

Spark和Mongodb软件安装与python交互测试
作者:Be_melting
3.1 python处理文件
(1)CSV文件
首先根据下载的航班数据,可以属于CSV逗号分隔符文件,可以在pycharm中新建一个项目,创建一个test.csv文件,内容如下。


然后再jupyter notebook中,指引到相同的位置打开后就可以发现这个文件,采用如下代码就能顺利进行CSV文件的读取。可以全部读取CSV文件中的信息,包含了换行符,也可以按照行数进行读取输出,代码如下。

(2)Json文件
首先创建一个常见的列表套字典的数据,就是多个字典数据放置在列表中进行存放。数据存放在Jsonl(line)文件中,就是将字典按照每一行的形式进行保存。

输出结果如下:(第6步执行的代码中,由于多个字典放置在列表中,所以要先进行遍历循环,然后将字典转化为json数据类型,最后写入文本数据中,最后以换行符作为结束,这样输出的结构中就是一行一个json的数据)

为了后续项目的操作方便,可以创建一个文件夹,把常规文件操作的过程封装称为函数,然后直接进行调用,避免每次运行程序时再进行函数的编写。分别在新建的lib文件夹下创建utils.py文件,里面添加读取Json、写入Json、读取Jsonl文件、写入Jsonl文件、读入压缩的Json/Jsonl文件、综合读入json文件(不管是Json,Jsonl,还是压缩的Json/Jsonl文件)6个函数。
import codecsimport jsonimport osimport bz2def read_json_file(path): '''Turn a normal json file (no CRs per record) into an object.''' text = codecs.open(path, 'r', 'utf-8').read() return json.loads(text)def write_json_file(obj, path): '''Dump an object and write it out as json to a file.''' f = codecs.open(path, 'w', 'utf-8') f.write(json.dumps(obj, ensure_ascii=False)) f.close()def read_json_lines(path): '''Read a JSON Lines file''' ary = [] with codecs.open(path, "r", "utf-8") as f: for line in f: record = json.loads(line.rstrip("\n|\r")) ary.append(record) return arydef write_json_lines_file(ary_of_objects, path): '''Dump a list of objects out as a json lines file.''' f = codecs.open(path, 'w', 'utf-8') for row_object in ary_of_objects: json_record = json.dumps(row_object, ensure_ascii=False) f.write(json_record + "\n") f.close()def read_json_lines_bz(path): '''Read a JSON Lines bzip compressed file''' ary = [] with bz2.open(path, "rt") as bz_file: for line in bz_file: record = json.loads(line.rstrip("\n|\r")) ary.append(record) return arydef read_json_lines_file(path): '''Turn a json cr file (CRs per record) into an array of objects''' ary = [] if os.path.isdir(path): for (dirpath, dirnames, filenames) in os.walk(path): for filename in filenames: full_path = f'{dirpath}/{filename}' if full_path.endswith('json') or full_path.endswith('jsonl'): ary.extend( read_json_lines(full_path) ) if path.endswith('bz2'): ary.extend( read_json_lines_bz(full_path) ) else: if path.endswith('bz2'): ary.extend( read_json_lines_bz(path) ) else: ary.extend( read_json_lines(path) ) return
3.2 搭建Spark开发环境和测试
准备好的安装材料截图如下
[En]
The screenshot of the installation material prepared is as follows

(1)安装Java JDK选择提供的工具包:jdk-8u144-windows-x64.exe,双击后 一直默认进行下一步,图示界面就代表安装完成。

点击关闭按钮后,使用快捷键win+r后输入cmd调出电脑的命令行工具,然后直接输入java回车,显示如下界面后就代表着java JDK安装完成。(如果不是默认安装,修改了安装地址,就需要手动的添加系统的环境变量,因此建议一直默认下一步安装即可)

(2)安装Spark
第一步:选择提供的工具包:spark-2.4.5-bin-hadoop2.7.tgz,进行解压缩到C盘的根目录中,然后把文件夹的名称修改为spark。

第二步:上述步骤完成后,还需要把提供的winutils文件夹也移动到C盘根目录,如下。

步骤3:添加环境变量。打开计算机的开始菜单搜索环境变量,结果如下所示。
[En]
Step 3: add environment variables. Open the computer’s start menu to search for environment variables, and the results are as follows.

进入环境变量设置中,添加两个环境变量,分别是 ​SPARK_HOME=c:\spark​和 ​HADOOP_HOME=c:\winutils​,操作如下。(如果前面Java JDK的安装不是默认方式也需要按照此步骤添加环境变量)

接着就是把环境变量添加到Path中,找到Path后双击,添加 ​%SPARK_HOME%\bin​和 ​%HADOOP_HOME%\bin​,添加完毕后,点击确认退出即可

第四步:检验是否安装成功。打开Ancaonda的命令行,安装findspark包,执行代码 ​pip install findspark​,操作及输出结果如下。

安装完成后,重新启动jupyter notebook,新建一个测试文件夹叫做准备课程(之后的程序都放置在这里),创建spark-test.ipynb文件,代码如下。如果直接进行 ​import pyspark​,输出结果会提示无法找到此模块。需要进行导入刚刚安装的模块后,进行初始化后再导入,就可以顺利加载spark了。

可以打开浏览器输入 ​localhost:4040​后回车,然后找到Environment菜单卡,点击后,可以看得到创建的程序名称就是指定的内容时,就代表这spark成功创建了。

注意点: 提供的Anaconda安装包是python3.7版本与提供的spark的2.4.5版本对应,如果使用的是python3.8及以上的版本需要将spark变更为3.x版本,或者在Anaconda中创建一个python3.7的虚拟环境即可。
3.3 搭建Mongodb和ES数据库及测试
3.3.1 Mongodb安装
需要安装两个软件,一个是Mongodb的社区版本,还有一个就是Mongodb数据库的可视化工具mongodb-compass。这两个软件资料中已经帮下载好了安装包,双击后即可安装,也可以在官网上下载。
首先安装Mongodb的社区版本。双击安装包:mongodb-windows-x86_64-4.4.3-signed.msi,然后一直默认系统选择进行安装。(下图就是双击后弹出的安装向导)

接着进入接受许可证界面,前面打钩后再点击Next。

进入下一界面后,默认点击Complete按钮,后进行下载的相关设置,保持默认即可。

下一步就会提醒是否安装Mongodb的可视化工具,这里默认是勾选的,直接进行下一步即可。

正式进入要安装的界面,点击Install按钮,软件就开始进行安装。

几分钟后,软件安装成功,最终界面如下。
[En]
After a few minutes, the software is installed successfully, and the final interface is as follows.

点击Finish按钮后,就进入了Compass软件的介绍页面,一路点击右侧的Next即可,然后在软件界面输入: ​mongodb://localhost:27017​后点击Connect按钮,就会自动连接到Mongodb数据库

成功连接后的界面如下。

3.3.2 Mongodb与python代码互动
Mongodb数据库安装完成后,可以测试python能否将数据写入到Mongodb中。在准备课程文件夹中新建一个mongodb-test.py文件。测试之前需要在Anaconda中安装一个pymongo实现两者之间的互动。

首先在文件中导入连接到数据库所需的库和操作代码,如下所示。
[En]
Import the required libraries and the operation code to connect to the database first in the file, as follows.
import pymongofrom pymongo import MongoClient#服务器的连接有多种方式,一般就是直接使用第一种即可client = MongoClient()client = MongoClient('localhost',27017)client = MongoClient("mongodb://localhost:27017/")#获取数据库的方式也有两种db = client.localdb = client['local']
然后需要在Mongodb中创建一个Collection(类别Mysql就是创建一个Table),起名为abc,任意插入一条字典数据,操作如下。
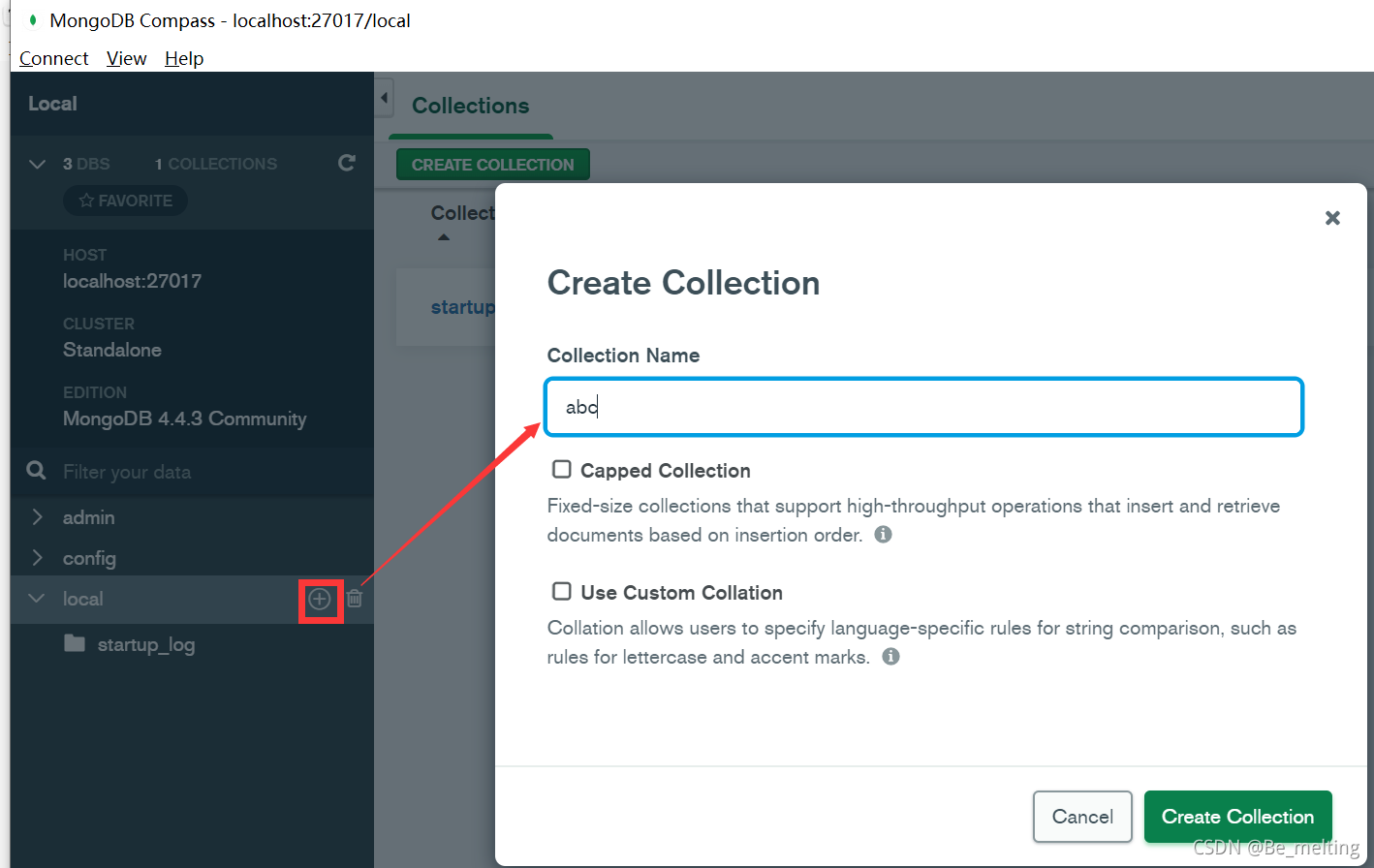
创建完成后,找到刚创建的Collection后,点击Add Data按钮,选择Insert Document选项,任意复制粘贴一行字典数据放置在空白地方即可。

点击INSERT按钮后,就会自动插入数据,输出如下。

此时可以在刚刚创建的mongo-test.py文件中继续输入一下三行代码,就可以查看到写入到数据库中的内容,测试结果如下。

以上是完成了数据库中的数据读取,接下来就是使用python代码向mongodb中插入数据,测试代码如下。
list1 = [{"姓名": "Mars老师", "职务": "教研负责人"},{"姓名": "木森老师", "职务": "助教老师"},{"姓名": "栗子老师", "职务": "班主任"}]for i in list1: posts = db['abc'] id = posts.insert_one(i).inserted_id print (id)
输出结果如下:(程序执行后会打印三个id信息,然后刷新Compass软件页面,就可以看到四条数据记录了)

如果要删除数据,可以直接在Compass中进行操作,点击数据记录右侧的Delete Document按钮后确认删除,就会自动删除该条记录。

如果要读取全部的数据,刚刚插入了多条记录,可以通过 ​for​循环的方式进行操作,代码如下。(注释掉前面的查询单行和写入的代码后运行,顺带也可以通过 ​count_documents()​的方法获得数据行数)

上图的最后一行代码中的{}表示过滤掉空行的作用,此外这里还可以填写其它的过滤信息,比如选择信息为Mars老师的数据。最后可以对数据进行排序输出,第一个参数放置要排序的依据,第二个参数就是排序的顺序,输出结果如下。

3.3.3 Mongodb与Spark交互
在准备课程文件夹中创建一个spark_mongo_test.py文件,进行spark初始化和进程的创建。
import findsparkfindspark.init()from pyspark.sql import SparkSessionspark = SparkSession.builder.appName("mongo-test-spark").getOrCreate()import
最后一行导入了一个模块,该模块并不是直接通过 ​pip install​,而是本地自己编写的程序,安装方式是需要进入到文件存放的位置,然后再执行 ​python setup.py install​,操作示例如下。

此时再运行上述代码,输出的结果中仍然没有成功,显示找不到这个模块。注意上图中间有一个warning的提示,需要我们将pymongo_spark.py文件移动到Anaconda第三方包下的文件夹中。

Anaconda的第三方包的路径查找,其实很简单,在安装第三方库的时候就有提醒。可以查看上方python setup.py install执行后最后两行的提醒,就是将包装到了Anaconda中。找到位置后,将当前文件夹下的pymongo_spark.py复制粘贴到site-package文件夹中,完成后再运行上述程序,就能够顺利找到对应的包了。

pymongo_spark文件经过解压后,里面还有一个mongo-hadoop-spark-2.0.2.jar文件,直接复制到c盘spark文件夹中的jars下。(以上的操作就解决了spark中使用mongodb的问题)

配置完成之后,就可以使用代码将本地文件读取到spark中了,代码操作及输出如下。(操作的过程有点类似pandas,这里先制定spark读取数据的格式为csv,然后设置读入时候的选项,制定有headers,数据类型进行自动推断,最后的load才是加载数据。通过 ​df.show()​就可以显示出读入到spark中的数据了)

下一步就是spark中的数据存放到mongodb中,具体的代码就两行搞定,代码如下。
mongodata = df.rdd.map(lambda x :x.asDict())mongodata.saveToMongoDB('mongodb://localhost:27017/local.on_time')
运行后再次刷新Compass软件界面,此时在local数据中就多了on_time的数据集,里面共有三条记录,结果如下。

3.3.4 ES数据库安装
由于涉及到大数据环境,数据的存放基本上不会在一台机器上。如果要进行精准查询,可以获取到数据所在的详细信息,但是如果进行的是模糊匹配,此时可能就没有办法进行正确结果的返回。为了解决这个问题,后续在设计具有查询功能页面时候使用的就是ES数据库,本质上就是一种搜索引擎。
软件具体安装步骤如下:
(1)将提供的elasticsearch-7.10.2-windows-x86_64.zip压缩包,解压至C盘,并进行文件夹重命名为elasticsearch。

(2)将当前文件夹目录添加到环境变量,添加内容为ES_HOME=c:\elasticsearch,操作如下。

(3)打开命令行,进入 c:\elasticsearch\bin 目录 然后在cmd状态下 运行 elasticsearch 即可启动,具体操作步骤如下。

(4)ES和Mongo DB一样安装完成也是一个通过命令行操作的软件,可以借助可视化的软件来进行展示。课程中提供了两个工具,第一个是Postman-win64-7.16.1-Setup.exe安装包,直接双击后默认安装即可(需要进行简单的注册登录)。软件打开后,可以创建一个请求(create a request),然后在GET输入框中输入:http://127.0.0.1:9200后回车确认,下方输入如下内容,代表着ES数据库成功访问。

第二个可视化工具就是kaizen-5.79.91-windows-x64.zip文件,压缩后进入文件夹中双击第二个kaizen.bat文件,就会弹出一个图标显示正在下载打开软件,如下。

软件打开后点击左上角的云端按钮后,再点击Add新建按钮,会自动出现ES数据库的链接,结果如下。

选择下方第一行的链接,当前页面的左上方的Connect按钮就会由灰色不可点击变成黑色可点击按钮,点击后就可以正常连接数据库了。

(4)使用python进行ES数据库连接测试,需要先pip install elasticsearch模块。

模块安装完毕后,新建一个es_test.py文件,进行代码连接测试。测试代码及输出结果如下,通过python代码就实现了与ES数据库的联动。

比如要在数据库里面添加内容,首先是要创建一个表(类似SQL里面的Table),然后在表中插入数据,测试代码及输出结果如下。

此外还可以给表进行命名和表中数据查询,代码如下。(通过search()方法进行查询,body中是字典样式的查询结构)
res = es.index(index='mydb3',doc_type='employee',id=1,document=e1)#print('--'*30)res = es.search(index='mydb3',body={ 'query':{ 'match': { "first_name":"nitin" } }})print (res)
输出结果如下。(最终输出的也是字典格式,最终匹配的结果是在hits键对应的值中,可以进一步通过res[‘hits’]进行目标数据的提取)

(5)使用Spark连接ES数据库,并将航班数据写入。和python连接也是类似,需要一个介质,课程中提供的elasticsearch-spark-20_2.11-7.10.2.jar文件先移动到Spark文件夹下的jar文件夹下,然后在step1文件夹下创建一个publish_data_to_es.py文件,输入如下测试代码。
from step1.SparkReady import start_sparkspark = start_spark('publish to es ',12,'8g')on_time_df = spark.read.parquet('./data/on_time.parquet')on_time_df.write.format("org.elasticsearch.spark.sql")\ .option("es.resource","example/on_time")\ .option("es.batch.size.entries","200")\ .mode("overwrite")\ .save()
程序运行后,打开ES数据库,可以看到数据成功加载。

整个流程大概是需要3-5分钟,程序后台会使用指定的全部的处理器,这里指定的是12个,打卡任务管理器,查看性能,可以发下处理器是处在100%运作过程中。

3.4 搭建Flask网站和数据测试
使用flask之前需要先在Anaconda命令行中安装flask包,直接进行 ​pip install flask​回车即可(系统中已经安装过)。

安装好后在准备课程文件夹中创建一个flask_test.py文件。然后打开flask官方网站,找到最简单的网站搭建的代码,然后复制粘贴到pycharm中运行,代码及输出结果如下。

如果要显示刚刚存储在数据库中的飞行数据,代码比较简单,测试和输出结果如下。
[En]
If you want to display the flight data just stored in the database, the code is relatively simple, and the test and output results are as follows.

Original: https://blog.51cto.com/u_15713987/5462704
Author: 百木从森
Title: 【大数据实战项目二】Spark环境和Mongo、ES数据库安装,以及数据库与Spark,Python联动
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/508303/
转载文章受原作者版权保护。转载请注明原作者出处!