

序言:保存数据的方式各种各样,最简单的方式是直接保存为文本文件,如TXT、JSON、CSV等,除此之外Excel也是现在比较流行的存储格式,通过这篇文章你也将掌握通过一些第三方库(xlrd/xlwt/pandas/openpyxl)去操作Excel进行数据存储与读取,此一文足以!
一、 TXT文本存储
1.1 使用方式
TXT文本几乎兼容任何平台,但是不利于检索,如果对检索和数据结构要求不高,寻求方便的话,可以采用TXT文本存储格式
1.2 基本写法
1 file = open('demo.txt','a',encoding='utf-8')
2 file.write(data)
3 file.close()
open()方法第一个参数表示要保存的目标文件名称,也可指定绝对路径,第二个参数a表示以追加的方式写入到文本,这样前面写入的内容就不会被覆盖,在爬虫中一般使用的都是这种追加的方式。第三个参数指定文件的编码为utf-8,接着写入数据,最后用close()方法来关闭文件
1.3 打开方式
上面的参数a表示每次写入文本时不会清空之前写入的数据,而是在文本末尾写入新的数据,这是一种打开方式,还有其他打开文件的方式:
r 以只读方式打开文件rb 以二进制只读方式打开一个文件r+以读写方式打开一个文件rb+以二进制读写方式打开一个文件w 以写入方式打开文件wb 以二进制写入方式打开一个文件w+以读写方式打开一个文件wb+以二进制读写方式打开一个文件a 以追加方式打开一个文件ab 以二进制追加方式打开一个文件a+以读写方式打开一个文件ab+以二进制追加方式打开一个文件
上面的b表示二进制,+表示以读写方式,r表示读,w表示写
1.4 简化写法
用with as 语法来写入数据,文件会自动关闭,就不需要调用close()方法了,简写如下:
1 with open('demo.txt','a',encoding='utf-8') as f:
2 f.write(data)
二、 JSON文件存储
2.1 适用方式
JSON,全称为JavaScript Object Notation,也就是JavaScript对象标记,构造简洁但是结构化程度非常高,采用对象和数组的组合来表示数据,是一种轻量级的数据交换格式,和XML有点类似,如果对数据结构有要求的话,可根据需求考虑此种方式
2.2 基本写法
Python提供了json库来实现对json文件的读写操作,通过调用json库的loads()方法可以将json文本字符串转换为json对象,而调用dumps()方法可以将json对象转换为文本字符串,如下:
1 import json
2
3 with open('demo.json','w',encoding='utf-8') as f:
4 f.write(json.dumps(data,indent=2,ensure_ascii=False))
1 import json
2
3 with open('demo.json','r',encoding='utf-8') as f:
4 data = f.read()
5 data = json.loads(data)
6 price = data.get('price')
7 location = data.get('location')
8 size = data.get('size')
indent代表缩进字符个数,ensure_ascii=False规定文件输出的编码,这样就可以输出中文
注意:JSON的数据需要用双引号来包围,不能使用单引号,代码如下:
1 [
2 {
3 "name":"makerchen',
4 "gender":"male",
5 "hobby":"running"
6 }
7 ]
2.3 以TXT格式存储JSON数据
如果我们想要把数据存储为TXT格式,又想要把数据变为json这样的结构,可以这样实现:
1 import json
2
3 with open('demo.txt','a',encoding='utf-8') as f:
4 f.write(json.dumps(data,indent=4,ensure_ascii=False) + '\n')
三、 CSV文件存储
3.1 适用方式
CSV,全称为Comma-Separated Values,中文名可以叫做字符分隔值或逗号分隔值,以纯文本形式存储表格数据,文本默认以逗号分隔,CSV相当于一个结构化表的纯文本形式,比Excel文件更加简洁,保存数据非常方便
3.2 单行写入
1 import csv
2
3 with open('demo.csv','w',encoding='utf-8') as csvf:
4 writer = csv.writer(csvf)
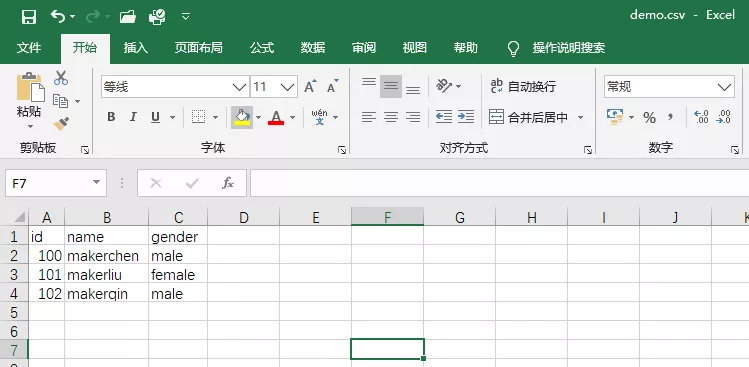
5 writer.writerow(['id','name','gender'])
6 writer.writerow(['100','makerchen','male'])
7 writer.writerow(['101','makerliu','female'])
8 writer.writerow(['102','makerqin','male'])
首先调用csv库的writer()方法初始化写入对象,然后再调用writerow()方法传入每行的数据即可完成写入
Excel效果如下:

如果想修改列与列之间的分隔符,可以传入参数delimiter,代码如下:
1 import csv
2
3 with open('demo.csv','w',encoding='utf-8') as csvf:
4 writer = csv.writer(csvf,delimiter=' ')
5 writer.writerow(['id','name','gender'])
6 writer.writerow(['100','makerchen','male'])
7 writer.writerow(['101','makerliu','female'])
8 writer.writerow(['102','makerqin','male'])
在这里,每列数据都用空格分隔。
[En]
Here, each column of data is separated by spaces.
3.3 多行写入
调用writerows()方法就可以同时写入多行,此时参数需要为二维列表,代码如下:
1 import csv
2
3 with open('demo.csv','w',encoding='utf-8') as csvf:
4 writer = csv.writer(csvf)
5 writer.writerow(['id','name','gender'])
6 writer.writerows(['100','makerchen','male'],
7 ['101','makerliu','female'],['102','makerqin','male'])
3.4 字典写入
一般而言,爬虫提取的数据是结构化数据,通常在词典中表示。代码如下:
[En]
In general, the data extracted by the crawler is structured data, which is generally expressed in a dictionary. The code is as follows:
1 import csv
2
3 with open('demo.csv','w',encoding='utf-8') as csvf:
4 fieldnames = ['id','name','gender']
5 writer = csv.DictWriter(csvf,fieldnames=fieldnames)
6 writer.writeheader()
7 writer.writerow({'id':'100','name':'makerchen','gender':'male'})
8 writer.writerow({'id':'101','name':'makerliu','gender':'female'})
9 writer.writerow({'id':'102','name':'makerqin','gender':'male'})
首先用fieldnames定义头信息,然后将其传给DictWriter来初始化一个字典写入对象,接着用writeheader()方法写入头信息,最后调用writerow()方法传入字典即可
如果想追加写入的话,可将open()方法的第二个参数改为a,代码如下:
1 with open('demo.csv','a',encoding='utf-8') as csvf
3.5 读取CSV文件
我们可以读出我们刚刚写的文件的内容。代码如下:
[En]
We can read out the contents of the file we just wrote. The code is as follows:
1 import csv
2
3 with open('demo.csv','r',encoding='utf-8') as csvf:
4 datas = csv.reader(csvf)
5 for data in datas:
6 print(data)
输出结果如下:
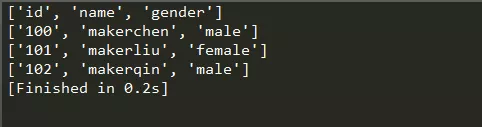
通过遍历输出每行,每行都以列表的形式输出
[En]
Output each line by traversing, each line in the form of a list
注意:如果CSV文件中包含中文的话,还需要指定文件编码
当然也可以用pandas库中的read_csv()方法将数据从CSV中读取出来:
1 import pandas as pd
2
3 data = pd.read_csv('demo.csv')
4 print(data)
此种方式在做数据分析的时候用的比较多,也是一种比较方便读取CVS文件的方法
四、 Excel文件存储
4.1 xlwt数据写入
Excel文件中包含了文本、数值、公式和格式等内容,而CSV不包含这些,默认打开编码为Unicode,是现在比较流行的数据存储格式
基本写入方式
这里我们调用xlwt库进行Excel的数据写入,代码如下:
1 import xlwt
2
3 file = xlwt.Workbook(encoding='utf-8')
4 table = file.add_sheet('data')
5 datas = [
6 ['python实习生','贵阳','本科'],
7 ['java实习生','杭州','本科'],
8 ['爬虫工程师','成都市','硕士']
9 ]
10 for i,p in enumerate(datas):
11 for j,q in enumerate(p):
12 table.write(i,j,q)
13 file.save('demo.xls')
我们首先导入xlwt库,然后调用Workbook()方法初始化一个可以操纵Excel表格的对象,并指定编码格式为utf-8,接着再创建一个我们要写入数据的指定表,用列表的形式创建二维数组,再用两个for循环指定我们要添加数据的位置,这里的i表示外层列表元素所在位置的序号,j表示里层列表元素所在位置的序号,p和q分别表示外层列表和里层列表的元素值,table.write(i,j,q)表示在第i行和第j列插入数据q,最后保存Excel文件。
运行效果如下:
带序号的写入方式
代码如下:
1 import xlwt
2
3 file = xlwt.Workbook(encoding = 'utf-8')
4 table = file.add_sheet('data')
5 data = {
6 "1":['python实习生','贵阳','本科'],
7 "2":['java实习生','杭州','本科'],
8 "3":['爬虫工程师','成都市','硕士']
9 }
10 ldata = []
11 num = [a for a in data]
12 #for循环指定取出key值存入num中,也就是序号
13 num.sort()
14 print(num)
15 #字典数据取出后需要先排序,避免序号混乱
16 for x in num:
17 #for循环将data字典中的键和值分批的保存在ldata中
18 t = [int(x)]
19 for a in data[x]:
20 print(t)
21 t.append(a)
22 print(t)
23 ldata.append(t)
24 print(ldata)
25
26 for i,p in enumerate(ldata):
27 #将数据写入文件,i,j是enumerate()函数返回的序号数
28 for j,q in enumerate(p):
29 # print i,j,q
30 table.write(i,j,q)
31 file.save('demo.xls')
控制台输出如下:
从上图看,num就是一个带有序号的列表,其值是data中的key,t是一个列表,并且它的第一个值也就是序号我们把它强制转换成了整型,然后利用for循环遍历data中value的每个字段值,并把这些字段值依次添加到列表t中;因为后面我们要以二维数组的形式把数据插入到Excel中,才能定位插入的位置,所以需要再构建一个列表ldata,最后再把列表t添加到列表ldata中,这样就构成了二维数组,后面的写法和上面的第一种写法一样
Excel效果如下:
注意:由于xlwt支持的Excel版本兼容问题,只支持Excel 97-2003(.xls),不支持Excel 2010(.xlsx)和Excel 2016(*.xlsx)的,所以在保存时后缀需为.xls,否则可能会有如下错误提示:
4.2 xlrd数据读取
这里我们用刚刚写入的数据demo.xls进行读取,代码如下:
1 import xlrd
2
3 def read(xlsfile):
4 file = xlrd.open_workbook(xlsfile) # 得到Excel文件的book对象,实例化对象
5 sheet0 = file.sheet_by_index(0) # 通过sheet索引获得sheet对象
6 # sheet1 = book.sheet_by_name(sheet_name) # 通过sheet名字来获取,当然如果知道sheet名字就可以直接指定
7 nrows = sheet0.nrows # 获取行总数
8 ncols = sheet0.ncols # 获取列总数
9 list = []
10 for i in range(nrows):
11 list.append([])
12 for j in range(ncols):
13 # print(sheet0.cell_value(i, j))
14 list[i].append(str(sheet0.cell_value(i, j)))
15 print(list)
16 return list
17
18
19 def excel_to_data():
20 list = read('demo.xls')
21 for lis in list:
22 print(lis)
23
24 if __name__ == '__main__':
25 excel_to_data()
首先调用xlrd的open_workbook()方法创建操纵Excel文件的对象,然后通过sheet_by_index(index)方法或者sheet_by_name(sheet_name)方法根据索引、sheet名获取sheet对象,然后获取数据的总行数以及总列数,通过两个for循环,调用sheet对象的cell_value(i, j)获取单元格的值,强制转换成字符串类型之后再根据索引添加到列表list中,以此构成二维数组,输出并返回,最后再遍历二维数组的每个元素(每个列表)进行输出即可
控制台输出如下:
注意:xlrd支持对后缀为.xls以及.xlsx的Excel文件的读取;并且不论是xlwt还是xlrd,数据的起始索引位置都为0
4.3 pandas写入或读取Excel
pandas读取
我们还是用上面的demo.xls进行操作:
1 import pandas as pd
2
3 data = pd.read_excel('demo.xls')
4 print(data)
5 print(type(data))
让我们来看看控制台的输出:
[En]
Let’s take a look at the console output:
我们可以观察看,通过pandas库的read_excel()方法,看起来好像更简单,但它更偏向于数据分析,注意数据类型为DataFrame,输出的数据中带有序号
pandas写入
1 import pandas as pd
2
3 data = pd.DataFrame([['python实习生','贵阳','本科'],['java实习生','杭州','本科'],['爬虫工程师','成都市','硕士']])
4 data.to_excel('demo.xlsx')
Excel效果如下:
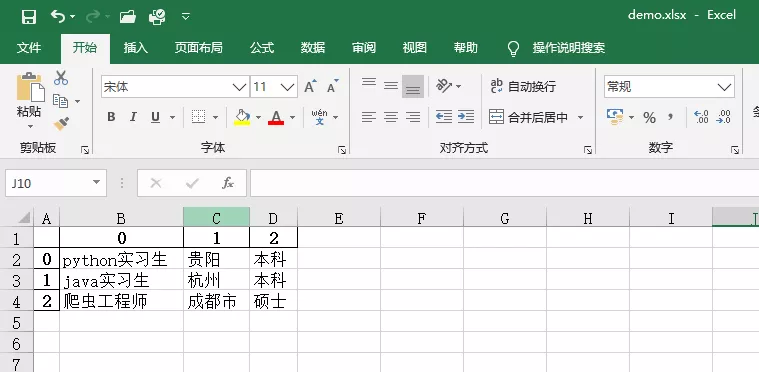
以pandas库的DataFrame()方法存储的数据都是带有索引序号的,方便进行数据分析、建模等
注意:pandas库支持后缀为.xlsx的Excel表格
4.4 openpyxl 写入或读取Excel
openpyxl写入
1 import openpyxl
2
3 wb = openpyxl.Workbook()
4 ws = wb.create_sheet('data')
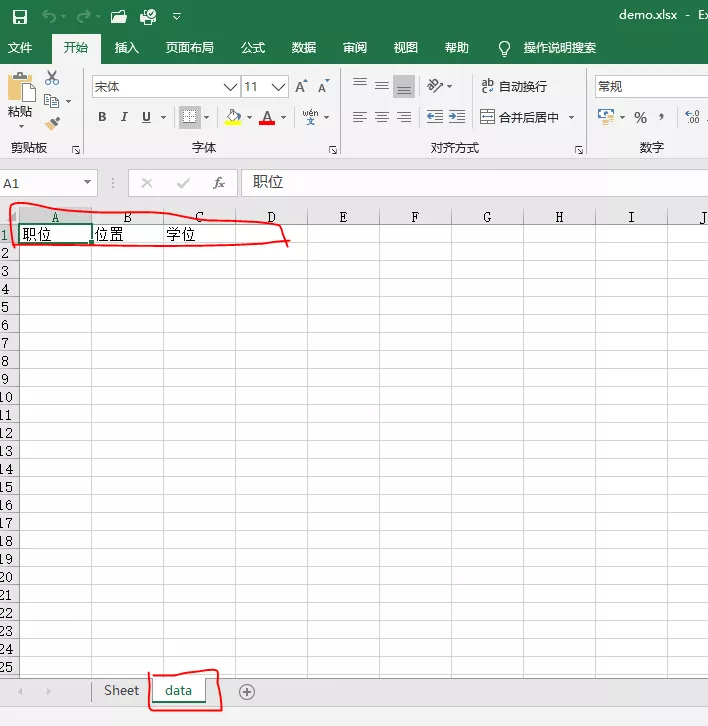
5 ws.cell(row=1,column=1).value="职位"
6 ws.cell(row=1,column=2).value="位置"
7 ws.cell(row=1,column=3).value="学位"
8 wb.save('demo.xlsx')
Excel效果如下:
openpyxl读取
1 import openpyxl
2
3 wb = openpyxl.load_workbook('demo.xlsx')
4 ws = wb.get_sheet_by_name('data')
5 rows = ws.max_row
6 columns = ws.max_column
7 datas = []
8 for i in range(1,rows+1):
9 for j in range(1,columns+1):
10 datas.append(str(ws.cell(i,j).value))
11 print(datas)
控制台输出如下:
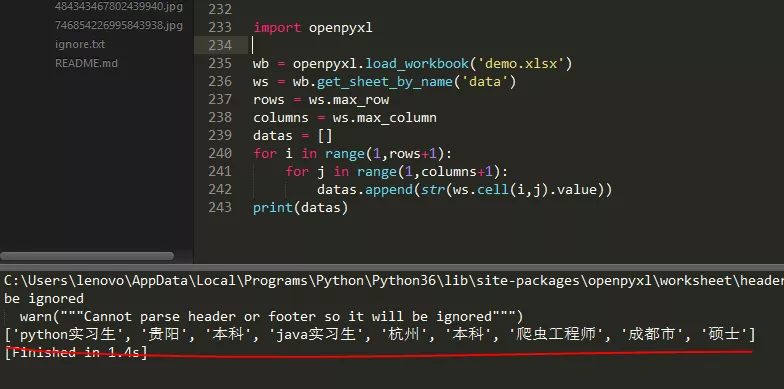
注意:openpyxl只支持后缀为.xlsx的Excel文件,并且读取或写入数据的索引位置均为1
个人推荐使用xlrd和xlwt以及pandas,这些库操作Excel文件时数据的起始索引位置都为0,比较方便,不过也可以根据个人使用习惯以及需求来决定
原创不易,如果觉得有点用,希望可以随手点个赞,拜谢各位老铁!
五、作者Info
作者:南柯树下,Goal:让编程更有趣!
原创微信公众号:『 小鸿星空科技』,专注于算法、爬虫,网站,游戏开发,数据分析、自然语言处理,AI等,期待你的关注,让我们一起成长、一起Coding!
转载说明:本文禁止抄袭和转载,侵权行为必须追究!
[En]
Reprint description: plagiarism and reprint are prohibited in this article, infringement must be investigated!
更多独家 精彩内容 请扫码关注 个人公众号 , 我们 一起成长,一起Coding,让编程更有趣!
—— —— —— —— — END —— —— —— —— ————
欢迎扫码关注我的公众号
小鸿星空科技

Original: https://www.cnblogs.com/makerchen/p/15509781.html
Author: 南柯树下
Title: Python常用的数据文件存储格式大全(2021最新/最全/最详细版)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/510846/
转载文章受原作者版权保护。转载请注明原作者出处!