

许多教程说,使用较少的样本数或更换较大的硬件。事实上,这是治标不治本的办法。
[En]
Many tutorials say using a smaller number of samples or swapping for larger hardware. As a matter of fact, it is a temporary cure rather than a permanent cure.
如果你是直接将全部训练样本以np.narray数组的形式输入fit,这种情况下的内存不够,即使使用更小的batchsize,也不会有明显的改善。
先说解决方案——那就是官方自定义的数据格式 tfrecords.
在这种格式下,每次只从存储硬盘中读取一个batchsize的数据入内存(显存),而不是将整个训练样本一次性全部读入,因此可以大大减小内存开支,但会牺牲小部分IO性能。
从tensorflow数据存取方式讲起
- Preloaded data:预加载数据。
- Feeding:利用python读取原始数据,将数据feed到图中。
- Reading from file:从文件中直接读取。
1. Preloaded data
这种方法是一般机器学习最基本的方法,但只适用于数据量较小的情况。
[En]
This method is the most basic way of general machine learning, but it is only suitable for cases with small amount of data.
数据加载方式是自己在内存中直接创建数据,省去了每个batch从硬盘到内存这个步骤。
然而,这种方法受到内存大小的严格限制,当内存中没有空间时,大数据不能使用这种方法。
[En]
However, this method is strictly limited by the size of memory, and big data cannot use this method when there is no room in it.
2. Feeding
这种方式就需要每次从硬盘存一个batch的数据到内存中,然后送入到占位符中,在图中进行计算。这种方式的优势在于训练过程只需要一个batch的内存,并且如果你暂时不熟悉tensorflow相关的数据才做,可以利用python相关的库处理之后再送入到占位符中。
但是这种方式也有很大缺陷,就是当数据规模较大的时候,也会出现数据传输的较大时间损耗,效率偏低。这里的传输只从python读入的数据传入到图中计算的数据,这之间存在一个数据转换的问题。
2. Reading from file
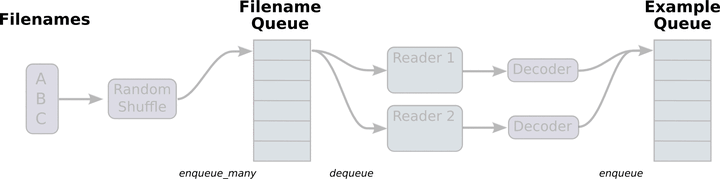

tensorflow内置了三种格式的文件读取管道,这种文件读取流程是如上图所示的高效率的双队列机制。
其中,读取数据的线程不断将文件系统中的数据读入,另一个线程则是负责计算,计算需要的数据直接从内存中取即可。在TF中还提供一种高效的数据管理机制,双队列机制。在内存队列之前有一个文件名队列,更好的管理epoch。综上所述,在这里讨论一种适用于大规模数据的方法。
这三种文件格式分别为:
tf.data.TFRecordDataset、tf.data.TextLineDataset、tf.contrib.data.CsvDataset
针对我们的高维数据类型,我们采用TFRecordDataset格式。
; 下面正式开始数据转存
1.首先将数据数组转为Tensor格式,并按照 tfrecords的存储方式存储。
tfrecords的存储方式为:将所有(float, int, bytes等)格式数据全部转为string格式的字符串数据;读取时再根据原数据格式反编译。
具体可参考:
Tensorflow官网: https://tensorflow.google.cn/tutorials/load_data/tfrecord
知乎相关文章: https://zhuanlan.zhihu.com/p/363999842
def save_tfrecords(data, label, desfile):
with tf.io.TFRecordWriter(desfile) as writer:
for i in range(len(data)):
features = tf.train.Features(
feature = {
"data":tf.train.Feature(bytes_list = tf.train.BytesList(value = [tf.io.serialize_tensor(data[i]).numpy()])),
"label":tf.train.Feature(float_list = tf.train.FloatList(value = label[i])),
}
)
example = tf.train.Example(features = features)
serialized = example.SerializeToString()
writer.write(serialized)
您可以拆分样本和标签,并将它们保存在块中:
[En]
You can split the sample and label and save them in blocks:
save_tfrecords(x_in_sample1,y_in_sample1, "path1.tfrecords")
save_tfrecords(x_in_sample2,y_in_sample2, "path2.tfrecords")
2.利用tensorflow内集成的数据流管道分批次读取TFR大数据集,并行训练
def map_func(example):
feature_description = {
'data': tf.io.FixedLenFeature([], tf.string),
'label': tf.io.FixedLenFeature([], tf.float32),
}
parsed_example = tf.io.parse_single_example(example, features=feature_description)
x_sample = tf.io.parse_tensor(parsed_example['data'], tf.float32)
y_sample = parsed_example['label']
return x_sample, y_sample
def load_dataset(filepaths):
shuffle_buffer_size = 3000
batch_size = 256
dataset = tf.data.TFRecordDataset(filepaths)
dataset = dataset.shuffle(shuffle_buffer_size)
dataset = dataset.map(map_func=map_func, num_parallel_calls= 8)
dataset = dataset.batch(batch_size).prefetch(64)
return dataset
train_set = load_dataset(["path1.tfrecords","path2.tfrecords"])
valid_set = load_dataset(["path3.tfrecords","path4.tfrecords"])
hist = model.fit(train_set,epochs=model_epochs, validation_data=valid_set, callbacks=[early_stopping])
至此,完成。
牺牲了小部分数据IO的性能,换来了仅需很小内存开支的模型大样本训练。
小tips:
使用了tfrecords后,训练模型所需要的内存大大减少,因此,为了充分利用GPU资源,可以手动将GPU的内存分割,从而用一个GPU同时训练多个模型。
GPU内存获取限制代码如下,这里设置memory_limit=1024:
gpus = tf.config.experimental.list_physical_devices('GPU')
if gpus:
try:
tf.config.experimental.set_virtual_device_configuration(
gpus[0],
[tf.config.experimental.VirtualDeviceConfiguration(memory_limit=1024)])
logical_gpus = tf.config.experimental.list_logical_devices('GPU')
print(len(gpus), "Physical GPUs,", len(logical_gpus), "Logical GPUs")
except RuntimeError as e:
print(e)
在每个模型程序中,加入此代码,设置memory_limit,即可在一个GPU中,同时训练多个模型。
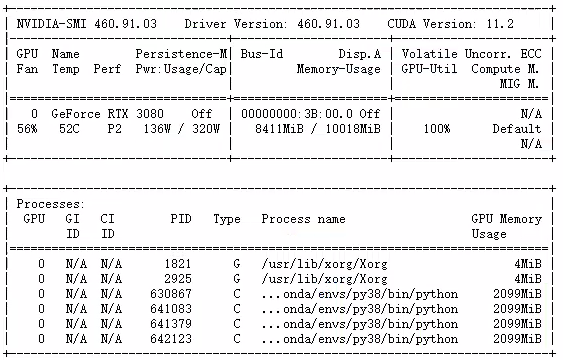
可以看到,这里同时跑了4个模型,每个模型使用2099M内存(虽然设置中仅为memory_limit=1024,但实际运行中可能会多1一个G左右,这个需要注意一下),且将GPU算力用到了100%,充分利用了GPU的资源。
Original: https://blog.csdn.net/qq_37373209/article/details/122094822
Author: RicardoOzZ
Title: tensorflow2.x(一) 显存不够或内存不够要怎么办?
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/496584/
转载文章受原作者版权保护。转载请注明原作者出处!