

tensorflow的gpu和cpu计算时间对比的小例子
原创
楚千羽©著作权
文章标签 Python tensorflow 2d 卷积 文章分类 Python 后端开发
©著作权归作者所有:来自51CTO博客作者楚千羽的原创作品,请联系作者获取转载授权,否则将追究法律责任
例子1
参数设置
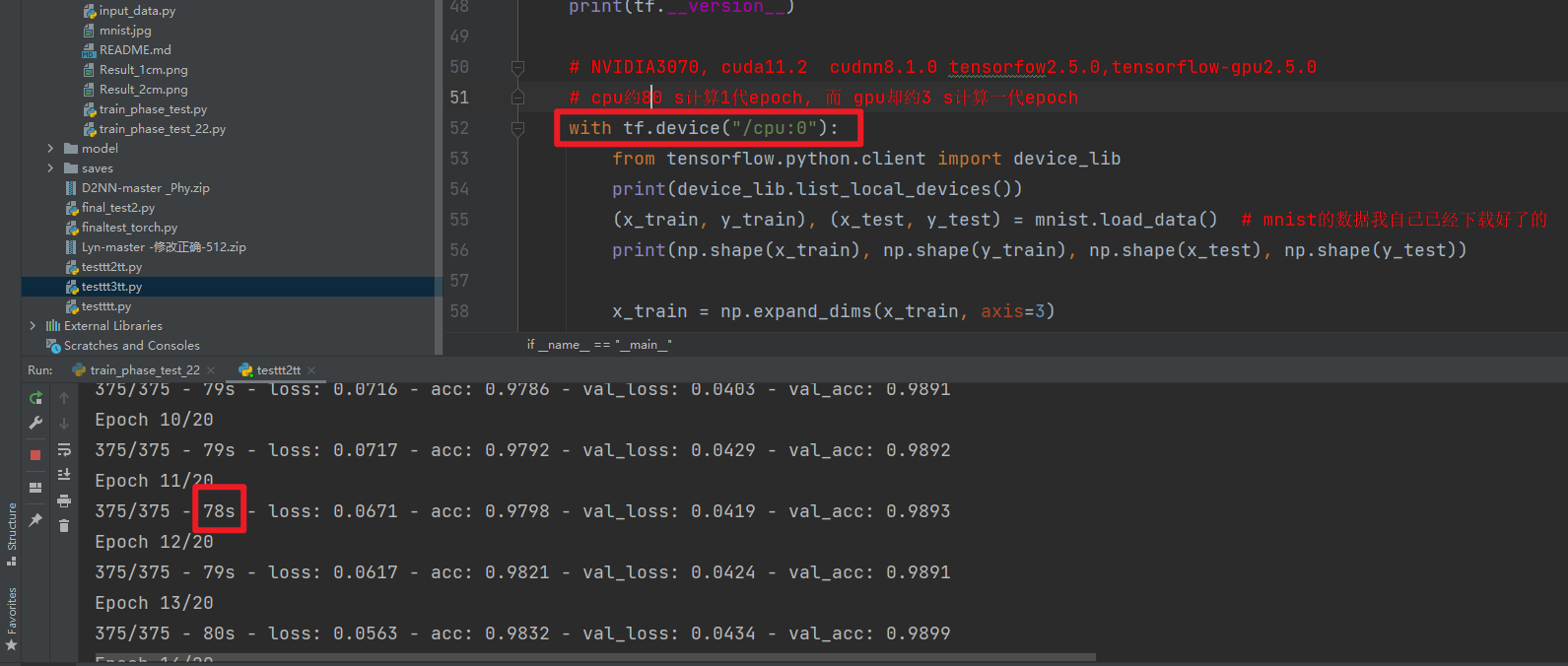
NVIDIA3070, cuda11.2 cudnn8.1.0 tensorfow2.5.0,tensorflow-gpu2.5.0
cpu约80 s计算1代epoch, 而 gpu却约3 s计算一代epoch
-*- coding: utf-8 -*-# @Time : 2022/6/11 16:03# @Author : chuqianyu# @FileName: testtt2tt.py# @Software: PyCharm# # 指定GPU训练# import os# os.environ["CUDA_VISIBLE_DEVICES"]="/gpu:0" ##表示使用GPU编号为0的GPU进行计算import numpy as npfrom tensorflow.keras.models import Sequential # 采用贯序模型from tensorflow.keras.layers import Dense, Dropout, Conv2D, MaxPool2D, Flattenfrom tensorflow.keras.datasets import mnistfrom tensorflow.keras.utils import to_categoricalfrom tensorflow.keras.callbacks import TensorBoardimport timedef create_model(): model = Sequential() model.add(Conv2D(32, (5, 5), activation='relu', input_shape=[28, 28, 1])) # 第一卷积层 model.add(Conv2D(64, (5, 5), activation='relu')) # 第二卷积层 model.add(MaxPool2D(pool_size=(2, 2))) # 池化层 model.add(Flatten()) # 平铺层 model.add(Dropout(0.5)) model.add(Dense(128, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(10, activation='softmax')) return modeldef compile_model(model): model.compile(loss='categorical_crossentropy', optimizer="adam", metrics=['acc']) return modeldef train_model(model, x_train, y_train, batch_size=128, epochs=10): tbCallBack = TensorBoard(log_dir="model", histogram_freq=1, write_grads=True) history = model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, shuffle=True, verbose=2, validation_split=0.2, callbacks=[tbCallBack]) return history, modelif __name__ == "__main__": import tensorflow as tf print(tf.__version__) # NVIDIA3070, cuda11.2 cudnn8.1.0 tensorfow2.5.0,tensorflow-gpu2.5.0 # cpu约80 s计算1代epoch, 而 gpu却约3 s计算一代epoch with tf.device("/gpu:0"): from tensorflow.python.client import device_lib print(device_lib.list_local_devices()) (x_train, y_train), (x_test, y_test) = mnist.load_data() # mnist的数据我自己已经下载好了的 print(np.shape(x_train), np.shape(y_train), np.shape(x_test), np.shape(y_test)) x_train = np.expand_dims(x_train, axis=3) x_test = np.expand_dims(x_test, axis=3) y_train = to_categorical(y_train, num_classes=10) y_test = to_categorical(y_test, num_classes=10) print(np.shape(x_train), np.shape(y_train), np.shape(x_test), np.shape(y_test)) model = create_model() model = compile_model(model) print("start training") ts = time.time() history, model = train_model(model, x_train, y_train, epochs=20) print("start training", time.time() - ts)
gpu约3 s计算一代epoch
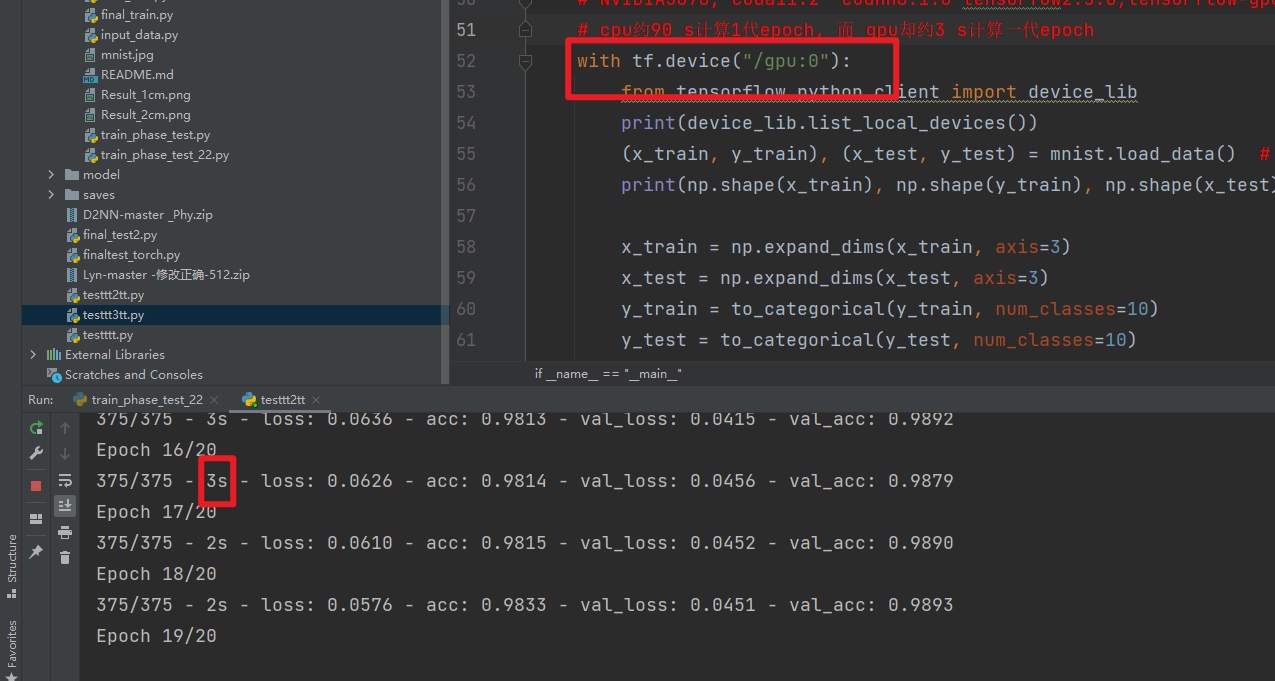

cpu约80 s计算一代epoch
例子2
-*- coding: utf-8 -*-# @Time : 2022/6/11 20:32# @Author : chuqianyu# @FileName: testtt3tt.py# @Software: PyCharmimport tensorflow as tffrom tensorflow.keras import *import timetf.config.set_soft_device_placement(True)tf.debugging.set_log_device_placement(True)gpus = tf.config.experimental.list_physical_devices('GPU')print(gpus)tf.config.experimental.set_visible_devices(gpus[0], 'GPU')tf.config.experimental.set_memory_growth(gpus[0], True)t=time.time()with tf.device("/gpu:0"): tf.random.set_seed(0) a = tf.random.uniform((10000,10000),minval = 0,maxval = 3.0) c = tf.matmul(a, tf.transpose(a)) d = tf.reduce_sum(c)print('gpu: ', time.time()-t)t=time.time()with tf.device("/cpu:0"): tf.random.set_seed(0) a = tf.random.uniform((10000,10000),minval = 0,maxval = 3.0) c = tf.matmul(a, tf.transpose(a)) d = tf.reduce_sum(c)print('cpu: ', time.time()-t)

- 赞
- 收藏
- 评论
- *举报
下一篇:重要学习网址收藏3
Original: https://blog.51cto.com/u_15240054/5548981
Author: 楚千羽
Title: tensorflow的gpu和cpu计算时间对比的小例子
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/504443/
转载文章受原作者版权保护。转载请注明原作者出处!