

系列文章
目录
一、项目简介
本文主要介绍如何使用python搭建:一个基于长短期记忆网络(LSTM:Long Short-Term Memory, 简称 LSTM)的 股票、大宗商品预测系统。
项目只是用股票预测作为抛砖引玉,其中包含了使用LSTM进行时序预测的相关代码。主要功能如下:
- 数据预处理。
- 模型构建及训练,使用tensorflow构建LSTM网络。
- 预测股票的时序走势,并评估模型
[En]
predict the timing trend of stocks and evaluate the model.*
如各位童鞋需要更换训练数据,完全可以根据源码将图像和标注文件更换即可直接运行。
博主也参考过网上图像分类的文章,但大多是理论大于方法。很多同学肯定对原理不需要过多了解,只需要搭建出一个预测系统即可。
本文只会告诉你如何快速搭建一个基于LSTM的股票预测系统并运行,原理的东西可以参考其他博主。
正是因为我发现,大部分的网帖都只是针对原理的介绍,实现功能的相对较少。
[En]
It is precisely because I found that most of the online posts are only for the introduction of the principle, the realization of the function is relatively few.
如果你有以上想法,那你来对地方了!
[En]
If you have the above ideas, you are in the right place!
别说太多废话了,开门见山吧!
[En]
Don’t talk too much nonsense, just get to the point!
二、数据集介绍
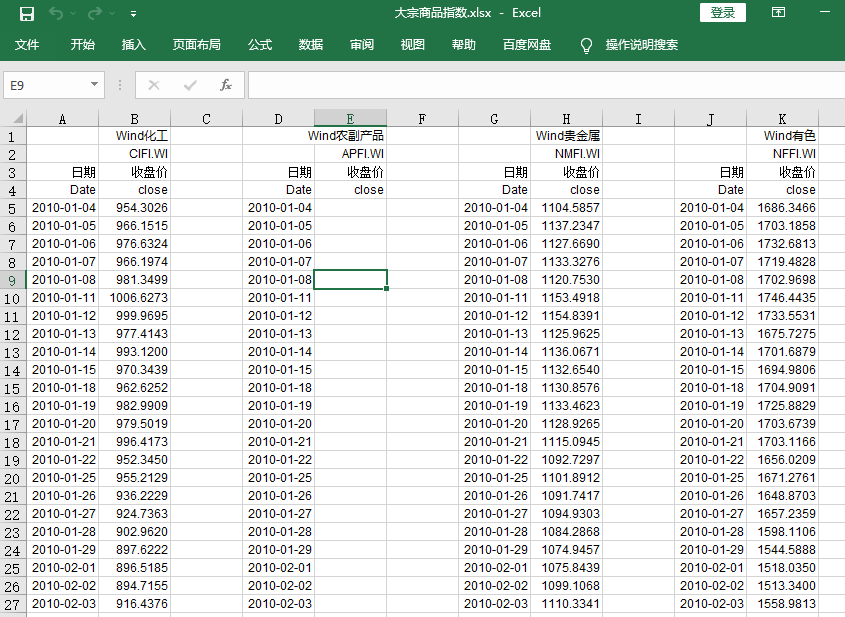
首先,我们这次的工作主要是针对大宗商品指数进行预测,这些指数是:化工、贵金属和有色金属。
[En]
First of all, our work this time is mainly aimed at a forecast of commodity index, which are: chemical industry, precious metals and non-ferrous metals.

- 接下来是模型预测的结果。在这里,我使用:化工产品来观察模型预测的时间序列结果:
[En]
next is the result of the model prediction. Here I use: chemical products to observe the time series results of the model prediction:*
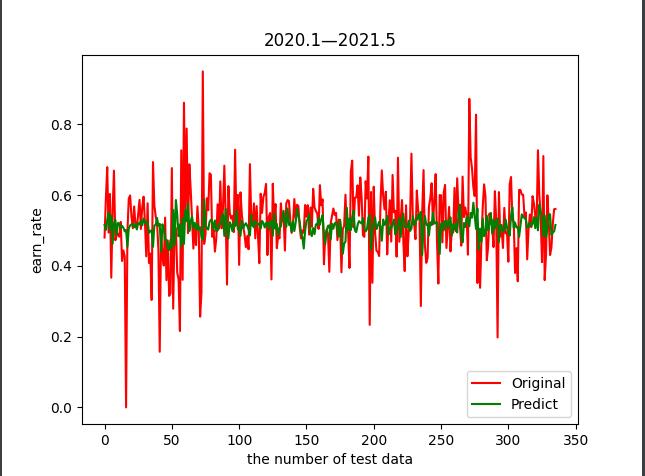
- 可见红色曲线为化工产品时序,绿色曲线为预测
[En]
it can be seen that the red curve is the time sequence of chemical products and the green curve is the prediction.*
; 三、环境安装
1.环境要求
本项目开发IDE使用的是: Pycharm,大家可以直接csdn搜索安装指南非常多,这里就不再赘述。
因为本项目基于TensorFlow因此需要以下环境:
- tensorflow >= 2.0
- pandas
- scikit-learn
- numpy
- matplotlib
- joblib
四、重要代码介绍
环境安装好后就可以打开 pycharm开始愉快的执行代码了。由于代码众多,博客中就不放入最终代码了,有需要的童鞋可以在 博客最下方找到下载地址。
1.数据预处理
- 首先,我们需要将计时问题转化为有监督的学习,然后才能进行培训。以下代码将输入的时间序列的收盘价转换为每日收益率,并将落后一天(默认为一天)的收益率的观测值作为监督学习值。
[En]
first of all, we need to convert the timing problem into supervised learning before we can carry out training. The following code converts the closing price of the entered time series into the daily rate of return and takes the observed value of the rate of return one day behind (the default is one day) as the supervised learning value.*
def series_to_supervised(data, n_in=1, n_out=1, dropnan=True):""" 将时间序列转换为监督学习问题 Arguments: data: 输入数据需要是列表或二维的NumPy数组的观察序列。 n_in: 输入的滞后观察数(X)。值可以在[1..len(data)]之间,可选的。默认为1。 n_out: 输出的观察数(y)。值可以在[0..len(data)-1]之间,可选的。默认为1。 dropnan: Bool值,是否删除具有NaN值的行,可选的。默认为True。 Returns: 用于监督学习的Pandas DataFrame。""" n_vars = 1 if type(data) is list else data.shape[1] df = DataFrame(data) cols, names = list(), list() for i in range(n_in, 0, -1): cols.append(df.shift(i)) names += [('var%d(t-%d)' % (j + 1, i)) for j in range(n_vars)] for i in range(0, n_out): cols.append(df.shift(-i)) if i == 0: names += [('var%d(t)' % (j + 1)) for j in range(n_vars)] else: names += [('var%d(t+%d)' % (j + 1, i)) for j in range(n_vars)] agg = concat(cols, axis=1) agg.columns = names if dropnan: agg.dropna(inplace=True) agg.drop(agg.columns[[6, 8, 10]], axis=1, inplace=True) print("*" * 20) print("完成监督学习转换:") print(agg.head()) return agg- 二是在数据构建完成后,将训练数据与测试数据按一定比例分离。
[En]
the second is to separate the training data from the test data at a certain rate after the data construction is completed.*
2.预测模型构建
- 因为使用的是LSTM做回归预测,因此模型输出应该不是分类的类别,而是回归值。模型构建代码如下:
def model_create(train_X):""" 搭建LSTM模型 :param train_X: :return:""" model = Sequential() model.add(LSTM(64, input_shape=(train_X.shape[1], train_X.shape[2]))) model.add(Dropout(0.5)) model.add(Dense(1, activation='relu')) model.compile(loss='mae', optimizer='adam', metrics=['mse']) return model3.模型训练
3.1 训练参数定义
- 设置批处理batch_size:100,博主总共跑了100个epoch。
callbacks = [ TensorBoard(log_dir=my_log_dir) ] history1 = lstm_gjs.fit(train_x_gjs, train_y_gjs, epochs=100, batch_size=100, validation_data=(test_x_gjs, test_y_gjs), callbacks=callbacks, verbose=2, shuffle=False) lstm_gjs.save_weights('models/' + 'model_lstm_gjs.tf')3.2 训练loss及MSE
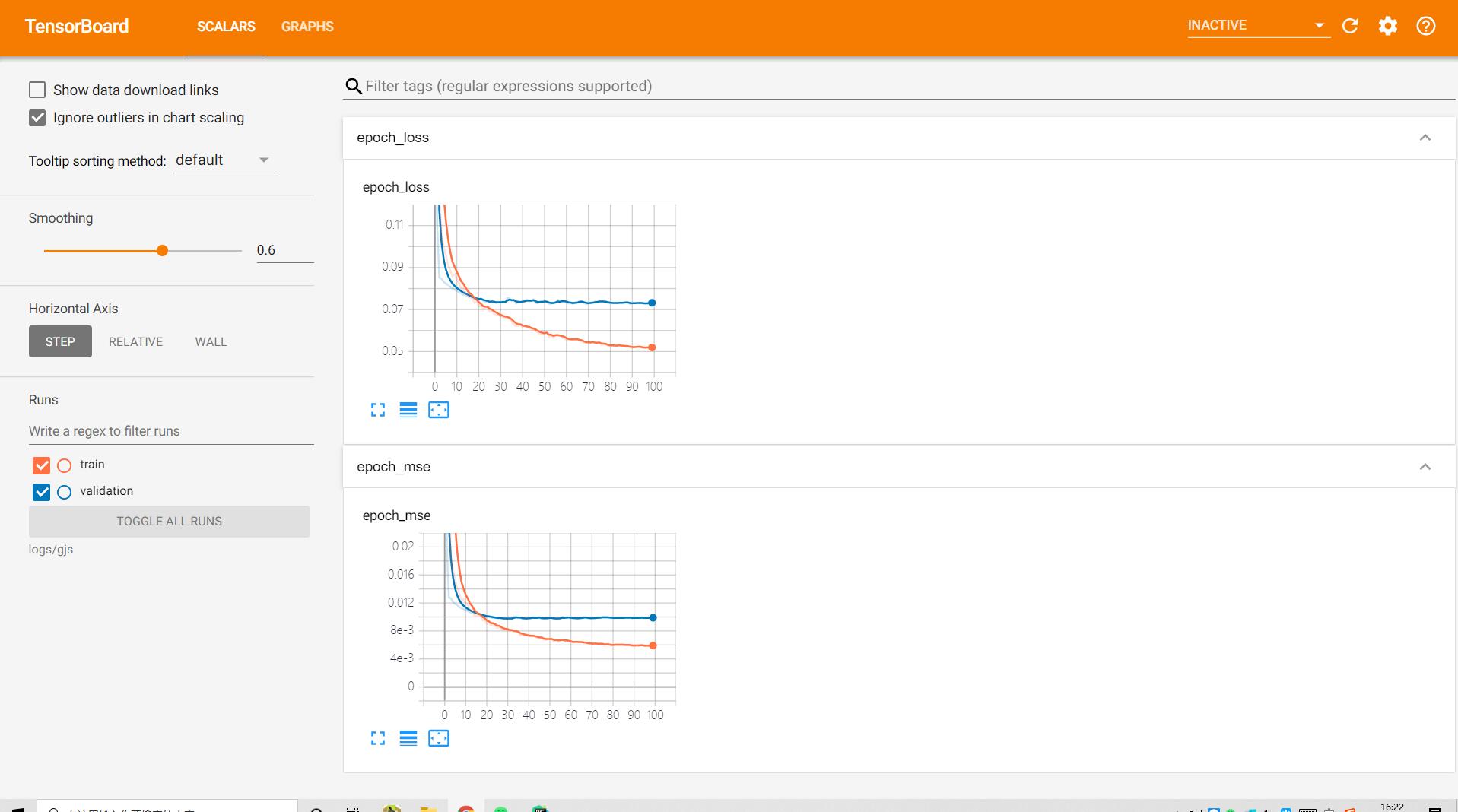
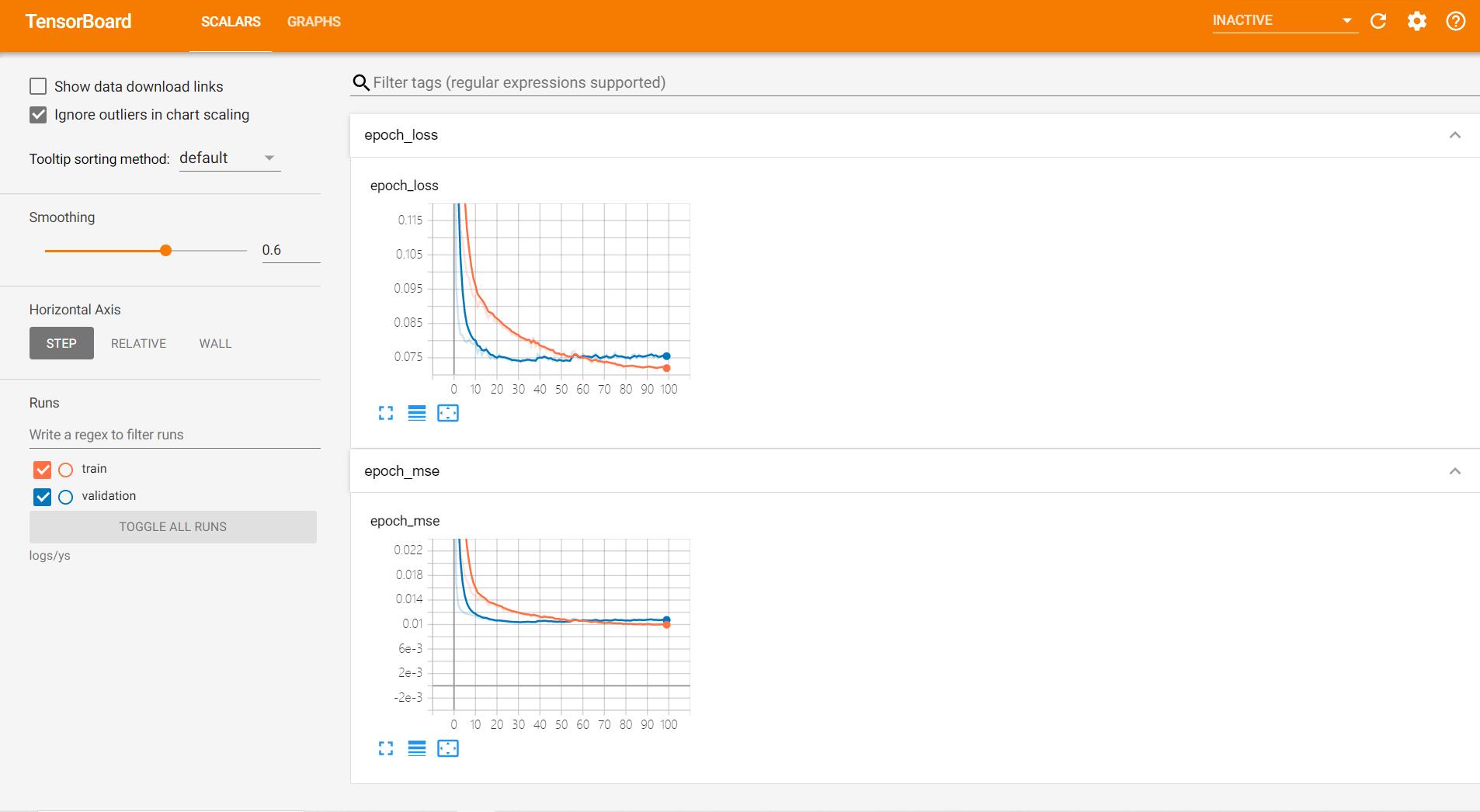
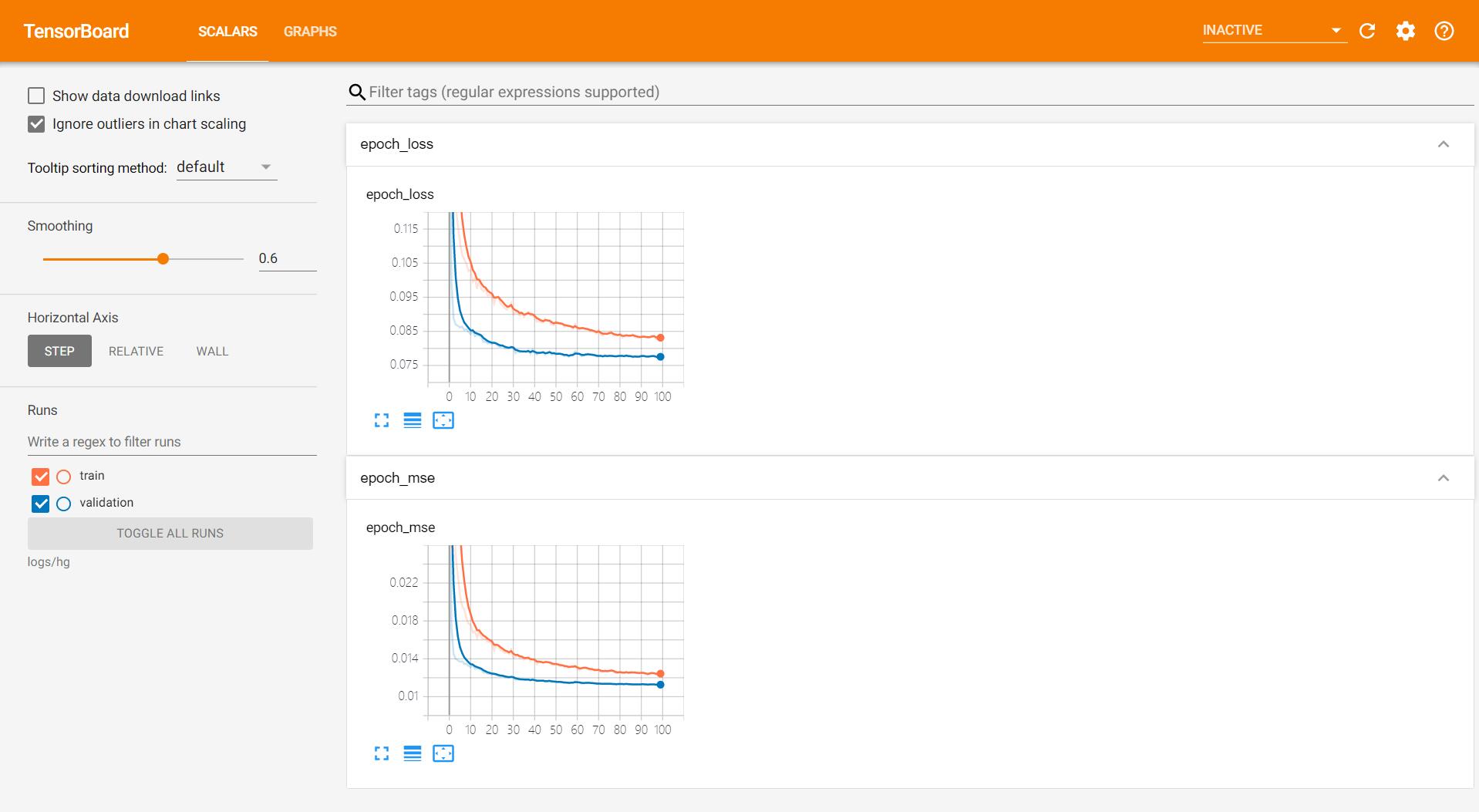
- 训练和测试集的loss,可以看到训练至30个epoch左右,loss已经收敛,同时MSE也较低。
- 贵金属训练曲线:
- 有色金属训练曲线:
- 化工商品训练曲线:
; 五、完整代码地址
由于有大量的项目代码和数据集,有兴趣的学生可以下载完整的代码。如果你在使用过程中遇到任何问题,你可以在评论区发表评论,我会逐一回答。
[En]
Due to the large amount of project code and data set, interested students can download the complete code. If you encounter any questions during use, you can comment on them in the comments area, and I will answer them one by one.
完整代码下载:
【代码分享】手把手教你:基于LSTM的股票预测系统
Original: https://blog.csdn.net/weixin_43486940/article/details/123086000
Author: 大雾的小屋
Title: 手把手教你:基于LSTM的股票预测系统
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/509025/
转载文章受原作者版权保护。转载请注明原作者出处!