

一、引言
最近在进行大创项目的结题工作,一开始的数据处理过程,是用C#处理的,想着最近在学python,就试了试用python做了下。下面来分享下我的处理流程,目前还处于初学阶段,有不足之处欢迎指点。
二、数据介绍
先看一下要处理的数据。

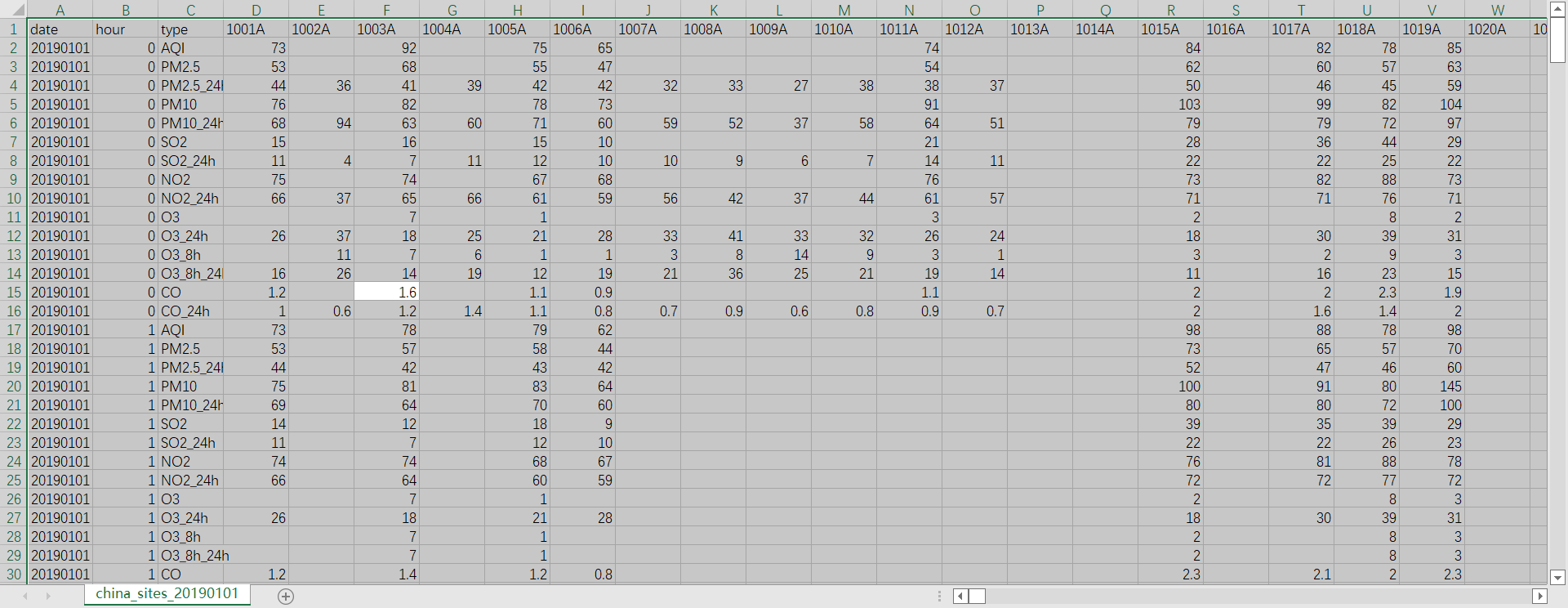
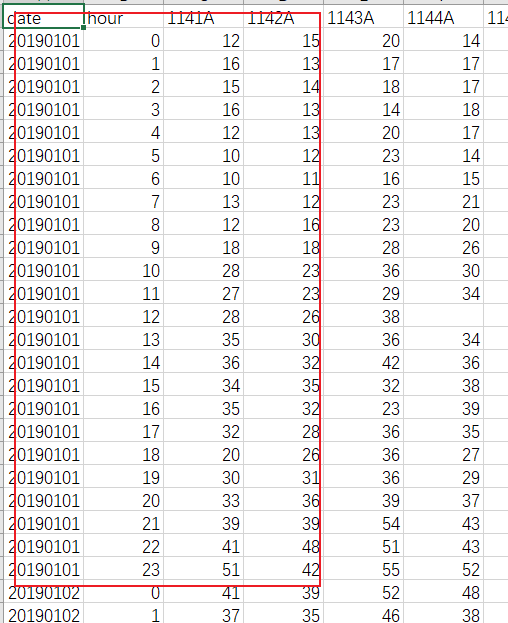
下面是具体20190101的站点数据,只列出了其中一部分。
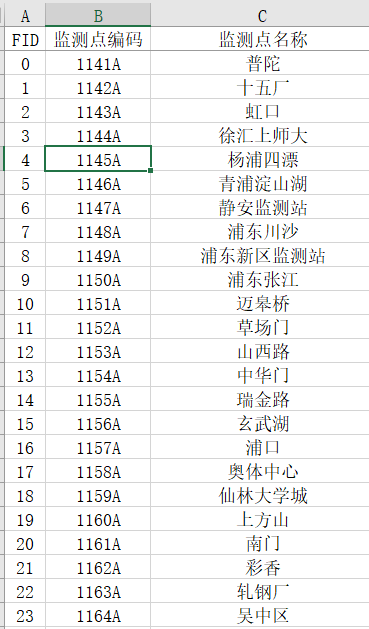
两个文件夹分别 为19年和20年的全国气象站点数据,目标是要从这里面筛选出江苏省内的以及周边区域邻近的站点的PM2.5数据,并计算其月均值数据。我将要筛选的站点数据存储在了一个excel表格里,样式如下:(数据只截取了一小部分)
三、数据处理
现在您想要过滤数据,第一步是读取所需的站点代码。简单介绍我的数据处理流程,阅读目标站点,过滤每天和每小时的数据,计算日平均,计算月平均。
[En]
Now that you want to filter the data, the first step is to read the required site code. Briefly introduce my data processing process, read the target site, filter the daily and hourly data, calculate the daily average, and calculate the monthly average.
1.读取站点编码
站点存储在excel文件里,因此要使用python来操作excel文件,这里我引用了openpyxl,下面是处理的代码(跳转至完整代码)
第一步导入openpyxl,
import openpyxl as xl
使用openpyxl库的load_workbook()来获得存储站点的excel文件
wb = xl.load_workbook(filename)
因为数据都是存储在工作簿的表里的,因此我们要获得工作簿里的表,也就是Sheet1,
sheet = wb['Sheet1']
在开始读数据前,先定义一个用于存储站点数据的列表,这里我定义的初始列表里有两个值,’date’,’hour’,这两个值用来标识所读取的PM2.5的数据的生产时间。
station_id = ['date', 'hour']
下面是开始读数据,遍历sheet1的每一行,将数据存储在station_id里,
for row in range(2, sheet.max_row+1):
cell = sheet.cell(row, 2)
station_id.append(cell.value)
因为我这里存放目标站点编号的表格里存在多个空行,因此会station_id的后面会存放很多None(excel里的单元格为空的话就是None)

于是需要把station_id里的多余的None去除
if(None in station_id):
index = station_id.index(None)
del station_id[index:]
将上述代码封装在一个函数中。完整的代码如下:
[En]
Encapsulate the above code in a function. The complete code is as follows:
import openpyxl as xl
'''
获得站点坐标,此处是以站点存储在excel里为例,并且是存放在一列,且是在第2列
'''
def get_station_id(filename):
# 获得路径对应的工作簿
wb = xl.load_workbook(filename)
# 获得工作簿里的表
sheet = wb['Sheet1']
# 定义一个存储站点的数据列表
station_id = ['date', 'hour']
# 遍历表,将站点信息存储在list里
for row in range(2, sheet.max_row+1):
cell = sheet.cell(row, 2)
station_id.append(cell.value)
# 删除id_list中的空数据,因为有可能最大行数会超过excel的实际数据行数
if(None in station_id):
index = station_id.index(None)
del station_id[index:]
return station_id
以上代码我单独放在了get_station_id.py文件里
2.筛选目标站点的数据
简单说下处理流程,先是获得存放上面两个csv文件夹的文件夹,也叫父级路径,再获得文件夹下的所有csv文件(这一步要尽量保证没有其他csv文件),最后是遍历读取需要的数据并写入一个csv,存放着天小时的目标站点的PM2.5数据。(跳转至完整代码)
第一步,通过pathlib的Path来获得父级路径。导入pathlib 下的Path类,以及接下来要进行处理csv文件所需的csv库
from pathlib import Path
import csv
获得存放csv文件夹的路径,并定义一个要存放数据的csv文件路径,
csv_dir = Path(r'F:\College\FileRecv\大创项目\站点数据201901-202012')
target = r'F:\College\FileRecv\大创项目\19-20-hours.csv'
获得路径下的所有csv文件
csv_list = list(csv_dir.rglob('*.csv'))
定义一个写入流,做好写入数据的准备,这里用dictwriter的写入方法,是因为在要处理的数据文件中,有的站点在某一年或某几个月中并不存在,这样处理更为准确方便。
with open(target, 'w', newline='') as out_file: writer = csv.DictWriter(out_file, fieldnames=station_id)
接下来是写入列头,将station_id写入要存放数据的csv(target)的第一行:
writer.writeheader()
遍历读取站点csv文件,筛选数据写入target,
for filename in csv_list:
with open(filename, 'r') as file:
# 将行数据映射到字典
reader = csv.DictReader(file)
for row in reader:
# 判断当前数据是否是PM2.5
if row['type'] == datatype:
# 查找对应station_id的数据,并存储在一个list里
# data = {}
# for id in station_id:
# if id in row:
# data[id] = row[id]
data = {id: row[id] for id in station_id if id in row}
writer.writerow(data)
这一数据处理步骤是成功的。我将其封装在一个方法中。完整的代码如下:
[En]
This step of data processing is successful. I encapsulate it in a method. The complete code is as follows:
from pathlib import Path
import csv
import get_station_id #
"""
获得指定站点编号的数据,并写入一个csv文件
输入的参数分别是 csv_dir----csv文件所在的目录的路径,
以及要写到目标文件的路径 target
station_id 站点编号
"""
def get_write_from_csv(csv_dir, target, station_id=['date', 'hour', '1141A'], datatype='PM2.5'):
# 判断路径是否正确
if not csv_dir.is_dir():
return
# 获得路径下所有的csv文件
csv_list = list(csv_dir.rglob('*.csv'))
with open(target, 'w', newline='') as out_file:
writer = csv.DictWriter(out_file, fieldnames=station_id)
# 写入头,station_id
writer.writeheader()
# 遍历csv文件并选择数据写入target
for filename in csv_list:
with open(filename, 'r') as file:
# 将行数据映射到字典
reader = csv.DictReader(file)
for row in reader:
# 判断当前数据是否是PM2.5
if row['type'] == datatype:
# 查找对应station_id的数据,并存储在一个list里
# data = {}
# for id in station_id:
# if id in row:
# data[id] = row[id]
data = {id: row[id] for id in station_id if id in row}
writer.writerow(data)
print('successed')
csv_dir = Path(r'F:\College\FileRecv\大创项目\站点数据201901-202012')
target = r'F:\College\FileRecv\大创项目\19-20-hours.csv'
存放着stationID的excel文件
filename = r'F:\College\FileRecv\大创项目\1920.xlsx'
获得stationid
station_id = get_station_id.get_station_id(filename)
get_write_from_csv(csv_dir, target, station_id)
3.对已筛选的数据进行计算日均值
观察一下数据构成,发现可以通过date这一列进行分组来进行计算日均值。(跳转至完整代码)
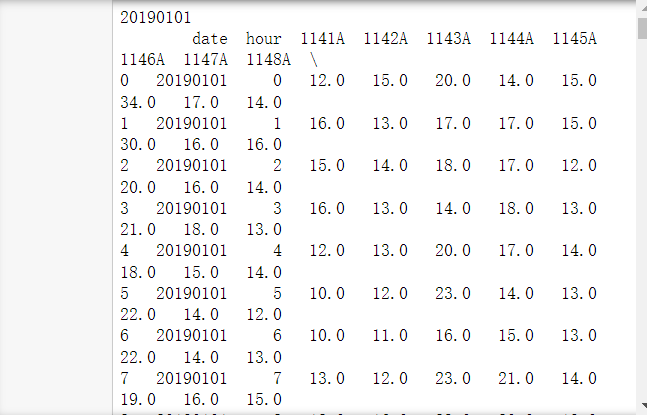
谈到分组就想到了pandas的groupby函数,要得到日均值只要按date这列分组就行了,首先导入需要的库,
import pandas as pd
import numpy as np
读取已筛选好的csv数据
df=pd.read_csv(r'F:\College\FileRecv\大创项目\target.csv')
将读取到的数据按date分组
day_group=df.groupby('date')
您可以使用以下代码查看分组结果
[En]
You can view the results of the grouping with the following code
for date,group in day_group:
print(date)
print(group)
下一步是对组进行平均化并查看聚合结果。
[En]
The next step is to average the groups and view the results of the aggregation.
data=day_group.agg(np.mean)
print(data)
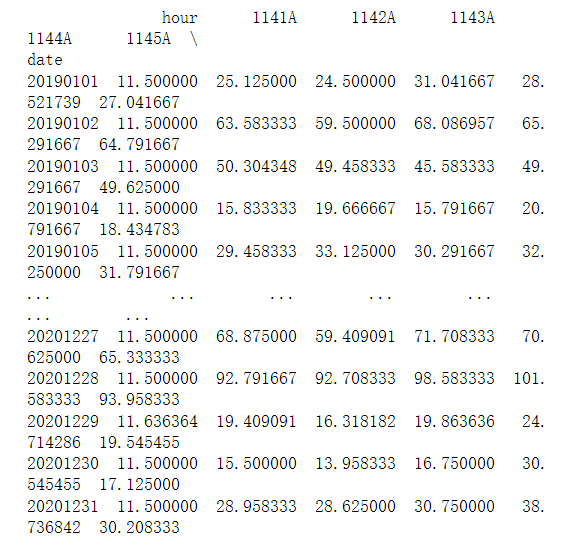
发现hour这列也被求平均了,这一列在接下来的处理中是不需要的,因此将它删去。
day_data=data.drop('hour',axis='columns')
将删去后的数据写入daydata.csv(存储日均值数据)
day_data.to_csv('daydata.csv')
完整代码如下:
import pandas as pd
import numpy as np
df=pd.read_csv(r'F:\College\FileRecv\大创项目\target.csv')
day_group=df.groupby('date')
data=day_group.agg(np.mean)
day_data=data.drop('hour',axis='columns')
day_data.to_csv('daydata.csv')
4.计算月均值
对处理好的日均值数据来求月均值,首先是要将数据按月来归类,简单讲下我的思路,首先将数据按年分开分为19年和20年的数据。再对19和20年的数据按月分类聚合求均值。(跳转至完整代码)
第一步,按年分割数据,
df=pd.read_csv('daydata.csv')
年份区开数据
data2019=df[df['date']]
data2020=df[df['date']>=20200101]
第二步,对各年的按月分类聚合求均值。考虑到date这列的数据类型是数字,可以通过按条件筛选属于某一月的数据,
def get_month_data(data,month_start,month_end):
month=data[(data['date']'date']>=month_start)]
这里聚合操作也将日期进行聚合了
return month.agg(np.mean)
第三步,获得某年的月均值数据,并写入csv文件。考虑到0101到0201之间差了100,(实际上两个月之间最多只差31天)设置了步长为100的形式来获得月均值,
def write_month_data(year_data,outfilename,month_start=20190101,step=100):
month_list=[]
获得每月均值数据,并添加到list里
for num in range(12):
month_data=get_month_data(year_data,month_start,month_start+step)
month_list.append(month_data)
month_start+=step
将list生成dataframe
df=pd.DataFrame(month_list)
修改日期格式为201901这种年加月形式
df['date']=df['date'].apply(lambda x: int(x/100))
df.to_csv(outfilename)
下面是完整的代码
import pandas as pd
import numpy as np
df=pd.read_csv('daydata.csv')
年份区开数据
data2019=df[df['date']]
data2020=df[df['date']>=20200101]
data2020.agg(np.mean)
def get_month_data(data,month_start,month_end):
month=data[(data['date']'date']>=month_start)]
这里聚合操作也将日期进行聚合了
return month.agg(np.mean)
def write_month_data(year_data,outfilename,month_start=20190101,step=100):
month_list=[]
获得每月均值数据,并添加到list里
for num in range(12):
month_data=get_month_data(year_data,month_start,month_start+step)
month_list.append(month_data)
month_start+=step
将list生成dataframe
df=pd.DataFrame(month_list)
修改日期格式为201901这种年加月形式
df['date']=df['date'].apply(lambda x: int(x/100))
df.to_csv(outfilename)
month_start2019=20190101
month_start2020=20200101
step=100 #因为20190101-20190201=-100
write_month_data(data2019,'19month.csv',month_start2019,step)
write_month_data(data2020,'20month.csv',month_start2020,step)
结果图:
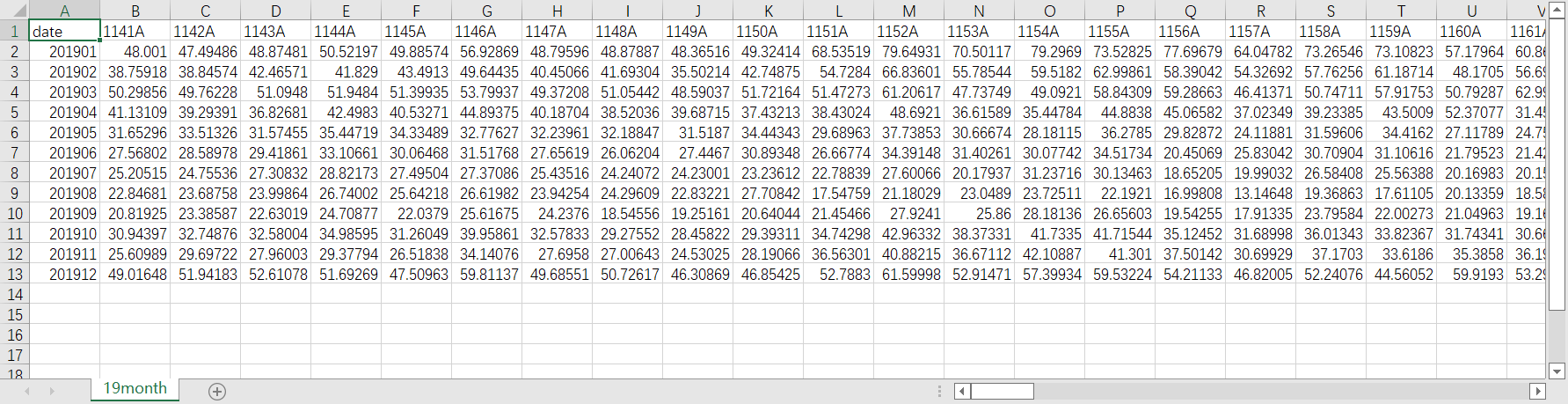
结语:以上就是我使用python处理数据的全流程了,作为一个python新手,如有错误还请指点,感谢大家花费宝贵的时间来阅读。
Original: https://www.cnblogs.com/madaao/p/16214692.html
Author: 百分号
Title: python 处理气象站点csv数据以及简单excel读写操作
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/499678/
转载文章受原作者版权保护。转载请注明原作者出处!