

import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense,Dropout,Convolution2D,MaxPooling2D,Flatten
from tensorflow.keras.optimizers import Adam
def train_model():
加载训练集和测试集数据以进行唯一的热编码
[En]
Load training set and test set data for unique hot coding
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
y_train = tf.keras.utils.to_categorical(y_train,num_classes=10)
y_test = tf.keras.utils.to_categorical(y_test,num_classes=10)
定义顺序模型
model = Sequential()
卷积层、池化层、展平、全连接
[En]
Convolution layer, pooling layer, flattening, full connection
model.add(Convolution2D(input_shape=(28, 28, 1), filters=32, kernel_size=5, strides=1, padding=’same’, activation=’relu’))
model.add(MaxPooling2D(pool_size=2, strides=2, padding = ‘same’))
model.add(Convolution2D(64, 5, strides=1, padding=’same’, activation=’relu’))
model.add(MaxPooling2D(2,2,’same’))
model.add(Flatten())
model.add(Dense(1024,activation = ‘relu’))
model.add(Dropout(0.5))
model.add(Dense(10,activation=’softmax’))
定义优化器,loss function,训练过程中计算准确率
adam = Adam(lr=1e-4)
model.compile(optimizer=adam,loss=’categorical_crossentropy’,metrics=[‘accuracy’])
训练模型
model.fit(x_train,y_train,batch_size=64,epochs=10,validation_data=(x_test, y_test))
保存模型
model.save(‘./model/model_v1’, save_format=”tf”)
3.1.2 查看模型文件
进入模型文件目录,执行以下命令,显示模型文件信息。圆圈红色的信息自上而下为模型的标签、签名、输入张量、输出张量和预测方法名称。此信息将在以后加载模型预测时使用。
[En]
Enter the model file directory and execute the following command to display the model file information. The information of circle red is the label, signature, input tensor, output tensor and prediction method name of the model from top to bottom. This information is used later when loading model predictions.
saved_model_cli show –dir ./model_v1/ –all


; 3.2 模型预测
3.2.1 工程搭建&框架引入
新建 Scala 工程,引入 Spark 和 Tensorflow 依赖
org.scala-lang
scala-library
${scala.version}
org.apache.spark
spark-core_${spark.scala.version}
${spark.version}
org.apache.spark
spark-hive_${spark.scala.version}
${spark.version}
org.apache.spark
spark-sql_${spark.scala.version}
${spark.version}
org.tensorflow
tensorflow
1.15.0
3.2.2 模型文件加载
调用 Tensorflow API 加载预训练好的 protobuff 格式模型文件,得到 SavedModelBundle 类型模型对象。模型文件我们可以保存在工程 resource 目录下,再从 resource 目录加载( Tensorflow 不支持直接从 HDFS 记载模型,后文会介绍如何实现)。
package com.tfspark
import org.apache.spark.sql.SparkSession
import org.tensorflow.SavedModelBundle
import org.{tensorflow => tf}
object ModelLoader {
//modelPath是模型在resource下路径,modelTag从模型文件信息中获取
def loadModelFromLocal(spark: SparkSession, modelPath: String, modelTag: String): SavedModelBundle = {
val bundle = tf.SavedModelBundle.load(modelPath, modelTag)
}
}
3.2.3 调用Tensorflow API 预测
在 Java 版本的 Tensorflow 中还是类似 Tensorflow1.0 中静态计算图的模式,需要建立 session ,指定 feed 的特征数据和 fetch 的预测结果,然后执行 run 方法。
通过查看模型文件获得的信息将作为参数传入此处。
[En]
The information obtained from viewing the model file will be passed in here as a parameter.
package com.tfspark.tensorflow
import com.qunar.rdc.util.TfUtil
import org.tensorflow.SavedModelBundle
import scala.collection.mutable.WrappedArray
import org.{tensorflow => tf}
object TensorFlowCnnProcessor {
def predict(broads: SavedModelBundle, features: WrappedArray[WrappedArray[WrappedArray[Float]]]): Int = {
val sess = bundle.session()
// 特征数据格式化
val x = tf.Tensor.create(Array(features.map(a => a.map(b => b.toArray).toArray).toArray))
// 执行预测 需要传入模型信息里的输入张量名和输出张量名,以及格式化后的特征数据
val y = sess.runner().feed(“serving_default_hmc_input:0”, x).fetch(“StatefulPartitionedCall:0”).run().get(0)
// 结果是1×2的二维数组
val result = Array.ofDim Float
y.copyTo(result)
//
《一线大厂Java面试题解析+后端开发学习笔记+最新架构讲解视频+实战项目源码讲义》
【docs.qq.com/doc/DSmxTbFJ1cmN1R2dB】 完整内容开源分享
返回最大值坐标,即为分类结果,对应的是one-hot编码
TfUtil.argMaxOneDim(result(0))
}
}
3.2.4 Spark 结合 Tensorflow 预测
Spark 从 Hive 读取预测数据,经过预处理转换成特征数据,调用 Tensorflow API 预测。通过 Tensorflow API 与 Spark 分布式数据集结合使用,实现分布式批处理框架和机器学习的集成。
// 将封装Tensorflow API的预测方法注册为udf函数
val sensorPredict = udf((features: WrappedArray[WrappedArray[WrappedArray[Float]]]) => {predict(bundle, features)})
// Dataframe调udf函数
val resultDf = featureDf.withColumn(“predict_result”, sensorPredict(col(“feature”))
3.3 服务部署
3.3.1 环境依赖
将 Spark-Scala 和 Tensorflow for Java 集成后的工程,通过 maven 打出依赖包:tfspark-1.0.0-jar-with-dependencies.jar 。
在部署了 spark 运行环境的 hadoop 集群上运行 jar 包。依赖的集群环境需提前安装 spark、hadoop、hive 等大数据组件。
3.3.2 执行脚本
spark-submit 执行 jar 包,指定执行的 main 函数类 com.tfspark.PredictMain ,指定 jar 包路径,设置执行任务的 executor 数和核心数以及内存参数,传入模型文件版本参数。
sudo -u root /usr/local/Cellar/apache-spark/2.4.3/bin/spark-submit –class com.tfspark.PredictMain –master yarn –deploy-mode client –driver-memory 6g –executor-memory 6g –num-executors 5 –executor-cores 4 /tmp/tfspark-1.0.0-jar-with-dependencies.jar model_v1
3.4 实践成果
完成 Tensorflow for Java 和 Spark-Scala 的集成,实现大数据分布式批处理框架和机器学习的结合。将 Python 环境下生成的模型文件,加载应用于 Java 平台, 达到机器学习模型跨平台应用的效果。
顺利应用于线上项目,每小时完成 300w 数据模型预测,任务耗时 9m ,吞吐量达到 5500+/秒。实现大数据场景下高性能的离线模型预测,打通了整套应用流程。
四. 优化&踩坑经验
时长性能优化
在 3.2.4 节示范了 Spark 在 DataFrame 中调用 Tensorflow API 的常规操作流程。我们的项目按以上实现方式上线之初, 300w 数据执行耗时在 20m 左右。分析之后认为性能上有优化的空间。
- 问题:每个数据调用一次模型预测方法,导致一些可重用对象被多次创建,同一方法流被多次调用。
[En]
problem: the model prediction method is called once for each piece of data, which causes some reusable objects to be created multiple times, and the same method flow is called multiple times.*
- 优化思路:批量数据调用预测方法。减少重复的对象创建和方法过程执行。
[En]
Optimization idea: call the prediction method in batch data. Reduce repetitive object creation and method process execution.*
- 解决方案:使用 RDD 模式下 mapPartition 算子替代 map 算子,获取特征数组,批量调用。
对比下 mapPartition 算子和 map 算子的实现:
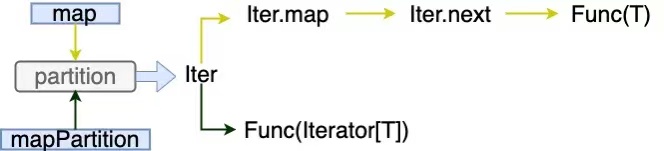
两者都是操作 partition 的迭代器, map 算子通过迭代器获取每个元素,调用操作函数,函数入参是元素类型。mapPartition 直接将迭代器传给操作函数,函数入参是元素集合的迭代器类型。所以使用区别在于, mapPartition 在一个方法中,操作所有 partition 元素,调用一次操作函数;map 一次只能操作一个元素,调用多次操作函数。
因此 mapPartition 对比 map ,更适用于存在重复对象创建或流程调用的场景,可以提升性能效率;mapPartition 存在的突出缺点是可能导致 OOM ,因为一次加载多个元素,相对于 map 一次加载一个元素,占用内存更多,不能及时垃圾回收。
Tensorflow API 支持传入数组批量调用,通过 mapPartition 将迭代器转换成数组,就可以批量预测,提升了效率。
float[][] matrix = new float[m][n];
Tensor ft = Tensor.create(matrix, Float.class);
val y = sess.runner().feed(“serving_default_hmc_input:0”, ft).fetch(“StatefulPartitionedCall:0”).run().get(0)
结果:经过采用RDD模式下mapPartition算子实现批量预测后,任务时长显著下降,由20m降至9m。
; 模型文件热更新
Original: https://blog.csdn.net/m0_54852680/article/details/122217528
Author: m0_54852680
Title: Tensorflow for Java + Spark-Scala分布式机器学习计算框架的应用实践
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/511540/
转载文章受原作者版权保护。转载请注明原作者出处!