

前言:
本栏目以理论与实践相结合的方式,左手阅卷,右手敲码,一步步带您领略深度学习和源代码的原理,一一攻克计算机视觉领域的三大基本任务:图像分类、目标检测、语义分割。
[En]
In the way of combining theory with practice, this column reads the paper with the left hand and knocks the code with the right hand, taking you through the principles of deep learning and source code step by step, conquering the three basic tasks in the field of computer vision one by one: image classification, target detection, and semantic segmentation.
本专栏完整代码将在我的GiuHub仓库更新,欢迎star收藏:https://github.com/Keyird/DeepLearning-TensorFlow2
文章目录
*
– 一、实战介绍与说明
–
+ (1)代码结构说明
+ (2)如何使用本项目进行预测
– 二、VOC数据集构建
–
+ (1)VOC格式介绍
+ (2)划分数据集
+ (3)解析xml标签
– 三、网络结构搭建
–
+ (1)骨干网络
+ (2)目标检测分支
– 四、损失函数构建
–
+ (1)边界框位置损失
+ (2)置信度损失
+ (3)类别损失
– 五、网络训练
–
+ (1)创建yolo模型与模型加载
+ (2)模型的装配
+ (3)模型的训练
– 六、模型预测
–
+ (1)对单张图片进行预测
+ (2)对视频进行预测
+ (3)预测结果
资源获取:
- 代码下载:https://github.com/Keyird/TensorFlow2-Detection/tree/main/YOLOv4-Tiny
- 预训练模型下载:https://pan.baidu.com/s/1dN2kR0IzGY5vluQy078qgw?pwd=o2sr 提取码:o2sr
- VOC2007数据集下载:https://pan.baidu.com/s/1lyiA3uzQhRLTaO2Xov5BHQ 提取码:wm4l
; 一、实战介绍与说明
(1)代码结构说明
yolov4-tiny
├── data // 存放预训练模型、类别等数据文件
├── img // 存放测试图片
├── nets // 存放各个局部网络结构
├── utlis // 其他
├── VOCdevkit // 数据集
├── yolo.py // 预测过程中的前向推理
├── make_data.py // 生成标签和图片路径
├── train.py // 训练网络
├── predict.py // 对单张图片进行预测
├── video.py // 对视频进行预测
(2)如何使用本项目进行预测
1、如果您希望直接使用本文的模型进行预测,只需完成以下几步:
- 下载网络模型放到data文件夹,下载数据集放在根目录下
- 运行predict.py对图片进行预测。如果是自己的图片,在predict.py中改变图片路径即可。
2、如果您需要自建数据集,并对其进行训练和预测,需完成如下步骤:
- 下载预训练模型放到data文件夹下
- 按照VOC2007的格式自制数据集,并放到根目录下
- 新建voc_classes.txt文件,写入类别,并放入data文件夹下
- 运行VOCdevkit下的dataSplit对数据集进行划分
- 运行make_data.py对标签进行解析
- 根据需要更改train.py文件中的先验框尺寸anchors_size ( 这一步可选择性跳过)
- 运行train.py进行训练,训练完成后,生成的模型默认存放在logs文件下,选择合适的模型最为最终的模型。
- 修改frcnn.py中的model_path,更改为训练好的最终的模型的路径。
二、VOC数据集构建
(1)VOC格式介绍
VOC 是目标检测一种通用的标准数据集格式,下面我以VOC2007数据集为例,来制作VOC标准数据集。整个数据集文件的目录结构如下图所示:


其中,VOC2007目录下存在着三个一级文件和一个py脚本,其具体作用是:
- Annotations:存放数据集的xml标签文件,xml文件需要进行解析。
- ImageSets:用来存放训练集或者测试集中图片ID的txt文件。
- JPEGImages:存放数据集原图。
- dataSplit.py:对数据集进行划分,将划分好的图片ID存入train.txt、val.txt和test.txt,并保存在ImageSets\Main路径下。
注:本文会提供划分好的txt文件。如果您希望训练自己的数据集,那么首先需要运行dataSplit.py文件,来划分自己的数据集。
; (2)划分数据集
运行VOCdevkit下的dataSplit.py文件,按照一定的比例,将数据集划分为:训练集、验证集和测试集。将划分好的图片ID分别存入train.txt、val.txt和test.txt,并保存在ImageSets\Main路径下。
temp_xml = os.listdir(xmlfilepath)
total_xml = []
for xml in temp_xml:
if xml.endswith(".xml"):
total_xml.append(xml)
num = len(total_xml)
trainval_percent = 0.9
train_percent = 0.9
trainval_length = int(num * trainval_percent)
train_length = int(trainval_length * train_percent)
list = range(num)
trainval = random.sample(list, trainval_length)
train = random.sample(trainval, train_length)
ftrain = open(os.path.join(saveBasePath, 'train.txt'), 'w')
fval = open(os.path.join(saveBasePath, 'val.txt'), 'w')
ftest = open(os.path.join(saveBasePath, 'test.txt'), 'w')
for i in list:
name = total_xml[i][:-4]+'\n'
if i in trainval:
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrain.close()
fval.close()
ftest .close()
(3)解析xml标签
运行make_data.py文件,通过下面的 convert_annotation() 函数对 xml 标签进行解析,并将原图路径和对应的解析后的标签写入并保存在list_file文件夹中。
def convert_annotation(year, image_id, list_file):
in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id))
tree = ET.parse(in_file)
root = tree.getroot()
for obj in root.iter('object'):
difficult = 0
if obj.find('difficult')!=None:
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (int(xmlbox.find('xmin').text), int(xmlbox.find('ymin').text), int(xmlbox.find('xmax').text), int(xmlbox.find('ymax').text))
list_file.write(" " + ",".join([str(a) for a in b]) + ',' + str(cls_id))
三、网络结构搭建
如下图所示是YOLOv4-Tiny的整体网络结构图,可以看出:YOLOv4-Tiny网络结构非常精简,网络层数不多。整体网络结构可以分为以下两部分:骨干网络和目标检测预测分支。
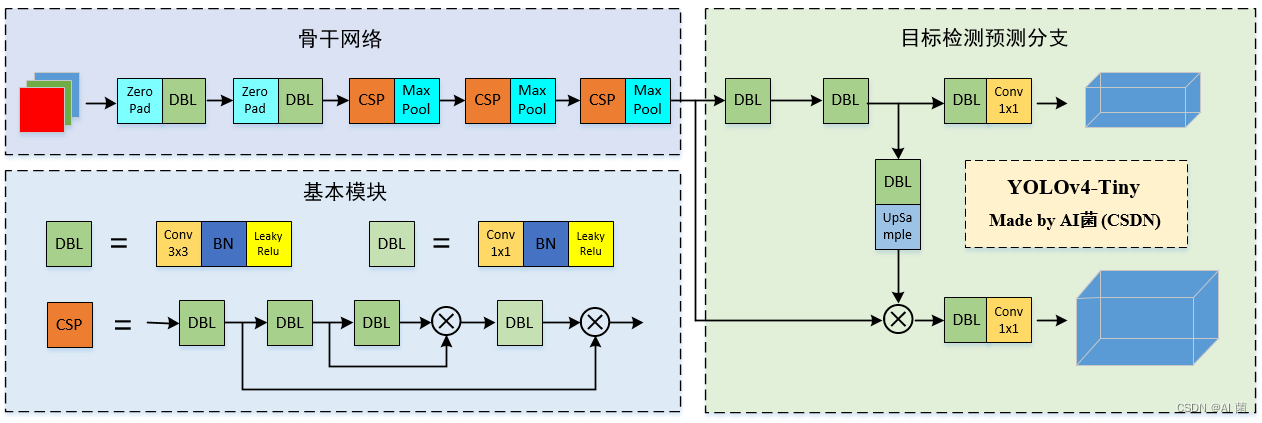
注:关注公众号【AI 修炼之路】,回复【tiny】,即可获得YOLOv4-Tiny高清无水印原图。
; (1)骨干网络
基本模块中的跨阶段局部模块CSP:
def resblock_body(x, num_filters):
""" CSPdarknet中的CSP结构块 """
x = DarknetConv2D_BN_Leaky(num_filters, (3, 3))(x)
route = x
x = Lambda(route_group, arguments={'groups': 2, 'group_id': 1})(x)
x = DarknetConv2D_BN_Leaky(int(num_filters / 2), (3, 3))(x)
route_1 = x
x = DarknetConv2D_BN_Leaky(int(num_filters / 2), (3, 3))(x)
x = Concatenate()([x, route_1])
x = DarknetConv2D_BN_Leaky(num_filters, (1, 1))(x)
feat = x
x = Concatenate()([route, x])
x = MaxPooling2D(pool_size=[2, 2], )(x)
return x, feat
整体骨干网络CSPDarknet:
def darknet_body(x):
""" CSPdarknet整体结构 """
x = ZeroPadding2D(((1, 0), (1, 0)))(x)
x = DarknetConv2D_BN_Leaky(32, (3, 3), strides=(2, 2))(x)
x = ZeroPadding2D(((1, 0), (1, 0)))(x)
x = DarknetConv2D_BN_Leaky(64, (3, 3), strides=(2, 2))(x)
x, _ = resblock_body(x, num_filters=64)
x, _ = resblock_body(x, num_filters=128)
x, feat1 = resblock_body(x, num_filters=256)
x = DarknetConv2D_BN_Leaky(512, (3, 3))(x)
feat2 = x
return feat1, feat2
(2)目标检测分支
通过已经构建的骨干网络可以获得feat1, feat2,将feat1, feat2送入两个目标检测分支,即可完成YOLOv4-Tiny网络模型的构建:
def yolo_body(inputs, num_anchors, num_classes):
"""
构建YOLOv4-Tiny网络模型
"""
feat1, feat2 = darknet_body(inputs)
P5 = DarknetConv2D_BN_Leaky(256, (1, 1))(feat2)
P5_output = DarknetConv2D_BN_Leaky(512, (3, 3))(P5)
P5_output = DarknetConv2D(num_anchors * (num_classes + 5), (1, 1))(P5_output)
P5_upsample = compose(DarknetConv2D_BN_Leaky(128, (1, 1)), UpSampling2D(2))(P5)
P4 = Concatenate()([P5_upsample, feat1])
P4_output = DarknetConv2D_BN_Leaky(256, (3, 3))(P4)
P4_output = DarknetConv2D(num_anchors * (num_classes + 5), (1, 1))(P4_output)
return Model(inputs, [P5_output, P4_output])
四、损失函数构建
YOLOv4-Tiny目标损失函数由以下三部分组成:

; (1)边界框位置损失
边界框位置损失采用的是CIOU损失函数,该函数在IOU函数的基础上进行了改进:
ciou_loss = object_mask * box_loss_scale * (1 - ciou)
ciou = box_ciou(pred_box, raw_true_box)
预测框与标签框之间的CIOU损失:
def box_ciou(b1, b2):
"""
输入为:
b1: tensor, shape=(batch, feat_w, feat_h, anchor_num, 4), xywh
b2: tensor, shape=(batch, feat_w, feat_h, anchor_num, 4), xywh
返回为:
ciou: tensor, shape=(batch, feat_w, feat_h, anchor_num, 1)
"""
b1_xy = b1[..., :2]
b1_wh = b1[..., 2:4]
b1_wh_half = b1_wh / 2.
b1_mins = b1_xy - b1_wh_half
b1_maxes = b1_xy + b1_wh_half
b2_xy = b2[..., :2]
b2_wh = b2[..., 2:4]
b2_wh_half = b2_wh / 2.
b2_mins = b2_xy - b2_wh_half
b2_maxes = b2_xy + b2_wh_half
intersect_mins = K.maximum(b1_mins, b2_mins)
intersect_maxes = K.minimum(b1_maxes, b2_maxes)
intersect_wh = K.maximum(intersect_maxes - intersect_mins, 0.)
intersect_area = intersect_wh[..., 0] * intersect_wh[..., 1]
b1_area = b1_wh[..., 0] * b1_wh[..., 1]
b2_area = b2_wh[..., 0] * b2_wh[..., 1]
union_area = b1_area + b2_area - intersect_area
iou = intersect_area / K.maximum(union_area, K.epsilon())
center_distance = K.sum(K.square(b1_xy - b2_xy), axis=-1)
enclose_mins = K.minimum(b1_mins, b2_mins)
enclose_maxes = K.maximum(b1_maxes, b2_maxes)
enclose_wh = K.maximum(enclose_maxes - enclose_mins, 0.0)
enclose_diagonal = K.sum(K.square(enclose_wh), axis=-1)
ciou = iou - 1.0 * (center_distance) / K.maximum(enclose_diagonal, K.epsilon())
v = 4 * K.square(tf.math.atan2(b1_wh[..., 0], K.maximum(b1_wh[..., 1], K.epsilon())) - tf.math.atan2(b2_wh[..., 0], K.maximum(b2_wh[..., 1], K.epsilon()))) / (math.pi * math.pi)
alpha = v / K.maximum((1.0 - iou + v), K.epsilon())
ciou = ciou - alpha * v
ciou = K.expand_dims(ciou, -1)
return ciou
(2)置信度损失
置信度损失基于交叉熵损失函数:
[En]
The confidence loss is based on the cross-entropy loss function:
confidence_loss = object_mask * K.binary_crossentropy(object_mask, raw_pred[..., 4:5], from_logits=True) + \
(1 - object_mask) * K.binary_crossentropy(object_mask, raw_pred[..., 4:5], from_logits=True) * ignore_mask
(3)类别损失
类别损失使用交叉熵损失函数:
[En]
The category loss uses the cross-entropy loss function:
class_loss = object_mask * K.binary_crossentropy(true_class_probs, raw_pred[..., 5:], from_logits=True)
五、网络训练
(1)创建yolo模型与模型加载
image_input = Input(shape=(None, None, 3))
model_body = yolo_body(image_input, num_anchors // 2, num_classes)
model_body.load_weights(weights_path, by_name=True, skip_mismatch=True)
(2)模型的装配
model.compile(optimizer=Adam(learning_rate_base),
loss={'yolo_loss': lambda y_true, y_pred: y_pred})
(3)模型的训练
model.fit(data_generator(lines[:num_train], batch_size, input_shape, anchors, num_classes, mosaic=mosaic,random=True, eager=False),
steps_per_epoch=epoch_size,
validation_data=data_generator(lines[num_train:], batch_size, input_shape, anchors, num_classes, mosaic=False, random=False, eager=False),
validation_steps=epoch_size_val,
epochs=Freeze_epoch,
initial_epoch=Init_epoch,
callbacks=[logging, checkpoint, reduce_lr, early_stopping, loss_history])
六、模型预测
(1)对单张图片进行预测
改变图片路径,运行predict.py,对单张图片进行预测:
if __name__ == "__main__":
yolo_tiny = YOLO()
img = "img/dog.jpg"
image = Image.open(img)
r_image = yolo_tiny.detect_image(image)
r_image.save("dog.jpg")
r_image.show()
(2)对视频进行预测
if __name__ == "__main__":
capture = cv2.VideoCapture("D:\\Project\\faster-rcnn-tf2\\1.mp4")
yolov4_tiny = YOLO()
while (True):
ref, frame = capture.read()
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
frame = Image.fromarray(np.uint8(frame))
frame = np.array(yolov4_tiny.detect_image(frame))
frame = cv2.cvtColor(frame, cv2.COLOR_RGB2BGR)
cv2.imshow("video", frame)
cv2.waitKey(1)
(3)预测结果

Original: https://blog.csdn.net/wjinjie/article/details/124985468
Author: AI 菌
Title: TensorFlow2深度学习实战(十八):目标检测算法YOLOv4-Tiny实战
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/496813/
转载文章受原作者版权保护。转载请注明原作者出处!