

MySQL 体系架构
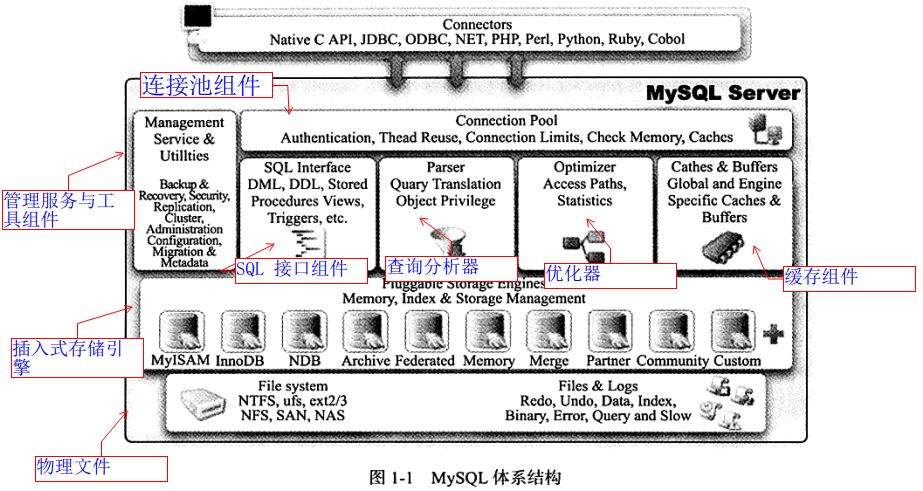

– 连接池组件
1、负责与客户端的通信,是半双工模式,这就意味着某一固定时刻只能由客户端向服务器请求或者服务器向客户端发送数据,而不能同时进行。
2、验证用户名和密码是否正确(数据库 MySQL 的 user 表中进行验证),如果错误返回错误通知 Access denied for user 'root'@'localhost'(using password:YES);如果正确,则会去 MySQL 的权限表查询当前用户的权限。
– 缓存组件
也称为查询缓存,存储的数据是以键值对的形式进行存储,如果开启了缓存,那么在一条查询 SQL 语句进来时会先判断缓存中是否包含当前的 SQL 语句键值对,如果存在直接将其对应的结果返回,如果不存在再执行后面一系列操作。如果没有开启则直接跳过。
show variables like 'have_query_cache'; # 查看缓存配置:
show variables like 'query_cache_type'; # 查看是否开启
show variables like 'query_cache_size'; # 查看缓存占用大小
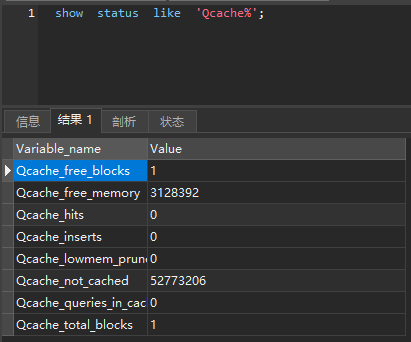
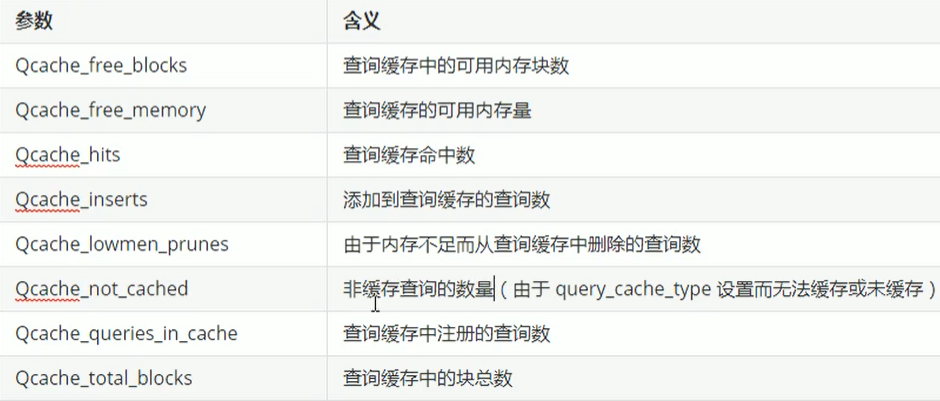
show status like 'Qcache%'; # 查看缓存状态信息
缓存失效场景
- 查询语句不一致。前后两条查询 SQL 必须完全一致;
- 查询语句中含有一些不确定的值时,则不会缓存。比如 now()、current_date()、curdate()、curtime()、rand()、uuid() 等;
- 不使用任何表查询。如 select ‘A’;
- 查询 mysql、information_schema 或 performance_schema 数据库中的表时,不会走查询缓存;
- 在存储的函数、触发器或事件的主体内执行的查询
[En]
queries executed within the body of a stored function, trigger, or event*
- 如果表更改,则使用该表的所有高速缓存查询都变为无效并从缓存中删除,这包括使用 MERGE 映射到已更改表的表的查询。一个表可以被许多类型的语句改变,如 insert、update、delete、truncate table、alter table、drop table、drop database。
通过上面的失效场景可以看出缓存是很容易失效的,所以如果不是查询次数远大于修改次数的话,使用缓存不仅不能提升查询效率还会拉低效率(每次读取后需要向缓存中保存一份,而缓存又容易被清除)。所以在 MySQL5.6 默认是关闭缓存的,并且在 8.0 直接被移除了。当然,如果场景需要用到,还是可以使用的。
开启
在配置文件(linux 下是安装目录的 cnf 文件,windows 是安装目录下的 ini 文件)中,增加配置: query_cache_type = 1

指定 SQL_NO_CACHE,SQL_CACHE 同理。
SELECT SQL_NO_CACHE * FROM student WHERE age > 20;
– 分析器
对客户端传来的 SQL 进行分析,这将包括预处理与解析过程,并进行关键词的提取、解析,并组成一个解析树。具体的解析词包括但不局限于 select/update/delete/or/in/where/group by/having/count/limit 等,如果分析到语法错误,会直接抛给客户端异常: ERROR:You have an error in your SQL syntax.。
select * from user where userId = 1234;
在分析器中就通过语义规则器将 select from where 这些关键词提取和匹配出来,MySQL 会自动判断关键词和非关键词,将用户的匹配字段和自定义语句识别出来。这个阶段也会做一些校验:比如校验当前数据库是否存在 user 表,同时假如 user 表中不存在 userId 这个字段同样会报错: unknown column in field list.。
– 优化器
进入优化器说明 SQL 语句是符合标准语义规则并且可以执行。优化器会根据执行计划选择最优的选择,匹配合适的索引,选择最佳的方案。比如一个典型的例子是这样的:
表 T,对 A、B、C 列建立联合索引 —— (A,B,C),在进行查询的时候,当 SQL 查询条件是: select xx where B=x and A=x and C=x。很多人会以为是用不到索引的,但其实会用到,虽然索引必须符合最左原则才能使用,但是本质上,优化器会自动将这条 SQL 优化为: where A=x and B=x and C=x,这种优化会为了底层能够匹配到索引,同时在这个阶段是自动按照执行计划进行预处理,MySQL 会计算各个执行方法的最佳时间,最终确定一条执行的 SQL 交给最后的执行器。
优化器会根据扫描行数、是否使用临时表、是否排序等来判断是否使用某个索引,其中扫描行数的计算可以通过统计信息来估算得出,而统计信息可以看作是索引唯一数的数量,可以使用部分采样来估算,具体就是选择 N 个数据页,统计这些页上数据的不同值,得到一个平均值,然后乘以这个索引的页面数,就得到了。但是因为索引数据会变化,所以索引的统计信息也会变化。当变更的数据行数超过 1/M 的时候,就会重新计算一次统计信息。
关于统计信息可以选择是否持久化::通过 innodb_stats_persistent,设置为 on 的时候,表示统计信息会持久化存储。这时,默认的 N 是 20,M 是 10。设置为 off 的时候,表示统计信息只存储在内存中。这时,默认的 N 是 8,M 是 16。
没有使用最优索引如何优化::
1、虽然会自动更新统计信息,但是但是不能保证统计信息是最新值,这就可能导致优化器选择了不同的索引导致执行变慢,所以可以通过 analyze table 表名 来重新计算索引的统计信息;
2、在表名后面添加 force index(索引名) 语句来强制使用索引(不建议);
3、将 SQL 进行修改成优化器可以选最优索引的实现方式;
4、新建一个最优索引或者删除优化器误用的索引;
– 执行器
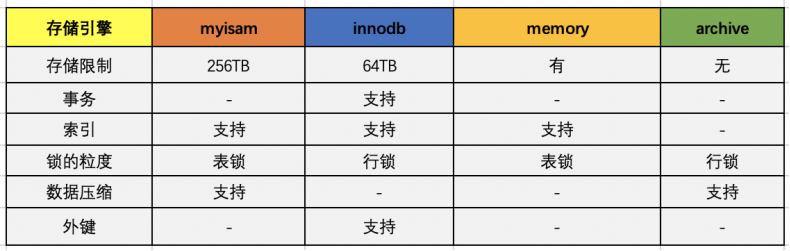
执行器会调用对应的存储引擎执行 SQL,主流的是 MyISAM 和 Innodb。
写操作执行过程

读操作执行过程
在 MySQL 5.6 之后引入了 索引下推(Index Condition Pushdown),所以在查询操作上会有一个 Index Filter 和 Table Filter 的过程,查询的流程图大致可以用下面这张图来概括:
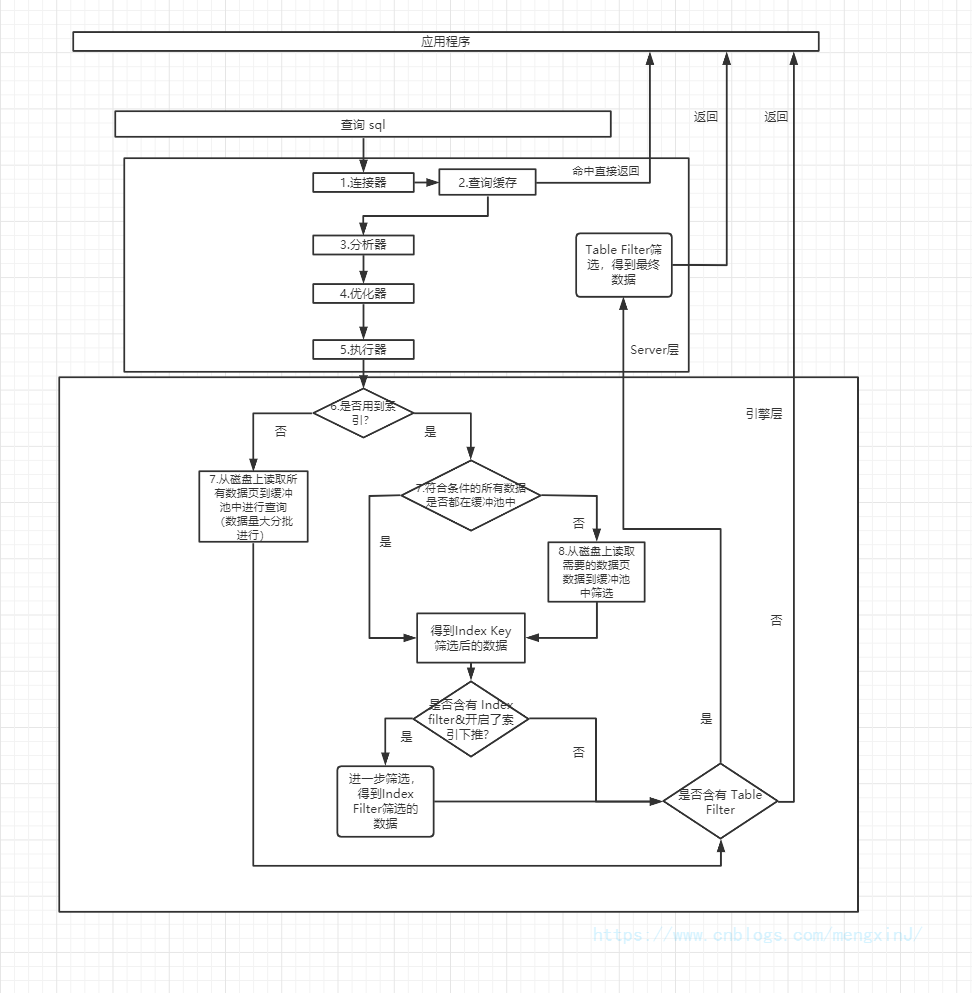
SQL执行顺序

原文链接:https://www.cnblogs.com/mengxinJ/p/14045520.html
Original: https://www.cnblogs.com/jmcui/p/15799516.html
Author: JMCui
Title: 【转】 一条 SQL 的执行过程详解
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/507870/
转载文章受原作者版权保护。转载请注明原作者出处!