但是其实 Self-attention layer 里面,唯一需要学的参数,就只有 W q W k W^{q} W^{k}W q W k 跟 W v W^{v}W v 而已,只有 W q W k W^{q} W^{k}W q W k 跟 W v W^{v}W v 是末知的,是需要透过我们的训练资料把它找出来的
但是其他的操作都没有末知的参数,都是我们人为设定好的,都不需要透过 training data 找出来,那这整个就是 Self-attention 的操作,从 I 到 O 就是做了 Self-attention
七、Multi-head Self-attention
Self-attention 有一个进阶的版本,叫做 Multi-head Self-attention, Multi-head Self-attention,其实今天的使用是非常地广泛的
需要用多少的 head,这个又是另外一个 hyperparameter,也是我们需要调的
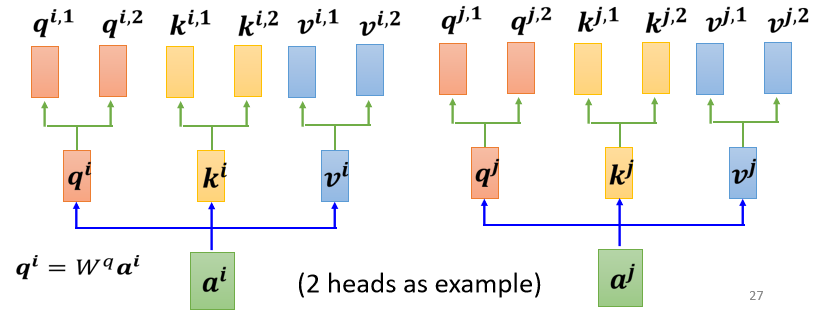
- 先把a a a 乘上一个矩阵得到q q q
- 再把q q q 乘上另外两个矩阵,分别得到q 1 q^{1}q 1 跟q 2 q^{2}q 2,那这边还有 这边是用两个上标, i 代表的是位置,然后这个 1 跟 2 代表是,这个位置 的第几个 q,所以这边有q i , 1 q^{i, 1}q i ,1 跟q i , 2 q^{i, 2}q i ,2,代表说我们有两个 head
我们认为这个问题,里面有两种不同的相关性,是我们需要产生两种不同的 head,来找两种不同的相关性
既然 q q q 有两个,那 k k k 也就要有两个,那 v v v 也就要有两个, 从 q q q 得到 q 1 q 2 q^{1} q^{2}q 1 q 2, 从 k k k 得到 k 1 k 2 , 从 ∨ k^{1} k^{2}, 从 \vee k 1 k 2 ,从∨ 得到 v 1 v 2 v^{1} v^{2}v 1 v 2,那其实就是把 q q q 把 k \mathrm{k}k 把 v \mathrm{v}v,分别乘上两个矩阵,得到这个不同的 head,就这样子而已,
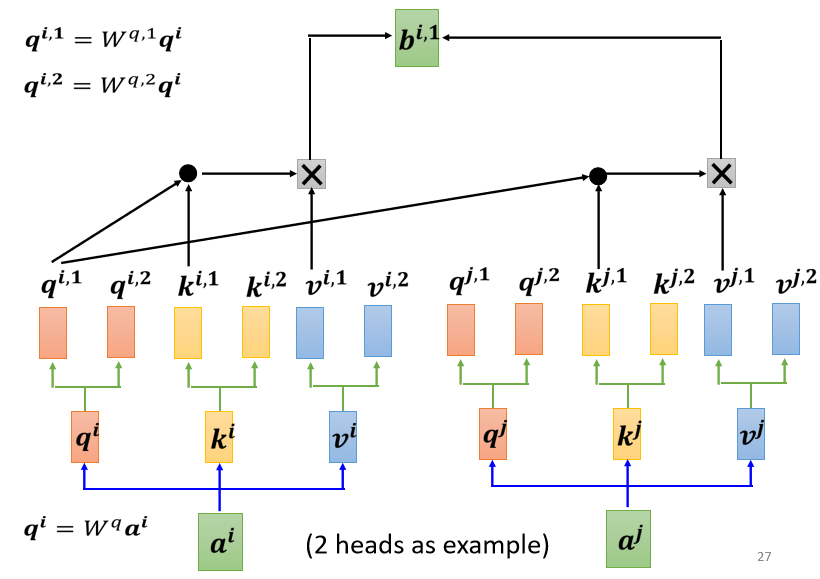
- 所以q i , 1 q_{i, 1}q i ,1 就跟k i , 1 k^{i, 1}k i ,1 算 attention
- q i , 1 q_{i, 1}q i ,1 就跟k j , 1 k^{j, 1}k j ,1 算 attention,也就是算这个 dot product,然后得到这个 attention 的分数
- 然后今天在做 weighted sum 的时候,也不要管v 2 v^{2}v 2 了,看V i , 1 V^{i, 1}V i ,1 跟v j , 1 v^{j, 1}v j ,1 就好,把 attention 的分数乘v i , 1 v^{i, 1}v i ,1,把 attention 的分数乘v j , 1 v^{j, 1}v j ,1
- 然后接下来就得到b i , 1 b^{i, 1}b i ,1
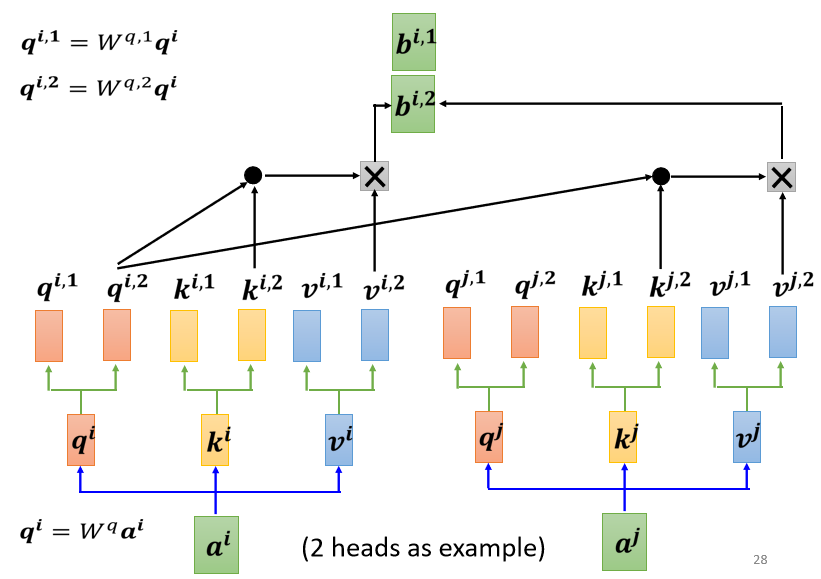
所以 q 2 q^{2}q 2 只对 k 2 k^{2}k 2 做 attention,它们在做 weighted sum 的时候,只对 v 2 v^{2}v 2 做 weighted sum,然后接下来我们就得到 b i , 2 b^{i, 2}b i ,2
如果有多个 head,有 8 个 head 有 16 个 head,那也是一样的操作,那这边是用两个 head 来当作例子
然后接下来我么可以 把 b i , 1 b^{i, 1}b i ,1 跟 b i , 2 b^{i, 2}b i ,2,把它接起来,然后再通过一个 transform
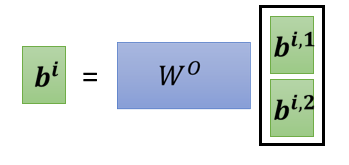
也就是再乘上一个矩阵,然后得到 bi,然后再送到下一层去,那这个就是 Multi-head attention,一个这个 Self-attention 的变形
; 八、Positional Encoding
目前为止,我们会发现 Self-attention 的这个 layer,它少了一个也许很重要的资讯,这个资讯是位置的资讯
我们做 Self-attention 的时候,如果觉得位置的资讯是一个重要的事情,那可以把位置的资讯把它塞进去,
怎么把位置的资讯塞进去呢,这边就要用到一个叫做positional encoding 的技术
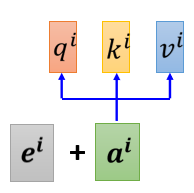
我们为每一个位置设定一个 vector, 叫做 positional vector,这边用 e i e^{i}e i 来表示,上标 i 代表是位置,每一个不同的位置,就有不同的vector,就是 e 1 e^{1}e 1 是一个 vector, e 2 e^{2}e 2 是一个vector, e 128 e^{128}e 1 2 8 是一个vector,不同的位置都有一个它专属的 e,然后 把这个 e 加到 a i a^{i}a i 上面,就结束了(就是告诉我们Self-attention,位置的资讯,如果它看到说 a i a^{i}a i 好像有被加上 e i e^{i}e i,它就知道说现在出现的位置,应该是在 i 这个位置)
九、Self-attention for Speech
比如说在做语音的时候,我们也可以用 Self-attention,不过在做语音的时候,可能会对 Self-attention,做一些小小的改动
因为一般语音的,如果我们要把一段声音讯号,表示成一排向量的话,这排向量可能会非常地长

而每一个向量,其实只代表了 10 millisecond 的长度而已,所以如果今天是 1 秒鐘的声音讯号,它就有 100 个向量了,5 秒钟的声音讯号,就 500 个向量了,我们随便讲一句话,都是上千个向量了
所以一段声音讯号,要描述它的时候,那个像这个 vector 的 sequence 它的长度是非常可观的,
那可观的 sequence,可观的长度,会造成什么问题呢?
我们今天在计算这个 attention matrix 的时候,它的 计算complexity 是长度的平方
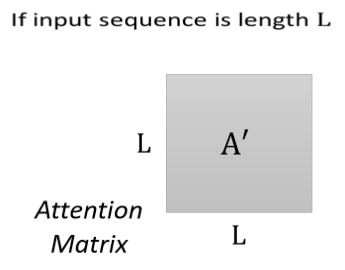
计算这个 attention matrix A \mathrm{A}A 我们需要做 L \mathrm{L}L 乘以 L \mathrm{L}L 次的 inner product,那如果这个 L \mathrm{L}L 的值很大的话,它的计算量就很 可观,也需要很大的这个 memory, 才能够把这个矩阵存下来
所以今天如果在做语音辨识的时候,一句话所产生的这个attention matrix,可能会太大,大到你根本就不容易处理,不容易训练,所以在做语音的时候,有一招叫做 Truncated Self-attention
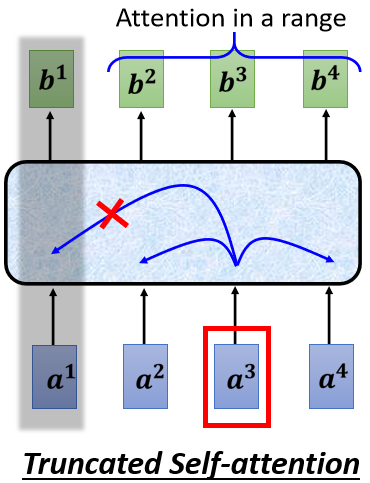
Truncated Self-attention做的事情就是,我们今天在做Self-attention的时候,不要看一整句话,就我们就只看一个小的范围就好
至于这个范围应该有多大,这是由人们设定的。
[En]
As for how big this range should be, that one is set by people.
今天在做语音辨识的时候,也许只需要看一个小的范围就好,那就是取决于你对这个问题的理解,也许我们要辨识这个位置有什么样的phoneme,这个位置有什么样的内容,我们并不需要看整句话,只要看这句话,跟它前后一定范围之内的资讯,其实就可以判断,所以如果在做 Self-attention 的时候,也许没有必要看过一整个句子,也许没有必要让 Self-attention 考虑一整个句子,也许只需要考虑一个小范围就好,这样就可以加快运算的速度,这个是 Truncated Self-attention。
; 十、Self-attention与CNN比较
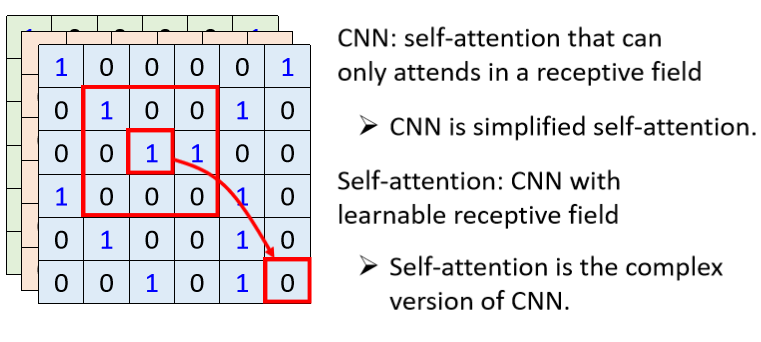
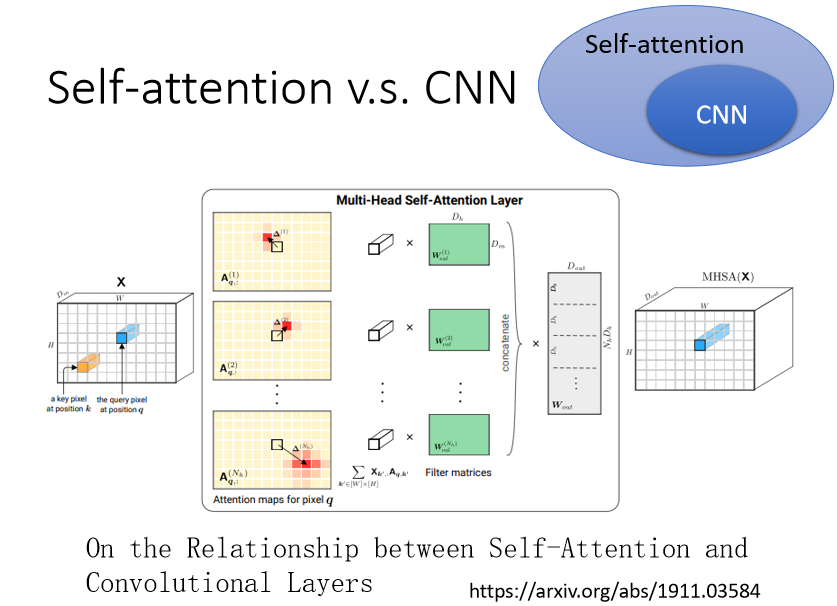
用 Self-attention 来处理一张图片,代表说,假设这个是你要考虑的 pixel,那它产生query,其他 pixel 产生 key,今天在做 inner product 的时候,考虑的不是一个小的receptive field的信息,而是整张影像的资讯。
但是今天在做 CNN 的时候,会画出一个 receptive field,每一个 filter,每一个 neural,只考虑 receptive field 范围裡面的资讯
CNN 可以看作是一种简化版的 Self-attention,因为在做CNN的时候,我们只考虑 receptive field 里面的资讯,而在做 Self-attention 的时候,我们是考虑整张图片的资讯,所以 CNN,是简化版的 Self-attention(或者是你可以反过来说,Self-attention 是一个复杂化的 CNN)
在 CNN 裡面,我们要划定 receptive field,每一个 neural,只考虑 receptive field 裡面的资讯,而 receptive field 的范围跟大小,是人决定的,
而对 Self-attention 而言,我们用 attention,去找出相关的 pixel,就好像是 receptive field 是自动被学出的,network 自己决定说,receptive field 的形状长什么样子,network 自己决定说,以这个 pixel 为中心,哪些 pixel 是我们真正需要考虑的,那些 pixel 是相关的
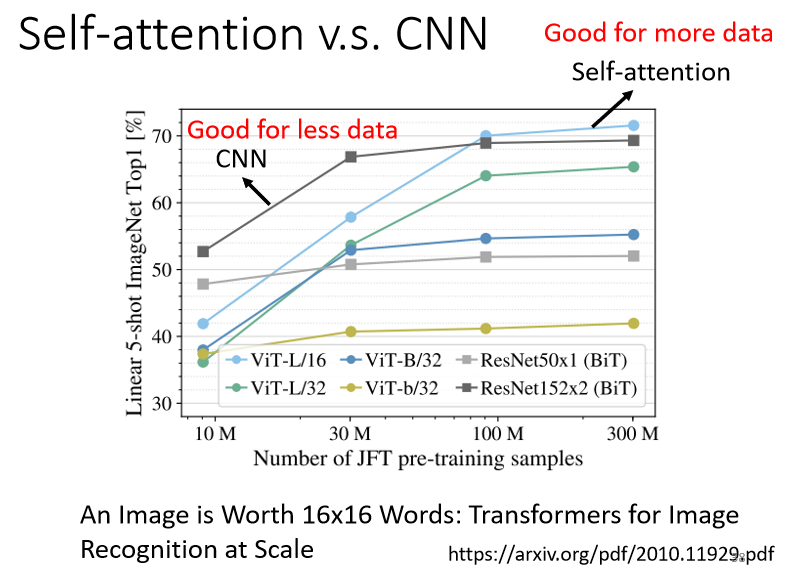
既然Self-attention 比较 flexible,之前有讲说比较 flexible 的 model,比较需要更多的 data,如果你 data 不够,就有可能 overfitting
就会发现说,随著资料量越来越多,那 Self-attention 的结果就越来越好,最终在资料量最多的时候,Self-attention 可以超过 CNN,但在资料量少的时候,CNN 它是可以比 Self-attention,得到更好的结果的
十一、Self-attention与RNN的比较
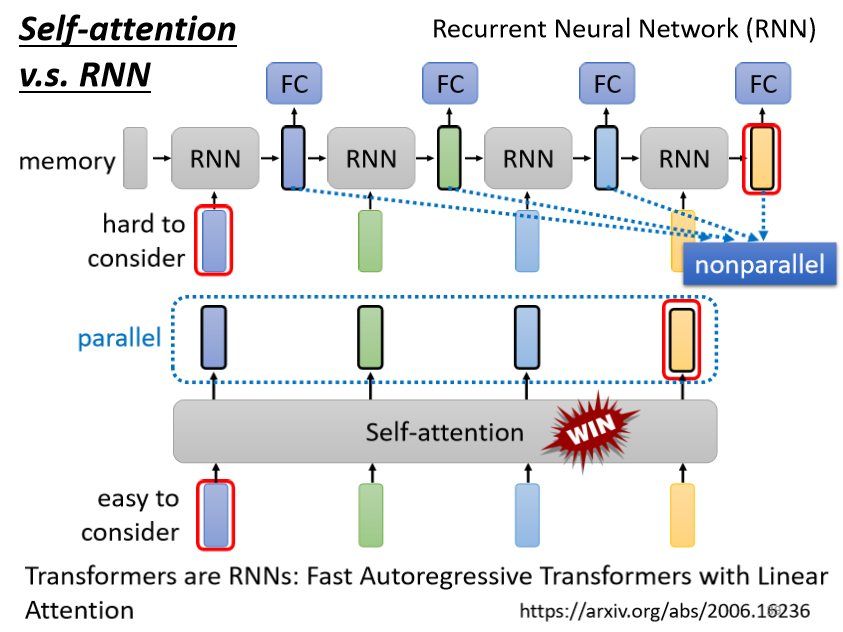
在 RNN 中:
- 左边是你的 input sequence,你有一个 memory 的 vector
- 然后你有一个 RNN 的 block,这个 RNN 的 block 呢,它”吃” memory 的 vector”吃”第一个 input 的 vector
- 然后 output 一个东西,然后根据这个 output 的东西,我们通常叫做这个 hidden,这个 hidden 的 layer 的 output
- 然后通过这个 fully connected network,然后再去做你想要的 prediction
接下来当sequence里面,第二个 vector 作为 input 的时候,也会把前一个时间点吐出来的东西,当做下一个时间点的输入,再丢进 RNN 里面,然后再产生新的 vector,再拿去给 fully connected network
然后第三个 vector 进来的时候,你把第三个 vector 跟前一个时间点的输出,一起丢进 RNN,再產生新的输出,然后在第四个时间点
第四个 vector 输入的时候,把第四个 vector 跟前一个时间点,產生出来的输出,再一起做处理,得到新的输出,再通过 fully connected network 的 layer,这个就是 RNN
Recurrent Neural Network跟 Self-attention 做的事情其实也非常像,它们的 input 都是一个 vector sequence
Self-attention output 是另外一个 vector sequence,这里面的每一个 vector,都考虑了整个 input sequence 以后,再给 fully connected network 去做处理
RNN它也会 output 另外一群 vector,这另外一排 vector 也会给,fully connected network 做进一步的处理
那 Self-attention 跟 RNN 有什么不同呢?
当然一个非常显而易见的不同,你可能会说,这边的每一个 vector,它都考虑了整个 input 的 sequence,而 RNN 每一个 vector,只考虑了左边已经输入的 vector,它没有考虑右边的 vector,那这是一个很好的观察
但是 RNN 其实也可以是双向的,所以如果你 RNN 用双向的 RNN 的话,其实这边的每一个 hidden 的 output,每一个 memory 的 output,其实也可以看作是考虑了整个 input 的 sequence。
但是假设我们把 RNN 的 output,跟 Self-attention 的 output 拿来做对比的话,就算我们用 bidirectional 的 RNN,还是有一些差别的:
对 RNN 来说,假设最右边这个黄色的 vector,要考虑最左边的这个输入,那它必须要把最左边的输入存在 memory 里面,然后接下来都不能够忘掉,一路带到最右边,才能够在最后一个时间点被考虑
但对 Self-attention 来说没有这个问题,它只要这边输出一个 query,这边输出一个 key,只要它们 match 得起来你可以从非常远的 vector,在整个 sequence 上非常远的 vector,轻易地抽取资讯
还有另外一个更主要的不同是,RNN 今天在处理的时候, input 一排 sequence,output 一排 sequence 的时候,RNN 是没有办法平行化的
但 Self-attention 有一个优势,是它可以平行处理所有的输出,我们input 一排 vector,再 output 这四个 vector 的时候,这四个 vector 是平行产生的,并不需要等谁先运算完才把其他运算出来,output 的这个 vector,里面的 output 这个 vector sequence 里面,每一个 vector 都是同时产生出来的
所以在运算速度上,Self-attention 会比 RNN 更有效率
Original: https://blog.csdn.net/weixin_46070306/article/details/120266229
Author: 所追寻的那座城
Title: Self-attention算法
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/512532/
转载文章受原作者版权保护。转载请注明原作者出处!