

ID:399899
注: 这里使用的数据源是Tushare
LSTM股票价格预测实验
实验介绍
使用LSTM进行股票价格的预测,用到的框架主要包括:TensorFlow2.0,主要用于深度学习算法的构建,本实验以Tushare平台的601398股票历史数据为基础,基于Keras深度学习库股票价格进行预测。
算法原理:
这里就不对模型原理进行介绍了 这里引用一下别人的 需要的朋友去看一下https://juejin.cn/post/6973082167970627620
搭建思路:
使用LSTM模型对股票数据的’open’, ‘high’, ‘low’, ‘close’, ‘pre_close’, ‘change’, ‘pct_chg’, ‘vol’, ‘amount’九个特征进行训练预测收盘价。
准备工作
环境准备:python3.7;Tensorflow;Keras
数据准备:https://www.tushare.pro/ ;原始数据取得是由tushare平台提供的股票日线行情历史数据。
实验步骤
导入实验环境
导入相应的模块
import pandas as pd
import tensorflow as tf
import numpy as np
import tushare as ts
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['KaiTi']
plt.rcParams['axes.unicode_minus'] = False
导入实验数据集
步骤 1 获取数据
ts.set_token('这里填写自己的token码在个人主页可以获取')
pro = ts.pro_api()
data = pr.daily(ts_code='601398.SH')
data = data.iloc[::-1,]
data1 = data.copy(deep=True)
tushare主页:https://tushare.pro/document/2
步骤 2 检测是否有缺失值
data.isna().any()
输出结果:
ts_code False
trade_date False
open False
high False
low False
close False
pre_close False
change False
pct_chg False
vol False
amount False
步骤 3 异常值检测
data1 = data
mean1 = data1['vol'].quantile(q=0.25)
mean2 = data1['vol'].quantile(q=0.75)
mean3 = mean2-mean1
topnum21 = mean2+1.5*mean3
bottomnum21 = mean2-1.5*mean3
print("正常值的范围:",topnum21,bottomnum21)
print("是否存在超出正常范围的值:",any(data1['vol']>topnum21))
print("是否存在小于正常范围的值:",any(data1['vol']<bottomnum21))
输出结果:
正常值的范围: 4625919.582500001 -113825.70250000013
是否存在超出正常范围的值: True
是否存在小于正常范围的值: False
检测到存在超出正常范围的值,并替换该值的这一部分。
[En]
Detect that there is a value outside the normal range, and replace this part of the value.
replace_value=data1['vol'][data1['vol']<topnum21].max()
data1.loc[data1['vol']>topnum21,'vol']=replace_value
mean1 = data1['amount'].quantile(q=0.25)
mean2 = data1['amount'].quantile(q=0.75)
mean3 = mean2-mean1
topnum21 = mean2+1.5*mean3
bottomnum21 = mean2-1.5*mean3
print("正常值的范围:",topnum21,bottomnum21)
print("是否存在超出正常范围的值:",any(data1['amount']>topnum21))
print("是否存在小于正常范围的值:",any(data1['amount']<bottomnum21))
输出结果:
正常值的范围: 2558165.1642500004 -167064.92425000016
是否存在超出正常范围的值: True
是否存在小于正常范围的值: False
检测到存在超出正常范围的值,并替换该值的这一部分。
[En]
Detect that there is a value outside the normal range, and replace this part of the value.
replace_value=data1['amount'][data1['amount']<topnum21].max()
data1.loc[data1['amount']>topnum21,'amount']=replace_value
步骤 4 归一化处理
这里采用的最大和最小归一化可以使模型更具稳健性。
[En]
The maximum and minimum normalization adopted here can make the model more robust.
data = data.iloc[:,2:]
data_max = data.max()
data_min = data.min()
data = (data-data_min)/(data_max-data_min)
步骤 5 数据划分并查看数据集信息
dataset_st = np.array(data)
def data_set(dataset, lookback):
dataX, dataY = [], []
for i in range(len(dataset)-lookback):
a = dataset[i:(i+lookback)]
dataX.append(a)
dataY.append(dataset[i+lookback][3])
return np.array(dataX), np.array(dataY)
train_size = int(len(dataset_st)*0.7)
test_size = len(dataset_st)-train_size
train, test = dataset_st[0:train_size], dataset_st[train_size:len(dataset_st)]
print(len(train))
print(len(test))
lookback = 60
trainX, trainY = data_set(train, lookback)
testX, testY = data_set(test, lookback)
print('trianX:,trianY', trainX.shape, trainY.shape)
输出结果:
trianX:,trianY (2560, 60, 7) (2560,)
LSTM回归预测 建模
步骤 1 初始化神经网络
数据集已经准备好了,然后我们需要建立一个训练模型,我们首先需要建立一个初始化的神经网络。
[En]
The data set is ready, and then we need to build a training model, and we first need to establish an initialized neural network.
model=tf.keras.Sequential([tf.keras.layers.LSTM(120,input_shape=(trainX.shape[1],
trainX.shape[2]),return_sequences=True),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.LSTM(60),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(30,activation='relu'),
tf.keras.layers.Dense(1)
])
步骤 2 定义学习率更新规则
设置模型的学习率参数。
给出学习率(步长)进行更新
model.compile(
optimizer=tf.keras.optimizers.Adam(0.001),
loss='mean_squared_error',
metrics=["mse"]
)
步骤 3 构建模型训练
神经网络模型参数的更新是一个迭代过程,可以将模型训练过程定义为训练模型的函数。
[En]
The updating of model parameters of neural network is an iterative process, so we can define the process of model training as a function to train the model.
history = model.fit(trainX, trainY,
batch_size=64, epochs=25, validation_data=(testX, testY),
validation_freq=1)
步骤 4 构建绘图函数
绘制train loss与epoch的关系图,这样我们就可以查看模型训练的每一步损失值。
def plot_learning_curves(history):
pd.DataFrame(history.history).plot(figsize=(10,6))
plt.grid(True)
plt.title('训练情况')
plt.savefig('./训练情况.jpg')
plt.show()
3实验结果及分析 ****
3 .1 实验结果 ****
评价指标:
MSE: tf.Tensor(25.45738, shape=(), dtype=float32)
MAE: tf.Tensor(5.0175276, shape=(), dtype=float32)
MAPE: tf.Tensor(93.39253, shape=(), dtype=float32)


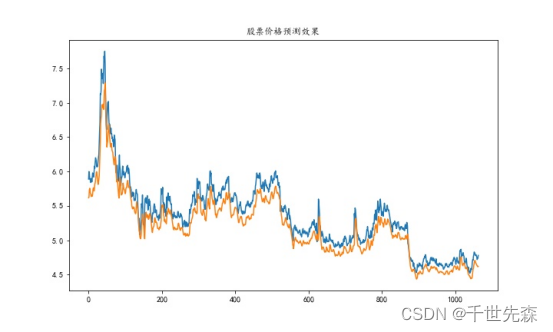
; 实验 分析
从评价指标可以看出,总体误差不大,预测形势走势与实际情况基本一致,但价格有所偏离,值得改进。
[En]
From the evaluation indicators, we can see that the overall error is small, and the trend of the predicted situation is basically consistent with the actual situation, but the price is deviated, which is worth improving.
整体来说,LSTM模型股票价格预测有一定效果,对证券投资市场具有一定的指导作用。
Original: https://blog.csdn.net/As_Yan_Do/article/details/124649032
Author: 千世先森
Title: LSTM股票价格预测
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/496450/
转载文章受原作者版权保护。转载请注明原作者出处!