

文章目录
*
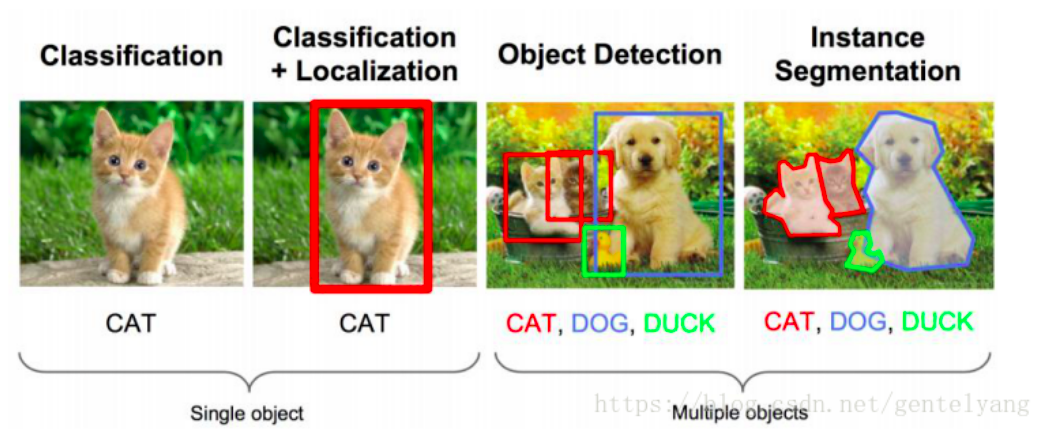
– 目标检测任务:
– 【NMS】
– 【RCNN:Regions with CNN features】
– 【fast RCNN】
– 【faster RCNN】
– 【SPPNet:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition】
– 【selective search】
– 【FPN: feature pyramid network】
– 【YOLO】
– 【SSD】
– 【小目标检测】
目标检测任务:

; 【NMS】
CSDN:https://blog.csdn.net/a1103688841/article/details/89711120
softNMS:https://github.com/bharatsingh430/soft-nms/blob/master/lib/nms/cpu_nms.pyx
import numpy as np
def py_cpu_nms(dets, thresh):
"""Pure Python NMS baseline."""
x1 = dets[:, 0]
y1 = dets[:, 1]
x2 = dets[:, 2]
y2 = dets[:, 3]
scores = dets[:, 4]
areas = (x2 - x1 + 1) * (y2 - y1 + 1)
order = scores.argsort()[::-1]
keep = []
while order.size > 0:
i = order[0]
keep.append(i)
xx1 = np.maximum(x1[i], x1[order[1:]])
yy1 = np.maximum(y1[i], y1[order[1:]])
xx2 = np.minimum(x2[i], x2[order[1:]])
yy2 = np.minimum(y2[i], y2[order[1:]])
w = np.maximum(0.0, xx2 - xx1 + 1)
h = np.maximum(0.0, yy2 - yy1 + 1)
inter = w * h
ovr = inter / (areas[i] + areas[order[1:]] - inter)
inds = np.where(ovr thresh)[0]
order = order[inds + 1]
return keep
【RCNN:Regions with CNN features】
知乎:https://zhuanlan.zhihu.com/p/23006190
RCNN的输入为完整图片,首先通过区域建议算法产生一系列的候选目标区域,其中使用的区域建议算法为Selective Search。
然后对于这些目标区域候选提取其CNN特征,并训练SVM分类这些特征。
最后为了提高定位的准确性在SVM分类后区域基础上进行BoundingBox回归。
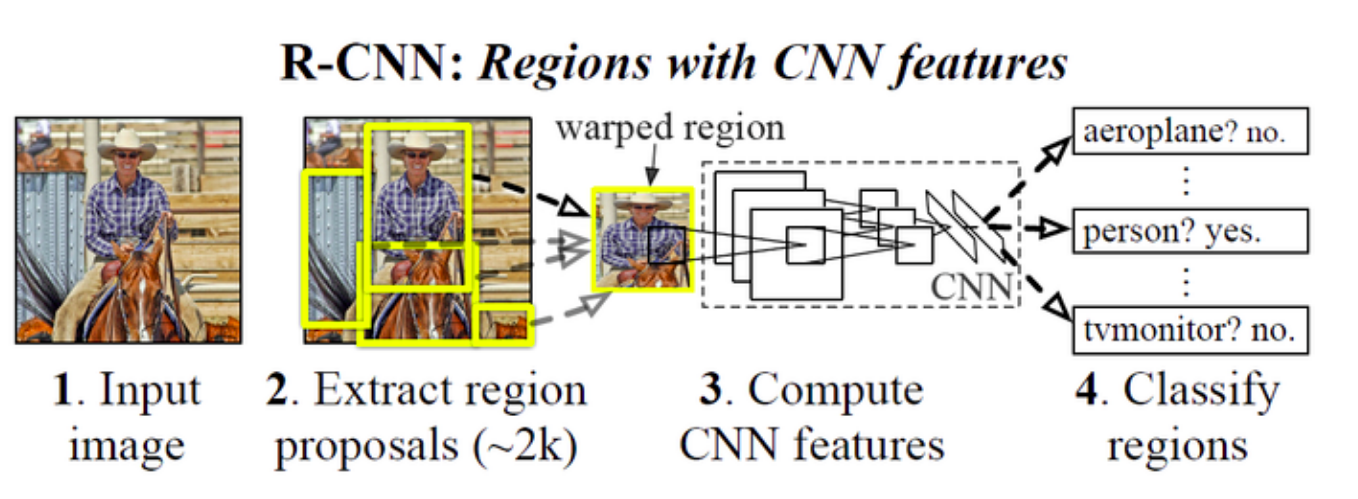
RCNN算法分为4个步骤
(1)候选区域生成: 一张图像生成1K~2K个候选区域 (采用Selective Search 方法)
(2)特征提取: 对每个候选区域,使用深度卷积网络提取特征 (CNN)
(3)类别判断: 特征送入每一类的SVM 分类器,判别是否属于该类
(4)位置精修: 使用回归器精细修正候选框位置
1、产生目标区域候选
这部分其实就是直接使用Selective Search,选择2K个置信度最高的区域候选。
使用一种过分割手段,将图像分割成小区域 (1k~2k 个)
查看现有的小区域,并根据合并规则合并最有可能相邻的两个区域。重复该操作,直到整个图像合并到一个区域位置
[En]
Look at the existing small areas and merge the two most likely adjacent areas according to the merge rules. Repeat until the whole image is merged into one region position
输出所有曾经存在的区域,即所谓的候选区域
[En]
Output all the regions that once existed, the so-called candidate regions
其中合并规则如下: 优先合并以下四种区域:
颜色相似(颜色直方图)
[En]
Similar in color (color histogram)
纹理相似(渐变直方图)
[En]
Similar in texture (gradient histogram)
合并后总面积小的: 保证合并操作的尺度较为均匀,避免一个大区域陆续”吃掉”其他小区域 (例:设有区域a-b-c-d-e-f-g-h。较好的合并方式是:ab-cd-ef-gh -> abcd-efgh -> abcdefgh。 不好的合并方法是:ab-c-d-e-f-g-h ->abcd-e-f-g-h ->abcdef-gh -> abcdefgh)
合并后,总面积在其BBOX中所占比例大的: 保证合并后形状规则。
然而CNN对输入图片的大小是有固定的,如果把搜索到的矩形选框不做处理,就扔进CNN中,肯定不行。因此对于每个输入的候选框都需要缩放到固定的大小。
一张照片我们得到了2000个候选框。然而人工标注的数据一张图片中就只标注了正确的bounding box,我们搜索出来的2000个矩形框也不可能会出现一个与人工标注完全匹配的候选框。
因此在CNN阶段我们需要用IOU为2000个bounding box打标签。
如果用selective search挑选出来的候选框与物体的人工标注矩形框(PASCAL VOC的图片都有人工标注)的重叠区域IoU大于0.5,那么我们就把这个候选框标注成物体类别(正样本),否则我们就把它当做背景类别(负样本)。
2、CNN预训练
网络结构是基本借鉴Hinton 2012年在Image Net上的分类网络Alexnet
所谓的有监督预训练也可以把它称之为迁移学习。比如你已经有一大堆标注好的人脸年龄分类的图片数据,训练了一个CNN,用于人脸的年龄识别。
然后当你遇到新的项目任务时:人脸性别识别,那么这个时候你可以利用已经训练好的年龄识别CNN模型,去掉最后一层,然后其它的网络层参数就直接复制过来,继续进行训练,让它输出性别。
这就是所谓的迁移学习。简单地说,与直接随机初始化的方法相比,它将一个任务对另一个任务的训练参数作为神经网络的初始参数。精确度可以大大提高。
[En]
This is the so-called transfer learning. to put it simply, it takes the trained parameters of one task to another task as the initial parameters of the neural network, compared with the method of random initialization directly. The accuracy can be greatly improved.
对于目标检测问题: 图片分类标注好的训练数据非常多,但是物体检测的标注数据却很少,如何用少量的标注数据,训练高质量的模型,这就是文献最大的特点,
这篇论文采用了迁移学习的思想: 先用了ILSVRC2012这个训练数据库(这是一个图片分类训练数据库),先进行网络图片分类训练。
这个数据库有大量的标注数据,共包含了1000种类别物体,因此预训练阶段CNN模型的输出是1000个神经元(当然也直接可以采用Alexnet训练好的模型参数)。
我们接着采用 selective search 搜索出来的候选框 (PASCAL VOC 数据库中的图片) 继续对上面预训练的CNN模型进行fine-tuning训练。
假设要检测的物体类别有N类,那么我们就需要把上面预训练阶段的CNN模型的最后一层给替换掉,替换成N+1个输出的神经元(加1,表示还有一个背景) (20 + 1bg = 21)
3、IOU
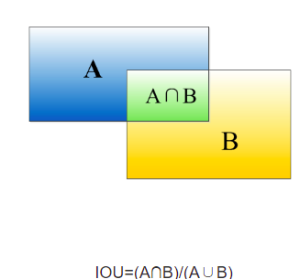
物体检测需要定位出物体的bounding box,就像下面的图片一样,我们不仅要定位出车辆的bounding box 我们还要识别出bounding box 里面的物体就是车辆。
对于bounding box的定位精度,有一个很重要的概念: 因为我们算法不可能百分百跟人工标注的数据完全匹配,因此就存在一个定位精度评价公式:IOU。
4、SVM训练
疑惑点: CNN训练的时候,本来就是对bounding box的物体进行识别分类训练,在训练的时候最后一层softmax就是分类层。那么为什么作者闲着没事干要先用CNN做特征提取(提取fc7层数据),然后再把提取的特征用于训练svm分类器?
这个是因为svm训练和cnn训练过程的正负样本定义方式各有不同,导致最后采用CNN softmax输出比采用svm精度还低。事情是这样的,cnn在训练的时候,对训练数据做了比较宽松的标注,比如一个bounding box可能只包含物体的一部分,那么我也把它标注为正样本,用于训练cnn;采用这个方法的主要原因在于因为CNN容易过拟合,所以需要大量的训练数据,所以在CNN训练阶段我们是对Bounding box的位置限制条件限制的比较松(IOU只要大于0.5都被标注为正样本了);然而svm训练的时候,因为svm适用于少样本训练,所以对于训练样本数据的IOU要求比较严格,我们只有当bounding box把整个物体都包含进去了,我们才把它标注为物体类别,然后训练svm。
这是一个二分类问题,我么假设我们要检测车辆。我们知道只有当bounding box把整量车都包含在内,那才叫正样本;如果bounding box 没有包含到车辆,那么我们就可以把它当做负样本。
但问题是当我们的检测窗口只有部分包含物体,那该怎么定义正负样本呢?作者测试了IOU阈值各种方案数值0,0.1,0.2,0.3,0.4,0.5。
最后通过训练发现,如果选择IOU阈值为0.3效果最好(选择为0精度下降了4个百分点,选择0.5精度下降了5个百分点),即当重叠度小于0.3的时候,我们就把它标注为负样本。
一旦CNN f7层特征被提取出来,那么我们将为每个物体类训练一个svm分类器。当我们用CNN提取2000个候选框,可以得到2000 _4096这样的特征向量矩阵,然后我们只需要把这样的一个矩阵与svm权值矩阵4096_N点乘(N为分类类别数目,因为我们训练的N个svm,每个svm包含了4096个权值w),就可以得到结果了。
5、NMS

非极大值抑制(NMS):
RCNN会从一张图片中找出n个可能是物体的矩形框,然后为每个矩形框为做类别分类概率:
就像上图一样,找到一辆车,最后算法找到一堆盒子,我们需要确定哪些矩形是无用的。
[En]
Just like the picture above, locate a vehicle, and finally the algorithm finds a bunch of boxes, and we need to determine which rectangles are useless.
非极大值抑制的方法是:先假设有6个矩形框,根据分类器的类别分类概率做排序,假设从小到大属于车辆的概率 分别为A、B、C、D、E、F。
(1)从最大概率矩形框F开始,分别判断A~E与F的重叠度IOU是否大于某个设定的阈值;
(2)假设B、D与F的重叠度超过阈值,那么就扔掉B、D;并标记第一个矩形框F,是我们保留下来的。
(3)从剩下的矩形框A、C、E中,选择概率最大的E,然后判断E与A、C的重叠度,重叠度大于一定的阈值,那么就扔掉;并标记E是我们保留下来的第二个矩形框。
只要继续重复,找到所有被保存下来的矩形。
[En]
Just keep repeating it, finding all the rectangles that have been preserved.
非极大值抑制(NMS)顾名思义就是抑制不是极大值的元素,搜索局部的极大值。这个局部代表的是一个邻域,邻域有两个参数可变,一是邻域的维数,二是邻域的大小。这里不讨论通用的NMS算法,而是用于在目标检测中用于提取分数最高的窗口的。例如在行人检测中,滑动窗口经提取特征,经分类器分类识别后,每个窗口都会得到一个分数。但是滑动窗口会导致很多窗口与其他窗口存在包含或者大部分交叉的情况。这时就需要用到NMS来选取那些邻域里分数最高(是行人的概率最大),并且抑制那些分数低的窗口。
6、回归器修正bbox位置
目标检测问题的衡量标准是重叠面积(IoU),许多看似准确的检测结果,往往因为候选框不够准确,重叠面积很小。故需要一个位置精修步骤。 对每一类目标,使用一个线性脊回归器进行精修。正则项λ=10000。
输入为深度网络pool5层的4096维特征,输出为xy方向的缩放和平移。
训练样本 叠面积大于0.6的候选框。
7、存在的问题
时间代价太高
网络训练是分阶段
; 【fast RCNN】
知乎:https://zhuanlan.zhihu.com/p/24780395
https://zhuanlan.zhihu.com/p/61611588
https://blog.csdn.net/shenxiaolu1984/article/details/51036677
1、RCNN不足
1、训练分多步。通过上一篇博文我们知道R-CNN的训练先要fine tuning一个预训练的网络,然后针对每个类别都训练一个SVM分类器,最后还要用regressors对bounding-box进行回归,另外region proposal也要单独用selective search的方式获得,步骤比较繁琐。
2、时间和内存消耗比较大。在训练SVM和回归的时候需要用网络训练的特征作为输入,特征保存在磁盘上再入的时间消耗还是比较大的。
3、测试的时候也比较慢,每张图片的每个region proposal都要做卷积,重复操作太多
针对上诉问题进行改进:
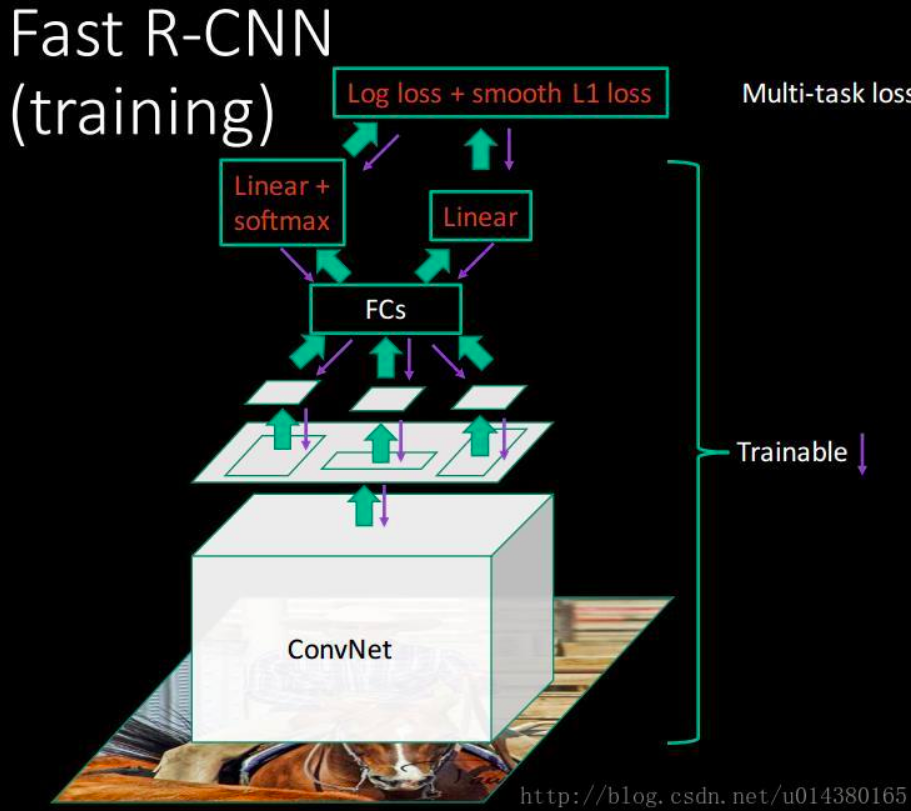
Q1:将整张图片归一化送入神经网络,在最后一层再加入候选框信息(这些候选框还是经过 提取,再经过一个 层统一映射到最后一层特征图上,而RCNN是通过拉伸来归一化尺寸),这样提取特征的前面层就不再需要重复计算。
Q2:损失函数使用了多任务损失函数(multi-task loss),将边框回归直接加入到CNN网络中训练。 网络结构如下
2、算法
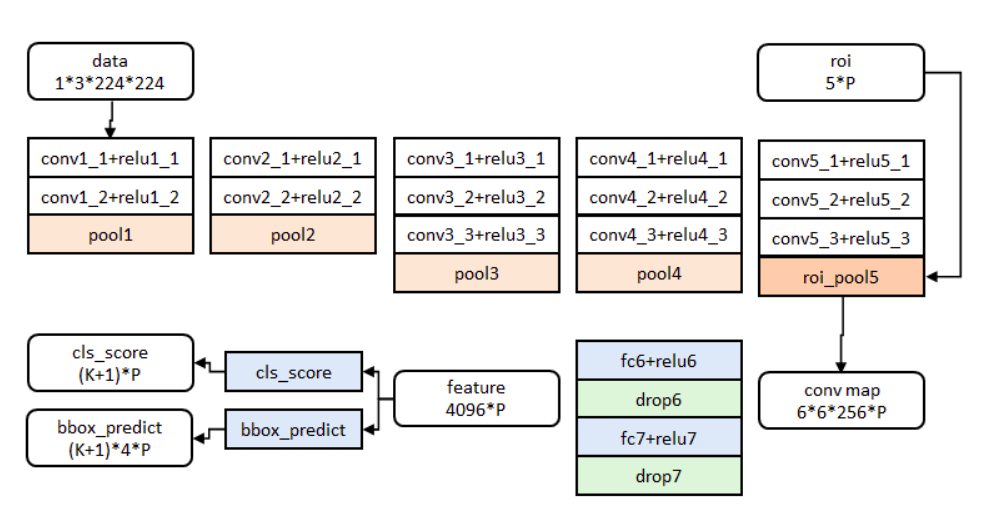
Fast R-CNN网络将整个图像和一组候选框作为输入。
首先,网络使用卷积层和最大池层对整幅图像进行处理,生成卷积特征图。
[En]
First of all, the network uses the convolution layer and the maximum pool layer to process the whole image to produce the convolution feature map.
然后,对于每个候选框,RoI池化层从特征图中提取固定长度的特征向量。
每个特征向量被送入一系列全连接(fc)层中,其最终分支成两个同级输出层 :
(1)一个输出K个类别加上1个背景类别的Softmax概率估计
(2)另一个为K个类别的每一个类别输出四个实数值。每组4个值表示K个类别的一个类别的检测框位置的修正。

3、ROI Pooling
由于region proposal的尺度各不相同,而期望提取出来的特征向量维度相同,因此需要某种特殊的技术来做保证。ROIPooling的提出便是为了解决这一问题的。其思路如下:
将region proposal划分为H×WH×W大小的网格
对每一个网格做MaxPooling(即每一个网格对应一个输出值)
将所有输出值组合起来便形成固定大小为H×WH×W的feature map
4、多任务损失函数

cls_score层用于分类,输出K+1维数组p pp,表示属于K类和背景的概率。
bbox_prdict层用于调整候选区域位置,输出4*K维数组,表示分别属于K类时,应该平移缩放的参数(x/y方向平移/缩放)。
; 【faster RCNN】
知乎:https://zhuanlan.zhihu.com/p/31426458
代码解读(torch):https://zhuanlan.zhihu.com/p/145842317
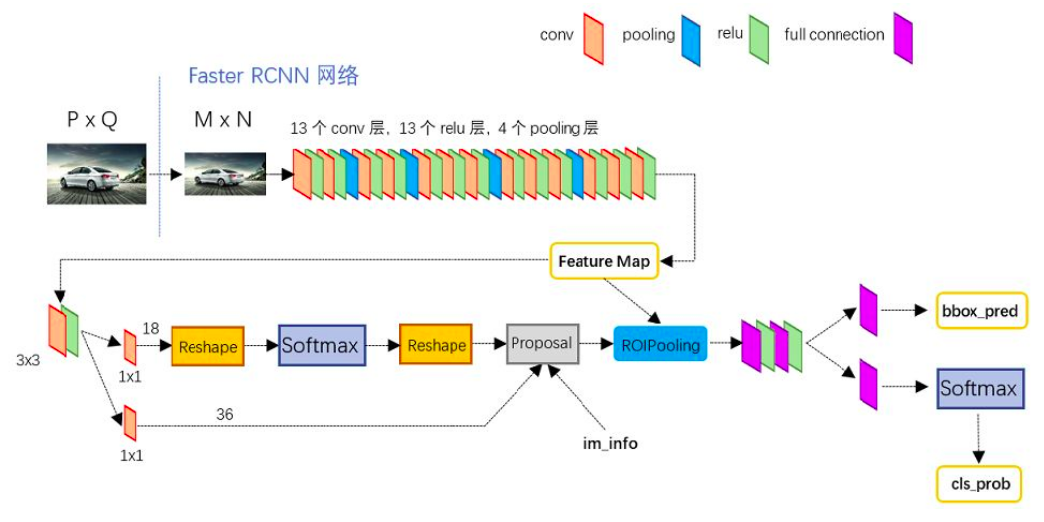
1、Conv layers。
作为一种CNN网络目标检测方法,Faster RCNN首先使用一组基础的conv+relu+pooling层提取image的feature maps。该feature maps被共享用于后续RPN层和全连接层。
2、Region Proposal Networks。
RPN网络用于生成region proposals。该层通过softmax判断anchors属于positive或者negative,再利用bounding box regression修正anchors获得精确的proposals。
3、Roi Pooling。
该层收集输入的feature maps和proposals,综合这些信息后提取proposal feature maps,送入后续全连接层判定目标类别。
4、Classification。
利用proposal feature maps计算proposal的类别,同时再次bounding box regression获得检测框最终的精确位置

; 【SPPNet:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition】
https://www.jianshu.com/p/90f9d41c6436
SPPnet是目标检测领域不可忽略的一篇论文,中国人何恺明大神的作品,阅读起来感觉亲(简)切(单)多了。
在我看来,SPPnet主要有两处亮点
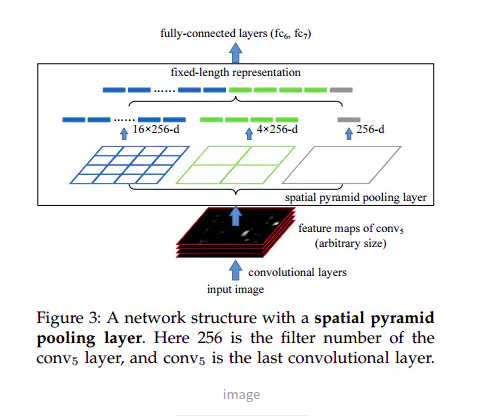
1.它解决了深度卷积神经网络(CNNs)的输入必须要求固定图像尺寸(例如224*224)的限制。
2.在目标检测领域它提高了提取特征的效率,速度相比R-CNN提升24-102倍。
论文中举例:把卷积操作之后的特征图(feature maps),以不同大小的块(池化框)来提取特征,分别是4 * 4,2 * 2,1 * 1,
将这三张网格放到下面这张特征图上,就可以得到16+4+1=21种不同的块(Spatial Bins),我们从这21个块中,每个块提取出一个特征(提取方式有平均池化、最大池化等),这样就得到了固定的21维特征向量。
将不同大小的网格组合在一起的过程就是空间金字塔的汇集。
[En]
The process of pooling with the combination of different sizes of lattices is the pooling of space pyramids.
这么一来,我们只要设计m个n * n大小的网格就可以生成任意维数的特征向量,而不需要在意经过多层卷积操作后的特征图的大小是多少,这也意味着我们不需要在意网络输入的图片尺寸。
; 【selective search】
CSDN:https://blog.csdn.net/u011436429/article/details/80277633
在目标检测中,为了定位目标的具体位置,通常将图像分成多个子块,然后将这些子块作为输入送入目标识别模型。
[En]
In target detection, in order to locate the specific location of the target, the image is usually divided into many sub-blocks, and then the sub-blocks are sent to the target recognition model as input.
分子块最直接的方法是滑动窗口法。滑动窗口的方法是根据子块的大小枚举整个图像上的所有子块。这种方法生成的数据量太大,无法想象。
[En]
The most direct method of molecular blocks is called sliding window method. The way to slide the window is to enumerate all the sub-blocks on the whole image according to the size of the sub-blocks. The amount of data generated by this method is too large to think about.
和滑动窗口法相对的是另外一类基于区域(region proposal)的方法。selective search就是其中之一!
首先通过简单的区域划分算法,将图片划分成很多小区域,再通过相似度和区域大小(小的区域先聚合,这样是防止大的区域不断的聚合小区域,导致层次关系不完全)不断的聚合相邻小区域,类似于聚类的思路。这样就能解决object层次问题。
最后,在计算速度上,只能说这个想法比较详尽,大大减少了后期分类过程中的计算量。
[En]
Finally, in terms of calculation speed, it can only be said that this idea is relatively exhaustive, which greatly reduces the amount of calculation in the later classification process.
1、算法
首先,采用基于图的图像分割方法对原始区域进行初始化,即将图像分成多个小块。
[En]
First of all, the original region is initialized by the graph-based image segmentation method, that is, the image is divided into many small blocks.
然后使用贪婪策略计算每个相邻区域的相似度,然后每次合并最相似的两个片段,直到只剩下一幅完整的图片。
[En]
Then we use the greedy strategy to calculate the similarity of each two adjacent regions, and then merge the two most similar pieces each time, until there is only one complete picture left.
然后保存每次生成的图像块,包括合并后的图像块,这样就可以得到图像的层次表示。
[En]
Then we save the image blocks generated each time, including the merged image blocks, so that we can get a hierarchical representation of the image.
step0:生成区域集R,具体参见论文《Efficient Graph-Based Image Segmentation》
step1:计算区域集R里每个相邻区域的相似度S={s1,s2,…}
step2:找出相似度最高的两个区域,将其合并为新集,添加进R
step3:从S中移除所有与step2中有关的子集
step4:计算新集与所有子集的相似度
step5:跳至step2,直至S为空
2、区域相似度计算
1.颜色距离就是对各个通道计算颜色直方图,然后取各个对应bins的直方图最小值。这样做的话两个区域合并后的直方图也很好计算,直接通过直方图大小加权区域大小然后除以总区域大小就好了。
2.纹理距离计算方式和颜色距离几乎一样,我们计算每个区域的快速sift特征,其中方向个数为8,3个通道,每个通道bins为10,对于每幅图像得到240维的纹理直方图。
3.优先合并小的区域,如果仅仅是通过颜色和纹理特征合并的话,很容易使得合并后的区域不断吞并周围的区域,后果就是多尺度只应用在了那个局部,而不是全局的多尺度。因此我们给小的区域更多的权重,这样保证在图像每个位置都是多尺度的在合并。
4.区域的合适度度距离,不仅要考虑每个区域特征的吻合程度,区域的吻合度也是重要的,吻合度的意思是合并后的区域要尽量规范,不能合并后出现断崖的区域,这样明显不符合常识,体现出来就是区域的外接矩形的重合面积要大。
5.综合各种距离,通过多种策略去得到区域建议,最简单的方法当然是加权。
6.参数初始化多样性,我们基于基于图的图像分割得到初始区域,而这个初始区域对于最终的影响是很大的,因此我们通过多种参数初始化图像分割,也算是扩充了多样性。
3、给区域打分
通过上述步骤,我们可以得到很多地区,但显然不是每个地区都有同样的可能性作为目标,所以我们需要衡量这种可能性。这样,我们就可以根据自己的需求筛选区域建议的数量。
[En]
Through the above steps, we can get a lot of areas, but obviously not every region has the same possibility as a target, so we need to measure this possibility. in this way, we can screen the number of regional suggestions according to our needs.
本文的做法是给首先合并的图像块更多的权重,例如最后一个完整图像的权重为1,倒数第二次合并的区域权重为2,等等。
[En]
The practice of this article is to give more weight to the image blocks that are merged first, such as the weight of the last complete image is 1, the region weight of the penultimate merge is 2, and so on.
但当我们有很多策略和很多多样性时,这个权重会有太多重叠,所以很难排序。文章的方法是将它们乘以一个随机数,毕竟3分取决于运气,然后对在同一区域多次出现的点进行加权。毕竟,有很多方式可以说你是目标,这是有原因的。
[En]
But when we have a lot of strategies and a lot of diversity, there will be too much overlap in this weight, so it’s not easy to sort. The method of the article is to multiply them by a random number, after all, 3 points depends on luck, and then add weights to those that appear many times in the same area. after all, there are many ways to say that you are the target, and there is a reason.
这样,我就得到了所有地区的目标分数,我可以根据自己的需求选择我需要的地区。
[En]
In this way, I get the target score for all areas, and I can choose how many regions I need according to my needs.
【FPN: feature pyramid network】
【YOLO】
https://zhuanlan.zhihu.com/p/25236464
【SSD】
【小目标检测】
【ROI Align】
https://www.cnblogs.com/wangyong/p/8523814.html
https://blog.csdn.net/u011918382/article/details/79455407
Original: https://blog.csdn.net/qq_37435458/article/details/123253389
Author: 今天刷leetcode了吗
Title: 目标检测 Object Detection
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/509580/
转载文章受原作者版权保护。转载请注明原作者出处!