

前言
本文主要记录学习 MySQL实战45讲之基础篇过程中一些新的收获,以及总结主要内容。其中包括 SQL如何运行、日志系统、事务隔离、索引和锁等。
基础架构
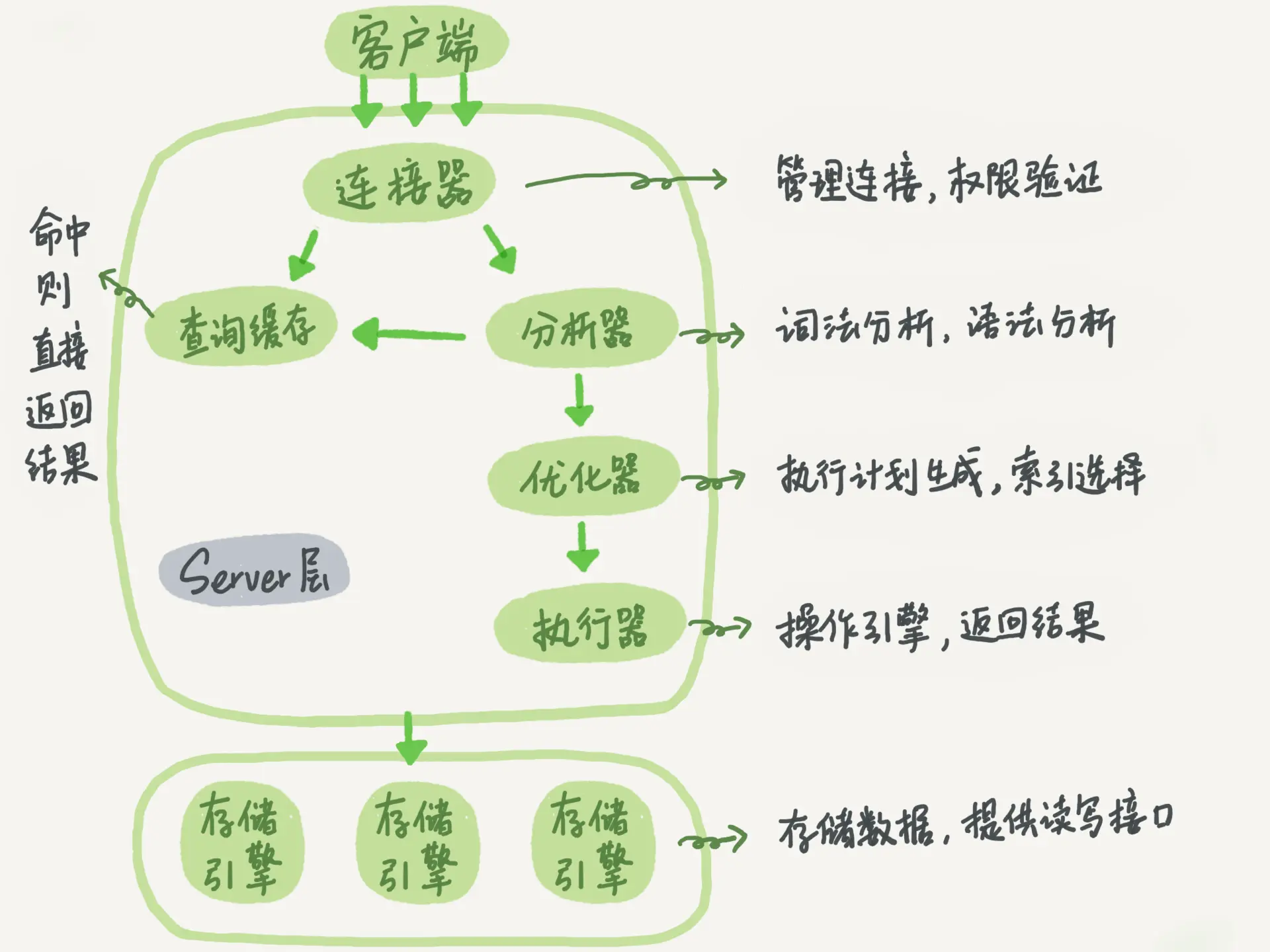

连接器,在建立连接的过程中,连接器会查询用户的权限,之后的操作都依赖于此时查询的权限,这意味着即使您用管理员帐号修改了用户的权限,也不会影响已有的连接。
[En]
Connector, in the process of establishing a connection, the connector will query the user’s permissions, and the operations after this time all rely on the permissions queried at this time, which means that even if you modify the user’s permissions with the administrator account, it will not affect the existing connection.
查询缓存,大部分场景下查询缓存都是弊大于利,因为一旦表发生修改,缓存就会失效,除非是静态表,即永远不发生修改的。并且, MySQL8.0已经将该功能移除。
分析器,对 SQL进行词法分析、语法分析。
优化器通过分析器知道要做什么,而优化器选择干式解决方案。例如,应该选择哪个索引来执行?在返回表之前是全表扫描还是索引扫描?等。
[En]
The optimizer knows what to do through the analyzer, while the optimizer chooses the dry solution. For example, which index should be selected to execute? Full table scan or index scan before returning to the table? Wait.
执行器,开始执行 SQL。在执行之前,会先验证用户是否有查询该表的权限。
为什么不先验证表的查询权限呢?因为这里不仅有要验证的表权限,还有触发器权限,所以必须在运行时确认这一点。
[En]
Why not verify the table query permissions before? Because there are not only table permissions to be validated here, but also trigger permissions, this must be confirmed at run time.
日志系统
redo log
1、用于崩溃恢复,由 InnoDB引擎提供。
2、物理日志,记录”在某个数据页上做了什么修改”,通过 redo log实现执行 SQL之后,不需要马上刷到磁盘,而是先写日志,即 WAL(Write Ahead Logging)技术。
3、日志固定大小,通过两个指针循环写。比如 0 ~ write_pos ~ check_point ~ end, write_pos ~ check_point之间的为可写空间, check_point之后循环到 write_pos为待刷新到磁盘的数据。当 write_pos追到 check_point时会停止写,先将 check_point后的数据刷到磁盘。
bin log
1、用于操作归档及主从同步,由 Server层提供,任何引擎都可以使用。
2、逻辑日志, SQL模式,记录执行的 SQL语句; row模式,记录更新前和更新后的行记录。
3、单个日志文件有最大值,满了后创建新的追加写。
总结
redo log和 bin log使用两阶段提交来保证两个日志的一致性。此外,通过全量备份和 bin log可以恢复到之前任意时刻的数据库状态。
那每周一备和每日一备如何选择?
一周一次,数据恢复时间更长,但需要的存储空间较少;一天一次,数据恢复时间较短,但需要更多的存储空间。如何选择取决于企业的重要性。
[En]
Once a week, the data recovery time is more likely to be longer, but less storage space is needed, while once a day, the data recovery time is shorter, but more storage space is needed. How to choose depends on the importance of the business.
隔离原理
在可重复读隔离级别下,对于同一个值,不同时刻启动的事务可能读取到不同的值,也叫快照读。这个同一条记录多个版本就是多版本并发控制 MVCC,不同版本的记录即回滚日志,是在 undo log中存储的。
当然,这个回滚日志不能一直存在。如果没有比这条回滚日志更早的视图时,日志就会被删除。 insert操作在事务提交后会直接删除, update和 delete操作会写到 undo log list中,当判定不会被使用后,要么重用,要么放到删除列表等待 purge线程清除。
由上可知,长事务存在一个弊端就是会有很多老视图存在数据库中占据存储空间。所以,建议开启事务的自动提交 set autocommit=1。如果想避免每次开启事务的交互,可以考虑用 commit work and chain优化,提交事务并启动下一个事务。
索引结构
哈希表,只适用于等值查询的场景,比如 Nosql数据库等。对于范围查询必须全表扫描。
有序数组只在查询效率方面是一个很好的结构,但在插入和删除元素时需要移动元素。因此,它只适用于静态存储场景,即永远不变的表。
[En]
An ordered array is a good structure only in terms of query efficiency, but elements need to be moved when inserting and deleting. Therefore, it only applies to static storage scenarios, that is, tables that never change.
树,增删改查效率都比较好。由于对于同样大小的数据,二叉树高度远高于 N叉树,所以为了减少查询时的 IO读取,选择的是 N叉树,且 N差不多为 1200,这样的树第 4层的节点就有上亿个,即大部分存储场景只需要 3~4层就可以满足。并且,一般会提前将 1 or 2层先加载到内存。
主键索引选择
主键索引一般默认选择自增主键,原因如下:
[En]
The primary key index generally selects the self-increasing primary key by default for the following reasons:
1、性能上,自增主键插入索引树,默认是追加,可以有效地避免页分裂,页分裂需要创建新的页,并拷贝数据,必然影响性能。
2、存储空间上,自增主键一般只占用 4 or 8字节,采用其他像字符串一样的作为索引需要更多的存储空间。并且,主键值类型占用空间越多,普通索引的占用空间也越大。
重建索引
为什么需要重建索引?
由于删除数据或分页可能会导致索引出现漏洞,虽然后续操作会尽可能地填补这些漏洞,但总会有存储空间的浪费。对索引进行改造后,可以使数据紧凑,消除数据空洞,提高空间利用率。
[En]
Because deleting data or page splitting may lead to holes in the index, although subsequent operations will fill the holes as much as possible, there will always be a waste of storage space. After rebuilding the index, it can make the data compact, eliminate the data hole and improve the space utilization.
不过注意,如果要 重建主键索引,默认会删除所有的索引树再重新创建。此时,可以考虑用 Alter Table t Engine = InnoDB。
全局锁
全局锁,就是对数据库对象上锁。 MySQL支持全局读锁, Flush Table With Read Lock(FTWRL),上锁后会阻塞增删改操作, DDL操作(创建表、修改表结构等)和更新类事务操作。
全局锁定的典型情况是完全备份。备份过程中,业务停止工作,主备库数据同步停止,效率相对较低。但是,这是不支持事务的存储引擎使用的备份方法。对于支持事务的引擎,您可以在可重复读隔离级别下启动单个事务进行备份,即无需锁定即可实现一致读取。
[En]
A typical scenario for global locking is full backup. During the backup, the business stops working and the data synchronization between the master and slave libraries stops, which is relatively inefficient. However, this is the backup method used by storage engines that do not support transactions. For engines that support transactions * , you can start a single transaction to back up under the * repeatable read isolation level * , that is, consistent reading can be achieved without locking.*
表级锁
表级锁,分为两种表锁和元数据锁( meta data lock,MDL)。表锁就是对表数据显式上锁和释放,避免同时对表数据修改;而元数据锁,则是隐式对表结构上锁和释放,分为读锁和写锁,读取数据时上读锁,修改表结构上写锁。读写和写写互斥,避免读取数据时其他事务修改表结构。
注意,如果在一个事务中,先出现 DML读取数据,再进行 DDL修改表结构,则会阻塞后续的所有读写操作。
那么,如何安全地将字段添加到小表中呢?
[En]
So how do you safely add fields to a small table?
1、如果有长事务存在,考虑先暂停 DDL或者 kill掉这个长事务。
2、如果修改的表是热点表,并且不得不加字段,此时 kill基本没用,考虑给 DDL设定等待时间,失败了等一段时间再重试吧。
行锁
在事务中锁定并处理一行后,锁不会立即解锁,而是遵循二阶{分段锁定协议。因此,为了最大限度地减少锁冲突,请尝试允许在事务结束时执行锁冲突。
[En]
After a row is locked and processed in a transaction, the lock is not released immediately, but follows the * two-order {segment locking protocol * . Therefore, in order to minimize lock conflicts, try to allow lock conflicts to be performed at the end of the transaction.
- 一阶段锁协议
直接尝试一次获取所有锁资源,如果其中一个失败,则不执行事务,并在事务结束时释放所有资源。[En]
A direct attempt is made to get all lock resources at once, and if one of them fails, the transaction is not executed and all resources are released at the end of the transaction.
一阶段锁协议解决了死锁问题,但事务并发性不高。
[En]
The one-stage locking protocol solves the deadlock problem, but the transaction concurrency is not high.
- 两阶段锁协议
整个交易分为两个阶段。在第一阶段,可以处理锁,但不能解锁;在第二阶段,可以解锁,也可以处理数据,但不能再添加锁。[En]
The whole transaction is divided into two phases. In the first stage, the lock can be processed, but the lock cannot be released; in the second stage, the lock can be released, and the data can also be processed, but no more locks can be added.
两阶段锁协议具有高度的并发性,因为释放锁不一定要在事务结束时,但它不能解决死锁问题,因为在锁定阶段没有顺序要求。
[En]
The two-phase lock protocol has a high degree of concurrency because releasing the lock does not have to be at the end of the transaction, but it does not solve the deadlock problem because there is no order requirement in the locking phase.
死锁
因为 MySQL采用两段锁协议进行加锁,如果加锁顺序不合理时,会产生死锁。解决办法有两种,锁超时和死锁检测。
锁超时
如果因为发生死锁一直锁等待,到达超时时间后会自动回滚超时事务。 MySQL默认设置了锁等待超时时间, innodb_lock_wait_timeout=50s,并且通过下面语句操作:
查看: SHOW GLOBAL VARIABLES LIKE "innodb_lock_wait_timeout";
设置: SET GLOBAL innodb_lock_wait_timeout=1500;
死锁检测
MySQL Server层提供的自动检测机制,当发现两个或多个事务形成死锁时,会回滚其中一个或多个较小代价的事务。并且, MySQL默认开启了死锁检测( innodb_deadlock_detect=on)。
当事务并发量大时,死锁检测十分损耗 CPU。
那如何处理热点行更新导致的性能问题?
首先,为什么会有性能问题呢?因为热点行可能存在同一时刻大量事务更新同一个行,此时会出现大量锁等待,并触发死锁检测,每个死锁检测都是 O(n)的时间复杂度,导致损耗大量的 CPU资源。
第一种权宜之计是,如果您可以确认不会发生死锁,则考虑关闭死锁检测,但这通常不会使用。
[En]
The first stop-gap approach is to consider turning off deadlock detection if you can confirm that no deadlock will occur, but this is generally not used.
第二个方法是 减少并发度,避免同一时刻触发太多的死锁检测。比如控制同一时刻每行最多只有 10个线程在更新,或者将原先的一行拆分成多行,这样就可以将原先的并发量缩减为原来的 1/n,但视业务场景,可能要考虑拆分成多行造成的副作用,做一个详细方案的设计。
快照读和当前读
快照读
快照读取是可重复隔离级别的默认查询方法。当每个事务启动时,将创建一个读取视图,并根据该视图读取数据。
[En]
Snapshot reading is the default query method at the repeatable isolation level. When each transaction starts, a read view is created and the data is read according to the view.
这个视图实际上就是一个事务 id数组,表示当前事务启动时,全库范围内”活跃”的未提交事务 id。每个事务都有一个唯一的事务 id,由 InnoDB事务系统在事务创建前分配,并且按申请顺序严格递增。
此外,真实的快照数据存储在 undo log中,在事务更新行记录前,都会在 undo log中存储历史版本数据,并记录上当前事务的 id,表示 row trx_id。从而,通过当前执行的事务 id和行的历史版本中的 row trx_id比较,就可以判断哪些数据可见。
undo log是逻辑日志,存储的是与更新时相反的逻辑,就是下图中的 U1、U2、U3,而 V1、V2、V3、V4是不存在的,需要临时计算出来。
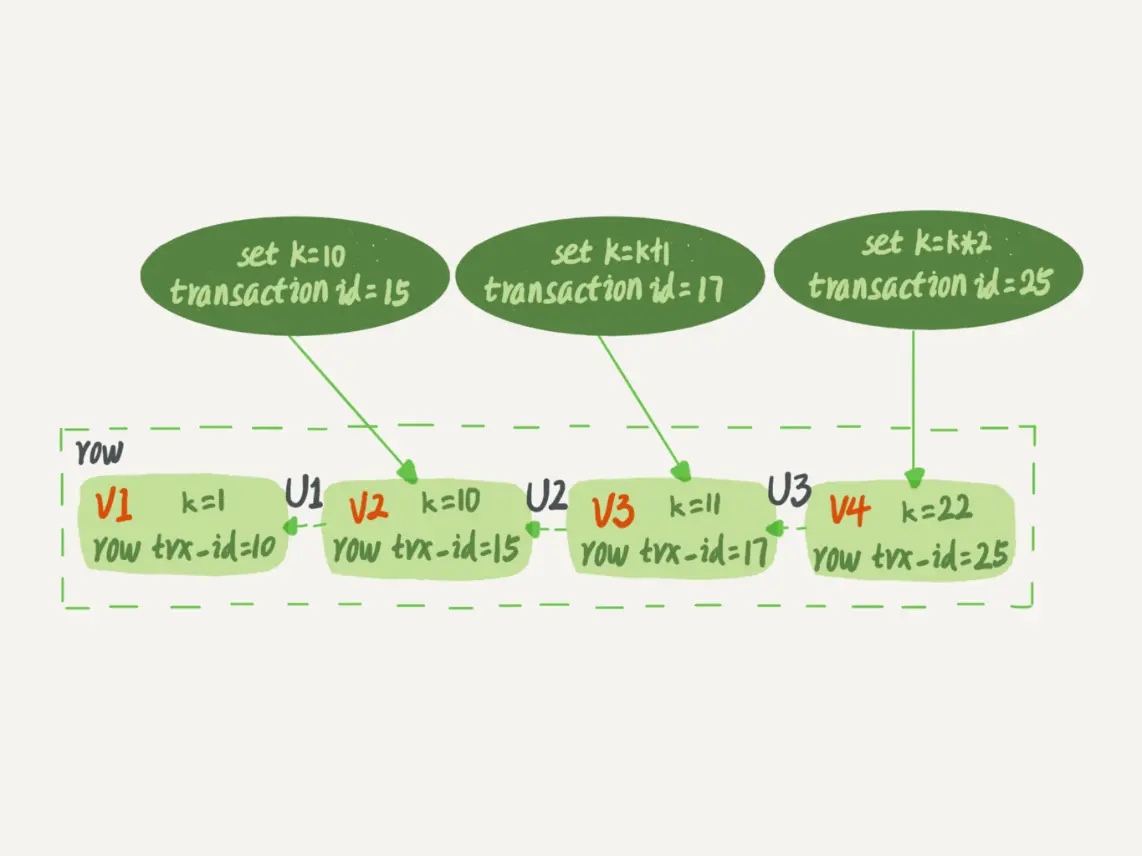
可见性结论:
1、版本未提交,不可见。
2、版本已提交,但是在视图创建后提交的,不可见。
3、版本已提交,在视图创建前提交,可见。
当前读
当前读用于更新语句,或者加锁的查询操作( SELECT * FROM t lock in share mode或者 SELECT * FROM for update,分别加了共享锁和排他锁),读取数据时会获取最新版本。
总结而言,可重复读依赖快照读实现,当要更新数据时,则采用当前读。
此外,视图也在COMMIT READ隔离级别下使用,但在由可重复读取创建时不会使用。它可以重复读取,仅在事务启动时创建视图,并在每次执行语句之前提交读取以创建视图。
[En]
In addition, views are also used under the commit read isolation level, but not when they are created by repeatable reads. It can be read repeatedly, creating a view only when the transaction starts, and committing a read to create a view before each statement execution.
参考
- [1] MySQL 45讲
- [2] MySQL undo log日志
Original: https://www.cnblogs.com/flowers-bloom/p/mysql45-basic.html
Author: flowers-bloom
Title: MySQL实战45讲之基础篇
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/508177/
转载文章受原作者版权保护。转载请注明原作者出处!