

现在Python横行的年代,财务、人事、行政等等岗位多少得学点Python,省事又不费脑!
所有操作都用Python自动实现,加班?不存在的!


excel和python其实都是工具,不要也不用拿去做对比,研究哪个好用,excel作为最为全球广泛的数据处理工具,垄断多年,肯定在数据处理方面有自己的优点,Python只是令 一些庞大的,费时间的操作加速处理,方便工作嘛。
当然也有很多excel的操作比用Python自动处理更加简单方便。
比如:对各列求和并在最下一行显示出来,excel就是对一列总一个sum()函数,然后往左一拉就解决,而python则要定义一个函数,python要判断格式,若非数值型数据会直接。我就不一一举例了!
好了,我们开始正题。
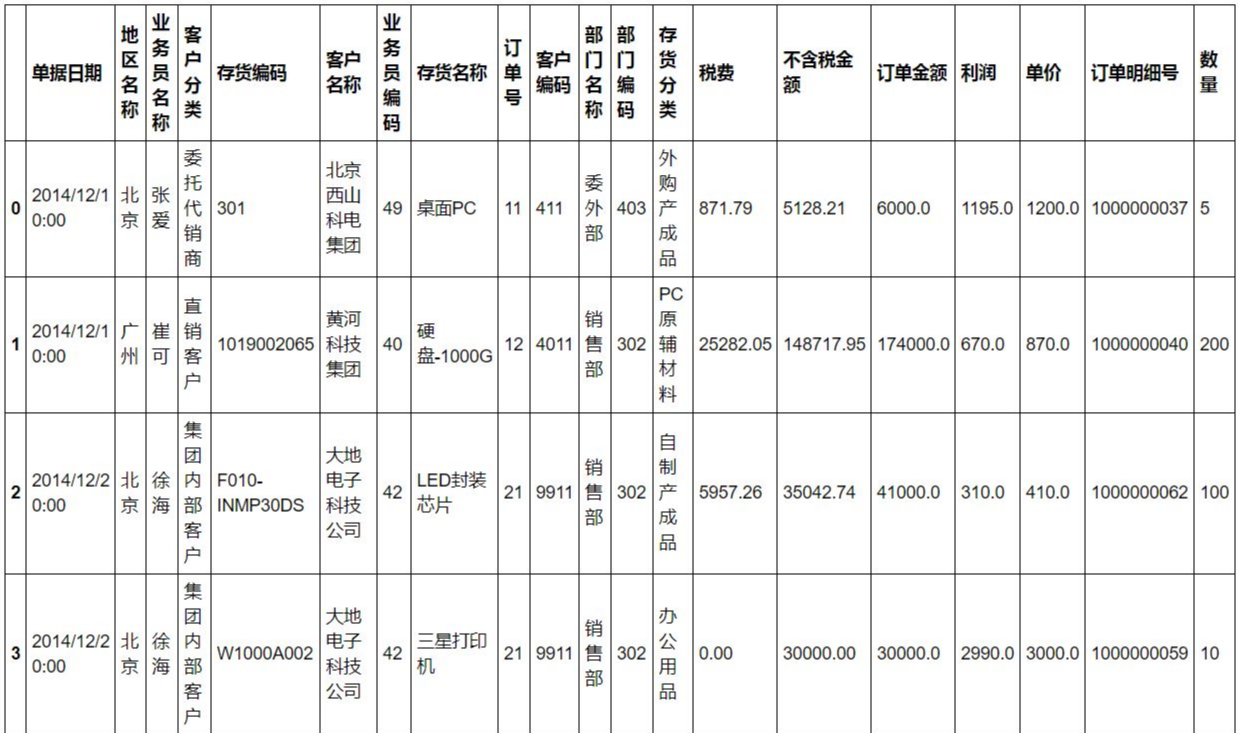
在互联网上找到的销售数据是这样的。
[En]
The sales data found on the Internet look something like this.
需求
想知道每个地区推销员的利润总额和平均数吗?
[En]
Want to know the sum and average of profits earned by salesmen in each region
pd.pivot_table(sale,index="地区名称",columns="业务员名称",values="利润",aggfunc=[np.sum,np.mean])
#兄弟们学习python,有时候不知道怎么学,从哪里开始学。掌握了基本的一#些语法或者做了两个案例后,不知道下一步怎么走,不知道如何去学习更加高#深的知识。
#那么对于这些大兄弟们,我准备了大量的免费视频教程,PDF电子书籍,以及#视频源的源代码!
#还会有大佬解答!
#都在这个裙里了 872937351
#欢迎加入,一起讨论 一起学习!
2、去除重复值
需求
去除业务员编码的重复值
sale.drop_duplicates("业务员编码",inplace=True)
3、分类汇总
需求
北京地区销售人员的总利润
[En]
The total profits of the salesmen in Beijing area
sale.groupby(["地区名称","业务员名称"])["利润"].sum()
4、关联公式:Vlookup
vlookup是excel几乎最常用的公式,一般用于两个表的关联查询等。
所以我先把这张桌子分成两张桌子。
[En]
So I’ll divide this table into two tables first.
df1=sale[['订单明细号','单据日期','地区名称', '业务员名称','客户分类', '存货编码', '客户名称', '业务员编码', '存货名称', '订单号',
'客户编码', '部门名称', '部门编码']]
df2=sale[['订单明细号','存货分类', '税费', '不含税金额', '订单金额', '利润', '单价','数量']]
需求
想知道df1的每一个订单对应的利润是多少
利润一列存在于df2的表格中,所以想知道df1的每一个订单对应的利润是多少。
用excel的话首先确认订单明细号是唯一值,然后在df1新增一列写:=vlookup(a2,df2!a:h,6,0) ,然后往下拉就ok了。
那用python是如何实现的呢?
#查看订单明细号是否重复,结果是没。
df1["订单明细号"].duplicated().value_counts()
df2["订单明细号"].duplicated().value_counts()
df_c=pd.merge(df1,df2,on="订单明细号",how="left")
5、条件计算
需求
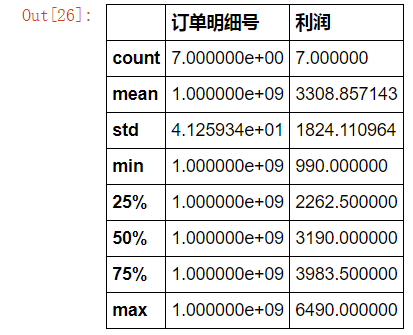
存货名称含”三星字眼”并且税费高于1000的订单有几个?
这些订单的总额和平均利润是多少?(或最小、最大、四分位数、尺寸差)
[En]
What is the sum and average profit of these orders? (or minimum, maximum, quartile, dimension difference)
sale.loc[sale["存货名称"].str.contains("三星")&(sale["税费"]>=1000)][["订单明细号","利润"]].describe()
6、分组
需求
根据利润数据的分布情况,将区域划分为“差”、“中等”、“较好”和“很好”。
[En]
The regions are divided into “poor”, “medium”, “better” and “very good” according to the distribution of profit data.
首先当然是看利润的数据分布,这里我们用四分位数来判断。
[En]
First of all, of course, it is to look at the data distribution of profits, here we use the quartile to judge.
sale.groupby("地区名称")["利润"].sum().describe()

根据四分位数把地区总利润为[-9,7091]区间的分组为”较差”,(7091,10952]区间的分组为”中等”
(10952,17656]分组为较好,(17656,37556]分组为非常好。
#先建立一个Dataframe
sale_area=pd.DataFrame(sale.groupby("地区名称")["利润"].sum()).reset_index()
#设置bins,和分组名称
bins=[-10,7091,10952,17656,37556]
groups=["较差","中等","较好","非常好"]
#使用cut分组
#sale_area["分组"]=pd.cut(sale_area["利润"],bins,labels=groups)
7、对比两列差异
因为表的每一列都有不同的数据维度,所以比较它没有任何意义,所以在比较它之前,我在Order Detail数字上做了一个改变。
[En]
Because each column of the table has different data dimensions, it doesn’t make any sense to compare it, so I made a difference in the order detail number before comparing it.
要求:比较订单明细编号和订单明细编号2之间的差异并显示出来。
[En]
Requirements: compare the difference between order detail number and order detail number 2 and show it.
sale["订单明细号2"]=sale["订单明细号"]
#在订单明细号2里前10个都+1.
sale["订单明细号2"][1:10]=sale["订单明细号2"][1:10]+1
#差异输出
result=sale.loc[sale["订单明细号"].isin(sale["订单明细号2"])==False]
8、异常值替换
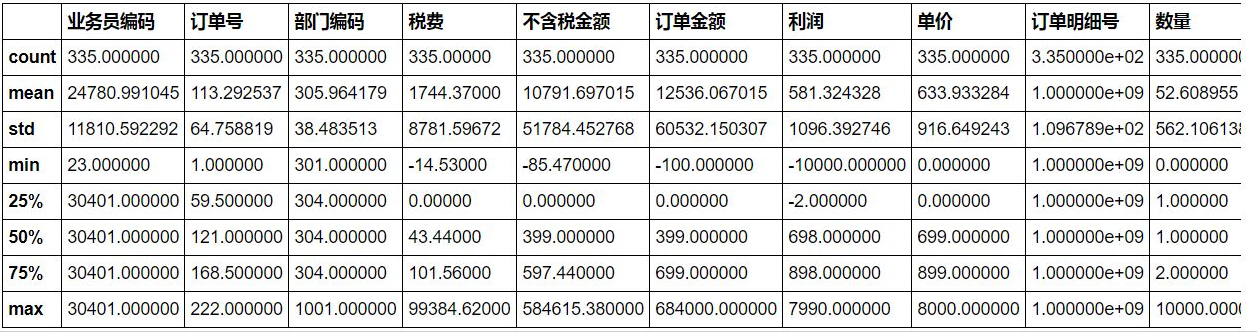
首先用describe()函数简单查看一下数据有无异常值。
#可看到销项税有负数,一般不会有这种情况,视它为异常值。
sale.describe()
用0代替异常值。
sale["订单金额"]=sale["订单金额"].replace(min(sale["订单金额"]),0)
9、缺失值处理
首先检查哪些销售数据列缺少值。
[En]
First check which columns of sales data have missing values.
#列的行数小于index的行数的说明有缺失值,这里客户名称329
sale.info()

需求
用0填充缺失值或则删除有客户编码缺失值的行
实际上,缺失值的处理方法是非常复杂的,这里只介绍简单的处理方法,如果是数值变量,最常用的是平均值或中位数或模式值的处理,更复杂的可以用随机森林模型填充其他维度来预测结果。
[En]
In fact, the method of dealing with missing values is very complex, here only introduce simple processing methods, if numerical variables, the most commonly used average or median or mode processing, more complex can be filled with random forest models to predict results according to other dimensions.
如果是分类变量,按照业务逻辑填报更准确。
[En]
If it is a classified variable, it is more accurate to fill it according to business logic.
例如,此处的需求填入了缺失的客户名称:可以根据存货分类频率最高的存货对应的客户名称进行填充。
[En]
For example, the demand here fills in the missing customer name: it can be filled according to the customer name corresponding to the inventory with the highest frequency of inventory classification.
在这里,我们使用一种简单的方法:用0填充缺失的值,或者用客户代码的缺失的值删除行。
[En]
Here we use a simple approach: populate the missing value with 0 or delete the row with the missing value of the customer code.
#用0填充缺失值
sale["客户名称"]=sale["客户名称"].fillna(0)
#删除有客户编码缺失值的行
sale.dropna(subset=["客户编码"])
10、数据分列
需求
将日期与时间分列
sale=pd.merge(sale,pd.DataFrame(sale["单据日期"].str.split(" ",expand=True)),how="inner",left_index=True,right_index=True)
11、 模糊筛选数据
需求
筛选存货名称含有”三星”或则含有”索尼”的信息
sale.loc[sale["存货名称"].str.contains("三星|索尼")]
12、删除数据间的空格
需求
删除存货名称两边的空格
sale["存货名称"].map(lambda s :s.strip(""))
13、根据业务逻辑定义标签
需求
销售利润率(即利润/订单金额)大于30%的商品信息并标记它为优质商品,小于5%为一般商品。
sale.loc[(sale["利润"]/sale["订单金额"])>0.3,"label"]="优质商品"
sale.loc[(sale["利润"]/sale["订单金额"])"label"]="一般商品"
14、多条件筛选
需求
想认识业务员张艾,北京地区销售的商品订单量是6000多件。
[En]
Want to know the salesman Zhang Ai, the order amount of goods sold in Beijing area is more than 6000.
sale.loc[(sale["地区名称"]=="北京")&(sale["业务员名称"]=="张爱")&(sale["订单金额"]>5000)]
这里只是列举了一些比较常用的,但是excel常用的操作还有很多,如果还想实现哪些操作,大家可以在评论区一起交流。大家如果对这这些操作有更好的写法,也可以在评论区一起交流!感谢!

.
Original: https://www.cnblogs.com/hahaa/p/15414338.html
Author: 轻松学Python
Title: Python处理Excel,学会这十四个方法,工作量减少大半!
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/511118/
转载文章受原作者版权保护。转载请注明原作者出处!