

⛳️ 实战场景
本次要分析的站点是 credit.acla.org.cn/,一个律师群体常去的站点,作为一个爬虫工程师,这简直是送自己去喝茶。
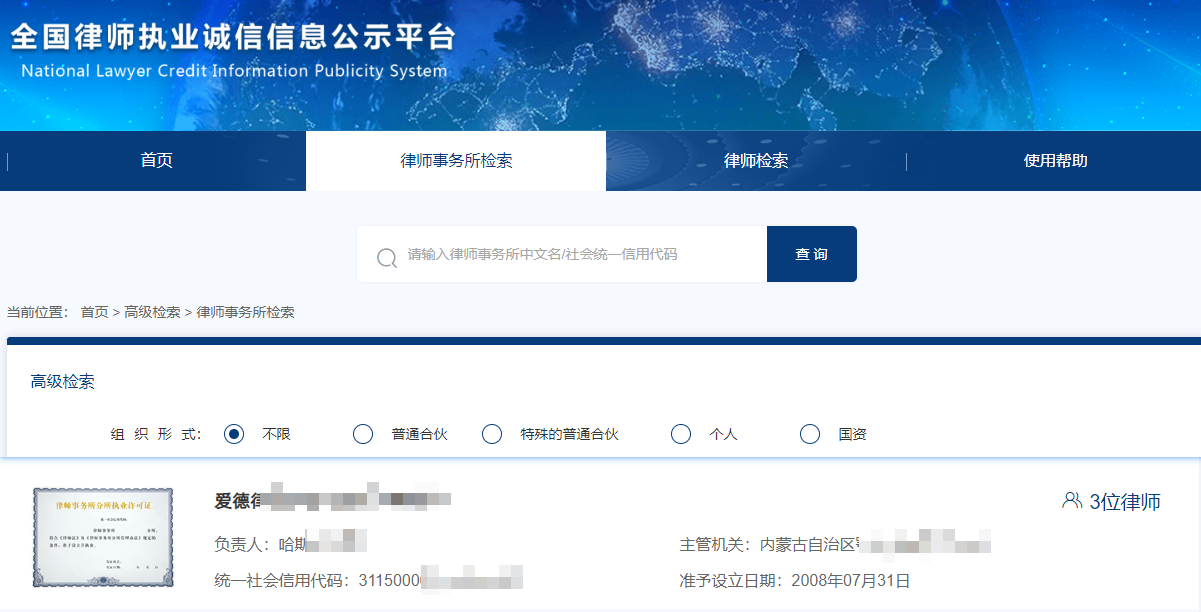

⛳️ 反爬实战
打开开发者工具,无限 debugger
(function anonymous() {
debugger;
});
直接行号处右键 一律不在此处暂停
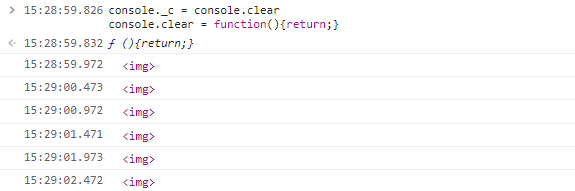
// 取消清空方法
console._c = console.clear;
console.clear = function () {
return;
};
console._l = console.log;
console.log = function () {
return;
};

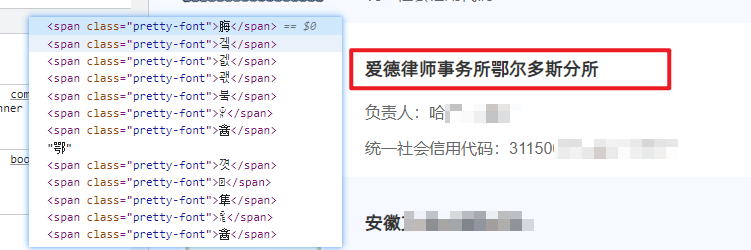
类 JSFUCK 加密反爬
简单的反爬行方法已经解决,让我们尝试获取网页数据,如下面的测试代码所示。
[En]
The simple anti-crawling method has been solved, so let’s try to get the web page data, as shown in the test code below.
import requests
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)",
"referer": "https://credit.acla.org.cn/"
}
res = requests.get('https://credit.acla.org.cn/credit/lawFirm?picCaptchaVerification=&keyWords=',headers=headers)
print(res.text)

注意不要在 Pycharm 等工具的控制台直接复制代码去开发者工具中运行,要写入文件,然后复制整行内容。
在打开一个站点的控制台,例如百度,然后唤醒控制台,删除 $=~[]……() 代码段最后的 (),然后执行。

PyMiniRacer 是适用于 Python 的最小的现代嵌入式 V8。PyMiniRacer 支持最新的 ECMAScript 标准,支持 Assembly,并提供可重用的上下文。
本部分代码如下所示。
import requests
import re
from py_mini_racer import MiniRacer
import execjs
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.67 Safari/537.36",
"referer": "https://credit.acla.org.cn/credit/lawFirm?picCaptchaVerification=&keyWords="
}
res = requests.get('https://credit.acla.org.cn/credit/lawFirm?picCaptchaVerification=&keyWords=',headers=headers)
with open('aaa.html', 'w') as f:
f.write(res.text)
pattern = re.compile('(\$\=\~\[\];.*?[\s\S]*)')
data = pattern.findall(res.text)[0]
print(data[0])
script_str = data[:-1].strip()
script_str = script_str.replace('();','')
"""
删除最终的自执行代码
script_str = script_str.replace(')();','')
删除包裹函数
script_str = script_str.replace(';$.$(',';')
"""
ctx = MiniRacer()
print(script_str)
print(ctx.eval(script_str))

删除最终的自执行代码
script_str = script_str.replace(')();','')
删除包裹函数
script_str = script_str.replace(';$.$(',';')


function decryptByDES(ciphertext, key) {
var keyHex = CryptoJS.enc.Utf8.parse(key);
var decrypted = CryptoJS.DES.decrypt(
{
ciphertext: CryptoJS.enc.Base64.parse(ciphertext),
},
keyHex,
{
mode: CryptoJS.mode.ECB,
padding: CryptoJS.pad.Pkcs7,
}
);
return decrypted.toString(CryptoJS.enc.Utf8);
}
剩下的事情就是秘钥 keyHex 的获取,这部分稍加调试即可实现。
⛳️ 反爬总结
真没想到,一个网站的搜索页面上有这么多防爬行手段,看来律师事务所的数据不好收集,拜托,版权问题,不能发布完整的代码,如果需要获取,请点击卡。
[En]
Really did not expect that there are so many anti-crawling means on the search page of a site, it seems that the data of the law firm is not easy to collect, come on, copyright issues, can not release the complete code, if you need to get, please click on the card.
📢📢📢📢📢📢 💗 你正在阅读 【梦想橡皮擦】 的博客 👍 阅读完毕,可以点点小手赞一下 🌻 发现错误,直接评论区中指正吧 📆 橡皮擦的第 篇原创博客
Original: https://blog.51cto.com/cnca/5546530
Author: 梦想橡皮擦
Title: 在座的Python爬虫工程师,你敢爬律师事务所站点吗?
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/504461/
转载文章受原作者版权保护。转载请注明原作者出处!