

开心一刻
今天,我的朋友怒气冲冲地向我走来。
[En]
Today, my friend came up to me angrily.
朋友:我和一个女朋友聊了三个月了。我昨天偷看了她的手机。猜猜她给了我什么。
[En]
Friend: I’ve been talking to a girlfriend for three months. I peeked at her phone yesterday. Guess what she gave me.
我:备注什么?
朋友:舔狗 2 号!
我一听就生气了,说:你去找她去吧,这个女人真该骂一顿,不要脸。
[En]
As soon as I heard this, I got angry and said, “go and go to her. this woman really should be scolded and shameless.”
我的朋友抓住我,建议我:哦,不是骂她,而是和她争论,让她换成Lick Dog 1号,我先来的!
[En]
My friend grabbed me and advised: Oh, not to scold her, but to argue with her and ask her to change to Lick Dog No. 1. I came first!
我:滚,我不认识你


需求背景
环境
MySQL 版本:8.0.27

共有四个表:业务信息表、任务表、业务任务表、任务执行日志表。
[En]
There are four tables: business information table, task table, business task table, task execution log table.

CREATE TABLE t_business (
business_id BIGINT(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '业务id',
business_name VARCHAR(100) NOT NULL COMMENT '业务名',
note VARCHAR(200) NOT NULL DEFAULT '' COMMENT '备注',
create_user BIGINT(20) NOT NULL COMMENT '创建人',
create_time DATETIME(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3) COMMENT '创建时间',
modify_user BIGINT(20) NOT NULL COMMENT '最终修改人',
modify_time DATETIME(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3) ON UPDATE CURRENT_TIMESTAMP(3) COMMENT '最终修改时间',
PRIMARY KEY (business_id) USING BTREE
) ENGINE=InnoDB COMMENT='业务信息';
CREATE TABLE t_task (
task_id BIGINT(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '任务id',
task_name VARCHAR(100) NOT NULL COMMENT '业务名',
note VARCHAR(200) NOT NULL DEFAULT '' COMMENT '备注',
create_user BIGINT(20) NOT NULL COMMENT '创建人',
create_time DATETIME(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3) COMMENT '创建时间',
modify_user BIGINT(20) NOT NULL COMMENT '最终修改人',
modify_time DATETIME(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3) ON UPDATE CURRENT_TIMESTAMP(3) COMMENT '最终修改时间',
PRIMARY KEY (task_id) USING BTREE
) ENGINE=InnoDB COMMENT='任务信息';
CREATE TABLE t_business_task (
id BIGINT(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '主键id',
business_id BIGINT(20) UNSIGNED NOT NULL COMMENT '业务id',
task_id BIGINT(20) UNSIGNED NOT NULL COMMENT '任务id',
PRIMARY KEY (id) USING BTREE
) ENGINE=InnoDB COMMENT='业务任务关系';
CREATE TABLE t_task_exec_log (
log_id BIGINT(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '日志id',
task_id BIGINT(20) UNSIGNED NOT NULL COMMENT '任务id',
exec_status VARCHAR(50) NOT NULL COMMENT '执行状态, 失败:fail,成功:success',
data_date DATE NOT NULL COMMENT '数据日期',
note VARCHAR(200) NOT NULL DEFAULT '' COMMENT '备注',
create_user BIGINT(20) NOT NULL COMMENT '创建人',
create_time DATETIME(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3) COMMENT '创建时间',
modify_user BIGINT(20) NOT NULL COMMENT '最终修改人',
modify_time DATETIME(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3) ON UPDATE CURRENT_TIMESTAMP(3) COMMENT '最终修改时间',
PRIMARY KEY (log_id) USING BTREE
) ENGINE=InnoDB COMMENT='任务执行日志';
View Code
它们关系如下

一个业务中有多个任务,一个任务可以属于不同的业务。同一业务下,一项任务最多关联一次。
[En]
There are multiple tasks in a business, and a task can belong to different businesses. Under the same business, a task can be associated at most once.
每次执行任务都会生成执行日志,执行日志的数据日期小于等于任务执行的当前日期,例如昨天执行的任务的数据日期可以是前天
[En]
Each time the task is executed, an execution log is generated; the data date of the execution log is less than or equal to the current date of the task execution, for example, the data date of the task executed yesterday can be the day before yesterday
四张表的数据量分别如下
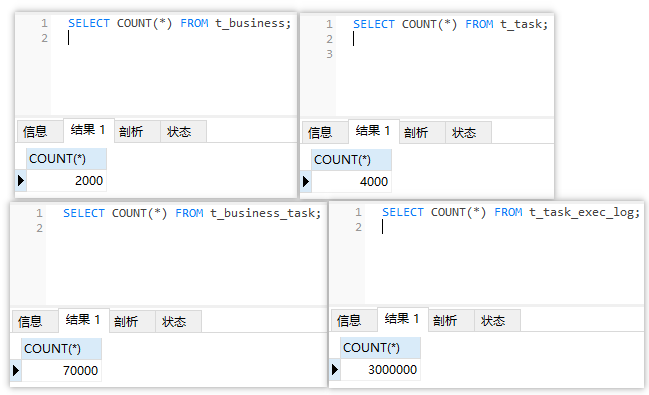
需求
按业务分页,每个业务可以展开显示关联的任务信息以及该任务的最新执行成功信息
[En]
Paged by business, each business can expand and display the associated task information as well as the latest execution success information of the task
任务的最新执行成功信息:状态为成功,是数据日期最大的执行日志消息,如果数据日期相同,取最后修改时间最长的
[En]
The latest execution success information of the task: the status is successful and the execution log message with the largest data date; if the data date is the same, take the one with the largest final modification time
后端返回的 JSON 数据类似如下

实现方式
先分页查业务和任务,再根据任务id循环查最新的执行成功信息
1、关联查询业务和任务
如果查询条件带任务信息(任务ID,任务名),那么 t_business 需要关联 t_business_task 、 t_task 来查
由于这三个表中的数据量相对较小,因此检查链接表不存在问题。
[En]
Because the amount of data in these three tables is relatively small, there is no problem with checking the linked tables.
2、根据上一步查到的 task_id 集逐个去查 t_task_exec_log
SQL 类似如下

可以建个组合索引 idx_status_task_date_modify(exec_status,task_id,data_date,modify_time)
3、将第 1、2 步的数据进行组合
将任务的最新成功执行信息添加到任务信息中
[En]
Add the latest successful execution information of the task to the task information
逻辑非常清晰,代码实现起来非常简单。
[En]
The logic is very clear and the code is very simple to implement.
但是,一个任务id就查一次数据库,这显然是有很大性能问题的(一般,公司的开发规范内都会有一条:禁止循环查数据库)
先分页查业务和任务,再根据任务id批量查最新的执行成功信息
1、关联查询业务和任务
2、根据第 1 步查到的任务id集批量查 t_task_exec_log
因为这是多个任务一起查,也就没法用 LIMIT 1 了
那么,如何找到每项任务成功执行的最新记录呢?
[En]
So how do you find out the latest record of successful execution of each task?
这也与文章的标题相对应:分组后取每组第一条记录
[En]
This also corresponds to the title of the article: * take the 1st record of each group after grouping *
实际上有很多方法可以实现它,我在这里提供一种方法,如下所示
[En]
There are actually many ways to implement it, and I offer one here, as follows

结合索引 idx_status_task_date_modify(exec_status,task_id,data_date,modify_time) ,查询速度还行
大家细看这个 SQL ,是不是发现了有意思的东西: GROUP_CONCAT(log_id ORDER BY data_date DESC,modify_time DESC)
这是一个知识盲区吗?有什么事吗?
[En]
Is it a knowledge blind area? is there something?
GROUP_CONCAT 语法 GROUP_CONCAT(DISTINCT expression ORDER BY expression SEPARATOR sep);

3、将第 1、2 步的数据进行组合
新增任务最新执行成功记录表
一般来说,数据量大的日志表不会参与复杂的查询,所以会单独取出一个表来记录任务最新成功执行的信息。
[En]
Generally speaking, log tables with large amounts of data do not participate in complex queries, so a separate table is taken out to record the latest successful execution information of the task.

一个任务最多只有一条记录,不存在则直接插入表中,存在则根据 data_date DESC,modify_time DESC 与表中记录做比较,看是否需要进行表中记录更新
因为一个任务最多只有一条记录,那么 t_task_latest_exec_log 的数据量是 小于等于 t_task 的数据量的,也就是说数据量不大
那么用一个 SQL 就可以实现业务(直接联表 t_business 、 t_business_task 、 t_task 、 t_task_latest_exec_log )
然后在后端代码中对数据格式进行处理,返回前端需要的格式。
[En]
Then the data format is processed in the back-end code to return the format needed by the front end.
新增表格后,如何导入其初始数据?
[En]
After adding a new table, how to import its initial data?

总结
1、大家写 SQL 的时候,一定要多结合执行计划来写
神奇的 SQL 之 MySQL 执行计划 → EXPLAIN,让我们了解 SQL 的执行过程!
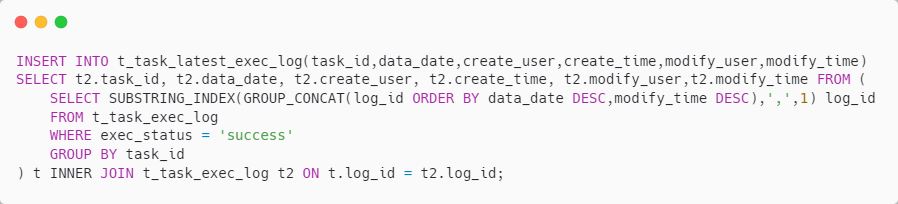
2、 t_task_latest_exec_log 初始数据的导入
其实比较简单, 如下所示
INSERT INTO t_task_latest_exec_log(task_id,data_date,create_user,create_time,modify_user,modify_time)
SELECT t2.task_id, t2.data_date, t2.create_user, t2.create_time, t2.modify_user,t2.modify_time FROM (
SELECT SUBSTRING_INDEX(GROUP_CONCAT(log_id ORDER BY data_date DESC,modify_time DESC),',',1) log_id
FROM t_task_exec_log
WHERE exec_status = 'success'
GROUP BY task_id
) t INNER JOIN t_task_exec_log t2 ON t.log_id = t2.log_id;
View Code
一定要去执行,你会发现大惊喜!
3、多和同事沟通,多和需求方沟通
多与同事交流,集思广益,你可能会找到合适的解决方案。
[En]
Communicate more with colleagues and draw on collective wisdom, and you may find a suitable solution.
多与需求方沟通,多谈个人意见。也许需求改变了,失去了,但我们实现起来要容易得多。
[En]
Communicate more with the demand side and talk more about personal opinions. Maybe the demand is changed and lost, but it is much easier for us to achieve.
4、留疑
1、分组后如何取前 N 条
2、分组后如何取倒数 N 条
Original: https://www.cnblogs.com/youzhibing/p/16597016.html
Author: 青石路
Title: 记一次有意思的 SQL 实现 → 分组后取每组的第一条记录
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/504972/
转载文章受原作者版权保护。转载请注明原作者出处!