

深度学习与推荐系统
6.1 推荐系统与深度学习关联
学习目标
- 目标
- 无
- 应用
- 无
6.1.1 深度学习到推荐系统
深度学习发展成功与局限
最近几年深度学习的流行,大家一般认为是从2012年 AlexNet 在图像识别领域的成功作为一个里程碑。AlexNet 提升了整个业界对机器学习的接受程度:以前很多机器学习算法都处在”差不多能做 demo “的程度,但是 AlexNet 的效果跨过了很多应用的门槛,造成了应用领域井喷式的兴趣。
- 成功理由:大数据、高性能计算。
[En]
reason for success: big data, high performance computing.*
- 大量的数据,比如说移动互联网的兴起,以及 AWS 这样低成本获得标注数据的平台,使机器学习算法得以打破数据的限制;
- 由于 GPGPU 等高性能运算的兴起,又使得我们可以在可以控制的时间内(以天为单位甚至更短)进行 exaflop 级别的计算,从而使得训练复杂网络变得可能。
- 局限性:一个是结构化的理解,一个是针对小数据的有效学习算法。
[En]
limitations: one is a structured understanding, and one is an effective learning algorithm on small data.*
- 很多深度学习的算法还是在感知这个层面上形成了突破,可以从语音、图像,这些非结构化的数据中进行识别的工作。面对更加结构化的问题的时候,简单地套用深度学习算法可能并不能达到很好的效果
- 在数据量非常小的时候,深度学习的复杂网络往往无法取得很好的效果,但是很多领域,特别是类似医疗这样的领域,数据是非常难获得的。
推荐系统的应用需求
事实上,在过去四年里,随着深度学习在自然语言处理、图像处理和图像识别领域的快速发展,深度学习在其他领域也发展迅速,比如推荐系统。如何解决除了语音和图像之外的更多问题。在阿里、美团等众多互联网企业中,有一个应用就是《沉默的多数》,那就是推荐系统:它往往占到机器学习算力的80%以上甚至90%。如何将深度学习与传统推荐系统进一步融合,如何找到新的模式,如何对搜索和推荐的结果进行建模,也是企业不可或缺的技能。
[En]
In fact, with the rapid development of deep learning in the fields of natural language processing, image processing and image recognition in the past four years, deep learning has also developed rapidly in other fields, such as recommendation systems. How to solve more problems besides voice and image. In Ali, Meituan and many other Internet enterprises, there is a “silent majority” application, that is, the recommendation system: it often accounts for more than 80% or even 90% of machine learning computing power. How to further integrate deep learning with traditional recommendation systems, how to find new models, and how to model the results of search and recommendation are also indispensable skills for companies.
6.1.2 推荐系统为什么加入深度学习?
为什么我们要用深度学习来处理推荐系统中的事情?从基于内容的推荐到协同过滤推荐,协同过滤推荐多年来一直在整个推荐算法领域处于领先地位。深度学习可能没有推荐系统中的图像处理算法那么出色,但它确实有助于推荐系统,并推波助澜。
[En]
Why do we want to use deep learning to deal with things in the recommendation system? from content-based recommendation to collaborative filtering recommendation, collaborative filtering recommendation has taken the lead in the whole field of recommendation algorithms for many years. Deep learning may not be as outstanding as image processing algorithms in the recommendation system, but it does help the recommendation system and add fuel to the flames.
- 直接从内容中提取特征的能力和强大的表示能力
[En]
ability to extract features directly from the content and strong representation ability*
- 噪声数据易于处理,抗噪声能量强
[En]
easy to process noise data with strong anti-noise energy*
- 深度学习促进负责数据的统一处理
[En]
Deep learning facilitates unified processing of responsible data*
具体的基于深度的推荐模型后面讲TensorFlow详细介绍
6.2 深度学习应用简介
学习目标
- 目标
- 无
- 应用
- 无
6.2.1 区别
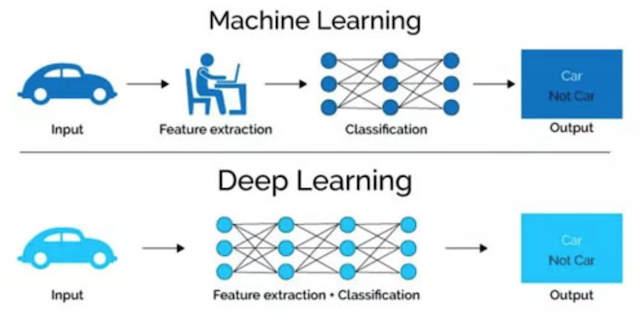

特征提取方面
- 机器学习的 特征工程步骤是要靠手动完成的,而且需要大量领域专业知识
- 深度学习 通常由多个层组成,它们通常将更简单的模型组合在一起,通过将数据从一层传递到另一层来构建更复杂的模型。通过大量数据的训练自动得到模型,不需要人工设计特征提取环节。
深度学习算法试图从数据中学习高级功能,这是深度学习的一个非常独特的部分。因此,减少了为每个问题开发新特征提取器的任务。 适合用在难提取特征的图像、语音、自然语言领域
数据量
机器学习的执行时间远小于深度学习,深度学习的参数往往很大,需要通过对大量数据的多次优化来训练。
[En]
The execution time of machine learning is much less than that of deep learning, and the parameters of deep learning are often very large, which need to be trained through many times of optimization of a large amount of data.
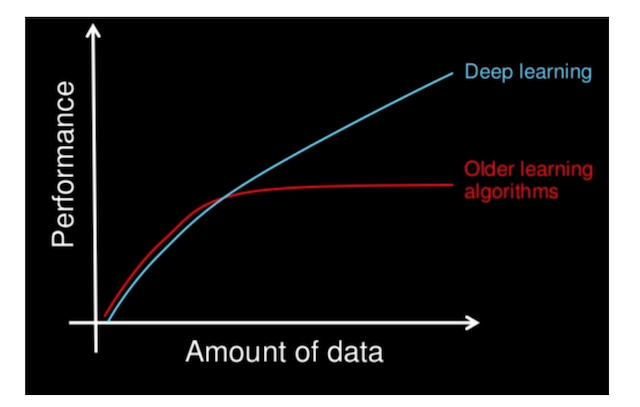
第一、它们需要大量的训练数据集
其次,训练深度神经网络需要大量的计算能力。[En]
Second, it takes a lot of computing power to train deep neural networks.
使用数百万张图像的数据集来训练一个深度网络可能需要几天甚至几周的时间。所以在未来
[En]
It can take days or even weeks to train a deep network using a dataset of millions of images. So in the future
- 需要强大对的GPU服务器来进行计算
- 全面管理的分布式训练与预测服务——比如谷歌 TensorFlow 云机器学习平台——可能会解决这些问题,为大家提供成本合理的基于云的 CPU 和 GPU
算法代表
- 机器学习
- 朴素贝叶斯、决策树等
- 深度学习
- 神经网络
; 6.2.2 深度学习主要应用
- 图像识别
- 物体识别
- 场景识别
- 车型识别
- 人脸检测跟踪
- 人脸关键点定位
- 人脸身份认证
- 自然语言处理技术
- 机器翻译
- 文本识别
- 聊天对话
- 语音技术
- 语音识别
- 推荐系统
前几年一直关注AI框架,但是近年来框架的同质化说明了它不再是一个需要花大精力解决的问题,TensorFlow、Pytorch这样的框架在工业界的广泛应用,以及各种框架利用 Python 在建模领域的优秀表现,已经可以帮助我们解决很多以前需要自己编程实现的问题,如果作为 AI 工程师,我们应该跳出框架的桎梏,往更广泛的领域寻找价值。
6.2.3 常见深度学习框架对比
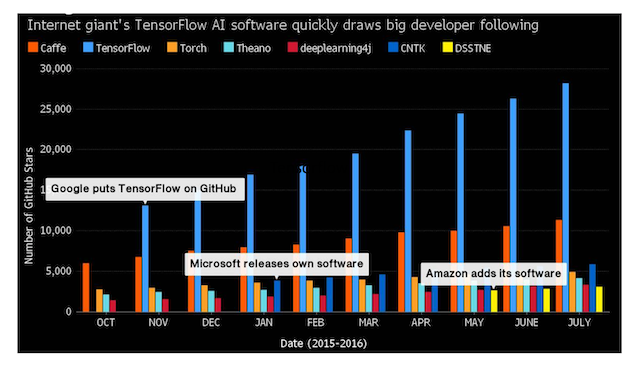
tensorflow的github:
; 1.2.2 TensorFlow的特点

官网:https://www.tensorflow.org/
- 语言多样(Language Options)
- TensorFlow使用C++实现的,然后用Python封装。谷歌号召社区通过SWIG开发更多的语言接口来支持TensorFlow
- 使用分销策略进行分销培训
[En]
use distribution strategies for distribution training*
- 对于大型 ML 训练任务,分发策略 API使在不更改模型定义的情况下,可以轻松地在不同的硬件配置上分发和训练模型。由于 TensorFlow 支持一系列硬件加速器,如 CPU、GPU 和 TPU
- Tensorboard可视化
- TensorBoard是TensorFlow的一组Web应用,用来监控TensorFlow运行过程
- 生产中的强模型部署在任何平台上,一旦您训练并保存了模型,您就可以直接在应用程序中执行它,或者使用部署库来服务它:
[En]
strong model deployment in production on any platform, once you have trained and saved the model, you can execute it directly in the application, or use the deployment library to service it:*
- TensorFlow 服务:允许模型通过 HTTP/REST 或 GRPC/协议缓冲区提供服务的 TensorFlow 库构建。
- TensorFlow Lite:TensorFlow 针对移动和嵌入式设备的轻量级解决方案提供了在 Android、iOS 和嵌入式系统上部署模型的能力。
- tensorflow.js:支持在 JavaScript 环境中部署模型,例如在 Web 浏览器或服务器端通过 Node.js 部署模型。TensorFlow.js 还支持在 JavaScript 中定义模型,并使用类似于 Kera 的 API 直接在 Web 浏览器中进行训练。
1.2.3 TensorFlow的安装
安装 TensorFlow在64 位系统上测试这些系统支持 TensorFlow:
- Ubuntu 16.04 或更高版本
- Windows 7 或更高版本
- macOS 10.12.6 (Sierra) 或更高版本(不支持 GPU)
进入虚拟环境当中再安装。刚开始的环境比较简单,只要下载tensorflow即可
- 环境包:
安装较慢,指定镜像源,请在带有numpy等库的虚拟环境中安装
- ubuntu安装
pip install tensorflow==1.13 -i https://mirrors.aliyun.com/pypi/simple
- MacOS安装
pip install tensorflow==1.13 -i https://mirrors.aliyun.com/pypi/simple
注:如果需要下载GPU版本的(TensorFlow只提供windows和linux版本的,没有Macos版本的)参考官网https://www.tensorflow.org/install/gpu?hl=zh-cn,
1、虚拟机下linux也是用不了GPU版本TensorFlow
2、本机单独的windows和本机单独的unbuntu可以使用GPU版本TensorFlow,需要安装相关驱动
1.2.4 Tenssorlfow使用技巧
- 使用 tf.keras 构建、训练和验证您的模型,tf相关API用于损失计算修改等
- tensorflow提供模型训练模型部署
TensorFlow框架介绍
2.1 TF数据流图
学习目标
- 目标
- 说明TensorFlow的数据流图结构
- 应用
- 无
- 内容预览
- 2.1.1 案例:TensorFlow实现一个加法运算
- 1 代码
- 2 TensorFlow结构分析
- 2.1.2 数据流图介绍
2.1.1 案例:TensorFlow实现一个加法运算
2.1.1.1 代码
def tensorflow_demo():
"""
通过简单案例来了解tensorflow的基础结构
:return: None
"""
a = 10
b = 20
c = a + b
print("原生Python实现加法运算方法1:\n", c)
def add(a, b):
return a + b
sum = add(a, b)
print("原生python实现加法运算方法2:\n", sum)
a_t = tf.constant(10)
b_t = tf.constant(20)
c_t = tf.add(a_t, b_t)
print("tensorflow实现加法运算:\n", c_t)
with tf.Session() as sess:
sum_t = sess.run(c_t)
print("在sess当中的sum_t:\n", sum_t)
return None
注意问题:警告指出你的CPU支持AVX运算加速了线性代数计算,即点积,矩阵乘法,卷积等。可以从源代码安装TensorFlow来编译,当然也可以选择关闭
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
2.1.1.2 TensorFlow结构分析
TensorFlow 程序通常被组织成 一个构建图阶段和一个执行图阶段。
在构建阶段,数据和操作的执行步骤以图的形式描述。
[En]
During the construction phase, the execution steps of the data and operations are described as a diagram.
在执行阶段,使用会话来执行构建的关系图中的操作。
[En]
During the execution phase, use the session to perform the actions in the built diagram.
- 图和会话 :
- 图:这是 TensorFlow 将计算表示为指令之间的依赖关系的一种表示法
- 会话:TensorFlow 跨一个或多个本地或远程设备运行数据流图的机制
- 张量:TensorFlow 中的基本数据对象
- 节点:提供图中执行的操作
[En]
Node: provide the actions performed in the figure*
2.1.2 数据流图介绍
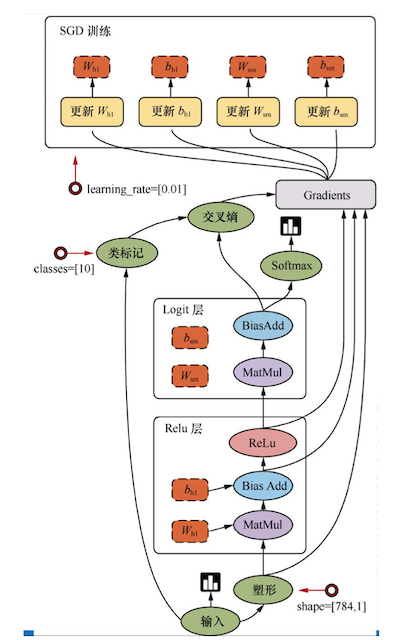
TensorFlow是一个采用数据流图(data flow graphs),用于数值计算的开源框架。
节点(Operation)在图中表示数学操作,线(edges)则表示在节点间相互联系的多维数据数组,即张量(tensor)。
; 2.2 图与TensorBoard
学习目标
- 目标
- 说明图的基本使用
- 应用tf.Graph创建图、tf.get_default_graph获取默认图
- 知道开启TensorBoard过程
- 知道图当中op的名字以及命名空间
- 应用
- 无
- 内容预览
- 2.2.1 什么是图结构
- 2.2.2 图相关操作
- 1 默认图
- 2 创建图
- 2.2.3 TensorBoard:可视化学习
- 1 数据序列化-events文件
- 2 启动TensorBoard
- 2.2.4 OP
- 1 常见OP
- 2 指令名称
2.2.1 什么是图结构
图包含了一组tf.Operation代表的计算单元对象和tf.Tensor代表的计算单元之间流动的数据。
2.2.2 图相关操作
1 默认图
通常TensorFlow会默认帮我们创建一张图。
查看默认图的两种方法:
- 通过调用tf.get_default_graph()访问 ,要将操作添加到默认图形中,直接创建OP即可。
- op、sess都含有graph属性 ,默认都在一张图中
def graph_demo():
a_t = tf.constant(10)
b_t = tf.constant(20)
c_t = tf.add(a_t, b_t)
print("tensorflow实现加法运算:\n", c_t)
default_g = tf.get_default_graph()
print("获取默认图:\n", default_g)
print("a_t的graph:\n", a_t.graph)
print("b_t的graph:\n", b_t.graph)
print("c_t的graph:\n", c_t.graph)
with tf.Session() as sess:
sum_t = sess.run(c_t)
print("在sess当中的sum_t:\n", sum_t)
print("会话的图属性:\n", sess.graph)
return None
2 创建图
- 可以通过tf.Graph()自定义创建图
- 如果要在这张图中创建OP,典型用法是使用tf.Graph.as_default()上下文管理器
def graph_demo():
a_t = tf.constant(10)
b_t = tf.constant(20)
c_t = tf.add(a_t, b_t)
print("tensorflow实现加法运算:\n", c_t)
default_g = tf.get_default_graph()
print("获取默认图:\n", default_g)
print("a_t的graph:\n", a_t.graph)
print("b_t的graph:\n", b_t.graph)
print("c_t的graph:\n", c_t.graph)
new_g = tf.Graph()
print("自定义图:\n", new_g)
with new_g.as_default():
new_a = tf.constant(30)
new_b = tf.constant(40)
new_c = tf.add(new_a, new_b)
print("new_a的graph:\n", new_a.graph)
print("new_b的graph:\n", new_b.graph)
print("new_c的graph:\n", new_c.graph)
with tf.Session() as sess:
sum_t = sess.run(c_t)
print("在sess当中的sum_t:\n", sum_t)
print("会话的图属性:\n", sess.graph)
with tf.Session(graph=new_g) as sess2:
sum_new = sess2.run(new_c)
print("在sess2当中的sum_new:\n", sum_new)
print("会话的图属性:\n", sess2.graph)
return None
TensorFlow有一个亮点就是,我们能看到自己写的程序的可视化效果,这个功能就是Tensorboard。在这里我们先简单介绍一下其基本功能。
2.2.3 TensorBoard:可视化学习
TensorFlow 可用于训练大规模深度神经网络所需的计算,使用该工具涉及的计算往往复杂而深奥。为了更方便 TensorFlow 程序的理解、调试与优化,TensorFlow提供了TensorBoard 可视化工具。
实现程序可视化过程:
; 1 数据序列化-events文件
TensorBoard 通过读取 TensorFlow 的事件文件来运行,需要将数据生成一个序列化的 Summary protobuf 对象。
tf.summary.FileWriter('./tmp/summary/test/', graph=sess.graph)
这将在指定目录中生成一个 event 文件,其名称格式如下:
events.out.tfevents.{timestamp}.{hostname}
2 启动TensorBoard
tensorboard --logdir="./tmp/tensorflow/summary/test/"
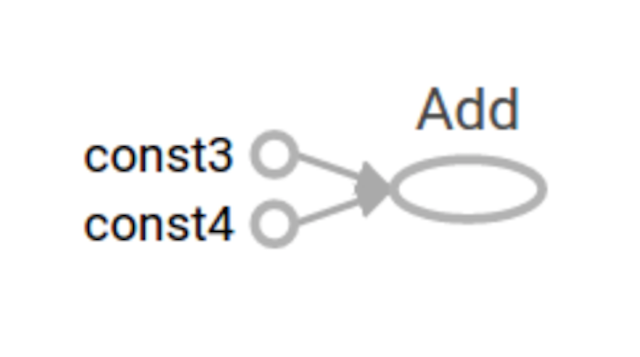
在浏览器中打开 TensorBoard 的图页面 127.0.0.1:6006,会看到与以下图形类似的图,在GRAPHS模块我们可以看到以下图结构
; 2.2.4 OP
2.2.4.1 常见OP
哪些是OP?
类型实例标量运算add, sub, mul, div, exp, log, greater, less, equal向量运算concat, slice, splot, constant, rank, shape, shuffle矩阵运算matmul, matrixinverse, matrixdateminant带状态的运算Variable, assgin, assginadd神经网络组件softmax, sigmoid, relu,convolution,max_pool存储, 恢复Save, Restroe队列及同步运算Enqueue, Dequeue, MutexAcquire, MutexRelease控制流Merge, Switch, Enter, Leave, NextIteration
一个操作对象(Operation)是TensorFlow图中的一个节点, 可以接收0个或者多个输入Tensor, 并且可以输出0个或者多个Tensor, Operation对象是通过op构造函数(如tf.matmul())创建的。
例如: c = tf.matmul(a, b) 创建了一个Operation对象,类型为 MatMul类型, 它将张量a, b作为输入,c作为输出,,并且输出数据,打印的时候也是打印的数据。其中tf.matmul()是函数,在执行matmul函数的过程中会通过MatMul类创建一个与之对应的对象
con_a = tf.constant(3.0)
con_b = tf.constant(4.0)
sum_c = tf.add(con_a, con_b)
print("打印con_a:\n", con_a)
print("打印con_b:\n", con_b)
print("打印sum_c:\n", sum_c)
打印语句会生成:
打印con_a:
Tensor("Const:0", shape=(), dtype=float32)
打印con_b:
Tensor("Const_1:0", shape=(), dtype=float32)
打印sum_c:
Tensor("Add:0", shape=(), dtype=float32)
注意, 打印出来的是张量值,可以理解成OP当中包含了这个值。并且每一个OP指令都对应一个唯一的名称,如上面的Const:0,这个在TensorBoard上面也可以显示
请注意,tf.Tensor 对象以输出该张量的 tf.Operation 明确命名。张量名称的形式为 “
- “
- “” 是一个整数,它表示该张量在指令的输出中的索引
2.2.4.2 指令名称
tf.Graph对象为其包含的 tf.Operation对象定义的一个 命名空间。TensorFlow 会自动为图中的每个指令选择一个唯一名称,用户也可以指定描述性名称,使程序阅读起来更轻松。我们可以以以下方式改写指令名称
- 每个创建新的 tf.Operation 或返回新的 tf.Tensor 的 API 函数可以接受可选的 name 参数。
例如,tf.constant(42.0, name=”answer”) 创建了一个名为 “answer” 的新 tf.Operation 并返回一个名为 “answer:0” 的 tf.Tensor。如果默认图已包含名为 “answer” 的指令,则 TensorFlow 会在名称上附加 “1”、”2″ 等字符,以便让名称具有唯一性。
- 当修改好之后,我们在Tensorboard显示的名字也会被修改
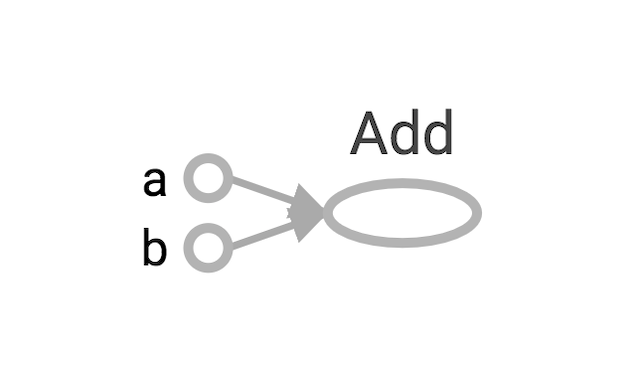
a = tf.constant(3.0, name="a")
b = tf.constant(4.0, name="b" )
2.3 会话、张量、变量OP
学习目标
- 目标
- 应用sess.run或者eval运行图程序并获取张量值
- 应用feed_dict机制实现运行时填充数据
- 应用placeholder实现创建占位符
- 知道常见的TensorFlow创建张量
- 知道常见的张量数学运算操作
- 说明numpy的数组和张量相同性
- 说明张量的两种形状改变特点
- 应用set_shape和tf.reshape实现张量形状的修改
- 应用tf.matmul实现张量的矩阵运算修改
- 应用tf.cast实现张量的类型
- 说明变量op的特殊作用
- 说明变量op的trainable参数的作用
- 应用global_variables_initializer实现变量op的初始化
- 应用
- 无
- 内容预览
2.3.1 会话
一个运行TensorFlow operation的类。会话包含以下两种开启方式
- tf.Session:用于完整的程序当中
- tf.InteractiveSession:用于交互式上下文中的TensorFlow ,例如shell
1 TensorFlow 使用 tf.Session 类来表示客户端程序(通常为 Python 程序,但也提供了使用其他语言的类似接口)与 C++ 运行时之间的连接
2 tf.Session 对象使用分布式 TensorFlow 运行时提供对本地计算机中的设备和远程设备的访问权限。
2.3.1.1 init (target=”, graph=None, config=None)
会话可能拥有的资源,如 tf.Variable,tf.QueueBase和tf.ReaderBase。当这些资源不再需要时,释放这些资源非常重要。因此,需要调用tf.Session.close会话中的方法,或将会话用作上下文管理器。以下两个例子作用是一样的:
def session_demo():
"""
会话演示
:return:
"""
a_t = tf.constant(10)
b_t = tf.constant(20)
c_t = tf.add(a_t, b_t)
print("tensorflow实现加法运算:\n", c_t)
with tf.Session() as sess:
print(sess.run([a_t, b_t, c_t]))
print("会话的图属性:\n", sess.graph)
return None
- target:如果将此参数留空(默认设置),会话将仅使用本地计算机中的设备。可以指定 grpc:// 网址,以便指定 TensorFlow 服务器的地址,这使得会话可以访问该服务器控制的计算机上的所有设备。
- graph:默认情况下,新的 tf.Session 将绑定到当前的默认图。
- config:此参数允许您指定一个 tf.ConfigProto 以便控制会话的行为。例如,ConfigProto协议用于打印设备使用信息
sess = tf.Session(config=tf.ConfigProto(allow_soft_placement=True,
log_device_placement=True))
会话可以分配不同的资源以在不同的设备上运行。
[En]
Sessions can allocate different resources to run on different devices.
/job:worker/replica:0/task:0/device:CPU:0
device_type:类型设备(例如CPU,GPU,TPU)
2.3.1.2 会话的run()
- run(fetches,feed_dict=None, options=None, run_metadata=None)
- 通过使用sess.run()来运行operation
- fetches:单一的operation,或者列表、元组(其它不属于tensorflow的类型不行)
- feed_dict:参数允许调用者覆盖图中张量的值,运行时赋值
- 与tf.placeholder搭配使用,则会检查值的形状是否与占位符兼容。
使用tf.operation.eval()也可运行operation,但需要在会话中运行
a = tf.constant(5.0)
b = tf.constant(6.0)
c = a * b
sess = tf.Session()
print(sess.run(c))
print(c.eval(session=sess))
2.3.1.3 feed操作
- placeholder提供占位符,run时候通过feed_dict指定参数
def session_run_demo():
"""
会话的run方法
:return:
"""
a = tf.placeholder(tf.float32)
b = tf.placeholder(tf.float32)
sum_ab = tf.add(a, b)
print("sum_ab:\n", sum_ab)
with tf.Session() as sess:
print("占位符的结果:\n", sess.run(sum_ab, feed_dict={a: 3.0, b: 4.0}))
return None
请注意运行时候报的错误error:
RuntimeError:如果这Session是无效状态(例如已关闭)。
TypeError:如果fetches或者feed_dict键的类型不合适。
ValueError:如果fetches或feed_dict键无效或引用 Tensor不存在的键。
在编写 TensorFlow 程序时,程序传递和运算的主要目标是tf.Tensor
2.3.2 张量(Tensor)
TensorFlow 的张量就是一个 n 维数组, 类型为tf.Tensor。Tensor具有以下两个重要的属性
- type:数据类型
- shape:形状(阶)
2.3.2.1 张量的类型
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5l9M4fqE-1650942232063)(images/%E7%B1%BB%E5%9E%8B.png)]
2.3.2.2 张量的阶
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Seo5A0jf-1650942232064)(images/%E9%98%B6.png)]
形状有0阶、1阶、2阶….
tensor1 = tf.constant(4.0)
tensor2 = tf.constant([1, 2, 3, 4])
linear_squares = tf.constant([[4], [9], [16], [25]], dtype=tf.int32)
print(tensor1.shape)
2.3.3 创建张量的指令
- 固定值张量

- 随机值张量

- 其它特殊的创建张量的op
- tf.Variable
- tf.placeholder
; 2.3.4 张量的变换
2.3.4.1 类型改变

; 2.3.4.2 形状改变
TensorFlow的张量具有两种形状变换,动态形状和静态形状
- tf.reshape
- tf.set_shape
对于动态和静态形状,必须满足以下规则
[En]
For dynamic and static shapes, the following rules must be met
- 静态形状
- 转换静态形状的时候,1-D到1-D,2-D到2-D,不能跨阶数改变形状
- 对于已经固定的张量的静态形状的张量,不能再次设置静态形状
- 动态形状
- tf.reshape()动态创建新张量时,张量的元素个数必须匹配
def tensor_demo():
"""
张量的介绍
:return:
"""
a = tf.constant(value=30.0, dtype=tf.float32, name="a")
b = tf.constant([[1, 2], [3, 4]], dtype=tf.int32, name="b")
a2 = tf.constant(value=30.0, dtype=tf.float32, name="a2")
c = tf.placeholder(dtype=tf.float32, shape=[2, 3, 4], name="c")
sum = tf.add(a, a2, name="my_add")
print(a, a2, b, c)
print(sum)
print("a的图属性:\n", a.graph)
print("b的名字:\n", b.name)
print("a2的形状:\n", a2.shape)
print("c的数据类型:\n", c.dtype)
print("sum的op:\n", sum.op)
print("b的静态形状:\n", b.get_shape())
a_p = tf.placeholder(dtype=tf.float32, shape=[None, None])
b_p = tf.placeholder(dtype=tf.float32, shape=[None, 10])
c_p = tf.placeholder(dtype=tf.float32, shape=[3, 2])
print("a_p的静态形状为:\n", a_p.get_shape())
print("b_p的静态形状为:\n", b_p.get_shape())
print("c_p的静态形状为:\n", c_p.get_shape())
print("a_p的静态形状为:\n", a_p.get_shape())
print("b_p的静态形状为:\n", b_p.get_shape())
print("c_p的静态形状为:\n", c_p.get_shape())
c_p_r = tf.reshape(c_p, [2, 3])
print("动态形状的结果:\n", c_p_r)
return None
2.3.5 张量的数学运算
- 算术运算符
- 基本数学函数
- 矩阵运算
- reduce操作
- 序列索引操作
详细请参考: https://www.tensorflow.org/versions/r1.8/api_guides/python/math_ops
这些API使用,我们在使用的时候介绍,具体参考文档
2.3.6 变量
TensorFlow变量是表示程序处理的共享持久状态的最佳方法。变量通过 tf.Variable OP类进行操作。变量的特点:
- 存储持久化
- 可修改值
- *可指定被训练
2.3.6.1 创建变量
- tf.Variable( initial_value=None,trainable=True,collections=None ,name=None)
- initial_value:初始化的值
- trainable:是否被训练
- collections:新变量将添加到列出的图的集合中collections,默认为[GraphKeys.GLOBAL_VARIABLES],如果trainable是True变量也被添加到图形集合 GraphKeys.TRAINABLE_VARIABLES
- 需要显式初始化变量才能运行值
[En]
variables need to be explicitly initialized to run values*
def variable_demo():""" 变量的演示 :return:""" a = tf.Variable(initial_value=30) b = tf.Variable(initial_value=40) sum = tf.add(a, b) init = tf.global_variables_initializer() with tf.Session() as sess: sess.run(init) print("sum:\n", sess.run(sum)) return None2.3.6.2 使用tf.variable_scope()修改变量的命名空间
会在OP的名字前面增加命名空间的指定名字
with tf.variable_scope("name"):
var = tf.Variable(name='var', initial_value=[4], dtype=tf.float32)
var_double = tf.Variable(name='var', initial_value=[4], dtype=tf.float32)
<tf.Variable 'name/var:0' shape=() dtype=float32_ref>
<tf.Variable 'name/var_1:0' shape=() dtype=float32_ref>
2.4 案例:实现线性回归
学习目标
- 目标
- 应用op的name参数实现op的名字修改
- 应用variable_scope实现图程序作用域的添加
- 应用scalar或histogram实现张量值的跟踪显示
- 应用merge_all实现张量值的合并
- 应用add_summary实现张量值写入文件
- 应用tf.train.saver实现TensorFlow的模型保存以及加载
- 应用tf.app.flags实现命令行参数添加和使用
- 应用reduce_mean、square实现均方误差计算
- 应用tf.train.GradientDescentOptimizer实现有梯度下降优化器创建
- 应用minimize函数优化损失
- 知道梯度爆炸以及常见解决技巧
- 应用
- 实现线性回归模型
- 内容预览
- 2.6.1 线性回归原理复习
- 2.6.2 案例:实现线性回归的训练
- 2.6.3 增加其他功能
- 1 增加变量显示
- 2 增加命名空间
- 3 模型的保存与加载
- 4 命令行参数使用
2.4.1 线性回归原理复习
根据数据建立回归模型,w1x1+w2x2+……+b = y,通过真实值与预测值之间建立误差,使用梯度下降优化得到损失最小对应的权重和偏置。最终确定模型的权重和偏置参数。最后可以用这些参数进行预测。
2.4.2 案例:实现线性回归的训练
1 案例确定
- 假设随机指定100个点,只有一个特征
- 数据本身的分布为 y = 0.8 * x + 0.7
这里将数据分布的规律确定,是为了使我们训练出的参数跟真实的参数(即0.8和0.7)比较是否训练准确
2 API
运算
- 矩阵运算
- tf.matmul(x, w)
- 平方
- tf.square(error)
- 均值
- tf.reduce_mean(error)
梯度下降优化
- tf.train.GradientDescentOptimizer(learning_rate)
- 梯度下降优化
- learning_rate:学习率,一般为0~1之间比较小的值
- method:
- minimize(loss)
- return:梯度下降op
3 步骤分析
- 1 准备好数据集:y = 0.8x + 0.7 100个样本
- 2 建立线性模型
- 随机初始化W1和b1
- y = W·X + b,目标:求出权重W和偏置b
- 3 确定损失函数(预测值与真实值之间的误差)-均方误差
- 4 梯度下降优化损失:需要指定学习率(超参数)
4 实现完整功能
import tensorflow as tf
import os
def linear_regression():
"""
自实现线性回归
:return: None
"""
X = tf.random_normal(shape=(100, 1), mean=2, stddev=2)
y_true = tf.matmul(X, [[0.8]]) + 0.7
weights = tf.Variable(initial_value=tf.random_normal(shape=(1, 1)))
bias = tf.Variable(initial_value=tf.random_normal(shape=(1, 1)))
y_predict = tf.matmul(X, weights) + bias
error = tf.reduce_mean(tf.square(y_predict - y_true))
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.01).minimize(error)
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
print("随机初始化的权重为%f, 偏置为%f" % (weights.eval(), bias.eval()))
for i in range(100):
sess.run(optimizer)
print("第%d步的误差为%f,权重为%f, 偏置为%f" % (i, error.eval(), weights.eval(), bias.eval()))
return None
6 变量的trainable设置观察
trainable的参数作用,指定是否训练
weight = tf.Variable(tf.random_normal([1, 1], mean=0.0, stddev=1.0), name="weights", trainable=False)
2.4.3 增加其他功能
- 增加命名空间
- *命令行参数设置
2 增加命名空间
是代码结构更加清晰,Tensorboard图结构清楚
with tf.variable_scope("lr_model"):
def linear_regression():
with tf.variable_scope("original_data"):
X = tf.random_normal(shape=(100, 1), mean=2, stddev=2, name="original_data_x")
y_true = tf.matmul(X, [[0.8]], name="original_matmul") + 0.7
with tf.variable_scope("linear_model"):
weights = tf.Variable(initial_value=tf.random_normal(shape=(1, 1)), name="weights")
bias = tf.Variable(initial_value=tf.random_normal(shape=(1, 1)), name="bias")
y_predict = tf.matmul(X, weights, name="model_matmul") + bias
with tf.variable_scope("loss"):
error = tf.reduce_mean(tf.square(y_predict - y_true), name="error_op")
with tf.variable_scope("gd_optimizer"):
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.01, name="optimizer").minimize(error)
tf.summary.scalar("error", error)
tf.summary.histogram("weights", weights)
tf.summary.histogram("bias", bias)
merge = tf.summary.merge_all()
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
print("随机初始化的权重为%f, 偏置为%f" % (weights.eval(), bias.eval()))
file_writer = tf.summary.FileWriter(logdir="./summary", graph=sess.graph)
for i in range(100):
sess.run(optimizer)
print("第%d步的误差为%f,权重为%f, 偏置为%f" % (i, error.eval(), weights.eval(), bias.eval()))
summary = sess.run(merge)
file_writer.add_summary(summary, i)
return None
3 模型的保存与加载
- tf.train.Saver(var_list=None,max_to_keep=5)
- 保存和加载模型(保存文件格式:checkpoint文件)
-
var_list:指定将要保存和还原的变量。它可以作为一个dict或一个列表传递.
-
max_to_keep:指示要保留的最近检查点文件的最大数量。创建新文件时,会删除较旧的文件。如果无或0,则保留所有检查点文件。默认为5(即保留最新的5个检查点文件。)
使用
例如:
指定目录+模型名字
saver.save(sess, '/tmp/ckpt/test/myregression.ckpt')
saver.restore(sess, '/tmp/ckpt/test/myregression.ckpt')
要确定模型是否存在,请直接指定目录
[En]
To determine whether the model exists, specify the directory directly
checkpoint = tf.train.latest_checkpoint("./tmp/model/")
saver.restore(sess, checkpoint)
4 命令行参数使用
- 1、
- 2、 tf.app.flags.,在flags有一个FLAGS标志,它在程序中可以调用到我们
前面具体定义的flag_name
- 3、通过tf.app.run()启动main(argv)函数
tf.app.flags.DEFINE_integer("max_step", 0, "训练模型的步数")
tf.app.flags.DEFINE_string("model_dir", " ", "模型保存的路径+模型名字")
FLAGS = tf.app.flags.FLAGS
for i in range(FLAGS.max_step):
sess.run(train_op)
完整代码
import tensorflow as tf
import os
tf.app.flags.DEFINE_string("model_path", "./linear_regression/", "模型保存的路径和文件名")
FLAGS = tf.app.flags.FLAGS
def linear_regression():
with tf.variable_scope("original_data"):
X = tf.random_normal(shape=(100, 1), mean=2, stddev=2, name="original_data_x")
y_true = tf.matmul(X, [[0.8]], name="original_matmul") + 0.7
with tf.variable_scope("linear_model"):
weights = tf.Variable(initial_value=tf.random_normal(shape=(1, 1)), name="weights")
bias = tf.Variable(initial_value=tf.random_normal(shape=(1, 1)), name="bias")
y_predict = tf.matmul(X, weights, name="model_matmul") + bias
with tf.variable_scope("loss"):
error = tf.reduce_mean(tf.square(y_predict - y_true), name="error_op")
with tf.variable_scope("gd_optimizer"):
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.01, name="optimizer").minimize(error)
tf.summary.scalar("error", error)
tf.summary.histogram("weights", weights)
tf.summary.histogram("bias", bias)
merge = tf.summary.merge_all()
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
print("随机初始化的权重为%f, 偏置为%f" % (weights.eval(), bias.eval()))
file_writer = tf.summary.FileWriter(logdir="./summary", graph=sess.graph)
for i in range(100):
sess.run(optimizer)
print("第%d步的误差为%f,权重为%f, 偏置为%f" % (i, error.eval(), weights.eval(), bias.eval()))
summary = sess.run(merge)
file_writer.add_summary(summary, i)
return None
def main(argv):
print("这是main函数")
print(argv)
print(FLAGS.model_path)
linear_regression()
if __name__ == "__main__":
tf.app.run()
作业:将面向过程改为面向对象
参考代码
tf.app.flags.DEFINE_integer("max_step", 0, "训练模型的步数")
tf.app.flags.DEFINE_string("model_dir", " ", "模型保存的路径+模型名字")
FLAGS = tf.app.flags.FLAGS
class MyLinearRegression(object):
"""
自实现线性回归
"""
def __init__(self):
pass
def inputs(self):
"""
获取特征值目标值数据数据
:return:
"""
x_data = tf.random_normal([100, 1], mean=1.0, stddev=1.0, name="x_data")
y_true = tf.matmul(x_data, [[0.7]]) + 0.8
return x_data, y_true
def inference(self, feature):
"""
根据输入数据建立模型
:param feature:
:param label:
:return:
"""
with tf.variable_scope("linea_model"):
self.weight = tf.Variable(tf.random_normal([1, 1], mean=0.0, stddev=1.0),
name="weights")
self.bias = tf.Variable(0.0, name='biases')
y_predict = tf.matmul(feature, self.weight) + self.bias
return y_predict
def loss(self, y_true, y_predict):
"""
目标值和真实值计算损失
:return: loss
"""
loss = tf.reduce_mean(tf.square(y_true - y_predict))
return loss
def merge_summary(self, loss):
tf.summary.scalar("losses", loss)
tf.summary.histogram("w", self.weight)
tf.summary.histogram('b', self.bias)
merged = tf.summary.merge_all()
return merged
def sgd_op(self, loss):
"""
获取训练OP
:return:
"""
train_op = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
return train_op
def train(self):
"""
训练模型
:param loss:
:return:
"""
g = tf.get_default_graph()
with g.as_default():
x_data, y_true = self.inputs()
y_predict = self.inference(x_data)
loss = self.loss(y_true, y_predict)
train_op = self.sgd_op(loss)
merged = self.merge_summary(loss)
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
print("初始化的权重:%f, 偏置:%f" % (self.weight.eval(), self.bias.eval()))
for i in range(FLAGS.max_step):
sess.run(train_op)
file_writer = tf.summary.FileWriter("./tmp/summary/", graph=sess.graph)
print("训练第%d步之后的损失:%f, 权重:%f, 偏置:%f" % (
i,
loss.eval(),
self.weight.eval(),
self.bias.eval()))
summary = sess.run(merged)
file_writer.add_summary(summary, i)
if __name__ == '__main__':
lr = MyLinearRegression()
lr.train()
2.5 TFAPI使用2.0建议
学习目标
- 目标
- 无
- 应用
- 无
2.5.2 TF2.0最新架构图
- 饱受诟病TF1.0的API混乱
- 删除 queue runner 以支持 tf.data。
- 删除图形集合。
- API 符号的移动和重命名。
- tf.contrib 将从核心 TensorFlow 存储库和构建过程中移除
TensorFlow 2.0 将专注于 简单性 和 易用性,具有以下更新:
- 使用 Keras 和 eager execution,轻松构建模型
- 在任何平台上实施稳健的生产环境模型部署
[En]
implement robust model deployment of production environment on any platform*
- 为研究提供强大的实验工具
[En]
provide powerful experimental tools for research*
- 通过清理废弃的 API 和减少重复来简化 API
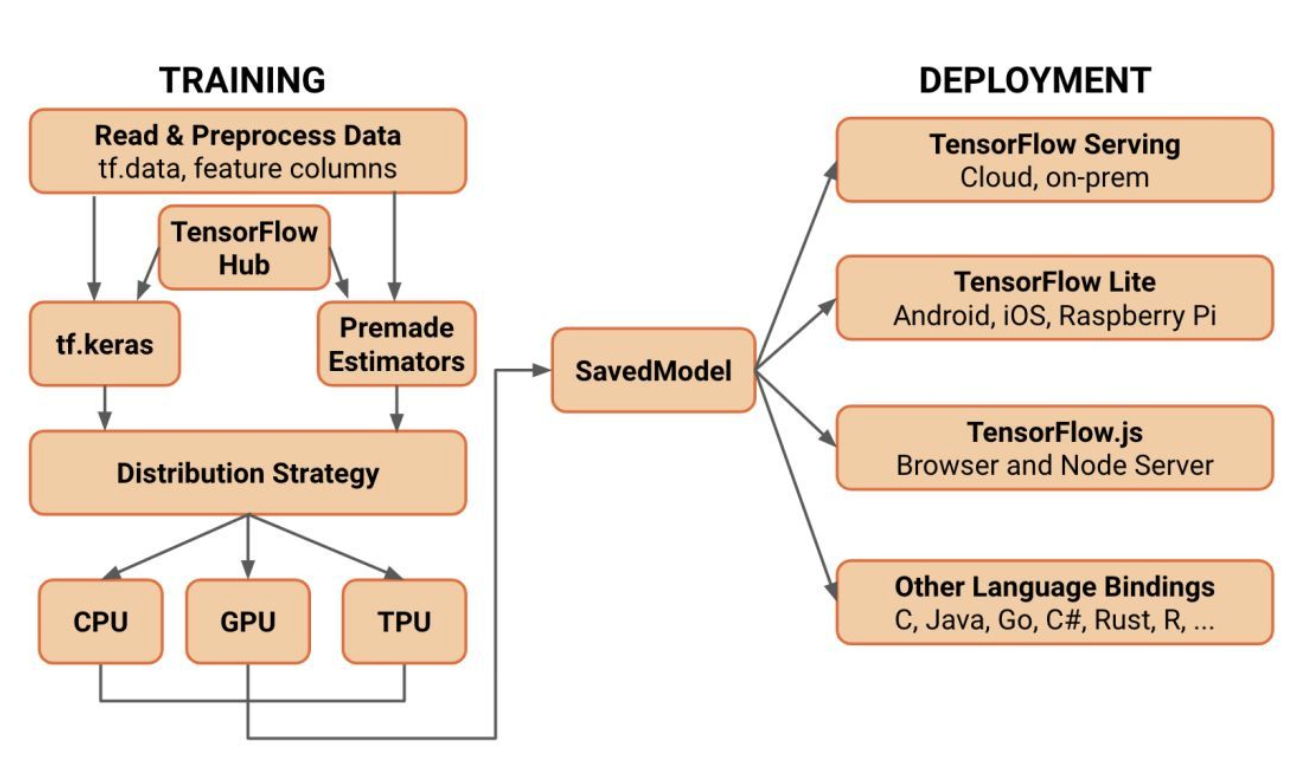
1、使用tf.data加载数据。使用输入管道读取训练数据,输入管道使用tf.data创建。利用tf.feature_column描述特征, 如分段和特征交叉。
2、使用tf.keras构建、训练并验证模型,或者使用Premade Estimators。
- Keras与TensorFlow的其余部分紧密集成,因此用户可以随时访问TensorFlow的函数。如线性或逻辑回归、梯度上升树、随机森林等也可以直接使用(使用tf.estimatorAPI实现)。
- 如果不想从头开始训练模型,用户也可以很快利用迁移学习来训练使用TensorFlow Hub模块的Keras或Estimator模型。(迁移学习)
3、使用分布式策略进行分布式训练。对于大型机器学习训练任务,分布式策略API可以轻松地在不同硬件配置上分配和训练模型,无需更改模型的定义。由于TensorFlow支持各种硬件加速器,如CPU,GPU和TPU,因此用户可以将训练负载分配到单节点/多加速器以及多节点/多加速器配置上(包括TPU Pod)。
4、导出到Saved Model。 TensorFlow将对Saved Model进行标准化,作为TensorFlow服务的一部分,他将成为TensorFlow Lite、TensorFlow.js、TensorFlow Hub等格式的可互换格式。
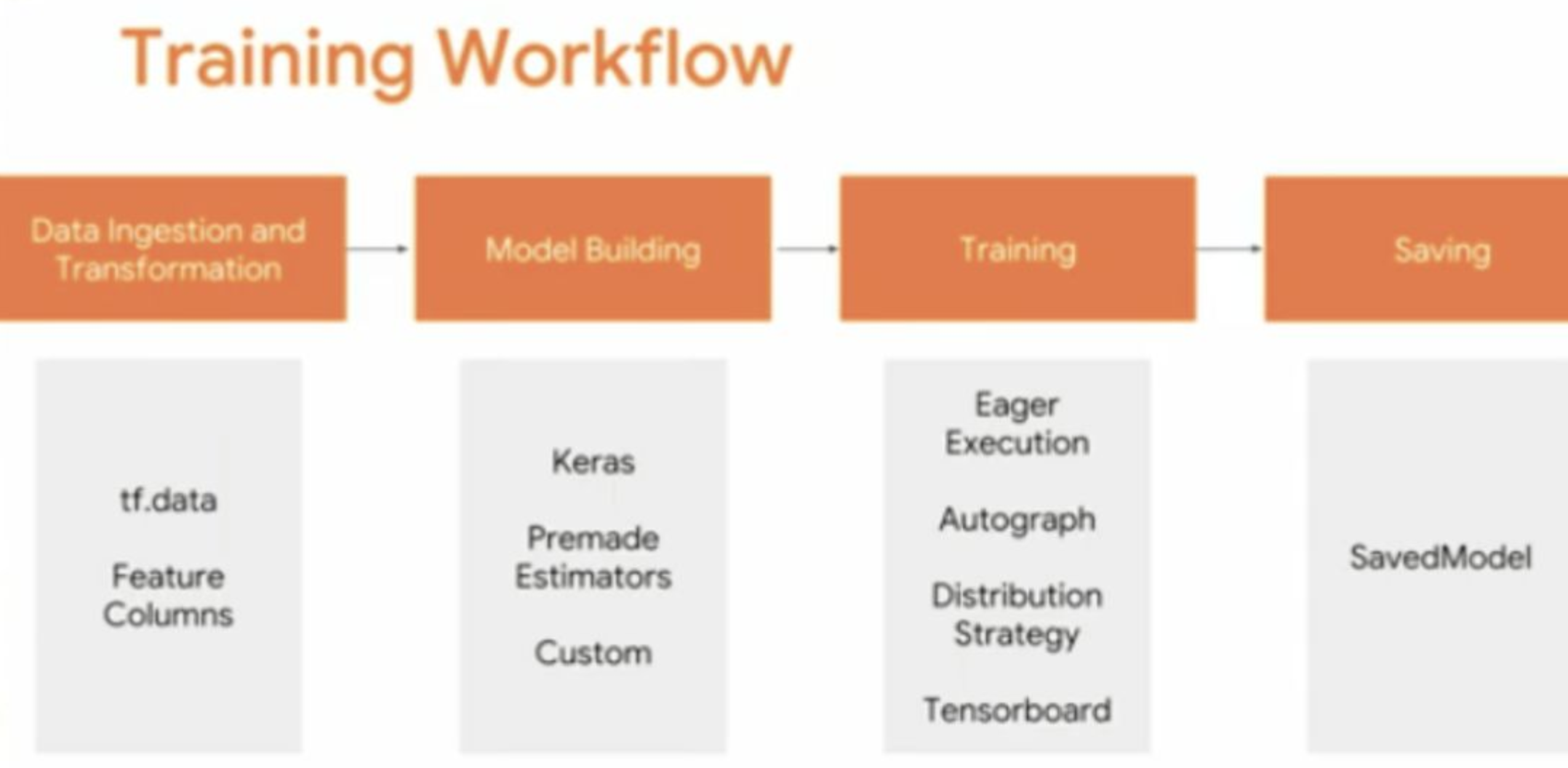
工作流程
; 2.5.3 API
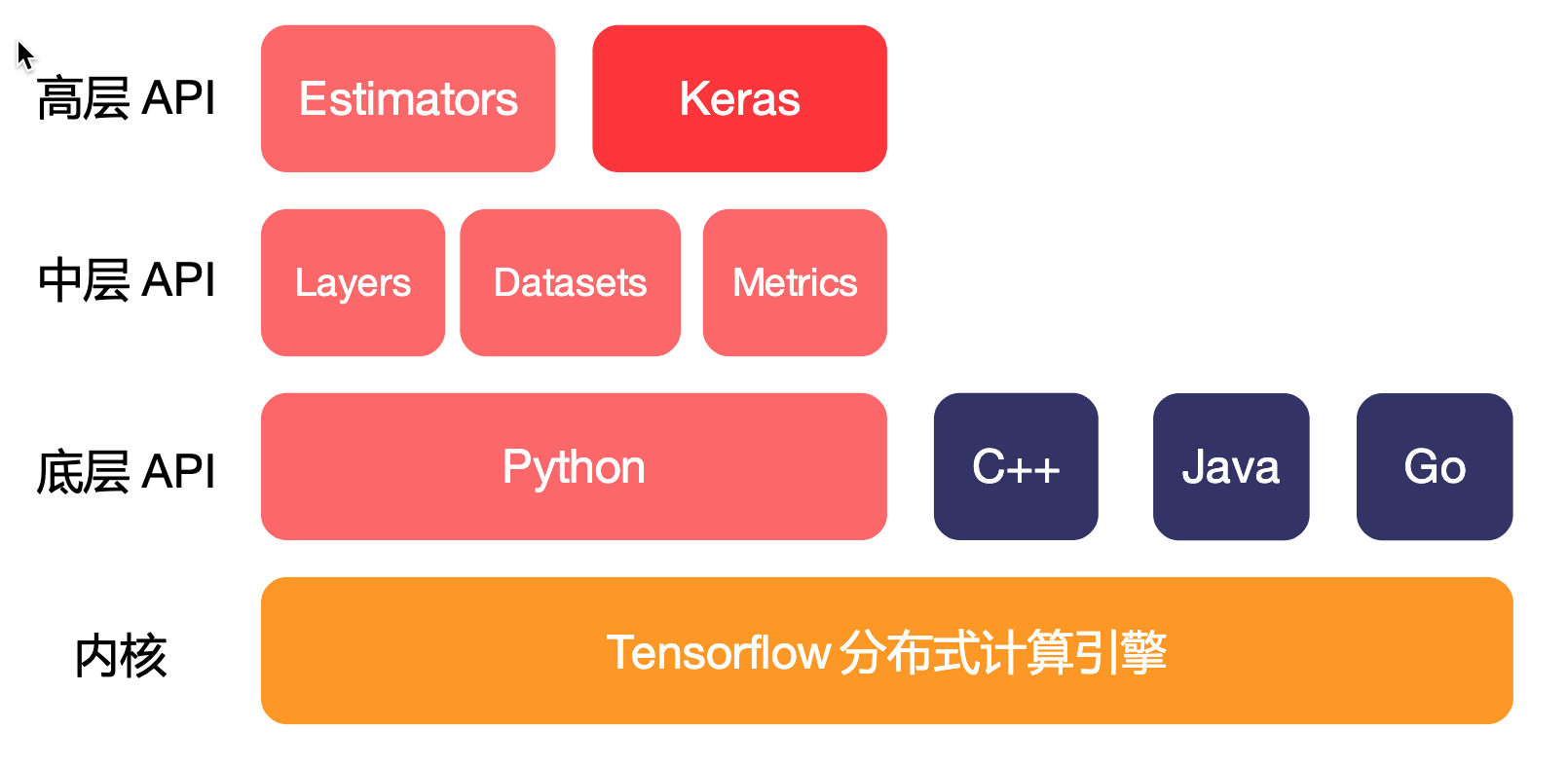
- 高层API (High level): 包括Estimators、Keras以及预构建好的Premade estimator(如线性回归、逻辑回归这些、推荐排序模型wide&deep);
- 中层API (Mid level): 包括layers, datasets, loss和metrics等具有功能性的函数,例如网络层的定义,Loss Function,对结果的测量函数等;
- 底层API (Low level): 包括具体的加减乘除、具有解析式的数学函数、卷积、对Tensor属性的测量等。
2.8 TFRecords与黑马训练数据存储
学习目标
- 目标
- 说明Example的结构
- 应用
- 应用TF保存Spark构建的样本到TFRecords文件
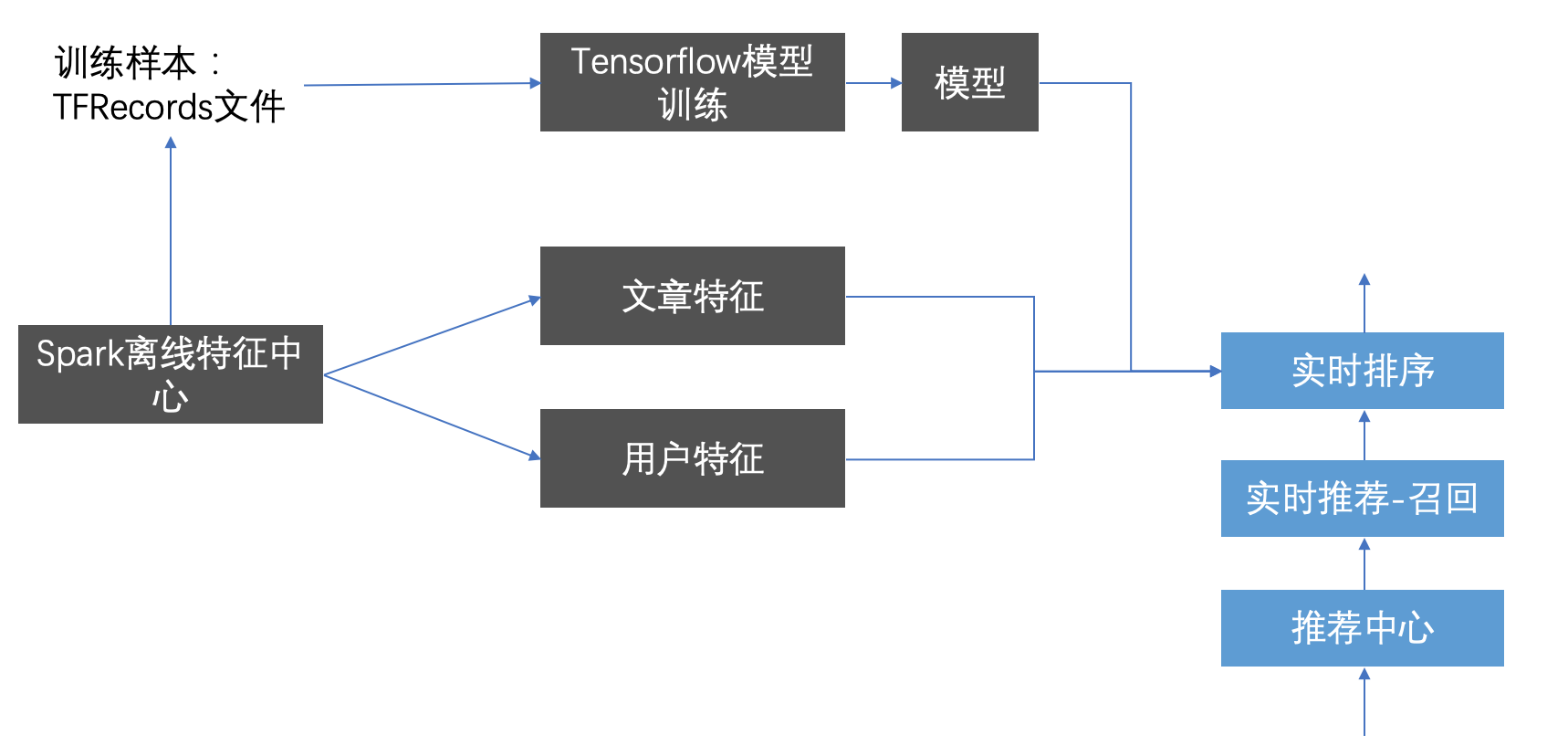
2.8.1 模型构造流程与离线样本
; 2.8.2 什么是TFRecords文件
TFRecords其实是一种二进制文件,虽然它不如其他格式好理解,但是它能更好的利用内存,更方便复制和移动, 并且不需要单独的标签文件。
TFRecords文件包含了 tf.train.Example 协议内存块(protocol buffer)(协议内存块包含了字段 Features)。可以获取你的数据, 将数据填入到 Example协议内存块(protocol buffer),将协议内存块序列化为一个字符串, 并且通过 tf.python_io.TFRecordWriter 写入到TFRecords文件。
- 文件格式 *.tfrecords
2.8.3 Example结构解析
tf.train.Example 协议内存块(protocol buffer)(协议内存块包含了字段 Features), Features包含了一个 Feature字段, Features中包含要写入的数据、并指明数据类型。这是一个样本的结构,批数据需要循环存入这样的结构
example = tf.train.Example(features=tf.train.Features(feature={
"features": tf.train.Feature(bytes_list=tf.train.BytesList(value=[features])),
"label": tf.train.Feature(int64_list=tf.train.Int64List(value=[label])),
}))
- tf.train.Example( features =None)
- 写入tfrecords文件
- features:tf.train.Features类型的特征实例
- return:example格式协议块
- tf.train. Features ( feature =None)
- 构建每个样本的信息键值对
- feature:字典数据,key为要保存的名字
- value为tf.train.Feature实例
- return:Features类型
- tf.train. Feature (options)
- options:例如
- bytes_list=tf.train. BytesList(value=[Bytes])
- int64_list=tf.train. Int64List(value=[Value])
- 支持存入的类型如下
- tf.train.Int64List(value=[Value])
- tf.train.BytesList(value=[Bytes])
- tf.train.FloatList(value=[value])
这种结构是不是很好的解决了 数据和标签(训练的类别标签)或者其他属性数据存储在同一个文件中
2.8.4 案例:CIFAR10数据存入TFRecords文件
2.8.4.1 分析
- 构造存储实例,tf.python_io.TFRecordWriter(path)
- 写入tfrecords文件
- path: TFRecords文件的路径
- return:写文件
- method
- write(record):向文件中写入一个example
- close():关闭文件写入器
- 循环将数据填入到
Example协议内存块(protocol buffer)
; 2.8.4.2 代码
对于每一个点击事件样本数据,都需要写入到example当中,所以这里需要取出每一样本进行构造存入
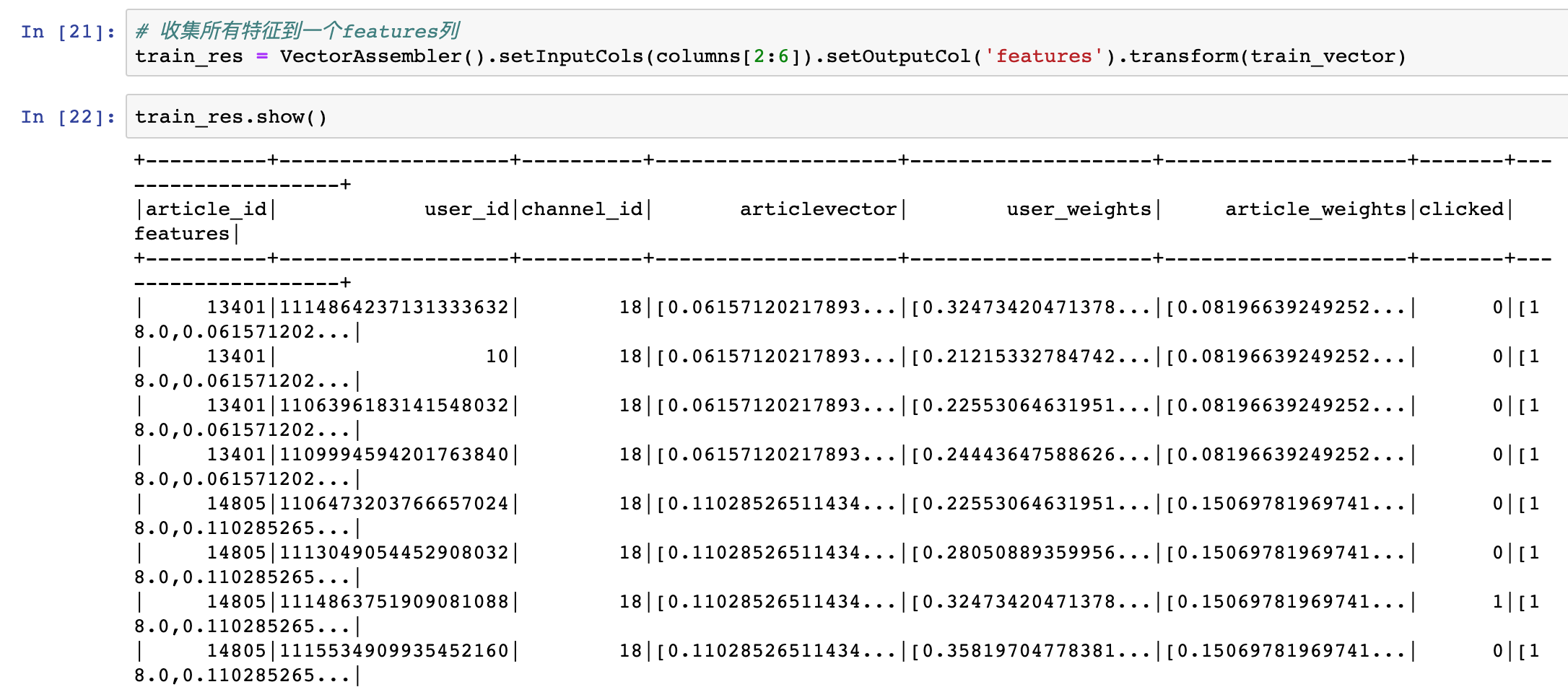
df = train_res.select(['user_id', 'article_id', 'clicked', 'features'])
df_array = df.collect()
import pandas as pd
df = pd.DataFrame(df_array)
存储
import tensorflow as tf
def write_to_tfrecords(click_batch, feature_batch):
"""
将数据存进tfrecords,方便管理每个样本的属性
:param image_batch: 特征值
:param label_batch: 目标值
:return: None
"""
writer = tf.python_io.TFRecordWriter("./train_ctr_201905.tfrecords")
for i in range(len(click_batch)):
click = click_batch[i]
feature = feature_batch[i].tostring()
example = tf.train.Example(features=tf.train.Features(feature={
"label": tf.train.Feature(int64_list=tf.train.Int64List(value=[click])),
"feature": tf.train.Feature(bytes_list=tf.train.BytesList(value=[feature])),
}))
writer.write(example.SerializeToString())
writer.close()
return None
with tf.Session() as sess:
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
write_to_tfrecords(df.iloc[:, 2], df.iloc[:, 3])
coord.request_stop()
coord.join(threads)
取出每个样本进行构建,并将其存放在<details><summary>*<font color='gray'>[En]</font>*</summary>*<font color='gray'>Take out each sample to construct and deposit it into</font>*</details>
存储
import tensorflow as tf
def write_to_tfrecords(click_batch, feature_batch):
"""
将数据存进tfrecords,方便管理每个样本的属性
:param image_batch: 特征值
:param label_batch: 目标值
:return: None
"""
writer = tf.python_io.TFRecordWriter("./train_ctr_201905.tfrecords")
for i in range(len(click_batch)):
click = click_batch[i]
feature = feature_batch[i].tostring()
example = tf.train.Example(features=tf.train.Features(feature={
"label": tf.train.Feature(int64_list=tf.train.Int64List(value=[click])),
"feature": tf.train.Feature(bytes_list=tf.train.BytesList(value=[feature])),
}))
writer.write(example.SerializeToString())
writer.close()
return None
with tf.Session() as sess:
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
write_to_tfrecords(df.iloc[:, 2], df.iloc[:, 3])
coord.request_stop()
coord.join(threads)
Original: https://blog.csdn.net/fegus/article/details/124423197
Author: 办公模板库 素材蛙
Title: Python黑马头条推荐系统第四天 TensorFlow框架介绍和深度学习
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/497568/
转载文章受原作者版权保护。转载请注明原作者出处!