

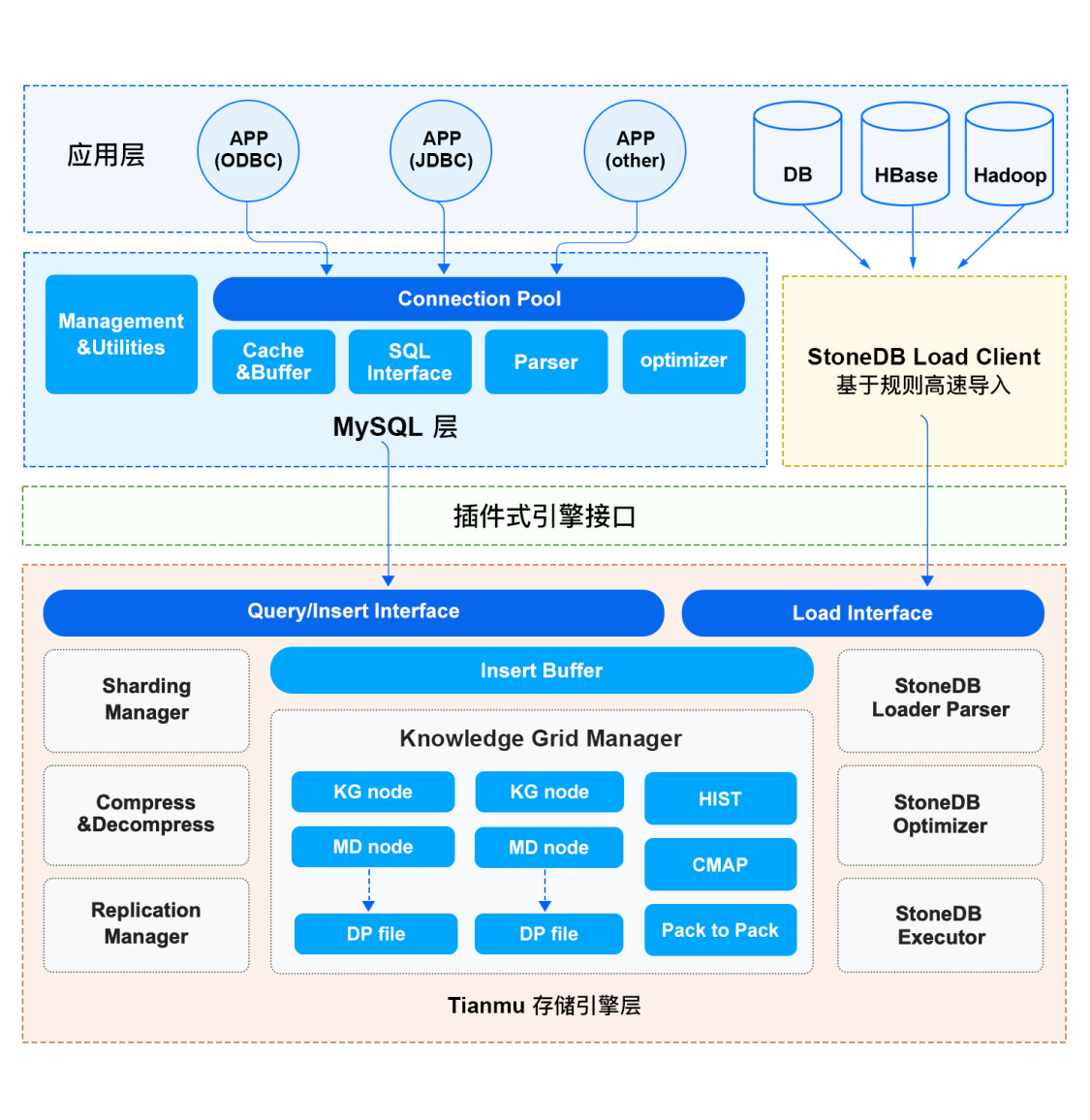

StoneDB 的整体架构分为三层,分别是应用层、服务层和存储引擎层。应用层主要负责客户端的连接管理和权限验证;服务层提供了 SQL 接口、查询缓存、解析器、优化器、执行器等组件;Tianmu 引擎所在的存储引擎层是 StoneDB 的核心,数据的组织和压缩、以及基于知识网格的查询优化均是在 Tianmu 引擎实现。下面为大家详细介绍 StoneDB 整体架构中的主要特性。
列式存储
StoneDB 创建的表在磁盘上是以列模式进行存储的,由于关系型数据库中每一列的数据类型都相同,所以这种连续的空间存储与行式存储相比,更加能够实现数据的高压缩比。在读取数据方面,如果只想查询一个字段的结果,在行式存储中,引擎层向服务层返回的是一整行的数据,需要消耗更多的网络带宽和 IO。而列式存储只需要返回一个字段,极大减少了网络带宽和 IO 的消耗。另外,列式存储无需再为列创建索引和维护索引。
id name age 1 Jack 37 2 Rose 18 3 Jason 26

数据压缩
上面提到同一数据类型的列存储在一起,能够实现数据的高压缩比。StoneDB 会根据不同的数据类型选择不同的压缩算法,目前支持的压缩算法主要有 PPM、LZ4、B2、Delta 等。数据被压缩后,数据量变得更小,在读取数据时,对网络带宽和磁盘 IO 的压力也就越小。由于列式存储相比行式存储有十倍甚至更高的压缩比,StoneDB 可以节省大量的存储空间,降低存储成本。
知识网格管理
当表的数据量达到千万、亿级,在做统计分析类查询时,使用 MySQL 的 InnoDB 存储引擎或其它关系型数据库的行式存储引擎可能需要几分钟到几十分钟才能得到结果集。这是因为基于成本的优化器需要根据表或者索引的统计信息生成执行计划,然后再去读取数据,中间过程会发生 IO,如果统计信息不准,生成了一个错误的执行计划,那么可能会发生更多的 IO。而 StoneDB 的 Tianmu 引擎在相同的数据量下,比 MySQL 的 InnoDB 存储引擎或或其它关系型数据库的行式存储引擎要快数十倍。Tianmu 引擎除了列式存储、数据压缩特性外,还有知识网格技术。在了解知识网格前,需要了解以下几个基本概念。
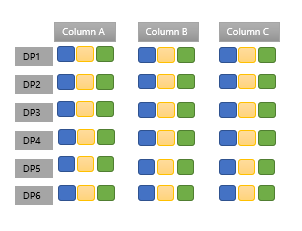
Data Pack
包用于存储实际数据,是最低的数据存储单元。每列按照65536行被分成一个包。每个数据包比列小,压缩比高,而每个数据包大于每行,查询性能更好。包是知识网格的解压缩单元。
[En]
The packet is used to store the actual data and is the lowest data storage unit. Each column is divided into a packet according to 65536 rows. Each packet is smaller than the column and has a higher compression ratio, while each packet is larger than each row and has better query performance. Packet is the decompression unit of knowledge grid.
粗糙集是一门数学学科,用来研究不完整的数据,不精确的知识表达、学习、归纳等的一套理论。在 StoneDB 中,粗糙集用于对数据包的划分,根据 SQL 的查询条件的数据在数据包中的确认范围,数据包分为以下几类:
1)不相关的数据包:表示不满足查询条件的数据包,这类数据包直接被忽略。
2)相关的数据包:表示满足查询条件的数据包,如果要查询相关的数据包里面的具体数据,需要对数据包进行解压缩,如果根据数据包的元数据节点就能得到数据,那么就不需要解压缩数据包。
3)可疑的数据包:表示数据包中的数据部分满足查询条件,需要进一步解压缩数据包才能得到满足条件的数据。
Data Pack Node
数据包节点也称为元数据节点,记录了每个数据包中列的最大值、最小值、平均值、总和、总记录数、null值的数量、压缩方式、占用的字节数。每一个元数据节点对应一个数据包。
Knowledge Node
元数据节点的上层是知识节点,除了记录分组或列之间的关系的元数据集合,如分组的最小值和最大值的范围以及列之间的关系外,还记录了数据特征和更深入的统计信息。大部分知识节点数据是在加载数据时生成的,另一部分是在查询时生成的。
[En]
The upper layer of the metadata node is the knowledge node, in addition to recording the set of metadata that records the relationship between packets or columns, such as the range of minimum and maximum values of packets and the relationship between columns, the data characteristics and more in-depth statistical information are also recorded. Most of the knowledge node data is generated when loading data, and the other part is generated when querying.
知识节点的3种基本类型:
1)Histogram
数据类型为整型、日期型、浮点型的列的统计值以直方图的形式存在。将一个数据包的最小值到最大值之间分为1024段,每段占用一个 bit,如果数据包中的实际值处于段中的范围,则标记为1,否则标记为0。Histogam 在数据被加载时自动创建。
在下面的示例中,显示了数据包中的值介于0100%和102301102400之间。
[En]
In the following example, it is shown that the value in the packet falls between 0100 and 102301102400.
0‒100 101‒200 201‒300 … 102301‒102400 1 0 0 … 1
如果想要执行以下 SQL:
select * from table where id>199 and id
从直方图可以看出,查询没有命中该报文,即当前报文不满足查询条件,直接丢弃该报文。
[En]
From the histogram, we can see that the query did not hit the packet, that is, the current packet does not meet the query conditions, and the packet is directly discarded.
2)Character Map
数据类型为字符串的列的字符映射表。统计当前数据包内 1~64 长度中 ASCII 字符是否存在。如果存在,则标记为1,否则标记为0。字符检索时,按照字符顺序依次对比字符标识值即可知道该数据包是否包含匹配数据。Character Map 在数据被加载时自动创建。
如下的例子中,说明 A 在字符串的第1个和第64个位置。
Char/Char pos 1 2 … 64 A 1 0 … 1 B 0 1 … 0 C 1 1 … 1 … … … … …
3)Pack to Pack
包对包关系表示不同表的两个列之间的等值映射表,并以二进制矩阵的形式进行存储,如果符合表关联条件,则标记为1,否则标记为0。包对包关系能帮助在表关联查询的时候快速判断出符合查询条件的数据包,从而提升表关联查询的效率。表关联查询时,Pack to Pack 被自动创建。
如下的例子中,表关联的查询条件是”A.C=B.D”,在 A.C1 这个数据包中,只有 B.D2 和 B.D5 这两个数据包中有符合表关联条件的值。
B.D1 B.D2 B.D3 B.D4 B.D5 A.C1 0 1 0 0 1 A.C2 1 1 0 0 0 A.C3 1 1 0 1 1
Knowledge Grid
知识网格由元数据节点和知识节点组成,在做统计分析类查询时,StoneDB 根据知识网格技术过滤掉不相关的数据包,如果只剩下相关数据包,那么只需要读取元数据就能返回查询结果。这样就消除了解压缩数据包的过程和降低 IO 消耗,提高了查询响应时间和网络利用率。
接下来,我们通过一个例子来理解一个查询语句在存储引擎层使用知识网格技术的查询优化过程。
有以下查询语句和分组节点的数据值分布范围。
[En]
There are the following query statements and the data value distribution range of the packet node.
select min(t2.D) from t1,t2 where t1.B=t2.C and t1.A>15;
Min. Max. t1.A1 1 9 t1.A2 10 30 t1.A3 40 100
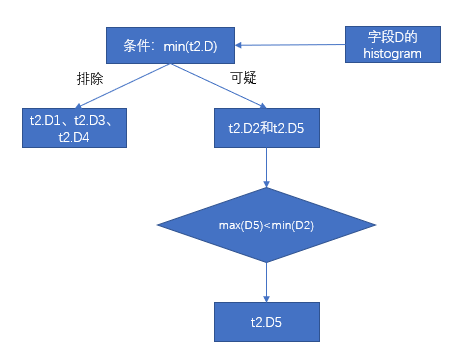
- 根据列 A 的 DPN 可知,t1.A1 属于不相关的数据包,t1.A2 属于可疑的数据包,t1.A3 属于相关的数据包,这一步就过滤掉数据包 t1.A1。
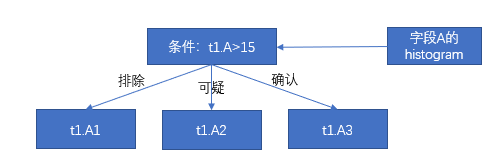
t2.C1 t2.C2 t2.C3 t2.C4 t2.C5 t1.B1 1 1 1 0 1 t1.B2 0 1 0 0 0 t1.B3 1 1 0 0 1
- 第一步已经过滤掉数据包 t1.A1,这一步就不需要对 t1.B1 和 t2.C1 做关联对比,根据包对包关系的映射表可知,这一步过滤掉数据包 t2.C3 和 t2.C4。那么满足关联条件的数据包有 t2.C2 和 t2.C5。
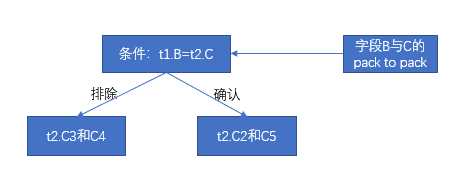
Min. Max. t2.D1 0 500 t2.D2 101 440 t2.D3 300 6879 t2.D4 1 432 t2.D5 3 100
- 第一步和第二步已经过滤掉 D1、D3、D4,那么只剩下 D2 和D5,根据列 D 的 DPN 可知,D5 的最大值100小于 D2 的最小值101,这一步过滤掉数据包 D2。最后只剩下数据包 D5,根据元数据得到 D5 的最小值3。
高性能导入
StoneDB 提供独立的数据导入客户端,支持不同的数据源环境,支持多语言架构。数据在导入前,首先会进行预处理,如数据压缩和知识节点的构建。数据经过预处理后,进入存储引擎无需再次执行解析、数据验证以及事务处理等操作。
于StoneDB的任何问题,都可以加我V咨询:StoneDB_2022 。
Original: https://www.cnblogs.com/yangwilly/p/16596215.html
Author: 来来士
Title: 【StoneDB Class】入门第二课:StoneDB整体架构解析
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/504996/
转载文章受原作者版权保护。转载请注明原作者出处!