

真实感音频驱动视频肖像
链接
介绍页:
https://richardt.name/publications/audio-dvp/
paper:
https://richardt.name/publications/audio-dvp/AudioDVP-WenEtAl-TVCG2020.pdf


图 1. 我们提出了一种新方法,用于生成与目标视频中的演员相对应的逼真视频肖像,由任意语音音频重演。我们的方法在视频会议、虚拟教育和培训场景中都有应用。
; 摘要
视频人像在视频会议、新闻广播、虚拟教育培训等各种应用中都很常见。我们提出了一种新方法来为输入的人像视频合成逼真的视频人像,由人的声音自动驱动。这项任务的主要挑战是从输入语音音频中产生似是而非的、逼真的面部表情的幻觉。为了应对这一挑战,我们采用了由几何、面部表情、光照等表示的参数化 3D 面部模型,并学习从音频特征到模型参数的映射。输入源音频首先表示为高维特征,用于预测3D人脸模型的面部表情参数。然后我们用预测的替换从原始目标视频计算的表情参数,并重新渲染重新制作的人脸。最后,我们通过神经面部渲染器从重演的合成面部序列生成逼真的视频肖像。我们方法的一个吸引人的特点是各种输入语音音频的泛化能力,包括来自文本到语音软件的合成语音音频。广泛的实验结果表明,我们的方法优于以前的通用音频驱动视频肖像方法。这包括一项用户研究,证明我们的结果比以前的方法更真实。
- 介绍
来自说话者面部的视觉信息,例如他们的嘴唇动作,可以提高一般人类交流中的语音理解能力。它在理解听力障碍者的语音内容或当声学信号被背景噪声破坏时起着至关重要的作用。然而,在许多场景中,例如医生和飞行员的电话或 VR/AR 专业培训,由于缺乏摄像头、隐私问题或网络带宽有限,语音通信纯粹是听觉的,缺少视觉对应物。为提升在这些场景中的语音理解,已经提出了许多方法来实时从声学语音合成一张说话的脸,作为虚拟 [21, 28, 47] 或逼真的头像 [40, 46]。当头像与真实用户相似时,用户的存在感也会增加[26, 36]。
视频肖像提供了一个人脸的逼真视觉内容,完美地保持了他们的身份,常用于视频会议、虚拟锚定和虚拟培训。然而,生成与声学信号相匹配的合理视觉内容具有挑战性,并且嘴巴运动和发音之间的任何错位都会降低视觉体验。这一挑战背后的基本技术问题是从原始音频信号到逼真图像的映射。现有的音频驱动视频肖像生成技术产生的结果对于应用程序的要求不够逼真,或者不能很好地泛化到给定的音频或目标视频输入。可以通过编辑文本来生成和编辑视频人像 [3,18]。然而,当前的基于文本的方法要么专注于预录视频的剪切和过渡操作 [3],不能用新文本生成结果,要么为指定的表演者合成新的视听语音内容 [18] 至少有一个小时的镜头用于特征搜索,不适用于实时应用。
在这项工作中,我们提出了一种新颖的实时照片级逼真视频肖像生成方法。我们建议使用神经网络从音频输入中预测参数化 3D 面部模型的面部表情分量,而不是直接学习从音频中预测 2D 肖像图像序列。然后,我们将预测的面部表情与从目标视频计算的其他组件混合,以生成重演的 3D 面部序列。使用在目标视频上训练的神经面部渲染器,将重新制作的 3D 面部转换为逼真的视频肖像。所有源代码都是公开的。
我们为这项工作作出了以下贡献:
[En]
We have made the following contributions to this work:
在给定输入语音音频的情况下,我们的方法生成目标演员的逼真视频肖像。目标三分钟的视频足以训练我们的整个管道–比现有方法少得多。
[En]
Given the input voice audio, our method generates a realistic video portrait of the target actor. The target’s three-minute video is enough to train our complete pipeline-much less data than existing methods.
* 我们提出了一种音频到面部表情的映射模块,可以将身份无关的语音音频转换为目标演员的面部表情参数,并且只对单一的目标人像视频进行训练。
[En]
We propose an audio-to-facial expression mapping module, which can convert identity-independent voice audio into the facial expression parameters of the target actor, and train only on a single target portrait video.
* 我们通过广泛的用户研究来评估我们方法的有效性。与现有的一般音频驱动的视频人像方法相比,我们的结果被参与者评价为最逼真的。
[En]
We evaluate the effectiveness of our approach through extensive user research. Compared with the existing general audio-driven video portrait methods, our results are rated as the most realistic by the participants.
- 相关工作
2.1 单目 3D 人脸重建
单目 3D 人脸重建旨在从视觉数据中重建面部几何形状和外观,包括面部表情 [4, 19, 46, 52]。这是面部再现的基础。基于模型的方法是常见的做法;当在综合分析范式中最小化重建能量时,他们采用参数人脸模型 [4, 17] 作为先验。根据视觉输入数据的类型,方法可以分为基于单幅图像的 [4, 42]、基于照片收集的 [16, 43] 和基于视频的 [19, 44, 52]。最近,已经提出了各种基于深度学习的方法来估计 3D 模型参数 [16、20、23、31、49]。除了模型参数之外,一些方法还可以回归精细尺度的皮肤细节 [6, 42, 49]。这是一个活跃的研究领域,有各种各样的作品;更多信息,我们参考最近的调查 [17, 55, 65]。
2.2 视频驱动的面部重演
视频驱动的面部重演需要两个面部序列作为输入:源和目标。使用源人脸的表情参数重新制定目标人脸。 Face2Face [52] 是一种实时视频重演方法,它采用高分辨率皮肤纹理并使用数据驱动的方法合成口腔。 Averbuch-Elor 等人。 [1] 提出了一种使用驾驶视频自动为静止图像人像制作动画的技术,方法是通过 2D 变形将面部表情从视频传输到图像,并合成嘴巴内部。类似的肖像图像动画可以通过从说话的头部视频中进行少量学习来实现。扎哈罗夫等人。 [62] 在大型视频数据集上采用元学习作为预训练,并对经过对抗训练的看不见的人进行少拍或单拍学习。在深度视频肖像 [30] 中,提出了生成对抗网络 (GAN) [22] 来生成逼真的视频,完全控制肖像的头部姿势、面部表情和眼睛注视。金等人。 [29]提出了一种视觉配音方法,可以在说话时保持目标演员的签名风格。这种方法不是直接用源actor的表达式替换目标表达式,而是以循环一致性的无监督方式学习映射[60, 64]。
2.3 音频驱动的面部再现
音频驱动的面部重演的目标是生成与输入音频流同步的逼真视频肖像。钟等人。 [12] 开发了一种技术,可以在音频语音之后为静态图像肖像设置动画。通过编码器网络将图像和音频联合编码到潜在空间中,解码器网络合成说话的头部。编码器和解码器都以无监督的方式进行训练。周等人。 [63] 提出了一种在新的对抗性训练过程中学习解开的视听表示的方法。此方法可以使用音频或视频来驱动目标演员。陈等人。 [11]首先将音频特征转换为面部标志作为中间特征,然后通过注意机制以标志为条件生成语音帧。普拉杰瓦尔等人。 [40] 提出了一种面对面的翻译方法,生成给定演讲片段的任何人的说话面孔。 LipGAN 架构包含一个生成器,用于从源音频和目标帧合成人像视频帧,以及一个鉴别器,用于确定合成的面部图像是否与音频同步。但是,在其结果中可以观察到模糊和抖动,因为无法保证合成内容的时间稳定性。虽然上述四种方法可以将任意音频作为输入,使用单个输入图像重新演绎任意演员,但由于图像质量低,结果不够逼真。 Vougioukas 等。 [54] 提出了一种端到端的方法来使用静止图像和语音音频生成会说话的头部视频。采用具有三个鉴别器的时间 GAN 来实现清晰的帧、视听同步和逼真的表达。 VOCA [15] 是一种基于 12 个扬声器的新 4D 面部数据集,从任意音频中获得逼真 3D 面部动画的技术。
Suwajanakorn 等。 [46] 使用他的音频流合成了美国前总统巴拉克奥巴马的高保真头部谈话视频。循环神经网络 (RNN) 接受了他 14 小时演讲的训练,以根据梅尔频率倒谱系数 (MFCC) 音频特征预测嘴形。使用检索到的候选帧的中间纹理在手动绘制的蒙版内合成逼真的嘴部区域。嘴巴区域序列最终合成在时间扭曲的目标视频背景上。虽然这种方法可以合成准确的口型同步视频,但它需要特定目标身份的 14 小时语音视频来训练网络,并且不能推广到其他身份。余等人。 [61] 提出了一种从文本和/或音频输入生成谈话头部视频的方法。引入了光流和自注意力来分别对时间和空间依赖性进行建模。然而,像 Suwajanakorn 等人一样。 [46],他们的方法只在美国总统唐纳德特朗普和巴拉克奥巴马身上得到了证明,并没有推广到他们之外。
我们注意到一些与我们相关的并发工作。与我们的工作类似,Neural Voice Puppetry [50] 提出了一个音频到表达网络,该网络在大量电视广播语料库上训练。下脸使用延迟神经渲染的音频预测表达重新渲染[51]。为了填补下巴和颈部之间的空隙,还使用了一个额外的独立修复网络。相比之下,我们使用由面部表情参数控制的简单蒙版扩展过程来解决这个问题,因此计算效率更高。宋等人。 [45] 提出了一个 ID 去除网络来预测表达参数,以及一个通用翻译网络,将地标热图转换为任意目标的逼真视频。然而,使用地标热图作为神经人脸渲染器的输入会引入抖动,因为保持地标的时间一致性具有挑战性。最近,Yi 等人。 [59] 提出了一种基于个性化学习的头部姿势生成方法,以提高头部谈话视频的保真度。通过记忆增强型 GAN 训练图像翻译网络所需的数据更少(约 10 秒)。然而,由于他们的人脸重建中的错误,重建的人脸序列不稳定,这会损害 GAN 的收敛性。在口腔中也可以看到明显的伪影,这会降低保真度和用户体验。
2.4 深度生成模型和神经渲染
最近,已经提出 GAN 用于从噪声合成图像。这种方法可以通过条件输入设置 [35] 进行扩展,它通常用于弥合两个不同但相关的域之间的差距。 pix2pix 图像到图像的转换方法 [27] 被广泛认为是基于条件 GAN 的图像合成的一种基准方法。这种范式可以扩展到视频到视频的转换,以合成具有时间一致性的视频帧。王等人。 [57] 提出了一种使用循环网络以从粗到细的方式生成高分辨率和时间平滑视频的方法。 Recycle-GAN 方法 [2] 可以实现对相干视频到视频翻译的非配对学习。少镜头视频到视频翻译 [56] 学习通过一种新颖的网络权重生成模块来合成看不见的主题的视频。视频到视频的翻译在许多应用中都显示出令人印象深刻的结果,尤其是面部重演、视觉配音 [18, 29, 30] 甚至全身重演 [10, 33]。
如今,许多方法将神经网络的强大功能与使用神经渲染的传统渲染结合起来 [48]。神经纹理 [51] 是一种新颖的可学习组件,它模仿了传统图形管道中使用的纹理贴图。它们在新视图合成、场景编辑和动画合成的应用中显示出令人信服的结果。 Meshry 等人。 [34] 训练了一个神经重新渲染网络,该网络采用由深度、颜色和语义标签组成的深度帧缓冲区作为输入,并在多个外观下输出逼真的场景渲染。蒂斯等人。提出了一种基于学习的图像引导渲染技术 [53],它结合了基于图像的渲染和基于 GAN 的图像合成。这种方法可以为虚拟和增强现实应用(例如虚拟游览、陈列室和观光)生成重建对象的逼真重新渲染。在我们的方法中,使用神经面部渲染器将下面部的粗略渲染转换为逼真的图像。
- 音频驱动的视频肖像生成
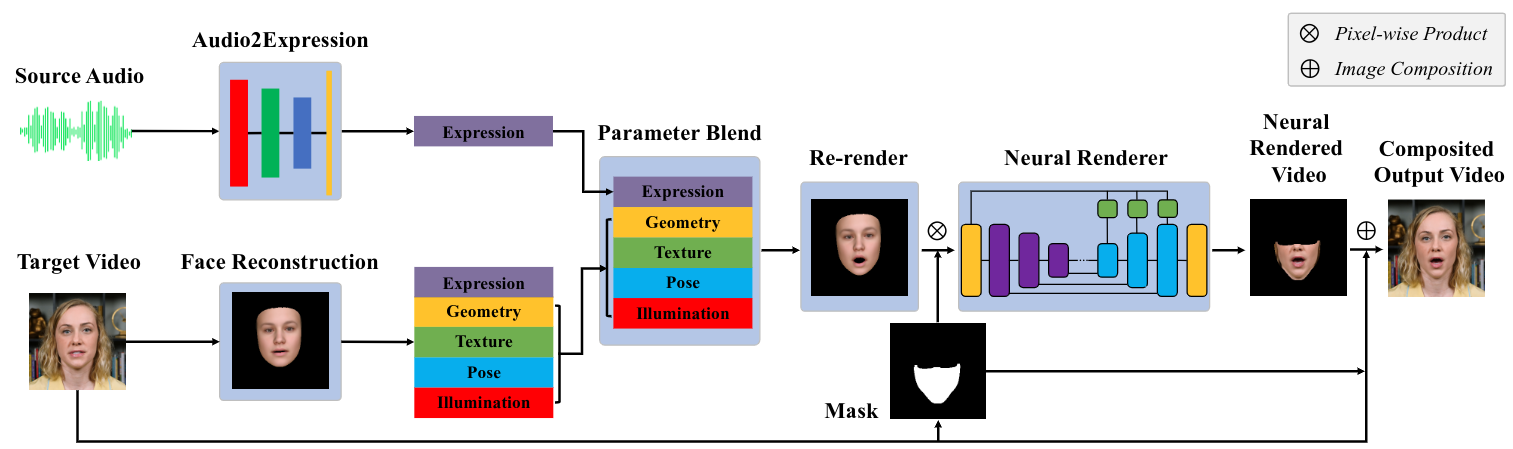
图 2. 我们方法的流水线。从左到右:首先,我们通过单目人脸重建(第 3.1 节)估计目标视频肖像的 3D 人脸模型的参数,并从源语音音频(第 3.2 节)计算面部表情参数。接下来,我们通过将从源音频预测的面部表情参数与来自目标视频的其他参数混合来创建新面部,并重新渲染新面部模型的合成图像。最后,我们使用神经人脸渲染器从合成图像生成逼真渲染,并将结果合成在动态视频背景之上(第 3.3 节)。
给定源语音音频,我们的方法旨在为给定的目标视频生成逼真的视频肖像。为了实现这一目标,我们采用了 3D 面部装备来弥合原始输入音频和逼真的输出视频模式之间的差距。该中间模型避免了对音频和视觉信号之间虚假相关性的过度拟合。我们方法的流程由三个主要组件组成,如图 2 所示:单目 3D 面部重建、音频到面部表情映射(’Audio2Expression’)和神经面部渲染。给定目标视频 V t V_t V t ,我们首先重建一个参数化 3D 人脸模型,其中包含每一帧的表情、几何、纹理、姿势和光照参数(第 3.1 节)。从同一个视频中,我们学习了从音频特征到相同参数 3D 面部模型的面部表情参数的映射(第 3.2 节);这种映射可以将语音音频(甚至来自其他人)转换为目标演员的表情参数。对于源音轨 A s A_s A s ,我们的方法从音频中预测表情参数,将预测的表情参数与从目标视频重建的面部模型混合,并重新渲染目标演员的音频驱动面部图像。可以看出,这些重新渲染的图像不是逼真的。为了解决这个问题,我们训练了一个神经面部渲染器,将渲染的下部面部区域转换为真实感的区域,这些区域被合成到原始目标视频帧中作为最终结果(第 3.3 节)。
; 3.1 单目3D人脸重建
对于 M M M 帧的目标视频 V t = { I 1 , … , I M } \mathcal{V}{t}=\left{I{1}, \ldots, I_{M}\right}V t ={I 1 ,…,I M } ,我们首先在所有帧中跟踪人脸并注册一个3D人脸模型。让 { X 1 , … , X M } \left{\mathcal{X}{1}, \ldots, \mathcal{X}{M}\right}{X 1 ,…,X M } 表示完整描述目标视频 V t \mathcal{V}_{t}V t 的面部表现的面部模型参数序列。我们遵循 Deng 等人的基于单图像的方法。 [16] 并将其应用于基于视频的 3D 人脸重建。在本节中,我们首先简要介绍我们使用的参数化人脸模型。然后,我们描述了将 3D 人脸模型转换为 2D 图像的图像形成过程。最后,我们讨论用于面部模型拟合的能量项。
3.1.1 参数人脸模型
我们使用 3D 可变形模型 (3DMM) 来表示人脸 [4, 17]。 3DMM 由一个具有 N v N_{v}N v 个顶点的模板三角形网格和一个仿射模型组成,该模型定义了面部几何形状 v ∈ R 3 N v v \in \mathbb{R}^{3 N_{v}}v ∈R 3 N v (顶点的堆叠 3D 位置)和堆叠的每顶点漫反射
r ∈ R 3 N v r \in \mathbb{R}^{3 N_{v}}r ∈R 3 N v ,{ α k } \left{\alpha_{k}\right}{αk } 对于几何,{ δ k } \left{\delta_{k}\right}{δk } 对于表达式, { β k } \left{\beta_{k}\right}{βk } 对于反射(颜色):
v ( α , δ ) = a g e o + ∑ k = 1 N α α k b k g e o + ∑ k = 1 N δ δ k b k e x p r ( β ) = a r e f + ∑ k = 1 N β β k b k r e f \begin{gathered} v(\alpha, \delta)=a_{\mathrm{geo}}+\sum_{k=1}^{N_{\alpha}} \alpha_{k} b_{k}^{\mathrm{geo}}+\sum_{k=1}^{N_{\delta}} \delta_{k} b_{k}^{\mathrm{exp}} \ r(\beta)=a_{\mathrm{ref}}+\sum_{k=1}^{N_{\beta}} \beta_{k} b_{k}^{\mathrm{ref}} \end{gathered}v (α,δ)=a g e o +k =1 ∑N ααk b k g e o +k =1 ∑N δδk b k e x p r (β)=a r e f +k =1 ∑N ββk b k r e f
这里向量 a geo , a ref ∈ R 3 N v a_{\text {geo }}, a_{\text {ref }} \in \mathbb{R}^{3 N_{v}}a geo ,a ref ∈R 3 N v 分别表示平均脸的面部几何和反射率, { b k geo } k = 1 N α \left{b_{k}^{\text {geo }}\right}{k=1}^{N{\alpha}}{b k geo }k =1 N α 是几何基, { b k exp } k − 1 N δ \left{b_{k}^{\exp }\right}{k-1}^{N{\delta}}{b k exp }k −1 N δ 是表情基, and { b k r e f } k − 1 N β \left{b_{k}^{\mathrm{ref}}\right}{k-1}^{N{\beta}}{b k r e f }k −1 N β 是反射率基,所有这些都使用主成分分析 (PCA) 从面部扫描数据计算得出。我们采用 2009 年巴塞尔人脸模型 [39] 用于面部几何形状 ( a geo , b geo ) \left(a_{\text {geo }}, b^{\text {geo }}\right)(a geo ,b geo ) 和反射率 ( a ref , b ref ) \left(a_{\text {ref }}, b^{\text {ref }}\right)(a ref ,b ref ),并使用来自 Guo 等人的粗到细学习框架的面部表情 b exp b^{\exp }b exp 对其进行扩充 [ 23],它建立在 FaceWarehouse [7] 之上。我们使用 N α = 80 N_{\alpha}=80 N α=8 0, N δ = 64 N_{\delta}=64 N δ=6 4 及 N β = 80 N_{\beta}=80 N β=8 0。刚性头部姿势由旋转 R ∈ S O ( 3 ) R \in \mathrm{SO}(3)R ∈S O (3 ) 和平移 T ∈ R 3 T \in \mathbb{R}^{3}T ∈R 3 表示。
3.1.2 图像形成过程
为了将 3D 人脸模型 X \mathcal{X}X 渲染为合成图像 I ^ \hat{I}I ^ ,我们还需要对照明和相机进行建模。我们假设朗伯表面和远处场景照明使用球谐函数 (SH) [41] 来近似环境照明: C ( r i , n i , γ ) = C\left(r_{i}, n_{i}, \gamma\right)=C (r i ,n i ,γ)= r i ⊙ ∑ b = 1 B 2 γ b Y b ( n i ) r_{i} \odot \sum_{b=1}^{B^{2}} \gamma_{b} Y_{b}\left(n_{i}\right)r i ⊙∑b =1 B 2 γb Y b (n i ) ,其中 B B B 是数字在 SH 波段中,γ b ∈ R 3 \gamma_{b} \in \mathbb{R}^{3}γb ∈R 3 是 RGB SH 系数, Y b : R 3 → R Y_{b}: \mathbb{R}^{3} \rightarrow \mathbb{R}Y b :R 3 →R 是SH 基函数, r i r_{i}r i 和 n i n_{i}n i 分别是顶点 i 的反射率和单位法向量,’⊙ \odot ⊙’ 是元素乘积。我们选择 B = 3 B=3 B =3 个 S H \mathrm{SH}S H 波段, B 2 = 9 B^{2}=9 B 2 =9 个系数向量,导致 SH 照明系数γ ∈ R 27 \gamma \in \mathbb{R}^{27}γ∈R 2 7。我们完整的人脸模型可以用向量 X = ( α , δ , β , γ , R , T ) ∈ R 257 \mathcal{X}=(\alpha, \delta, \beta, \gamma, R, T) \in \mathbb{R}^{257}X =(α,δ,β,γ,R ,T )∈R 2 5 7 表示。
我们将虚拟相机建模为具有透视投影 Π : R 3 → R 2 \Pi: \mathbb{R}^{3} \rightarrow \mathbb{R}^{2}Π:R 3 →R 2 的针孔相机,它将 3D 点从相机空间映射到 2D 图像空间。对于模型 X \mathcal{X}X 的顶点 v i ∈ v ( α , δ ) v_{i} \in v(\alpha, \delta)v i ∈v (α,δ),我们使用上述照明和相机模型计算其图像空间坐标 u i ( X ) u_{i}(\mathcal{X})u i (X ) 和相应的颜色 c i ( X ) c_{i}(\mathcal{X})c i (X ) 。最后,{ u i ( X ) } i = 1 N v \left{u_{i}(\mathcal{X})\right}{i=1}^{N{v}}{u i (X )}i =1 N v 和 { c i ( X ) } i = 1 N v \left{c_{i}(\mathcal{X})\right}{i=1}^{N{v}}{c i (X )}i =1 N v 被送入可微分光栅器以生成渲染合成图像 I ^ ( X , Π ) \hat{I}(\mathcal{X}, \Pi)I ^(X ,Π) 。与 Genova 等人[20]不同,我们的光栅化器是用 CUDA 实现的,以获得 GPU 加速,这可以加速训练和推理。
3.1.3 模型训练
我们使用在VGGFace2[9]上预训练的ResNet-50网络[25]从输入图像 I I I 估计人脸模型参数 X \mathcal{X}X ,因为我们发现它比直接优化在时间上产生更一致的结果。具体而言,我们修改网络的最终完全连接层,使其具有97维(无几何体和反射率;见下文),并采用合成分析方法,最大限度地减少模型合成渲染与输入图像之间的差异。重建损失包括三项:密集光度对齐、稀疏地标对齐和统计正则化。
我们使用在面部区域 M \mathcal{M}M 中的所有像素 i i i上计算的照片一致性损失来测量输入帧 I I I 和从模型 X \mathcal{X}X 渲染的合成图像 I ^ \hat{I}I ^ 之间的光度差异:
L photo ( X ) = 1 ∣ M ∣ ∑ i ∈ M ∥ I ( i ) − I ^ ( i ) ∥ 2 \mathcal{L}{\text {photo }}(\mathcal{X})=\frac{1}{|\mathcal{M}|} \sum{i \in \mathcal{M}}\|I(i)-\hat{I}(i)\|_{2}L photo (X )=∣M ∣1 i ∈M ∑∥I (i )−I ^(i )∥2
我们使用稀疏地标对齐约束来鼓励三维网格上的地标投影到输入图像中相应检测到的二维地标附近。我们使用现成的面对齐网络[5]在每个视频帧中检测 N L = 68 N_{L}=68 N L =6 8 个地标 { s 1 , … , s N L } \left{s_{1}, \ldots, s_{N_{L}}\right}{s 1 ,…,s N L } ,并将稀疏地标对齐损失计算为投影地标 u τ i ( X ) u_{\tau_{i}}(\mathcal{X})u τi (X ) 和检测地标 s i s_{i}s i 之间的加权欧氏距离:
L land ( X ) = 1 N L ∑ i = 1 N L ω i ∥ u τ i ( X ) − s i ∥ 2 \mathcal{L}{\text {land }}(\mathcal{X})=\frac{1}{N{L}} \sum_{i=1}^{N_{L}} \omega_{i}\left\|u_{\tau_{i}}(\mathcal{X})-s_{i}\right\|_{2}L land (X )=N L 1 i =1 ∑N L ωi ∥u τi (X )−s i ∥2
这里, τ i \tau_{i}τi 是与图像空间中的地标 i i i 相对应的三维人脸模型的顶点索引,ω i \omega_{i}ωi 是地标特定权重,对于20个嘴和12个眼睛地标设置为50,否则设置为1。
为了防止人脸形状和反射率的退化,我们进一步在回归的3DMM系数上使用正则化损失 L reg ( X ) \mathcal{L}{\text {reg }}(\mathcal{X})L reg (X ) ,这将在高斯分布下对平均人脸强制一个先验值[16,49]。
总模型拟合损失定义为:
L ( X ) = λ photo L photo ( X ) + λ land L land ( X ) + λ reg L reg ( X ) \mathcal{L}(\mathcal{X})=\lambda{\text {photo }} \mathcal{L}{\text {photo }}(\mathcal{X})+\lambda{\text {land }} \mathcal{L}{\text {land }}(\mathcal{X})+\lambda{\text {reg }} \mathcal{L}_{\text {reg }}(\mathcal{X})L (X )=λphoto L photo (X )+λland L land (X )+λreg L reg (X )
其中,对于所有实验,我们使用 λ photo = 1.9 , λ land = 0.0016 \lambda_{\text {photo }}=1.9, \lambda_{\text {land }}=0.0016 λphoto =1 .9 ,λland =0 .0 0 1 6 和 λ reg = 0.0003 \lambda_{\text {reg }}=0.0003 λreg =0 .0 0 0 3。关于详细的推导,我们参考Genova等人[20]。在将模型拟合到完整的目标视频之前,我们随机选择8帧来回归每个演员的几何和反射参数,并保持它们不变。然后,我们在目标视频上训练我们的人脸重建网络20个时代,批量大小为5,学习率为2 × 1 0 − 5 2 \times 10^{-5}2 ×1 0 −5。虽然本小节提供了面拟合的技术细节,与以前的工作相比,实现方面存在差异,但我们澄清,这不是我们的主要贡献之一。
3.2 音频到面部表情映射
为了仅基于音频流重新生成人脸模型,我们接下来介绍一种面部表情映射方法,该方法从输入音频估计人脸模型的面部表情参数。首先,我们使用AT net[11]从音频中稳健地提取高级特征。AT net最初设计用于从音频流创建里程碑式的动画,并在LRW数据集[13]上进行训练,LRW数据集是一个基于BBC广播的大规模唇读语料库。为了获得高层次的音频特征,我们将输入音频流转换为MFCC特征,然后将MFCC特征馈入AT-net,并将倒数第二层的256-D输出特征作为健壮的高层次特征。我们发现,这些特征有效地独立于任何特定的身份,并包含足够的信息进行表达预测。因此,我们为输入音频的每40毫秒段提取256-D特征向量 F F F(对应于每秒25帧的一个视频帧)。
我们使用均方误差损失优化(MSE) loss L exp \operatorname{loss} L_{\exp }l o s s L exp 训练 H \mathcal{H}H :
L exp = MSE ( H ( F t ) − δ t ) \mathcal{L}{\exp }=\operatorname{MSE}\left(\mathcal{H}\left(\mathbf{F}{t}\right)-\delta_{t}\right)L exp =M S E (H (F t )−δt )
其中 δ t \delta_{t}δt 是重建目标视频 t t t 时刻的表情参数。我们使用Adam[32]对网络进行训练,默认设置为10个时代,批量大小为5。
我们的音频到面部表情映射方法仅在目标视频 V t V_t V t (通常三分钟长)上训练,并且能够将任意人的语音音频转换为目标演员的面部表情参数。
3.3 神经面部渲染器
我们将从源音频 A s A_s A s 估计的表情参数与从目标视频重建的几何、反射和照明相结合,通过图像形成过程重新渲染人脸模型,并获得一系列合成人脸图像。然而,合成图像看起来显然是计算机生成的,而不是照片。为了使合成面更真实和自然,我们使用神经面部渲染器将合成渲染转换为真实照片图像。
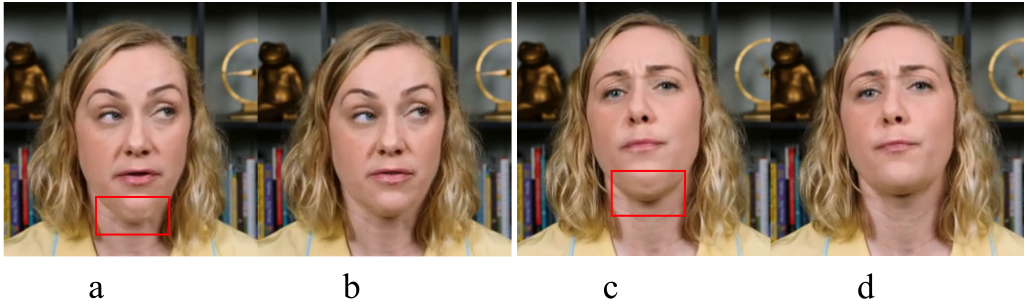
图3。掩模扩展对神经人脸绘制的影响。(a) 和(c):将原始下面罩内的合成面部区域直接合成到目标视频中可能会产生双下巴伪影。(b) 和(d):通过我们的面罩扩展,合成的下脸和部分颈部都被合成到目标视频中,从而避免了下巴区域周围的冲突内容。

图4。下面罩的展开。我们通过将第一个表达式参数的值设置为”-8″来生成一个嘴完全张开(中间)的修改过的面具,这使得下巴覆盖了颈部的一部分。展开的遮罩是两个遮罩的并集。

图5。我们通过将扩展的模板分别应用于每一个目标视频帧和合成视频帧来构建成对的训练语料库。
在将神经人脸渲染应用于合成人脸渲染之前,我们引入了一种遮罩策略,使用覆盖下巴、嘴巴和鼻子部分的预定义遮罩提取下半部人脸区域。我们使用神经人脸渲染器仅预测遮罩内的内容,并将预测内容与目标视频合成以生成最终结果。通过这种遮罩策略,训练的重点是下半脸的嘴巴动画,避免了目标视频的任何动态背景的不稳定性。首先,我们提取一个原始遮罩,如下所示:我们标记所有面顶点,y y y 坐标小于阈值 ξ = 0 \xi=0 ξ=0(假设中的标准化模型空间坐标)[ − 1 , + 1 ] [-1,+1][−1 ,+1 ] ). 我们对蒙面进行光栅化,得到每一帧的二值下蒙面。然而,由于预测的表达参数与目标视频中的原始参数不一致,直接将预测内容合成到目标视频中可能会导致双下巴,如图3所示。受InverseFaceNet[31]的启发,我们通过减小表达式第一个分量的值,显式地扩展了颌骨区域周围的遮罩使嘴完全张开,使下巴覆盖部分颈部。该过程如图4所示。
我们通过将扩展的掩码应用于每个目标视频帧 I I I 和相应的合成图像 I ^ \hat{I}I ^ ,为神经面部渲染器创建成对的训练语料库,如图5所示。为了避免过度标记,让训练语料库 { ( I t , I ^ t ) } t = 1 M \left{\left(I_{t}, \hat{I}{t}\right)\right}{t=1}^{M}{(I t ,I ^t )}t =1 M 表示扩展的下面罩内的图像内容(而不是完整图像)。神经面部渲染器学习将目标角色的合成渲染转换为照片级真实感渲染。根据deep video-portraits[30],我们训练了一个神经面部渲染器,该渲染器由一个基于U网络的生成器 G \mathcal{G}G 和一个鉴别器 D \mathcal{D}D 组成,以对抗的方式交替优化。该发生器包括编码器和解码器。编码器使用卷积层反复对输入张量进行降采样,然后进行批量归一化和leaky RELU。解码器通过使用转置卷积、批量归一化、丢失和ReLU进行上采样,从低维潜在变量表示合成高质量输出。判别器采用Patch-GAN[27]。有关完整的网络架构,请参阅deep video-portraits[30]和我们的源代码。生成器 G \mathcal{G}G 的输入是一个叠加张量 T t = { I ^ t } i = t − N w t + N w \mathbf{T}{t}=\left{\hat{I}{t}\right}{i=t-N w}^{t+N w}T t ={I ^t }i =t −N w t +N w ,其组成与第3.2节相同,以保持时间一致性。鉴别器 D \mathcal{D}D 的输入是 T t \mathbf{T}{t}T t c 与地面真值图像 I t I_{t}I t 或神经渲染图像 G ( T t ) \mathcal{G}\left(\mathbf{T}_{t}\right)G (T t ) 的组合。生成器 G \mathcal{G}G 的最佳网络参数可通过解决以下问题获得:
G ∗ = arg min G max D L ( G , D ) \mathcal{G}^{*}=\arg \min {\mathcal{G}} \max {\mathcal{D}} \mathcal{L}(\mathcal{G}, \mathcal{D})G ∗=ar g G min D max L (G ,D )
完整训练目标包括光度重建损失 L r \mathcal{L}{r}L r 和对抗损失 L a d v \mathcal{L}{\mathrm{adv}}L a d v ,加权 λ = 100 \lambda=100 λ=1 0 0。
L ( G , D ) = L r e c ( G ) + λ L a d v ( G , D ) \mathcal{L}(\mathcal{G}, \mathcal{D})=\mathcal{L}{\mathrm{rec}}(\mathcal{G})+\lambda \mathcal{L}{\mathrm{adv}}(\mathcal{G}, \mathcal{D})L (G ,D )=L r e c (G )+λL a d v (G ,D )
光度重建损失 L rec \mathcal{L}{\text {rec }}L rec 鼓励合成输出的锐度,可表示为:
L r e c ( G ) = ∥ I t − G ( T t ) ∥ 1 \mathcal{L}{\mathrm{rec}}(\mathcal{G})=\left\|I_{t}-\mathcal{G}\left(\mathbf{T}{t}\right)\right\|{1}L r e c (G )=∥I t −G (T t )∥1
对抗性损失为:
L a d v ( G , D ) = log D ( I t ) + log ( 1 − D ( G ( T t ) ) \mathcal{L}{\mathrm{adv}}(\mathcal{G}, \mathcal{D})=\log \mathcal{D}\left(I{t}\right)+\log \left(1-\mathcal{D}\left(\mathcal{G}\left(\mathbf{T}_{t}\right)\right)\right.L a d v (G ,D )=lo g D (I t )+lo g (1 −D (G (T t ))
我们使用带有默认设置的Adam优化器对网络进行训练[32]。我们从零开始训练我们的网络,权重按照正态分布 N ( 0 , 0.0 2 2 ) \mathcal{N}\left(0,0.02^{2}\right)N (0 ,0 .0 2 2 ) 初始化。培训过程需要250个阶段,批量大小为16,学习率为 0.0002 0.0002 0 .0 0 0 2。
在推理中,我们使用高斯平滑掩模来合成神经人脸渲染器的输出与目标帧的背景,如图2所示。
[En]
In reasoning, we use a Gaussian smooth mask to synthesize the output of the neural face renderer with the background of the target frame, as shown in figure 2.
; 4. 实验
我们通过执行定性和定量评估来演示我们的音频驱动的视频人像生成方法。我们鼓励读者观看我们的补充视频,了解实际效果。
[En]
We demonstrate our audio-driven video portrait generation method by performing qualitative and quantitative assessments. We encourage readers to watch our supplementary videos to learn about the actual results.
数据集。我们在从YouTube和之前的工作中收集的11个目标视频集上测试我们的方法[29]。表2提供了这些视频的摘要,包括它们的长度和语言。视频剪辑的平均长度为3分钟。在预处理中,我们使用检测到的地标对齐所有视频帧,以确保上半身占据图像的主要空间。对齐的帧被进一步裁剪并调整为256×256像素。
实施细节。所有网络均在PyTorch中实现[38]。我们使用CUDA加速实现光栅化器[20],并将其集成到Pytorch中。所有实验都是在一台配有3.6 GHz CPU、32 GB RAM和NVIDIA GeForce RTX 2080 Ti GPU的计算机上进行的。运行时性能。对于3分钟的目标视频肖像,重建人脸模型大约需要30分钟,训练Audio2Expression模块需要20秒,训练神经人脸渲染器需要6.5小时。在在线测试阶段,从音频预测表达参数需要2毫秒,重新渲染人脸模型需要3毫秒,执行神经人脸渲染需要13毫秒,将神经人脸渲染区域合成到目标帧需要2毫秒。总之,从音频生成一帧视频肖像需要20 ms,这对于实时应用(50 Hz)来说足够了。
- 讨论
在这项工作中,我们展示了各种序列的真实感音频驱动视频肖像效果。虽然在VR和AR中广泛使用的虚拟人和化身可能具有有限的逼真性、身份保存和音频表达同步,但我们的音频驱动视频肖像具有照片真实感,与音频同步,并保持目标演员的身份。我们的方法通过使用新的语音音频重新再现现有视频,朝着简化真实感虚拟化身创建和动画迈出了一步。这在网络带宽受限或VR应用中可能无法使用视频捕获设备时尤其有用。然而,我们的方法有一些局限性,可以在未来的研究中加以解决。
我们的方法需要一个大约3分钟的纵向视频作为训练数据,为每个目标发生器生成视觉上合理的结果。这是因为我们的管道包括一个人特定的神经面部渲染器,需要为每个目标提供足够的训练数据。在未来的日常应用中,最短30秒的自拍视频是可取的。这引入了一个有趣的未来工作,它可以大量减少训练渲染器所需的数据,可能使用元学习[56]。

图13。失败案例。伪影可能是由(a)不协调的口腔运动和头部姿势,或(b)目标夸张的面部表情引起的。
在我们的神经面部渲染器中,只有较低的面部区域被重新渲染并集成到目标视频的原始面部,当原始头部姿势和源音频不兼容时,这可能会导致不自然的伪影。例如,图13(a)显示了闭着嘴的非自然移动头部姿势的框架。动态时间扭曲[46]可以改善这一点,它从目标视频中检索帧以更好地对齐口腔运动。此外,全帧视频合成以及音频驱动的头部姿势预测是未来有趣的研究方向。此外,当预测的表达式参数被夸大时,我们的神经面部渲染器可能会失败并产生伪影,见图13(b)。
; 6. 结论
我们提出了一种新的实时方法,用于从输入音频和目标视频合成逼真的视频肖像。我们提出了一个Audio2Expression网络,用于从任何语音音频预测目标演员的面部表情参数。通过混合预测的面部表情参数和从目标视频重建的三维面部参数,合成面部图像与音频同步渲染。最后,我们训练了一个神经人脸渲染器,该渲染器具有优雅的遮罩扩展策略,可将合成渲染转换为照片级真实感视频肖像。
定性和定量评估表明,我们的方法超越了以前的通用音频驱动视频肖像方法,但Audio2Obama[46]除外,这是一种专门定制的方法,仅适用于从同一参与者处采集的广泛、一致的音频和视频。用户研究证实,我们的结果令人信服,通常比其他通用音频驱动方法更受欢迎。
我们提出的方法为几种VR/AR应用提供了好处,包括真实感虚拟新闻主播、虚拟教育和培训。它还支持多种应用,如在线数字语音助理增强和视频会议,尤其是在网络带宽有限的情况下。我们相信,我们的方法朝着解决这一挑战性任务迈出了重要的一步,它有可能与更多的VR/AR应用相结合。
- 参考资料
[1] H. Averbuch-Elor, D. Cohen-Or, J. Kopf, and M. F. Cohen. Bringingportraits to life. ACM Trans. Graph., 36(6):196:1–13, 2017. doi: 10.1145/3130800.3130818
[2] A. Bansal, S. Ma, D. Ramanan, and Y. Sheikh. Recycle-GAN: Unsuper-vised video retargeting. In ECCV, 2018. doi: 10.1007/978-3-030-01228-1_8
[3] F. Berthouzoz, W. Li, and M. Agrawala. Tools for placing cuts andtransitions in interview video. ACM Trans. Graph., 31(4), 2012.
[4] V. Blanz and T. Vetter. A morphable model for the synthesis of 3D faces.In SIGGRAPH, pp. 187–194, 1999. doi: 10.1145/311535.311556
[5] A. Bulat and G. Tzimiropoulos. How far are we from solving the 2D & 3Dface alignment problem? (and a dataset of 230,000 3D facial landmarks).In ICCV, 2017. doi: 10.1109/ICCV.2017.116
[6] C. Cao, D. Bradley, K. Zhou, and T. Beeler. Real-time high-fidelity facialperformance capture. ACM Trans. Graph., 34(4):46:1–9, 2015. doi: 10.1145/2766943
[7] C. Cao, Y. Weng, S. Zhou, Y. Tong, and K. Zhou. FaceWarehouse: A3D facial expression database for visual computing. IEEE Transactionson Visualization and Computer Graphics, 20(3):413–425, 2014. doi: 10.1109/TVCG.2013.249
[8] H. Cao, D. G. Cooper, M. K. Keutmann, R. C. Gur, A. Nenkova, andR. Verma. CREMA-D: Crowd-sourced emotional multimodal actorsdataset. IEEE Transactions on Affective Computing, 5(4):377–390, 2014.doi: 10.1109/TAFFC.2014.2336244
[9] Q. Cao, L. Shen, W. Xie, O. M. Parkhi, and A. Zisserman. VGGFace2:A dataset for recognising faces across pose and age. In Face & Gesture,2018. doi: 10.1109/FG.2018.00020
[10] C. Chan, S. Ginosar, T. Zhou, and A. A. Efros. Everybody dance now. InICCV, pp. 5933–5942, 2019. doi: 10.1109/ICCV.2019.00603
[11] L. Chen, R. K. Maddox, Z. Duan, and C. Xu. Hierarchical cross-modaltalking face generation with dynamic pixel-wise loss. In CVPR, pp. 7824–7833, 2019. doi: 10.1109/CVPR.2019.00802
[12] J. S. Chung, A. Jamaludin, and A. Zisserman. You said that? In BMVC,2017.
[13] J. S. Chung and A. Zisserman. Lip reading in the wild. In ACCV, 2016.
[14] M. Cooke, J. Barker, S. Cunningham, and X. Shao. An audio-visual corpusfor speech perception and automatic speech recognition. The Journal of theAcoustical Society of America, 120(5):2421–2424, 2006. doi: 10.1121/1.2229005
[15] D. Cudeiro, T. Bolkart, C. Laidlaw, A. Ranjan, and M. J. Black. Capture,learning, and synthesis of 3D speaking styles. In CVPR, 2019. doi: 10.1109/CVPR.2019.01034
[16] Y. Deng, J. Yang, S. Xu, D. Chen, Y. Jia, and X. Tong. Accurate 3D facereconstruction with weakly-supervised learning: From single image toimage set. In CVPR Workshops, 2019. doi: 10.1109/CVPRW.2019.00038
[17] B. Egger, W. A. P. Smith, A. Tewari, S. Wuhrer, M. Zollhoefer, T. Beeler,F. Bernard, T. Bolkart, A. Kortylewski, S. Romdhani, C. Theobalt, V. Blanz,and T. Vetter. 3D morphable face models—Past, present, and future. ACMTrans. Graph., 39(5):157:1–38, 2020. doi: 10.1145/3395208
[18] O. Fried, A. Tewari, M. Zollhöfer, A. Finkelstein, E. Shechtman, D. B.Goldman, K. Genova, Z. Jin, C. Theobalt, and M. Agrawala. Text-basedediting of talking-head video. ACM Trans. Graph., 38(4):68:1–14, 2019.doi: 10.1145/3306346.3323028
[19] P. Garrido, M. Zollhöfer, D. Casas, L. Valgaerts, K. Varanasi, P. Pérez, andC. Theobalt. Reconstruction of personalized 3D face rigs from monocularvideo. ACM Trans. Graph., 35(3):28:1–15, 2016. doi: 10.1145/2890493
[20] K. Genova, F. Cole, A. Maschinot, A. Sarna, D. Vlasic, and W. T. Freeman.Unsupervised training for 3D morphable model regression. In CVPR, pp.8377–8386, 2018. doi: 10.1109/CVPR.2018.00874
[21] M. Gonzalez-Franco, A. Steed, S. Hoogendyk, and E. Ofek. Using facialanimation to increase the enfacement illusion and avatar self-identification.IEEE Transactions on Visualization and Computer Graphics, 26(5):2023–2029, 2020. doi: 10.1109/TVCG.2020.2973075
[22] I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley,S. Ozair, A. Courville, and Y. Bengio. Generative adversarial nets. InNIPS, 2014.
[23] Y. Guo, J. Zhang, J. Cai, B. Jiang, and J. Zheng. CNN-based real-timedense face reconstruction with inverse-rendered photo-realistic face im-ages. IEEE Transactions on Pattern Analysis and Machine Intelligence,41(6):1294–1307, 2019. doi: 10.1109/TPAMI.2018.2837742
[24] N. Harte and E. Gillen. TCD-TIMIT: An audio-visual corpus of continuousspeech. IEEE Transactions on Multimedia, 17(5):603–615, 2015. doi: 10.1109/TMM.2015.2407694
[25] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for imagerecognition. In CVPR, pp. 770–778, 2016. doi: 10.1109/CVPR.2016.90
[26] C. Heeter. Being there: The subjective experience of presence. Presence:Teleoperators & Virtual Environments, 1(2):262–271, 1992.
[27] P. Isola, J.-Y. Zhu, T. Zhou, and A. A. Efros. Image-to-image translationwith conditional adversarial networks. In CVPR, pp. 5967–5976, 2017.doi: 10.1109/CVPR.2017.632
[28] T. Karras, T. Aila, S. Laine, A. Herva, and J. Lehtinen. Audio-driven facialanimation by joint end-to-end learning of pose and emotion. ACM Trans.Graph., 36(4):94:1–12, 2017. doi: 10.1145/3072959.3073658
[29] H. Kim, M. Elgharib, M. Zollhöfer, H.-P. Seidel, T. Beeler, C. Richardt,and C. Theobalt. Neural style-preserving visual dubbing. ACM Trans.Graph., 38(6):178:1–13, 2019. doi: 10.1145/3355089.3356500
[30] H. Kim, P. Garrido, A. Tewari, W. Xu, J. Thies, M. Nießner, P. Pérez,C. Richardt, M. Zollhöfer, and C. Theobalt. Deep video portraits. ACMTrans. Graph., 37(4):163:1–14, 2018. doi: 10.1145/3197517.3201283
[31] H. Kim, M. Zollhöfer, A. Tewari, J. Thies, C. Richardt, and C. Theobalt.InverseFaceNet: Deep monocular inverse face rendering. In CVPR, pp.4625–4634, 2018. doi: 10.1109/CVPR.2018.00486
[32] D. P. Kingma and J. Ba. Adam: A method for stochastic optimization. InICLR, 2015.
[33] L. Liu, W. Xu, M. Zollhöfer, H. Kim, F. Bernard, M. Habermann, W. Wang,and C. Theobalt. Neural animation and reenactment of human actor videos.ACM Trans. Graph., 38(5):139:1–14, 2019. doi: 10.1145/3333002
[34] M. Meshry, D. B. Goldman, S. Khamis, H. Hoppe, R. Pandey, N. Snavely,and R. Martin-Brualla. Neural rerendering in the wild. In CVPR, 2019.doi: 10.1109/CVPR.2019.00704
[35] M. Mirza and S. Osindero. Conditional generative adversarial nets.arXiv:1411.1784, 2014.
[36] M. Murcia-López, T. Collingwoode-Williams, W. Steptoe, R. Schwartz,T. J. Loving, and M. Slater. Evaluating virtual reality experiences throughparticipant choices. In IEEE VR, pp. 747–755, 2020. doi: 10.1109/VR46266.2020.00098
[37] A. v. d. Oord, S. Dieleman, H. Zen, K. Simonyan, O. Vinyals, A. Graves,N. Kalchbrenner, A. Senior, and K. Kavukcuoglu. WaveNet: A generativemodel for raw audio. arXiv:1609.03499, 2016.
[38] A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen,Z. Lin, N. Gimelshein, L. Antiga, A. Desmaison, A. Kopf, E. Yang, Z. De-Vito, M. Raison, A. Tejani, S. Chilamkurthy, B. Steiner, L. Fang, J. Bai,and S. Chintala. PyTorch: An imperative style, high-performance deeplearning library. In NeurIPS, pp. 8024–8035, 2019.
[39] P. Paysan, R. Knothe, B. Amberg, S. Romdhani, and T. Vetter. A 3D facemodel for pose and illumination invariant face recognition. In InternationalConference on Advanced Video and Signal based Surveillance, pp. 296–301, 2009.
[40] K. R. Prajwal, R. Mukhopadhyay, J. Philip, A. Jha, V. Namboodiri, andC. V. Jawahar. Towards automatic face-to-face translation. In Proceedingsof the International Conference on Multimedia, pp. 1428–1436, 2019. doi:10.1145/3343031.3351066
[41] R. Ramamoorthi and P. Hanrahan. An efficient representation for irra-diance environment maps. In SIGGRAPH, pp. 497–500, 2001. doi: 10.1145/383259.383317
[42] E. Richardson, M. Sela, R. Or-El, and R. Kimmel. Learning detailed facereconstruction from a single image. In CVPR, pp. 5553–5562, 2017. doi:10.1109/CVPR.2017.589
[43] J. Roth, Y. T. Tong, and X. Liu. Adaptive 3D face reconstruction fromunconstrained photo collections. IEEE Transactions on Pattern Analysisand Machine Intelligence, 39(11):2127–2141, 2017. doi: 10.1109/TPAMI.2016.2636829
[44] F. Shi, H.-T. Wu, X. Tong, and J. Chai. Automatic acquisition of high-fidelity facial performances using monocular videos. ACM Trans. Graph.,33(6):222:1–13, 2014. doi: 10.1145/2661229.2661290
[45] L. Song, W. Wu, C. Qian, R. He, and C. C. Loy. Everybody’s talkin’: Letme talk as you want. arXiv:2001.05201, 2020.
[46] S. Suwajanakorn, S. M. Seitz, and I. Kemelmacher-Shlizerman. Syn-thesizing Obama: Learning lip sync from audio. ACM Trans. Graph.,36(4):95:1–13, 2017. doi: 10.1145/3072959.3073640
[47] S. Taylor, T. Kim, Y. Yue, M. Mahler, J. Krahe, A. G. Rodriguez, J. Hod-gins, and I. Matthews. A deep learning approach for generalized speechanimation. ACM Trans. on Graph., 36(4), July 2017. doi: 10.1145/3072959.3073699
[48] A. Tewari, O. Fried, J. Thies, V. Sitzmann, S. Lombardi, K. Sunkavalli,R. Martin-Brualla, T. Simon, J. Saragih, M. Nießner, R. Pandey, S. Fanello,G. Wetzstein, J.-Y. Zhu, C. Theobalt, M. Agrawala, E. Shechtman, D. B.Goldman, and M. Zollhöfer. State of the art on neural rendering. Comput.Graph. Forum, 39(2):701–727, 2020. doi: 10.1111/cgf.14022
[49] A. Tewari, M. Zollhöfer, F. Bernard, P. Garrido, H. Kim, P. Pérez, andC. Theobalt. High-fidelity monocular face reconstruction based on anunsupervised model-based face autoencoder. IEEE Transactions on Pat-tern Analysis and Machine Intelligence, 42(2):357–370, 2020. doi: 10.1109/TPAMI.2018.2876842
[50] J. Thies, M. Elgharib, A. Tewari, C. Theobalt, and M. Nießner. Neuralvoice puppetry: Audio-driven facial reenactment. In ECCV, 2020.
[51] J. Thies, M. Zollhöfer, and M. Nießner. Deferred neural rendering: Imagesynthesis using neural textures. ACM Trans. Graph., 38(4):66:1–12, 2019.doi: 10.1145/3306346.3323035
[52] J. Thies, M. Zollhöfer, M. Stamminger, C. Theobalt, and M. Nießner.Face2Face: Real-time face capture and reenactment of RGB videos. Com-munications of the ACM, 62(1):96–104, 2018. doi: 10.1145/3292039
[53] J. Thies, M. Zollhöfer, C. Theobalt, M. Stamminger, and M. Nießner.Image-guided neural object rendering. In ICLR, 2020.
[54] K. Vougioukas, S. Petridis, and M. Pantic. Realistic speech-driven facialanimation with GANs. IJCV, 128:1398–1413, 2020. doi: 10.1007/s11263-019-01251-8
[55] M. Wang, X.-Q. Lyu, Y.-J. Li, and F.-L. Zhang. VR content creation andexploration with deep learning: A survey. Computational Visual Media,6:3–28, 2020. doi: 10.1007/s41095-020-0162-z
[56] T.-C. Wang, M.-Y. Liu, A. Tao, G. Liu, J. Kautz, and B. Catanzaro. Few-shot video-to-video synthesis. In NeurIPS, 2019.
[57] T.-C. Wang, M.-Y. Liu, J.-Y. Zhu, G. Liu, A. Tao, J. Kautz, and B. Catan-zaro. Video-to-video synthesis. In NeurIPS, 2018.
[58] Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli. Image qualityassessment: from error visibility to structural similarity. IEEE Transac-tions on Image Processing, 13(4):600–612, 2004. doi: 10.1109/TIP.2003.819861
[59] R. Yi, Z. Ye, J. Zhang, H. Bao, and Y.-J. Liu. Audio-driven talk-ing face video generation with learning-based personalized head pose.arXiv:2002.10137, 2020.
[60] Z. Yi, H. Zhang, P. Tan, and M. Gong. DualGAN: Unsupervised duallearning for image-to-image translation. In ICCV, pp. 2868–2876, 2017.doi: 10.1109/ICCV.2017.310
[61] L. Yu, J. Yu, M. Li, and Q. Ling. Multimodal inputs driven talkingface generation with spatial-temporal dependency. IEEE Transactions onCircuits and Systems for Video Technology, 2020. doi: 10.1109/TCSVT.2020.2973374
[62] E. Zakharov, A. Shysheya, E. Burkov, and V. Lempitsky. Few-shot adver-sarial learning of realistic neural talking head models. In ICCV, 2019. doi:10.1109/ICCV.2019.00955
[63] H. Zhou, Y. Liu, Z. Liu, P. Luo, and X. Wang. Talking face generationby adversarially disentangled audio-visual representation. In AAAI, 2019.doi: 10.1609/aaai.v33i01.33019299
[64] J.-Y. Zhu, T. Park, P. Isola, and A. A. Efros. Unpaired image-to-imagetranslation using cycle-consistent adversarial networks. In ICCV, pp.2242–2251, 2017. doi: 10.1109/ICCV.2017.244
[65] M. Zollhöfer, J. Thies, P. Garrido, D. Bradley, T. Beeler, P. Pérez, M. Stamminger, M. Nießner, and C. Theobalt. State of the art on monocular 3D face reconstruction, tracking, and applications. Comput. Graph. Forum,37(2):523–550, 2018. doi: 10.1111/cgf.13382
Original: https://blog.csdn.net/weixin_41967328/article/details/121364378
Author: 胖胖腐乳
Title: Photorealistic Audio-driven Video Portraits (译文)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/512179/
转载文章受原作者版权保护。转载请注明原作者出处!