

1 前言
我们浏览在各个平台时会发现”为你推荐”功能。比如YouTube推荐爱看的视频,音乐软件为你提供你可能喜欢的音乐等。其实这一功能的背后涉及的原理就是人工智能的推荐系统。今天我们将介绍TensorFlow推荐系统模型的库——TensorFlow Recommenders(TFRS)[1]。
对TensorFlow感兴趣的朋友们,还可以回顾我们之前相关的文章:
2 推荐原理
在这里,我们用一个电影推荐的例子来解释推荐系统的原理。
[En]
Here we use an example of movie recommendation to explain the principle of the recommendation system.
对于现有的四个用户和五部类型不同的电影,首先,我们需要创建用户画像和定义电影类别,这一步是为了区分数据,将现实特征转化为可计算的变量。对于现有的用户数据和电影数据,我们如何给用户D推荐她可能喜欢的电影呢?


如下图所示,我们在这里为用户和电影这两个变量分别创建了一个二维矩阵。对于用户,我们会定义他们是否更喜欢儿童电影(-1表示他们喜欢儿童电影,反之亦然),他们是否更喜欢热门电影(1表示他们喜欢热门电影,-1表示他们喜欢热门电影)。对于电影,定义为是否为儿童片(儿童电影为-1,非儿童电影为1)以及是否为热门电影(热门电影为1,反之亦然)。
[En]
As shown in the following figure, here we create a matrix of two dimensions for each of the two variables, the user and the movie. For users, we will define whether they prefer children’s movies (- 1 means they like children’s movies, and vice versa) and whether they prefer hot movies (1 indicates that they like hot movies,-1 vice versa). For movies, it is defined as whether it is a children’s film (- 1 for children’s movies, 1 for non-children’s movies) and whether it is a hot movie (1 for hot movies,-1 is vice versa).
可以看出,用户A很喜欢看儿童且火爆的电影,这就是基于两个维度的 User Embedding;而《怪物史莱克》在这里被定义为儿童且火爆的电影,这一过程就是 Movie Embedding。值得一提的是,在搭建模型时, Embedding的维度不只是二维的,往往是多维的矩阵来表示变量。

接下来,用矩阵分解进行协同过滤计算预测的反馈矩阵。如下图所示,U代表用户矩阵,V代表电影候选条目的矩阵,计算的A值就是预测的反馈值。所以 协同过滤就是依据用户和候选条目之间的相似度来进行推荐。
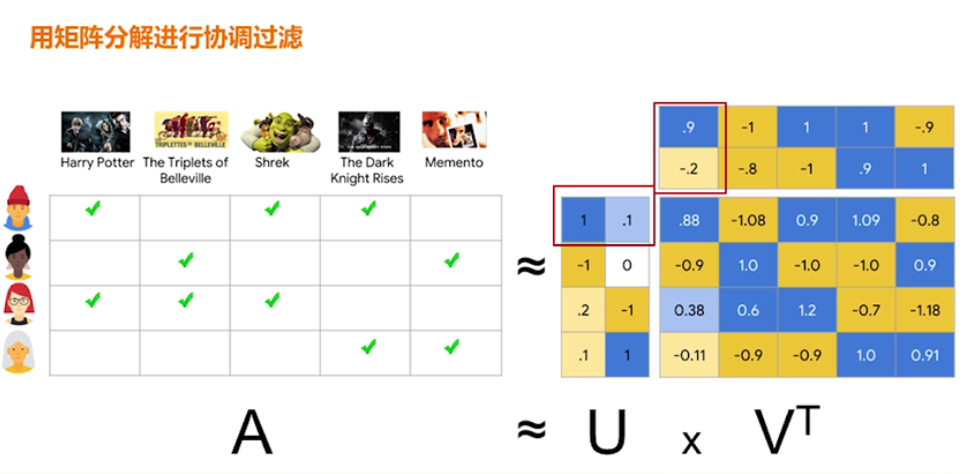
在使用矩阵分解进行协同过滤时,为了减少目标函数的预测误差,官方解释使用随机梯度下降 Stochastic Gradient Descent(SGD)或加权交替最小平方算法 Weighted Alternating Least Squares(WALS)两种方式。
值得一提的是,WALS是专门解决推荐系统而创建的新算法,与前者不同,WALS每次迭代时,固定U的值来确定V,再固定V的值来确定U。两种方法各有利弊,这里不再详细介绍了,感兴趣的朋友可以学习一下矩阵分解[2]的官方资料.

3 源码解析
实际的推荐系统分为两部分:
[En]
The actual recommendation system is divided into two parts:
- 从大量的潜在推荐条目中选择可能性比较大的items,这一过程叫做信息检索(retrieval)。
- 对于提取模型的结果,我们还需要排序来缩小选择最有可能被用户选择的items,这一过程叫做rank。
这一部分,我们先介绍第一阶段的信息提取模型。信息提取模型又包含两个子模型,查询模型和候选模型,对应上述的例子就是用户矩阵和候选条目矩阵,通过计算两个子模型的乘积,得到的 query-candidate affinity score就是反映查询和候选条目之间的匹配程度,即用户喜欢推荐条目的可能性。
# Dependency install
!pip install -q tensorflow-recommenders
!pip install -q --upgrade tensorflow-datasets
import os
import pprint
import tempfile
from typing import Dict, Text
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
## import tensorflow recommenders API
import tensorflow_recommenders as tfrs
从网上加载 MovieLens数据:
# Ratings data.
ratings = tfds.load("movielens/100k-ratings", split="train")
# Features of all the available movies.
movies = tfds.load("movielens/100k-movies", split="train")
## Note: MovieLens 没有事先准备好数据集,所有的数据都在train data中。
# 查看数据rating和movies
for x in ratings.take(2).as_numpy_iterator():
  pprint.pprint(x)
#{'movie_title': b"One Flew Over the Cuckoo's Nest (1975)", 'user_id': b'138'}
#{'movie_title': b'Strictly Ballroom (1992)', 'user_id': b'92'}
for x in movies.take(2).as_numpy_iterator():
  pprint.pprint(x)
#b'You So Crazy (1994)'
#b'Love Is All There Is (1996)'
在提取模型中,我们先处理 rating数据集,并选择 user_id和 movie_title来定义用户画像。
ratings = ratings.map(lambda x: {
    "movie_title": x["movie_title"],
    "user_id": x["user_id"],
})
movies = movies.map(lambda x: x["movie_title"])
设置训练集和测试数据集:
[En]
Set up the training set and test data set:
tf.random.set_seed(42)
shuffled = ratings.shuffle(100_000, seed=42, reshuffle_each_iteration=False)
train = shuffled.take(80_000)
test = shuffled.skip(80_000).take(20_000)
# 为变量数值做mapping
movie_titles = movies.batch(1_000)
user_ids = ratings.batch(1_000_000).map(lambda x: x["user_id"])
unique_movie_titles = np.unique(np.concatenate(list(movie_titles)))
unique_user_ids = np.unique(np.concatenate(list(user_ids)))
unique_movie_titles[:10]
#array([b"'Til There Was You (1997)", b'1-900 (1994)',
       #b'101 Dalmatians (1996)', b'12 Angry Men (1957)', b'187 (1997)',
       #b'2 Days in the Valley (1996)',
       #b'20,000 Leagues Under the Sea (1954)',
       #b'2001: A Space Odyssey (1968)',
       #b'3 Ninjas: High Noon At Mega Mountain (1998)',
       #b'39 Steps, The (1935)'], dtype=object)
定义用户模型和电影模型:
[En]
Define the user model and movie model:
#设定embedding维度
embedding_dimension = 32
#设定用户模型
user_model = tf.keras.Sequential([
  tf.keras.layers.StringLookup(
      vocabulary=unique_user_ids, mask_token=None),
  # We add an additional embedding to account for unknown tokens.
  tf.keras.layers.Embedding(len(unique_user_ids) + 1, embedding_dimension)
])
#设定电影模型
movie_model = tf.keras.Sequential([
  tf.keras.layers.StringLookup(
      vocabulary=unique_movie_titles, mask_token=None),
  tf.keras.layers.Embedding(len(unique_movie_titles) + 1, embedding_dimension)
])
关于评估标准, TensorFlow使用的是 FactorizedTopK去衡量预测能力,
metrics = tfrs.metrics.FactorizedTopK(
  candidates=movies.batch(128).map(movie_model)
)
task = tfrs.tasks.Retrieval(
  metrics=metrics
)
封装模型函数和损耗函数:
[En]
Encapsulate the model function and loss function:
class MovielensModel(tfrs.Model):
  def __init__(self, user_model, movie_model):
    super().__init__()
    self.movie_model: tf.keras.Model = movie_model
    self.user_model: tf.keras.Model = user_model
    self.task: tf.keras.layers.Layer = task
  def compute_loss(self, features: Dict[Text, tf.Tensor], training=False) -> tf.Tensor:
    # We pick out the user features and pass them into the user model.
    user_embeddings = self.user_model(features["user_id"])
    # And pick out the movie features and pass them into the movie model,
    # getting embeddings back.
    positive_movie_embeddings = self.movie_model(features["movie_title"])
    # The task computes the loss and the metrics.
    return self.task(user_embeddings, positive_movie_embeddings) 
训练并评估模型结果:
model = MovielensModel(user_model, movie_model)
model.compile(optimizer=tf.keras.optimizers.Adagrad(learning_rate=0.1))
#shuffle data and get samples
cached_train = train.shuffle(100_000).batch(8192).cache()
cached_test = test.batch(4096).cache()
model.fit(cached_train, epochs=3)
#使用test data evaluate
model.evaluate(cached_test, return_dict=True)
{'factorized_top_k/top_1_categorical_accuracy': 0.00044999999227002263,
 'factorized_top_k/top_5_categorical_accuracy': 0.004100000020116568,
 'factorized_top_k/top_10_categorical_accuracy': 0.01145000010728836,
 'factorized_top_k/top_50_categorical_accuracy': 0.09040000289678574,
 'factorized_top_k/top_100_categorical_accuracy': 0.19300000369548798,
 'loss': 28535.75390625,
 'regularization_loss': 0,
 'total_loss': 28535.75390625}
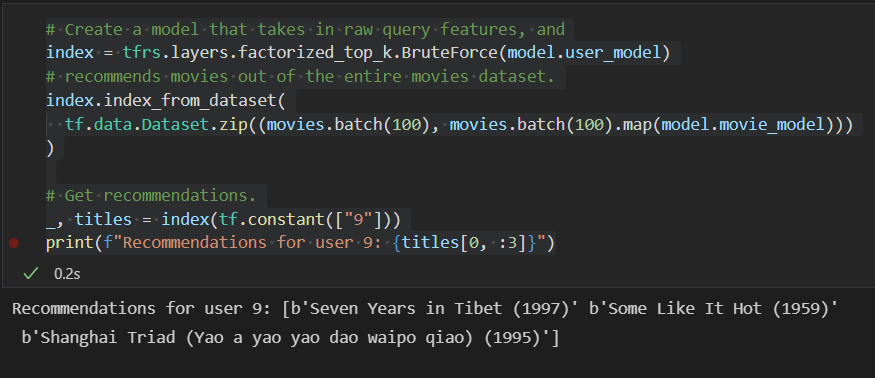
使用训练好的模型为 user_id=9的用户推荐电影的预测:
# Create a model that takes in raw query features, and
index = tfrs.layers.factorized_top_k.BruteForce(model.user_model)
# recommends movies out of the entire movies dataset.
index.index_from_dataset(
  tf.data.Dataset.zip((movies.batch(100), movies.batch(100).map(model.movie_model)))
)
# Get recommendations.
_, titles = index(tf.constant(["9"]))
print(f"Recommendations for user 9: {titles[0, :3]}")
4 总结
TensorFlow 为机器学习提供了非常丰富且强大的资源,感兴趣的朋友可以将这些模型运用到现有的数据中,去探究一些有趣的惊喜吧!
我希望这个分享会对你有所帮助,也欢迎你留言讨论。
[En]
I hope this sharing will be helpful to you, and you are welcome to leave a message for discussion.
参考资料
[1]
TensorFlow Recommenders: https://www.tensorflow.org/recommenders?hl=en
[2]
Matrix Factorization: https://developers.google.com/machine-learning/recommendation/collaborative/matrix
Original: https://blog.csdn.net/BulletTech2021/article/details/121941086
Author: BulletTech2021
Title: TensorFlow推荐系统(一)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/511742/
转载文章受原作者版权保护。转载请注明原作者出处!