

前言
今天,由于工作需要,小松研究了斯皮策的一个语音识别模型,这是以前没有人碰过的,主要看了语音唤醒的内容。
[En]
Today, due to the need of his work, Komatsu studied a speech recognition model of Spitzer, which has not been touched before, and mainly looked at the content of voice awakening.
本地语音唤醒,在做完配置后,只需要实现唤醒回调接口,实例化唤醒引擎,这个 唤醒引擎我理解为启动唤醒功能的容器,你可以实现很多接口,比如唤醒引擎检测到说话声,会有对应的回调方法,开发人员可以实现这些回调方法,自定义自己的app的效果
部分回调方法会带来约定好的返回值,比如检测到声音变化或者错误码等等,下图表示整个流程,蓝框外面为应用开发来做,框里面除了实现接口回调,其他的都是sdk的工作
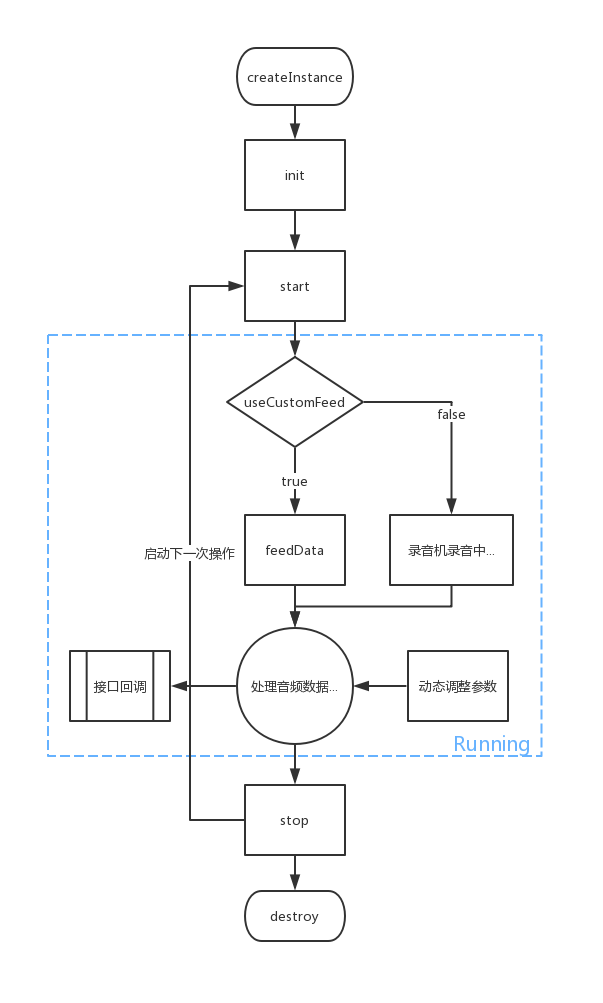

话说这个项目文档真的拉胯,在sdk文档里面,本地语音识别,实时短语音识别和本地语音唤醒都是同样的内容,改了点边边角角都当三个item了,甚至接口文档直接拿jdk的来当……

当然做为开发工程师,我们不能满足于调包,调参,上图中蓝色框内的部分就是sdk做的事情,我们希望能深入理解,语音是一个比较大的模块,本文仅讨论其中的 唤醒识别,由于小松水平有限,若有错误,恳请指正
; 唤醒识别
大家都知道,语音识别现在已经普遍采用了深度学习中的神经网络,而唤醒识别,是语音识别的第一步,类似于tcp链接的第一次握手,相比普通的语音识别,需要做更多的工作,主要是 语音活动端点检测(VAD) 和 唤醒词识别技术
VAD
现在你手上有一个iphone,你只需要说:”嘿 siri”,siri就会回答你,类似的,小度,小爱,小冰都是一样的,那么,就这一句话,你是否想过,发生了什么事情呢?
- 特征提取,从原始音频中提取时域或频域的特征,类似于无论你在微信上给某人发什么消息,在计算机眼中,它都会被转换成二进制。声音的特征非常丰富,如能量、熵、基频等。
[En]
feature extraction, extracting features in time domain or frequency domain from the original audio, similar to the fact that no matter what message you send to someone on Wechat, in the eyes of the computer, it will be converted to binary. The features of the sound are very rich, such as energy, entropy, fundamental frequency, etc.*
- 初步决定:这里是分析中心,每个输入的音频片段都分为语音片段和非语音片段。我们常用的降噪耳机在这里是为了减少别人的噪音和环境噪音。这里的算法非常复杂:可以设置规则,例如,均匀分贝的声音很可能是环境噪声,但不准确;也可以用于大数据统计的深入学习,更准确,但解释性较少。
[En]
preliminary decision: this is the analysis center, where each input audio clip is divided into voice clips and non-voice clips. Our commonly used noise reduction headphones are here to reduce other people’s noise and ambient noise. The algorithm here is very complex: rules can be set, for example, the sound of uniform decibels is likely to be ambient noise, but it is not accurate; it can also be used for in-depth learning of big data statistics, which is more accurate but less explanatory.*
- 后处理:主要目的是平滑初步决定的结果,每个音频片段都以帧的形式传输。当处理1Magazine 2和3帧时,初步判定可能是1 Magi 3是人类声音,而2是环境声音。这在理论上是不可能的,因为人们的发言应该是连续的,不太可能中间突然没有一个帧,然后就会有一个瞬间。因此,后处理是为了纠正这些可能的错误,以避免频繁切换语音状态。
[En]
Post-processing: the main purpose is to smooth the results of the preliminary decision, and each audio clip is transmitted in the form of a frame. When dealing with 1Magazine 2 and 3 frames, the preliminary decision may be that 1 Magi 3 is a human voice and 2 is an ambient voice. This is theoretically impossible, because people’s speech should be continuous, it is unlikely that there will be a sudden absence of a frame in the middle, and then there will be an instant. Therefore, the post-processing is to correct these possible errors to avoid frequently switching voice states.*

从上面可以知道,最关键的部分是初步决策中选择何种VAD算法区分人声与环境声,我们希望这个VAD算法能在嘈杂环境,也就是高信噪比下能区分人声,同时有较好的鲁棒性
关键在于,人声和噪声的区别是什么?肯定是有区别的,不然人耳为什么能区分?基于这个角度,出现了下面这些算法
- 短时能量检测 这种方法认为,能量是语音与噪声最大的区别,语音的能量更大,同时由于语音本质是非线性的(再唠叨的人也不会连续不断的说话),我们只需要统计这些非线性声音的能量,求一个平均值,然后未来再出现类似能量的声音,我们就认为是人声,公式如下
 开发同学不必深究公式,简单说就是x(n)为原生声音,w(n – m)为窗函数,表示取样长度,然后最后求平均值即可
开发同学不必深究公式,简单说就是x(n)为原生声音,w(n – m)为窗函数,表示取样长度,然后最后求平均值即可
这个方法在环境声比较固定,且比较小,比如持有intel 版本的mac程序员,使用这种方法,能比较好的过滤这种mac的风扇声(intel给爷爬,m1 yyds)
局限性也比较明显,那就是适用范围窄,在较为复杂的环境下,比如,公司,马路,菜市场这些地方,就几乎没有什么作用
下图可以简单总结一下
算法原理优点缺点短时能量检测计算人声能量的平均值简单,噪声小且稳定时效果较好适用范围窄,功能弱DNN深度学习提取特征效果更好,适用性更好可解释性差,优化较为困难DNN+ 输入特征DNN+人工输入特征应该是目前最好的解决方案很难实现
; 唤醒词识别
上面说了针对语音端点检测的算法原理和两种现有的算法,我们回到siri,现在iphone已经在嘈杂环境下用DNN识别出了你的语音,那么接下来就是解码的过程,将你的语音转为系统能识别的指令
当我们说:”你好,siri”的时候,siri并不会理我们,所以,我们可以推测,siri的启动指令,一定是通过”嘿,siri”转换而来,那么,这就是使用了关键词检测
所以,iphone在用DNN训练时,一定是针对这句话进行了多种语言,多种声音模式的大数据训练,并构建了一个关键词声学模型,这种针对于关键词的检测算法有很多种,其中一种常用的是基于 隐马尔科夫模型的关键词检测
隐马尔科夫模型
听着很悬,但是思想不难,只需要为关键词构造一组HMM模型,称为keyword 模型,为非关键词构造另一组HMM模型,称为Filler模型,当接受到一个关键词的时候,如果发现他属于Filler模型,那么就cut掉
我们都说,幸福的家庭都是一样的幸福,而不幸的家庭各有各的不幸。在这里,也一样,keyword模型只有一个,而Filler模型是一个统称,他的HMM模型,可以有很多个
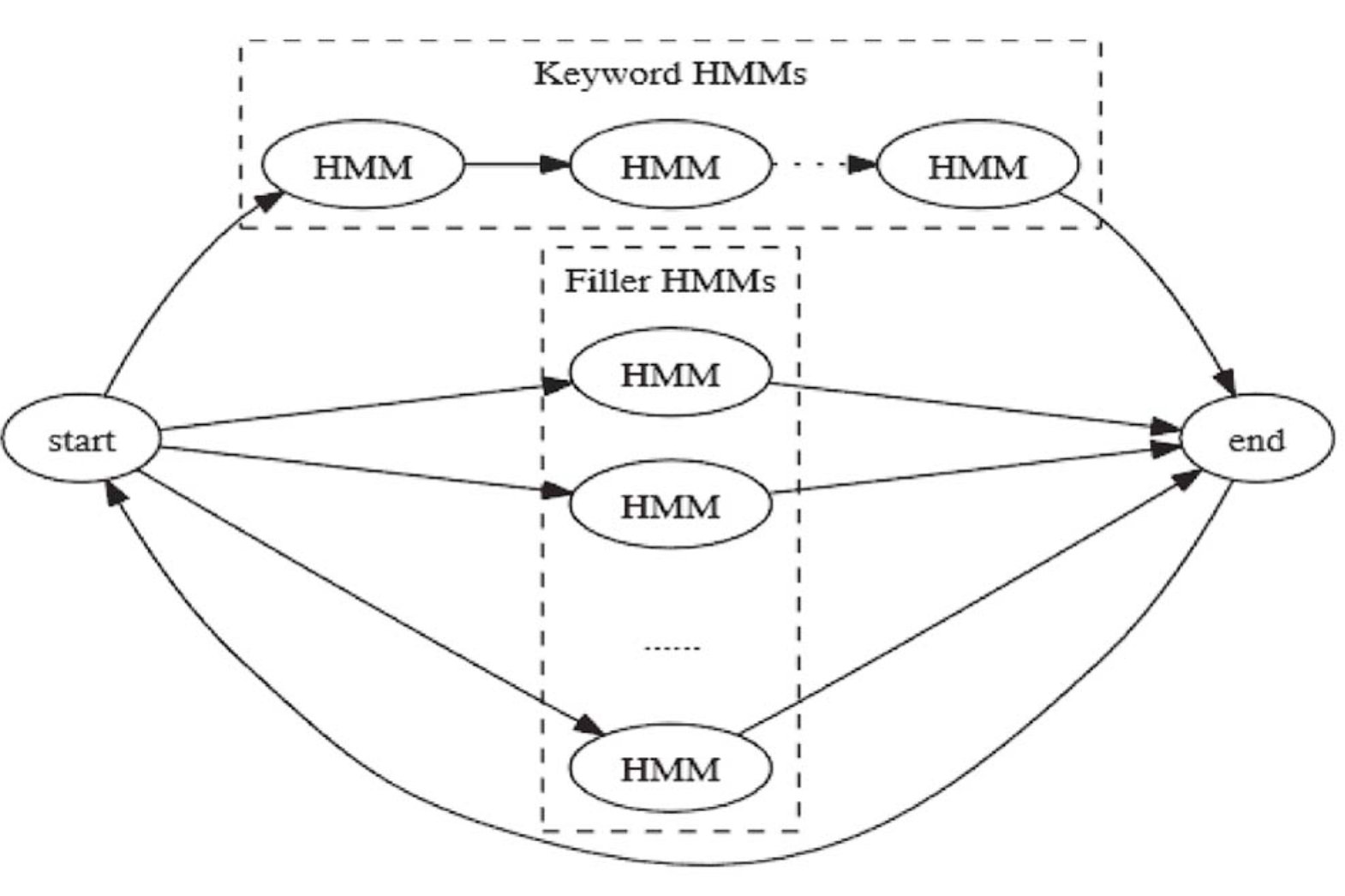
这个模型的核心作用就是过滤出关键词,并将他通过HMM模型转换为系统可识别的信号,这一过程就是解码的过程,将声学型号进行转换
; 解码
你可能会说,这还不简单,我们直接硬编码就行了,反正唤醒识别只用说”嘿,siri”
当然不是!虽然唤醒识别只有一句话,但后续用户会说很多不同的东西,而解码者需要在整个语音交互过程中发挥作用,而不仅仅是唤醒这一部分。
[En]
Of course not! Although there is only one sentence for wake-up recognition, subsequent users will say a lot of different things, and the decoder needs to play a role in the whole process of voice interaction, not just awakening this part.
但世界上有成千上万个不同的词。你想让服务员像明星一样把这句话说完吗?绝对不是那么回事。本质上,它是检测句子中的关键词,推断句子的意思。
[En]
But there are more than thousands of different words in the world. Do you want the server to exhaust this sentence like stars? Definitely not. In essence, it is to detect the key words in the sentence and infer the meaning of the sentence.
因此,解码过程本质上是关键字检测。
[En]
So the decoding process is essentially keyword detection.
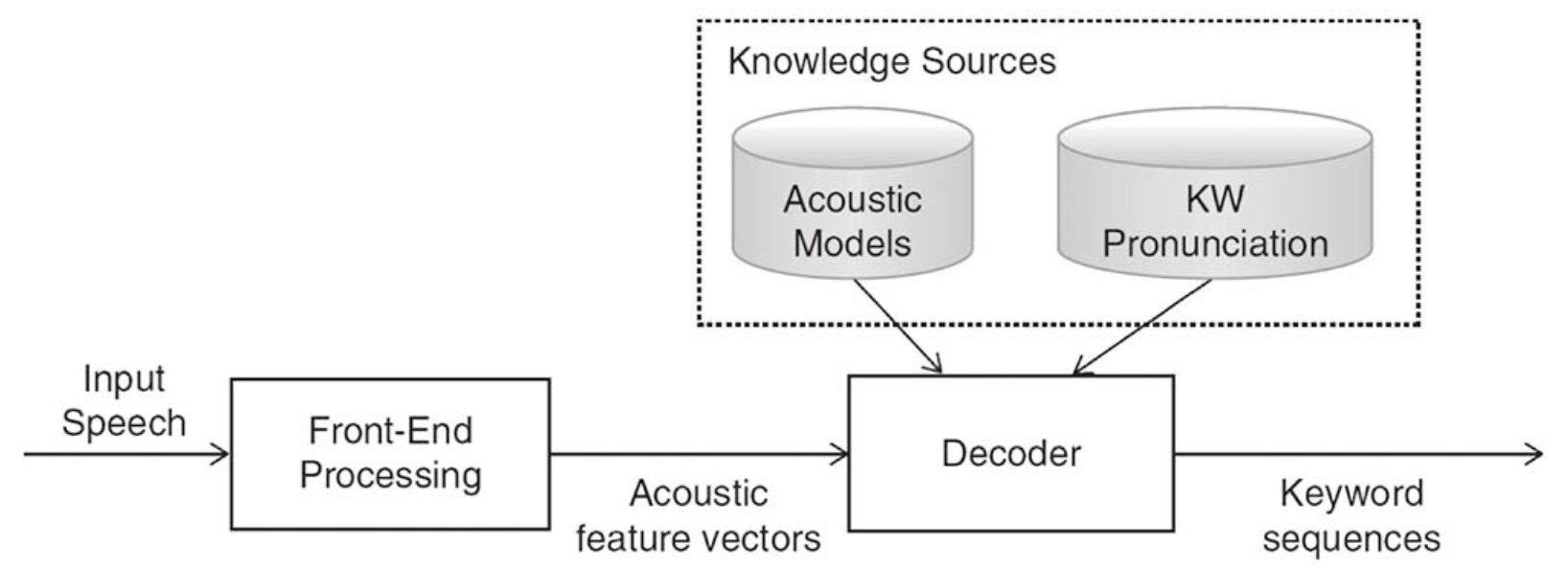
上图就是解码器所处的位置,既然要做关键词检测,就必须有一个词库KW进行配对,同时需要一个Acoustic Models模型,区分出每一句话中的关键词,当然这里已经不属于唤醒识别的范畴了,本文仅讨论唤醒识别,有兴趣的同学可以去研究哦,我后续也会继续研究的~
后记
这是小松第一次系统总结语言识别的相关知识。总而言之,有两个步骤。
[En]
This is the first time that Komatsu has systematically summarized the relevant knowledge of * language recognition * . To sum up, there are two steps.
- 语音检测VAD DNN算法过滤噪声
- 唤醒词识别 隐马尔科夫模型识别关键词,解码器匹配词库解码
我本科时接过百度的apollo,百度的语音模型算是国内比较领先的了,具体使用也很简单,就是将关键词填进去,然后当一句话包含那个关键词时,就可以被模型检测出来,返回相应的结果,
比如在后台,填入一个”吃饭”,然后在app中实现回调函数:调用地图,搜索饭店
这样,你对着集成了apollo模型的app说:吃饭,app就会自动打开地图搜索饭点
这很有趣。有兴趣的学生可以试一试。
[En]
It’s fun. Interested students can give it a try.
小松很高兴生活在这个知识爆炸的时代,有太多我一直好奇的问题有科学的答案,即使没有现成的答案,也有科学的方法帮助我们找到答案,终身学习,共同进步!
[En]
Komatsu is very happy to live in this era of knowledge explosion, there are too many questions I have been curious about have scientific answers, even if there are no ready-made answers, there are scientific ways to help us to find answers, lifelong learning, and progress together!
参考书《人工智能:语音识别的理解和实践》
[En]
Reference Book artificial Intelligence: understanding and practice of speech recognition
个人简介
我是小松,20届,末流985本科,曾参与开发手机QQ,现在不断在b站更新题解视频,手绘图解和代码实战,专注android与算法,文章首发与公众号小松漫步
另外建有学习群,已经有上百位爱学习的小伙伴,每周与群友进行模拟面试,互相鼓励学习,有意参与可以加我微信 cs183071301,加了后,请主动说自己的技术栈和称呼,然后我拉你进群(务必备注自己哦)
每周周六晚9点大家可以一起线上参与模拟远程面试,b站【小松不漫步】直播,大家快来参与吧
Original: https://blog.csdn.net/qq_37465638/article/details/122001236
Author: 只有小松了
Title: 当我们说“嘿,siri”时,会发生什么?
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/512036/
转载文章受原作者版权保护。转载请注明原作者出处!