

项目已免费开源:https://gitee.com/zhengzsj/automatic-speech-recognition–ars/tree/master
1、技术路线
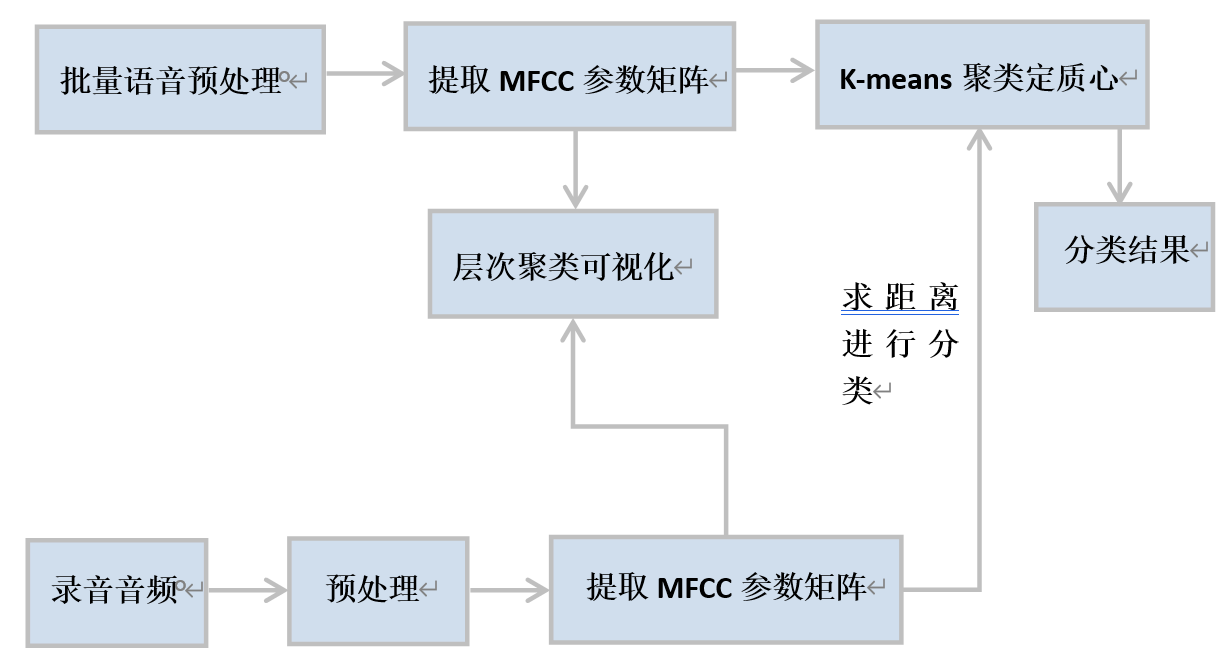

; 2、实现过程
层次聚类和K-means聚类的样本是0-9语音每个数字各5个,分类时加入一个新录入的语音与之前的50个样本进行分类,并与10个K-means聚类求出的质心求距离,在通过实验确定的阈值约束下,选取最小值进行分类,如果最小值大于阈值则显示无法识别。
语音预处理和提取MFCC参数矩阵在这里不再赘述,求出MFCC矩阵之后对行取平均值,即对所有帧的MFCC参数求取平均,为简化运算和消除高频与低频噪音的影响,取第2-20个MFCC参数作为聚类样本,因此高维数据变成1*18维数据,可直接进行层次聚类和K-means聚类,层次聚类和K-means聚类都直接调用MATLAB提供的函数,求距离用欧氏距离。
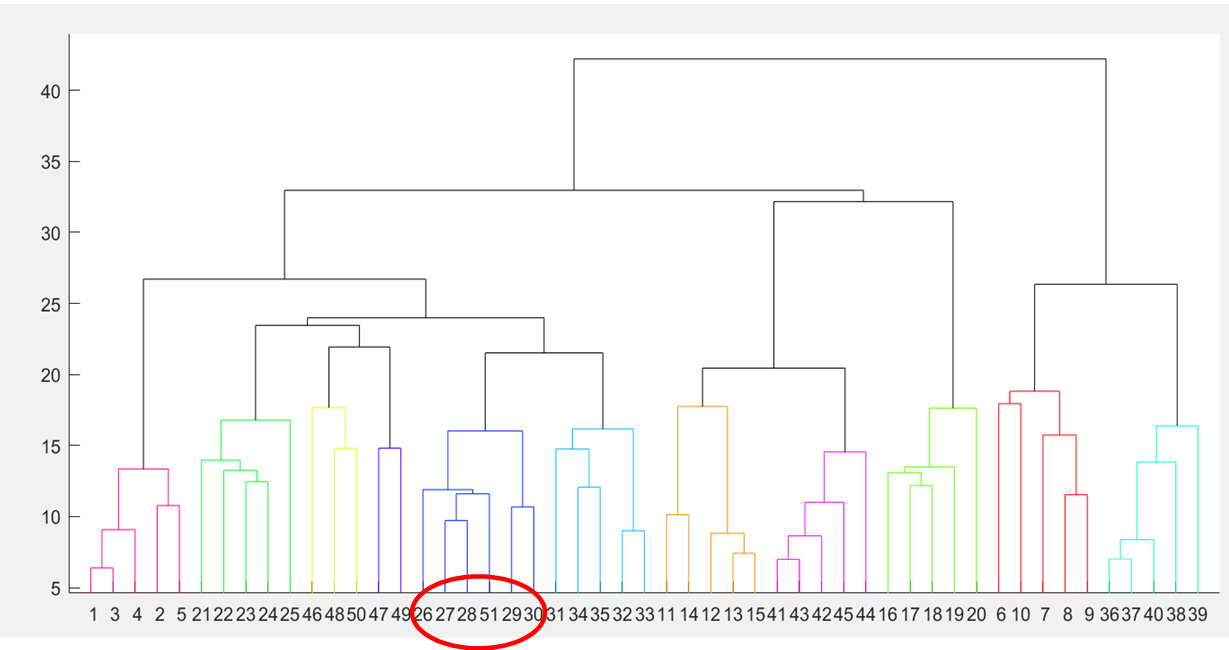
3、聚类、分类效果
从图中可以看出,层次聚类效果非常好。5个数量相近的样本属于同一个数,即将相同颜色的数据聚为一组,聚类准确率可达87.96%。同时对录音《5》(档号51)进行分类,分类正确,但经多次实验验证,分类准确率不高,最高分类准确率只能达到30%左右。
[En]
It can be seen from the figure that the hierarchical clustering effect is very good. Five samples with similar numbers belong to the same number, that is, the data of the same color are clustered into the same group, and the clustering accuracy can reach 87.96%. At the same time, recording’5′ (file No. 51) is classified, and the classification is correct, but many experiments have verified that the classification accuracy is not high, and the highest classification accuracy can only reach about 30%.
; 4、GUI界面
聚类、分类GUI界面如下,左边’开始’、’停止’可输入语音,中间坐标轴可视化层次聚类结果和输入语音分类结果,下边显示与K-means聚类质心进行分类的结果。同时作为服务机,可以接受客户机发送到数据并显示到下方聚类结果显示栏,同时电子音一一播放接收的数据,可清除聚类结果显示栏和坐标。

5、结果与结论
( 1)当说0时,层次聚类后分类效果不错,其与K-means聚类质心距离和质心间的距离如表1、表2。

样本与质心距离的阈值为500,样本‘0’与数字‘0’的距离仅为88.85,但样本与所有粒子的距离较小,质心之间的类间距特别大。聚类数据之间的类间距也很大,样本和质心之间的类内距离很小,但样本和其他质心之间的类间距也很小。这也可能是分类准确率较低的原因之一。此外,数据降维的平均方式过于简单粗暴,可能会丢失大量有效信息,这也是影响分类效果的一大原因。
[En]
The threshold of the distance between the sample and the centroid is 500, and the distance between the sample’0′ and the number’0′ is only 88.85, but the distance between the sample and all the particles is relatively small, and the class spacing between the centroids is particularly large. The class spacing between the clustering data is also very large, and the intra-class distance between the sample and the centroid is very small, but the class spacing between the sample and other centroids is also very small. This may also be one of the reasons for the low accuracy of classification. In addition, the way of averaging data dimensionality reduction is too simple and rough, which may lose a lot of effective information, which is also a big reason that affects the effect of classification.

表1 样本’0’与10个质心DTW距离
注:第i列代表样本’0’与数字’i’的质心间的距离。红色为最大值,绿色为最小值。
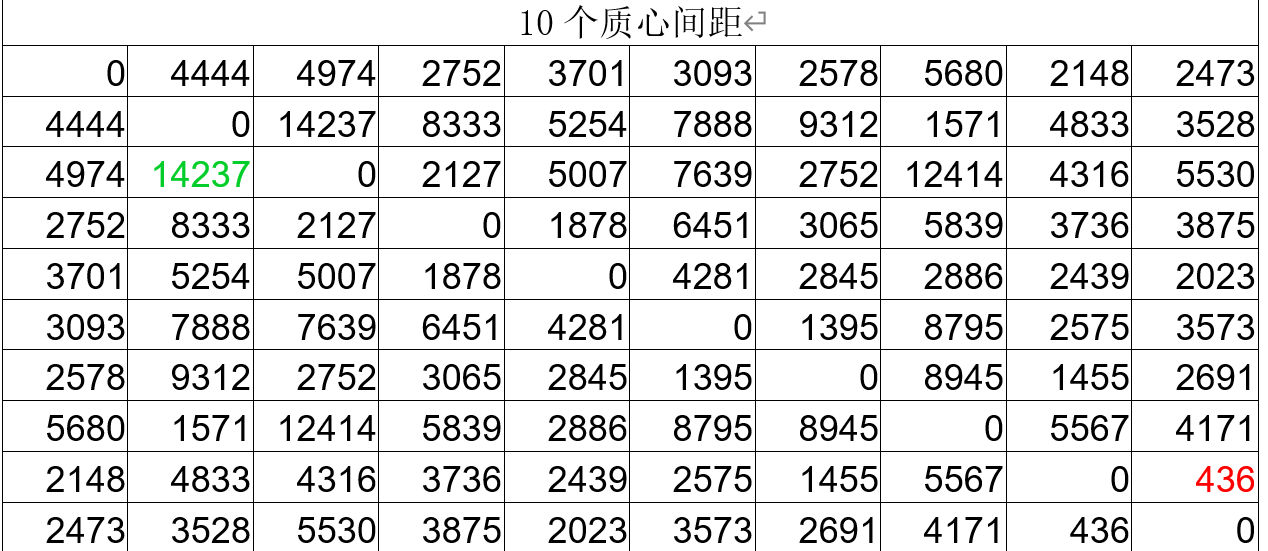
表2 K-means聚类10个质心间DTW距离(类间差)
注:i行j列代表数字’i’质心与数字’j’质心的距离。红色为最大值,绿色为最小值。
( 2)0-9数字模板匹配识别和聚类、分类识别对比
在时间上,模板匹配类似于聚类,但由于模板匹配的准确率要高得多,所以选择了模板匹配的方法进行数字识别。然而,模板匹配的准确性尤其取决于模板的数量和方法以及记录器的性别。这组中的100个模板都是相同的女性。最后,由6名女生测试的平均正确率为83%。但如果男孩来测试,准确率可能会很低,并不一定模板越多,准确率就越高。当使用多个语音作为模板时,可能会发生这种情况。不同人的1号和7号非常相似,这降低了类间距,降低了准确率,所以在实践中,模板匹配不会用于语音识别。
[En]
In terms of time, template matching is similar to clustering, but because the accuracy of template matching is much higher, the method of template matching is chosen for digital recognition. However, the accuracy of template matching especially depends on the number and method of templates and the sex of the recorder. All 100 templates in this group are the same female. Finally, the average accuracy rate tested by 6 female students is 83%. But if boys come to test, the accuracy may be very low, and it is not necessarily that the more templates, the higher the accuracy. It may occur when using multiple voice as templates. Different people’s 1 and 7 are very similar, which reduces the class spacing and reduces the accuracy, so in practice, template matching will not be used for speech recognition.

使用模板匹配的方式进行0-9语音识别参考:https://blog.csdn.net/weixin_43808138/article/details/123184195?spm=1001.2014.3001.5501
部分代码:
%% kmeans聚类中心判别
type=11;
min_=100000;
% load C4
C4=xlsread('C4.xlsx');
for i=1:10
D(i,1)=dtw(C4(i,:),me0);
if(D(i,1)<500)
type=i-1;
set(handles.edit1,'string',type);
end
% if(D(i,1)<min_)
% min_=D(i,1);
% type=i;
% end
end
if type==11
set(handles.edit1,'string','无法识别');
end
%% 层次聚类
fileFolder='层次聚类\';
dirOutput=dir(strcat(fileFolder,'*'));
fileNames={dirOutput.name};
len = length(fileNames);
%% 循环读取
for j=3:len
% 连接路径和文件名得到完整的文件路径
K_Trace = strcat(fileFolder, fileNames(j));
eval(['[x,fs]','=','audioread(K_Trace{1,1})',';']);
%% 端点检测
%幅度归一化到[-1,1]
x = double(x);
x = x / max(abs(x));
% figure,plot(x);
%常数设置
FrameLen = 256;%帧长为256点
FrameInc = 80;%帧移为80点
amp1 = 20;%初始短时能量高门限
amp2 = 2;%初始短时能量低门限
zcr1 = 10;%初始短时过零率高门限
zcr2 = 5;%初始短时过零率低门限
maxsilence = 8; % 8*10ms = 80ms
%语音段中允许的最大静音长度,如果语音段中的静音帧数未超过此值,则认为语音还没结束;如果超过了
%该值,则对语音段长度count进行判断,若count<minlen,则认为前面的语音段为噪音,舍弃,跳到静音
%状态0;若count>minlen,则认为语音段结束;
minlen = 15; % 15*10ms = 150ms
%语音段的最短长度,若语音段长度小于此值,则认为其为一段噪音
status = 0; %初始状态为静音状态
count = 0; %初始语音段长度为0
silence = 0; %初始静音段长度为0
%计算过零率
x1=x(1:end-1);
x2=x(2:end);
%分帧
tmp1=enframe(x1,FrameLen,FrameInc);
tmp2=enframe(x2,FrameLen,FrameInc);
signs = (tmp1.*tmp2)<0;
diffs = (tmp1 -tmp2)>0.02;
zcr = sum(signs.*diffs, 2);%一帧一个值,2表示按行求和
%计算短时能量
%一帧一个值
%amp = sum(abs(enframe(filter([1 -0.9375], 1, x), FrameLen, FrameInc)), 2);
amp = sum(abs(enframe(x, FrameLen, FrameInc)), 2);
%调整能量门限
amp1 = min(amp1, max(amp)/4);
amp2 = min(amp2, max(amp)/8);
%开始端点检测
%For循环,整个信号各帧比较
%根据各帧能量判断帧所处的阶段
x1 = 0;
x2 = 0;
v_num=0;%记录语音段数
v_Begin=[];%记录所有语音段的起点
v_End=[];%记录所有语音段的终点
%length(zcr)即为帧数
for n=1:length(zcr)
goto = 0;
switch status
case {0,1} % 0 = 静音, 1 = 可能开始
if amp(n) > amp1 % 确信进入语音段
x1 = max(n-count-1,1);
% '打印每个x1*FrameInc'
% x1*FrameInc
status = 2;
silence = 0;
count = count + 1;
elseif amp(n) > amp2 | ... % 可能处于语音段
zcr(n) > zcr2
status = 1;
count = count + 1;
else % 静音状态
status = 0;
count = 0;
end
case 2 % 2 = 语音段
if amp(n) > amp2 | ... % 保持在语音段
zcr(n) > zcr2
count = count + 1;
else % 语音将结束
silence = silence+1;
if silence < maxsilence % 静音还不够长,尚未结束
count = count + 1;
elseif count < minlen % 语音长度太短,认为是噪声
status = 0;
silence = 0;
count = 0;
else % 语音结束
status = 3;
end
end
case 3
%break;
%记录当前语音段数据
v_num=v_num+1; %语音段个数加一
count = count-silence/2;
x2 = x1 + count -1;
v_Begin(1,v_num)=x1*FrameInc;
v_End(1,v_num)=x2*FrameInc;
%不跳出 数据归零继续往下查找下一段语音
status = 0; %初始状态为静音状态
count = 0; %初始语音段长度为0
silence = 0; %初始静音段长度为0
end
end
if length(v_End)==0
x2 = x1 + count -1;
v_Begin(1,1)=x1*FrameInc;
v_End(1,1)=x2*FrameInc;
end
lenafter=0;
for len=1:length(v_End)
tmp=v_End(1,len)-v_Begin(1,len);
lenafter=lenafter+tmp;
end
lenafter;
afterEndDet=zeros(lenafter,1);%返回去除静音段的语音信号
beginnum=0;
endnum=0;
for k=1:length(v_End)
tmp=x(v_Begin(1,k):v_End(1,k));
beginnum=endnum+1;
endnum=beginnum+v_End(1,k)-v_Begin(1,k);
afterEndDet(beginnum:endnum)=tmp;
end
% figure,plot(tmp);
% end
x=tmp;
%% Mel三角滤波器组参数
fh=fs/2; % fs=8000Hz,fh=4000Hz 语音信号的频率一般在300-3400Hz,所以一般情况下采样频率设为8000Hz即可。
max_melf=2595*log10(1+fh/700);%耳朵响应频率
M=24;%三角滤波器的个数
N=floor(0.03*fs);%设置帧长
i=0:25;
f=700*(10.^(max_melf/2595*i/(M+1))-1);%将mei频域中的 各滤波器的中心频率 转到实际频率
F=zeros(24,N);
for m=1:24
for k=1:N
i=fh*k/N;
if (f(m)i)&&(if(m+1))
F(m,k)=(i-f(m))/(f(m+1)-f(m));
else if (f(m+1)i)&&(if(m+2))
F(m,k)=(f(m+2)-i)/(f(m+2)-f(m+1));
else
F(m,k)=0;
end
end
end
end
% figure,plot((1:N)*fh/N,F);
%% DCT系数的计算方法
dctcoef=zeros(12,24);
for k=1:12
n=1:24;
dctcoef(k,:)=cos((2*n-1)*k*pi/(2*24));
end
%% 预加重
len=length(x);
alpha=0.98;
y=zeros(len,1);
for i=2:len
y(i)=x(i)-alpha*x(i-1);
end
%% MFCC特征参数的求取
h=hamming(N);%256*1
num=floor(0.235*N); %帧移
count=floor((len-N)/num+1);%帧数
c1=zeros(count,12);
for i=1:count
x_frame=y(num*(i-1)+1:num*(i-1)+N);%分帧
w = x_frame.* h;%
Fx=abs(fft(w));% Fx=abs(fft(x_frame));
s=log(F*Fx.^2);%取对数
c1(i,:)=(dctcoef*s)'; %离散余弦变换
end
%% 求取一阶差分mfcc系数
dtm = zeros(size(c1));
for i=3:size(c1,1)-2
dtm(i,:) = -2*c1(i-2,:) - c1(i-1,:) + c1(i+1,:) + 2*c1(i+2,:);
end
dtm = dtm/3;
%% 合并
ccc=[c1 dtm];
ccc = ccc(3:size(c1,1)-2,:);
%% 一段语音的所有帧的mfcc参数求均值
me1(j,:)=mean(ccc);
end
me1=me1(3:end,2:20);
me=[me1;me0];
%%
Y=pdist(me); % 计算样本点之间的欧氏距离
Y=squareform(Y);
Z=linkage(Y); % 用最短距离法创建系统聚类树?
% C2=cophenet(Z,Y) %
T=cluster(Z,10); % 聚类结果
dendrogram(Z,0,'ColorThreshold',20);
后期会上传整个项目代码~
项目已免费开源:https://gitee.com/zhengzsj/automatic-speech-recognition–ars/tree/master
点个赞和收藏吧~谢谢啦!
Original: https://blog.csdn.net/weixin_43808138/article/details/123823298
Author: zz神君
Title: 通过聚类中心进行0-9数字语音识别(matlab)——基于K-means聚类
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/497910/
转载文章受原作者版权保护。转载请注明原作者出处!