

导语
在使用xtrabackup8版本对mysql8版本进行备份恢复搭建从库的时候,继续使用xtrabackup2版本的方式,从xtrabackup_binlog_info 文件中找到gtid信息,执行purge,尝试多次发现搭建失败,于是对xtrabackup2和xtrbackup8版本备份流程(依据官网)进行了简单的分析和测试。
1、xtrabackup2.4版本备份mysql5.7流程
(1)整体流程:
xtrabackup是物理备份,通过复制数据文件来进行备份的,在复制innodb数据文件的时候,会导致数据内部不一致,但是由于redo事务日志的存在(它包含对innodb数据修改的记录),当innodb启动的时候会检查数据文件和事务日志,该提交提交该回滚回滚,从而保证了一致性。
xtrabackup在启动的时候会记住日志序列号(LSN),然后复制数据文件,然而当数据量较大的时候,复制数据文件是需要一定的时间的,如果该时间内不断有写入业务的话,那么将会使数据库处于不同的时间点。这时xtrabackup会从后台启动一个事务日志监测进程(每秒检测一次),并不断的复制事务日志的修改,由于事务日志是循环的方式写的,所以在xtrabackup开始的时候就会不断的复制事务日志的修改。
将使用ftwrl加全局读锁,来备份非innodb表,并且写xtrabackup_binlog_info文件,使用FLUSH NO_WRITE_TO_BINLOG ENGINE LOGS来刷盘redo log,阻止所有可能改变二进制日志位置或Exec_Master_Log_Pos或Exec_Gtid_Set的操作,然后停止redo log的复制操作,解锁二进制日志和表,然后写xtrabackup_info文件,备份完成。
(2)流程总结:
以下是上述备份过程的简要摘要:
[En]
A brief summary of the above backup process is as follows:
①开始备份,连接数据库并进行权限校验以及确认版本(version_check Connected to MySQL server);
②备份innodb表,并开启后台线程拷贝redo log事务日志(>> log scanned up to (952373638)…..);
③innodb表备份完成后,加ftwrl全局读锁来copy非innodb表文件,拷贝完成后(Finished backing up non-InnoDB tables and files)通过show master status写xtrabackup_binlog_info文件;
④将redo log buffer中的redo log进行刷盘(Executing FLUSH NO_WRITE_TO_BINLOG ENGINE LOGS…);
⑤停止拷贝事务日志(Stopping log copying thread.);
⑥解锁二进制日志和表(Executing UNLOCK TABLES);
⑦写xtrabackup_info文件(Writing /data0/backup/9909/base/xtrabackup_info);
⑧备份完成。
(3)关于恢复后binlog信息位置点:
您可以创建一个存储过程来模拟数据插入。
[En]
You can create a stored procedure to simulate the insertion of data.
①首先进行一次全备份:
xtrabackup –defaults-file=/etc/mysql/9909.cnf –backup –user=root –password=root –parallel=4 –ftwrl-wait-timeout=60 –ftwrl-wait-threshold=3 –rsync –socket=/tmp/mysql_9909.sock –target-dir=/data0/backup/9909/base
②进行prepare阶段:
xtrabackup –prepare –apply-log-only –target-dir=/data0/backup/9909/base/
③查看xtrabackup_binlog_info 文件binlog点位信息:
mysql-bin.000026 1251702 9c94ddb7-7397-11ec-a69f-fa37ddbb3200:1-38088
④用备份文件启动mysql,查看binlog点位信息:
mysql> show master stauts;9c94ddb7-7397-11ec-a69f-fa37ddbb3200:1-34381可以看到该点位比xtrabackup_binlog_info要差很多,查看原来实例的binlog找到该两个gtid信息位置:9c94ddb7-7397-11ec-a69f-fa37ddbb3200:38088此处是一个insert语句:
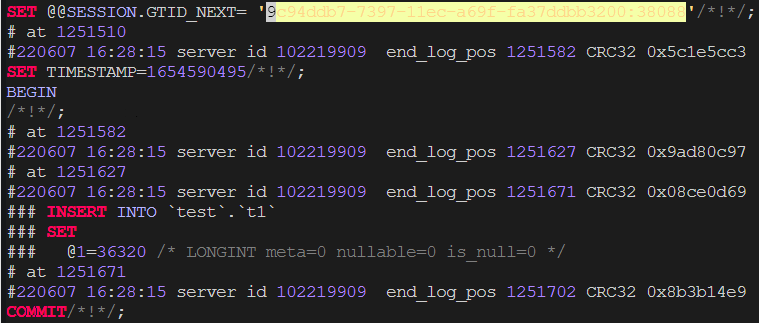

我们查询恢复的库以查看是否有这条记录,我们可以看到有这条记录,并且下一条记录消失了(因为上面的存储过程是按顺序插入的):
[En]
We query the restored library to see if there is this record, and we can see that there is this record, and the next record is gone (because the above stored procedure is inserted sequentially):
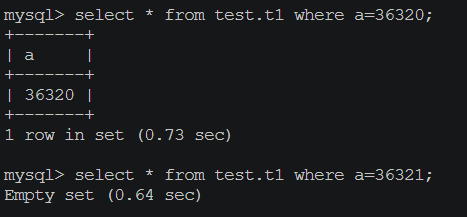
所以说在9c94ddb7-7397-11ec-a69f-fa37ddbb3200:38088之前的记录都已经存在了,而show master status查询出来的要落后好多,如果使用该binlog点位搭建从库的话(不执行purge)会出问题的,比如会出现主键冲突等。
(4)原因:在备份的时候通过show master status读取binlog信息,因为开启了binlog日志,所以show master status读取的是show global variables查出来的gtid的信息,然后保存到了xtrabackup_binlog_info文件中。这里使用的是备份文件进行启动的实例,binlog从1号开始,所以需要读取这个表,所以查出来的show master status是通过这个表来获取的,而这个表在原库没有更新过,所以会比xtrabackup_binlog_info文件中的gtid要少。
(5)补充:
在恢复的时候,需要进行准备阶段,该阶段使用复制的事务日志文件对数据文件进行崩溃恢复,完成之后,数据库就可以恢复和使用了。备份的非innodb表和innodb表最终保持一致,因为在准备阶段,innodb的数据会前滚到备份完成的点,而不是回滚。这个时间点和ftwrl的时间点相匹配,所以mysiam和innodb数据是一致的。
2、xtrabackup8.0版本备份mysql8.0流程
(1)整体流程:
xtrabackup是物理备份,通过复制数据文件来进行备份的,在复制innodb数据文件的时候,会导致数据内部不一致,但是由于redo事务日志的存在(它包含对innodb数据修改的记录),当innodb启动的时候会检查数据文件和事务日志,该提交提交该回滚回滚,从而保证了一致性。
xtrabackup在启动的时候会记住日志序列号(LSN),然后复制数据文件,然而当数据量较大的时候,复制数据文件是需要一定的时间的,如果该时间内不断有写入业务的话,那么将会使数据库处于不同的时间点。这时xtrabackup会从后台启动一个事务日志监测进程(每秒检测一次),并不断的复制事务日志的修改,由于事务日志是循环的方式写的,所以在xtrabackup开始的时候就会不断的复制事务日志的修改。
xtrabackup8在备份mysql8版本的时候,使用备份锁来代替ftwrl(mysql8通过lock instance for backup语句获取一个实例级备份锁)。当只有innodb表时,xtrabackup将尽可能避免使用备份锁和ftwrl。xtrabackup从performance_schema.log_status来获取二进制日志的信息。在mysql8中如果xtrabackup使用–slave-info参数或者存在非innodb表的时候(除了系统表),仍然需要ftwrl进行加锁。当支持备份锁时,xtrabackup会先拷贝innodb数据,然后运行lock tables for backup再拷贝myisam表。
在此之后,使用FLUSH NO_WRITE_TO_BINLOG BINARY LOGS切换binlog,并读取log_status表,使用FLUSH NO_WRITE_TO_BINLOG ENGINE LOGS来刷盘redo log,阻止所有可能改变二进制日志位置的操作,然后将完成redo日志文件的复制,并获取二进制日志信息。完成后,将解锁二进制日志和表。然后写xtrabackup_info文件,备份完成。
( 2)流程总结:对于上述的备份过程分两种情况简单总结一下就是:
a、只有innodb表:
①开始备份,连接数据库并进行权限校验以及确认版本(version_check Connected to MySQL server);
②备份innodb表,并开启后台线程拷贝redo log事务日志(>> log scanned up to (952373638)…..);
③innodb表备份完成后,copy非innodb表文件,拷贝完成后(Finished backing up non-InnoDB tables and files)通过切换binlog(Executing FLUSH NO_WRITE_TO_BINLOG BINARY LOGS)并查询log_status表(Selecting LSN and binary log position from p_s.log_status);
④拷贝新的binlog(Copying /data0/mysql/8001_test/mysql-bin.000011 to /data0/backup/8001/base/mysql-bin.000011),写mysql-bin.index文件和xtrabackup_binlog_info文件;
④将redo log buffer中的redo log进行刷盘(Executing FLUSH NO_WRITE_TO_BINLOG ENGINE LOGS…);
⑤停止拷贝事务日志(Stopping log copying thread.);
⑥解锁二进制日志和表(Executing UNLOCK TABLES);
⑦写xtrabackup_info文件(Writing /data0/backup/9909/base/xtrabackup_info);
⑧备份完成。
b、包含myisam表:
①开始备份,连接数据库并进行权限校验以及确认版本(version_check Connected to MySQL server);
②备份innodb表,并开启后台线程拷贝redo log事务日志(>> log scanned up to (952373638)…..);
③innodb表备份完成后,加ftwrl全局读锁来copy非innodb表文件,拷贝完成后(Finished backing up non-InnoDB tables and files)通过切换binlog(Executing FLUSH NO_WRITE_TO_BINLOG BINARY LOGS)并查询log_status表(Selecting LSN and binary log position from p_s.log_status);
④拷贝新的binlog(Copying /data0/mysql/8001_test/mysql-bin.000011 to /data0/backup/8001/base/mysql-bin.000011),写mysql-bin.index文件和xtrabackup_binlog_info文件;将redo log buffer中的redo log进行刷盘(Executing FLUSH NO_WRITE_TO_BINLOG ENGINE LOGS…);
⑤停止拷贝事务日志(Stopping log copying thread.);
⑥解锁二进制日志和表(Executing UNLOCK TABLES);
⑦写xtrabackup_info文件(Writing /data0/backup/9909/base/xtrabackup_info);
⑧备份完成。
其实只有innodb表和包含myisam表,xtrbackup8备份的时候差别在于包含myisam表的时候增加了ftwrl操作。
(3)performance_schema.log_status表简介:
该表是为在线备份工具来使用的,提供了日志的信息,当查询log_status表时,服务器阻塞日志记录和相关管理更改,时间足够填充表,然后释放资源。
该表通知在线备份工具应该复制到二进制日志的哪个点以及每个通道的中继日志的信息。还提供了单个存储引擎的相关信息,例如最近的日志序列号(LSN)和innodb存储引擎的最后一个检查点的LSN。注意该表不允许执行truncate table。
(4)lock instance for backup简介:
是一个实例级别的备份锁,允许在联机备份期间进行DML操作。执行该命令需要backup_admin权限,当从早期版本升级到mysql8.0版本时,该权限会自动授权具有reload权限的用户。该备份锁防止文件被创建、重命名或者删除(比如repair table、truncate table、optimizer table等),对于redo中没有记录的修改的操作也会被阻止。
(5)关于恢复后binlog信息位置点(只测试只有innodb表的时候)可以创建一个存储过程,来模拟数据的插入。
①首先进行一次全备份:xtrabackup8 –defaults-file=/etc/mysql/8001.cnf –backup –user=root –password=root –parallel=4 –ftwrl-wait-timeout=60 –ftwrl-wait-threshold=3 –rsync –socket=/data0/mysql/8001_test/mysql_8001.sock –target-dir=/data0/backup/8001/base
②进行prepare阶段:
xtrabackup8 –prepare –apply-log-only –target-dir=/data0/backup/8001/base/
③查看xtrabackup_binlog_info 文件binlog点位信息:
mysql-bin.000027 1027 c8020369-d117-11ec-9049-fa37ddbb3200:1-96358
④用备份文件启动mysql,查看binlog点位信息:
mysql> show master stauts;c8020369-d117-11ec-9049-fa37ddbb3200:1-96359可以看到该点位比xtrabackup_binlog_info 文件binlog点位要大,到底哪个是准确的呢?来看一下binlog:
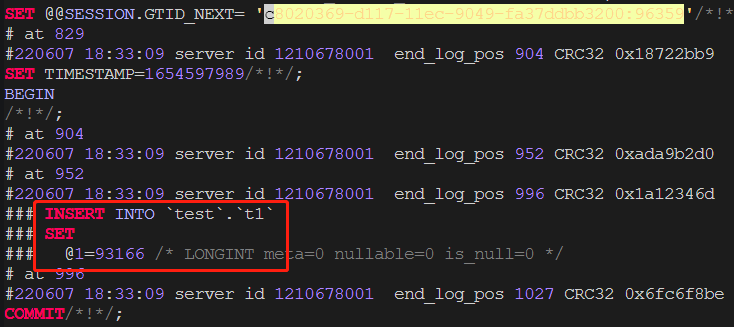
插入了一条数据,在用备份启动的mysql上查看是否存在该数据:
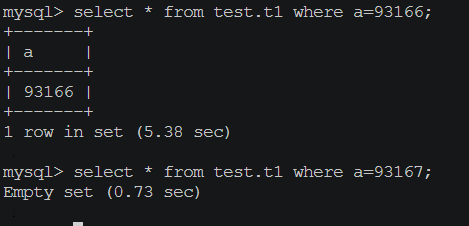
已经存在该数据了,如果当做从库的话,还是从xtrabackup_binlog_info该文件去查找binlog点位然后执行purge,那么搭建起来的从库会报错,比如主键冲突等,或者造成数据不一致。所以xtrabackup8备份mysql8之后show master status就是正确的binglog点位,不用再去执行purge。
⑤原因:
因为xtrabackup8中在备份过程中多了两个步骤:
第一:切换binlog;
第二:拷贝新的binlog,并写mysql-bin.index文件。当使用备份启动实例的时候,由于binlog存在,所以启动的时候从binlog去读取点位信息,并更新mysql.gtid_executed表。
看一下原库的p_s.log_status表:

由于一直有数据插入所以该表一直是更新的。再来看一下恢复库的p_s.log_status表:

由于没有数据写入,所以和恢复后show master status保持一致。
该表主要的作用就是,在备份过程中提供一致性点位,在查询该表之后会执行Executing FLUSH NO_WRITE_TO_BINLOG ENGINE LOGS…来阻止可能改变二进制位置的操作。
3、补充
①xtrabackup_binlog_info 文件binlog点位信息:1027position对应的gtid是: c8020369-d117-11ec-9049-fa37ddbb3200:96358而实际上1027position对应的gtid是: c8020369-d117-11ec-9049-fa37ddbb3200:96359可见xtrabackup_binlog_info 中的并不准确。
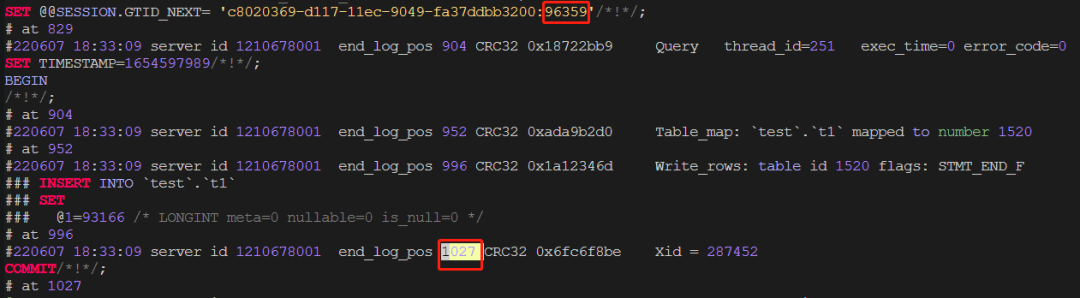
②当包含myisam表的时候,使用xtrabackup8进行备份,因为会执行ftwrl所以最后xtrabackup_binlog_info和show master status均一致。
参考:
[https://dev.mysql.com/doc/refman/8.0/en/performance-schema-log-status-table.html
https://docs.percona.com/percona-xtrabackup/8.0/how_xtrabackup_works.html
https://docs.percona.com/percona-xtrabackup/2.4/how_xtrabackup_works.html](https://dev.mysql.com/doc/refman/8.0/en/performance-schema-log-status-table.html%3Cbr/%3E%3Cbr/%3Ehttps://docs.percona.com/percona-xtrabackup/8.0/how_xtrabackup_works.html%3Cbr/%3E%3Cbr/%3Ehttps://docs.percona.com/percona-xtrabackup/2.4/how_xtrabackup_works.html)
Original: https://www.cnblogs.com/ordinarydba/p/16374951.html
Author: DB文档搬运工
Title: xtrabackup2版本和xtrabackup8版本对比
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/505290/
转载文章受原作者版权保护。转载请注明原作者出处!